En esta lección, aprenderemos a ejecutar un análisis de moderación múltiple en R. Al explorar el impacto de múltiples moderadores, podemos profundizar nuestra comprensión de la dinámica entre las variables de interés e iluminar interacciones potenciales.
Los análisis estadísticos frecuentemente revelan relaciones intrigantes entre variables. Sin embargo, las relaciones entre variables suelen ser más complejas de lo que aparentan en el mundo real. Múltiples factores pueden influir en estas relaciones, añadiendo una capa de complejidad a los análisis. Es aquí donde entra en juego el concepto de moderación múltiple: una forma de regresión múltiple moderada que examina cómo dos o más variables moderadoras afectan la relación entre predictores y resultados.
Si ya estás familiarizado con la moderación, estás listo para dar un paso más hacia la moderación múltiple. Si no, te recomendamos familiarizarte con el concepto de moderación consultando nuestro artículo anterior, Cómo Ejecutar un Análisis de Moderación en R con Un Solo Moderador.
Este es un tutorial práctico con un conjunto de datos descargable e instrucciones paso a paso para dominar el análisis de moderación múltiple en R.
Qué es el Análisis de Moderación Múltiple
El análisis de moderación es una estrategia analítica que busca descifrar e iluminar las circunstancias bajo las cuales una relación particular se mantiene. La idea subyacente es bastante intuitiva: la relación entre dos variables puede depender de, o estar influenciada por, los niveles de otra variable, un concepto conocido como moderación. El moderador modifica la dirección o fuerza de la correlación entre el predictor (o variable independiente) y el resultado (o variable dependiente).
Un análisis de moderación simple investiga un moderador, pero qué sucede si la interacción entre el predictor y el resultado depende de más de una condición? Aquí es donde entra en escena el análisis de moderación múltiple.
En el contexto de moderación múltiple, nos interesa explorar cómo dos o más variables moderadoras modifican el efecto de la variable predictora sobre la variable de resultado. Para representar esto en una ecuación de regresión múltiple, extendemos el modelo de moderación simple incluyendo términos adicionales para cada moderador y término de interacción. En un estudio con dos moderadores, nuestra ecuación de regresión se vería así:
Donde:
-
Y es la variable de resultado.
-
X es la variable predictora.
-
M1 y M2 son las dos variables moderadoras.
-
B0 es el intercepto.
-
B1, B2, B3 son los coeficientes de regresión para los efectos principales de X, M1 y M2 respectivamente.
-
B4 y B5 son los coeficientes para los términos de interacción de dos vías X*M1 y X*M2, representando los efectos de moderación de cada moderador.
-
B6 es el coeficiente para la interacción de dos vías entre los dos moderadores M1*M2.
-
B7 es el coeficiente para el término de interacción triple X*M1*M2, representando el efecto de moderación combinado de ambos moderadores simultáneamente.
-
e es el término de error, representando la varianza residual no explicada por los predictores y moderadores.
Ejemplo de Análisis de Moderación Múltiple
Consideremos un ejemplo relacionado con las ciencias del ejercicio. Supongamos que estás investigando el efecto de un programa de entrenamiento (la variable predictora, X) sobre el rendimiento deportivo (la variable de resultado, Y). Propones que la edad del atleta (primer moderador, M1) y sus años de entrenamiento previo (segundo moderador, M2) podrían influir en la efectividad del programa de entrenamiento.
En este caso, el análisis de moderación múltiple nos permite investigar si el efecto del programa de entrenamiento sobre el rendimiento deportivo es diferente para diversos grupos de edad y niveles de experiencia de entrenamiento previo. En otras palabras, el análisis nos ayuda a determinar si la influencia del programa de entrenamiento sobre el rendimiento deportivo está moderada tanto por la edad como por los años de entrenamiento previo.
Al comprender el efecto de estos múltiples moderadores, obtenemos una visión más matizada de cómo y bajo qué condiciones nuestro programa de entrenamiento impacta el rendimiento. Este tipo de investigación puede conducir a programas de entrenamiento más focalizados que consideren la edad del atleta y su experiencia previa.
Entonces, por qué es crucial el análisis de moderación múltiple? La fortaleza de este enfoque reside en su capacidad para revelar relaciones intrincadas y multifacéticas. En lugar de explorar asociaciones directas entre variables, el análisis de moderación múltiple proporciona información sobre bajo qué circunstancias o para quién estas relaciones son relevantes.
Este método puede destacar cómo la influencia de una variable independiente sobre una dependiente puede cambiar en función de los niveles de dos o más moderadores diferentes, ofreciendo así una comprensión más rica y estratificada de la dinámica en juego.
Al responder preguntas más afines a las complejidades de situaciones reales, el análisis de moderación múltiple ofrece una herramienta robusta para la investigación en diversos campos, aumentando nuestra comprensión del mundo que nos rodea.
Supuestos del Análisis de Moderación Múltiple
-
Linealidad y Aditividad: La relación entre predictores (incluyendo los términos de interacción) y la variable de resultado debe ser lineal, y los efectos de los diferentes predictores deben ser aditivos. Esto significa que el efecto de un predictor sobre la variable de resultado no debe cambiar en función del valor de otro predictor, excepto según lo definido por el término de interacción. Puedes aprender más sobre la importancia de la linealidad aquí.
-
Independencia de Errores: Los residuos (errores) del modelo, es decir, las diferencias entre los valores observados y predichos de la variable de resultado, deben ser independientes. Esto implica que el valor del residuo para una observación no debe predecir el valor del residuo de otra.
-
Homocedasticidad: La varianza de los residuos debe ser constante a través de todos los niveles de los predictores. Esto significa que la dispersión de los residuos debe ser aproximadamente la misma para todos los valores de tus predictores. Aquí puedes aprender más sobre por qué la homocedasticidad es crucial en estadística.
-
Normalidad de Errores: Los residuos del modelo deben estar aproximadamente distribuidos de forma normal. Esto significa que si graficamos la frecuencia de los residuos, el gráfico debería formar aproximadamente la forma de una campana. Aprende más sobre la normalidad de errores aquí.
-
Ausencia de Multicolinealidad: Los predictores en el modelo no deben estar perfectamente correlacionados entre sí. Si existe multicolinealidad perfecta (o incluso alta multicolinealidad), implica que dos o más predictores están proporcionando la misma información sobre la variación en la variable de resultado, dificultando la identificación del efecto independiente de cada predictor.
-
Sin Valores Atípicos Influyentes: No debe haber un solo punto de datos que influya indebidamente en las estimaciones del modelo. Aunque los valores atípicos no son inusuales, los particularmente influyentes pueden distorsionar los resultados del modelo y reducir la precisión de tus predicciones.
En el contexto del análisis de moderación múltiple, estos supuestos ayudan a asegurar que nuestros resultados sean confiables y que evitemos interpretaciones engañosas. Mientras que violaciones menores de algunos supuestos pueden no afectar drásticamente el modelo, violaciones severas o múltiples podrían sugerir que el análisis de moderación múltiple puede no ser el método más apropiado para nuestros datos.
Formula el Modelo de Análisis de Moderación Múltiple
Imaginemos que estamos interesados en estudiar el impacto del ejercicio físico sobre la salud mental. Específicamente, nos interesa comprender el rol de dos moderadores potenciales, "calidad del sueño" y "dieta equilibrada", en esta relación.
Así se vería nuestra pregunta de investigación: "Cómo la calidad del sueño y tener una dieta equilibrada moderan la relación entre el ejercicio físico y la salud mental?"
Dada esta pregunta de investigación, podríamos formular las siguientes hipótesis:
-
El ejercicio físico tiene un efecto positivo sobre la salud mental.
-
El efecto positivo del ejercicio físico sobre la salud mental es más fuerte para individuos con mejor calidad de sueño.
-
El efecto positivo del ejercicio físico sobre la salud mental es más fuerte para individuos que siguen una dieta equilibrada.
Ahora, dibujemos un diagrama que represente visualmente las relaciones e interacciones que proponemos en nuestra pregunta de investigación e hipótesis asociadas:
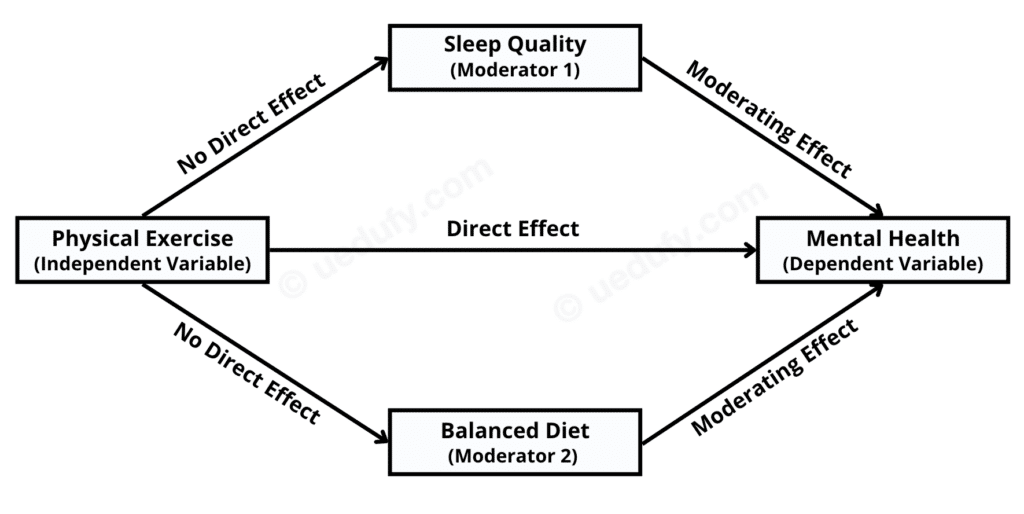
Figura 1: Modelo de análisis de moderación múltiple con dos moderadores
Donde:
-
Ejercicio Físico (Variable Independiente): Esta es nuestra variable independiente. Es el factor principal que investigamos por un efecto potencial sobre la salud mental. Podría medirse de varias formas, como horas de ejercicio por semana, tipo de ejercicio realizado, etc.
-
Salud Mental (Variable Dependiente): Esta es nuestra variable dependiente. Nuestro interés principal radica en comprender cómo el ejercicio físico podría influir en esta variable. La salud mental podría evaluarse mediante muchas métricas, como encuestas de autorreporte, evaluaciones clínicas, etc.
-
Calidad del Sueño (Moderador 1) y Dieta Equilibrada (Moderador 2) son nuestras variables moderadoras. Hipotetizamos que estos factores pueden modificar la relación entre el ejercicio físico y la salud mental. Respectivamente, el efecto del ejercicio físico sobre la salud mental podría cambiar dependiendo del nivel de estas variables moderadoras.
Los efectos, representados por las flechas en el diagrama anterior, son los siguientes:
-
Efecto Directo: Esta flecha significa el impacto directo que el ejercicio físico (Variable Independiente) puede tener sobre la salud mental (Variable Dependiente).
-
Efectos Moderadores: Estas flechas muestran la influencia potencial que nuestros moderadores (Calidad del Sueño y Dieta Equilibrada) podrían tener sobre la relación entre el ejercicio físico y la salud mental. Específicamente, estos efectos muestran cómo la relación entre el ejercicio físico y la salud mental podría cambiar en diferentes niveles de las variables moderadoras.
-
Sin Efecto Directo: Estas flechas indican que no hipotetizamos un efecto directo del ejercicio físico (Variable Independiente) hacia ninguna de las variables moderadoras (Calidad del Sueño y Dieta Equilibrada).
A medida que avancemos, el diagrama ayudará enormemente a mantener una comprensión conceptual clara de las relaciones que estamos evaluando e interpretando en nuestro análisis.
Cómo Ejecutar un Análisis de Moderación Múltiple en R
Habiendo establecido una base teórica sólida sobre el análisis de moderación múltiple, es momento de poner la teoría en práctica ejecutando un análisis de moderación en R.
Si aún no tienes R o RStudio instalado, aquí tienes una guía útil para instalar R y RStudio en Windows, macOS, Linux y Unix. Ahora, pongamos manos a la obra y profundicemos en el proceso de ejecutar un análisis de moderación con múltiples moderadores en R.
El conjunto de datos consiste en datos ficticios de 30 encuestados y cuatro variables, y se utilizará únicamente con fines educativos. Alternativamente, puedes usar tu propio conjunto de datos y seguir las instrucciones.
Paso 1: Cargar los Datos y Paquetes Necesarios en R
Antes de proceder con el análisis, necesitamos cargar nuestros datos en R. Dado que nuestro conjunto de datos está en un archivo Excel, podemos utilizar el paquete readxl para importar los datos de forma conveniente.
Para nuestro análisis de moderación, usaremos dos paquetes clave. El primero es jtools, que proporciona funciones amigables que hacen los modelos de regresión más fáciles de comprender e interpretar. El segundo paquete, interactions, está específicamente diseñado para explorar y visualizar interacciones dentro de modelos de regresión, convirtiéndolo en una herramienta ideal para el análisis de moderación.
Combinar estos paquetes nos permitirá realizar un análisis de moderación completo y visualmente intuitivo.
# Instalar los paquetes necesarios
install.packages("readxl")
install.packages("jtools")
install.packages("interactions")
# Cargar los paquetes
library(readxl)
library(jtools)
library(interactions)
# Cargar los datos en un data frame
data <- read_excel("Ruta_a_tu_archivo/data.xlsx")
En este código, reemplaza "**Ruta_a_tu_archivo/data.xlsx**" por la ruta real de tu archivo Excel.
IMPORTANTE: Si eliges importar tu conjunto de datos mediante la interfaz gráfica de RStudio, aún necesitas agregar data <- read_excel("Ruta_a_tu_archivo/data.xlsx") a tu script; de lo contrario, tu conjunto de datos no se cargará en un data frame en R. No olvides colocar la ruta de tu conjunto de datos entre comillas. Aquí tienes algunos recursos útiles para importar un conjunto de datos en varios formatos a R, por si encuentras algún problema:
Paso 2: Explorar los Datos
Antes de sumergirse en el análisis, siempre es buena idea explorar y comprender tus datos. Usaremos la función str para mostrar la estructura de nuestro conjunto de datos.
# Explorar la estructura de los datos
str(data)
La función str mostrará los nombres de tus variables y las primeras entradas de cada una.

Figura 2: Estructura del conjunto de datos en R mostrando 30 encuestados y 4 variables
Paso 3: Ajustar el Modelo de Regresión
Nuestro siguiente paso es ajustar un modelo de regresión a nuestros datos. El modelo incluye términos de interacción para nuestros moderadores. Usaremos la función lm en R, que ajusta un modelo de regresión de mínimos cuadrados ordinarios (OLS) a los datos.
# Ajustar el modelo
model <- lm(mental_health ~ exercise * sleep_quality * balanced_diet, data = data)
IMPORTANTE: En el script anterior, mantén los nombres de las variables exactamente como están en tu conjunto de datos; de lo contrario, R no podrá encontrar el objeto respectivo.
Es decir, si tenemos la variable mental_health en nuestro conjunto de datos, úsala exactamente así y no Mental_Health o MentalHealth.
En el modelo, dos asteriscos (**) representan los términos de interacción. Un término de interacción es simplemente una variable creada al multiplicar dos variables. En nuestro caso, nos interesa la interacción de exercise tanto con sleep_quality como con balanced_diet. El modelo anterior considera todas las interacciones posibles entre nuestra variable independiente y los moderadores.
Para que sepas, no esperamos que R proporcione ningún resultado con el código anterior. Aquí solo estamos ajustando el modelo, y en el siguiente paso veremos los resultados.
A continuación, evaluaremos la significancia de nuestro modelo, verificaremos los supuestos de regresión e interpretaremos nuestros hallazgos.
Paso 4: Examinar los Resultados del Análisis de Moderación Múltiple
Una vez ajustado el modelo, el siguiente paso es examinar los resultados del análisis. Para esto, usaremos la función summary() para mostrar un resumen de los resultados del modelo. Así es como se hace:
# Mostrar un resumen de los resultados del modelo
summary(model)
Ejecutar este código proporcionará una salida que incluye coeficientes para los efectos principales de cada variable independiente (exercise, sleep_quality, balanced_diet), así como los términos de interacción (exercise:sleep_quality, exercise:balanced_diet, sleep_quality:balanced_diet y exercise:sleep_quality:balanced_diet).
Así se ve la salida del resumen:
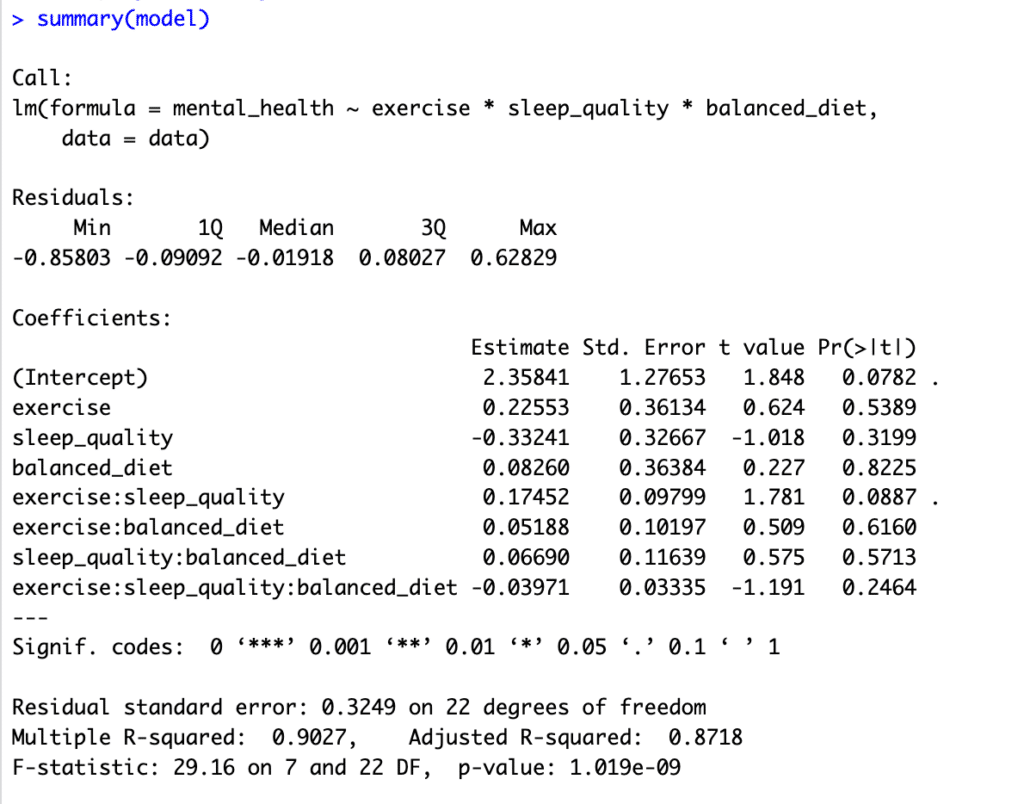
Figura 3: Resultados del análisis de moderación múltiple mostrando efectos de interacción
Los coeficientes para los términos de interacción son de interés primario en el análisis de moderación, ya que nos dicen cómo la relación entre la variable independiente (exercise) y la variable dependiente (mental_health) cambia en función de las variables moderadoras (sleep_quality, balanced_diet).
Si el coeficiente del término de interacción es significativamente diferente de cero (p menor a 0.05), podemos concluir que el efecto de la variable independiente sobre la variable dependiente está moderado por la variable respectiva.
Paso 5: Interpretar los Resultados del Análisis de Moderación Múltiple
Interpretar los resultados de un análisis de moderación múltiple puede ser desafiante, particularmente cuando hay múltiples términos de interacción. Sin embargo, la premisa básica sigue siendo la misma: si el término de interacción es significativo, indica que la relación entre la variable independiente y la variable dependiente está moderada por la variable respectiva.
Así interpretamos la salida del resumen del modelo anterior:
-
El término de interacción
exercise:sleep_qualitytiene un valor p de 0.0887, que está justo por encima del umbral estándar de 0.05 para significancia estadística, pero podría considerarse "marginalmente significativo" o una "tendencia" hacia la significancia. Esto indica que podría existir un efecto de moderación de la calidad del sueño sobre la relación entre ejercicio y salud mental. Sin embargo, la evidencia no es lo suficientemente fuerte para estar seguros al nivel estándar de 0.05. -
El término de interacción
exercise:balanced_diettiene un valor p de 0.6160, indicando que la evidencia no es lo suficientemente fuerte para concluir que una dieta equilibrada modera la relación entre ejercicio y salud mental. -
El término de interacción triple
exercise:sleep_quality:balanced_diettiene un valor p de 0.2464, indicando que la evidencia no es lo suficientemente fuerte para concluir que los efectos del ejercicio sobre la salud mental están moderados por la calidad del sueño y la dieta equilibrada simultáneamente. -
Las estimaciones de los coeficientes representan el cambio en la variable dependiente (salud mental) por cada incremento de una unidad en la variable independiente respectiva, asumiendo que todas las demás variables se mantienen constantes.
-
El error estándar residual es una medida de la calidad del modelo de regresión lineal: valores más bajos generalmente sugieren un mejor ajuste a los datos.
-
El valor de R cuadrado es una medida estadística que representa la proporción de la varianza de una variable dependiente explicada por una o más variables independientes en un modelo de regresión. En este caso, aproximadamente el 90% de la varianza en salud mental es explicada por el ejercicio, la calidad del sueño, la dieta equilibrada y sus interacciones. Esto generalmente se considera un R cuadrado muy alto e indica un buen ajuste del modelo.
Paso 6: Visualizar el Efecto de Interacción
Frecuentemente es útil graficar las interacciones para que estas relaciones sean más fáciles de comprender. Puedes usar la función interact_plot() del paquete jtools. Así se grafica la interacción entre exercise, sleep_quality y balanced_diet:
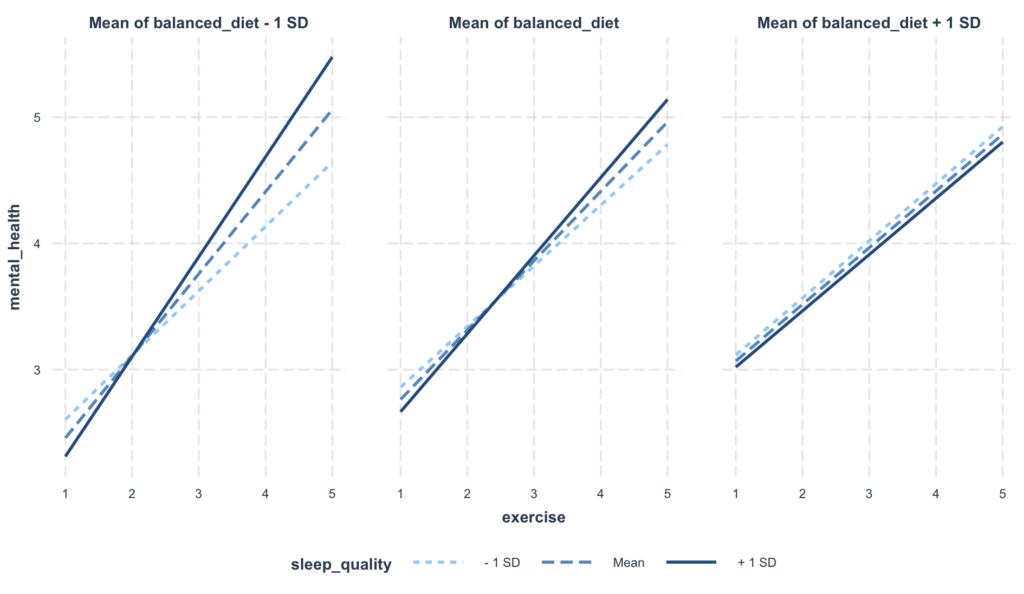
Figura 4: Visualización de efectos de interacción en el análisis de moderación múltiple
Donde:
-
El eje x representa el nivel de ejercicio, con valores que van de menor a mayor.
-
El eje y representa las puntuaciones de salud mental, donde valores más altos indican mejor salud mental.
-
Hay dos líneas, una para dieta equilibrada alta (línea continua) y otra para dieta equilibrada baja (línea discontinua). Estas líneas indican las puntuaciones predichas de salud mental según los niveles de ejercicio y dieta equilibrada.
-
El sombreado alrededor de cada línea representa el intervalo de confianza alrededor de la predicción. Cuando estas áreas sombreadas no se superponen, generalmente indica una diferencia estadísticamente significativa.
-
El gráfico está dividido por niveles de calidad del sueño, indicando que se grafican relaciones separadas para niveles bajo, promedio y alto de calidad del sueño.
De este gráfico, podemos extraer algunas conclusiones preliminares:
-
Para personas con menor calidad de sueño (la faceta izquierda), parece haber poca diferencia en las puntuaciones de salud mental según el nivel de ejercicio o si tienen una dieta equilibrada alta o baja. Esto sugiere que la calidad del sueño podría ser un determinante clave de la salud mental para este grupo, eclipsando los efectos del ejercicio y la dieta.
-
Para personas con calidad de sueño promedio (la faceta central), comenzamos a ver algunas diferencias. Particularmente, los individuos con una dieta equilibrada alta (línea continua) parecen beneficiarse más del ejercicio en términos de puntuaciones de salud mental que aquellos con una dieta equilibrada baja (línea discontinua).
-
Para personas con alta calidad de sueño (la faceta derecha), el ejercicio parece mejorar significativamente la salud mental para aquellos con una dieta equilibrada alta (línea continua). Sin embargo, para aquellos con una dieta equilibrada baja (línea discontinua), el ejercicio no parece conducir a mejoras importantes en la salud mental.
Paso 7: Evaluar los Supuestos y Diagnósticos del Modelo
Dado que el análisis de moderación múltiple se basa en la regresión, verificar los supuestos del modelo es importante para asegurar que los resultados que interpretamos sean válidos. Una violación de estos supuestos puede conducir a resultados inexactos. Específicamente, para nuestro modelo de moderación múltiple, los principales supuestos incluyen:
1. Linealidad y Aditividad
La relación entre predictores (incluyendo los términos de interacción) y la variable de resultado debe ser lineal, y los efectos de los diferentes predictores deben ser aditivos. Esto significa que el efecto de un predictor sobre la variable de resultado no debe cambiar en función del valor de otro predictor, excepto según lo definido por el término de interacción.
Aquí está el código para verificar la linealidad y aditividad en R:
# Verificar linealidad y aditividad
plot(model$fitted.values, model$residuals,
xlab = "Predicted values", ylab = "Residuals")
abline(h = 0, col = "red")
Podemos verificar esto graficando los residuos (la diferencia entre los valores observados y predichos) contra los valores predichos. Un patrón no aleatorio sugeriría una violación del supuesto de linealidad.
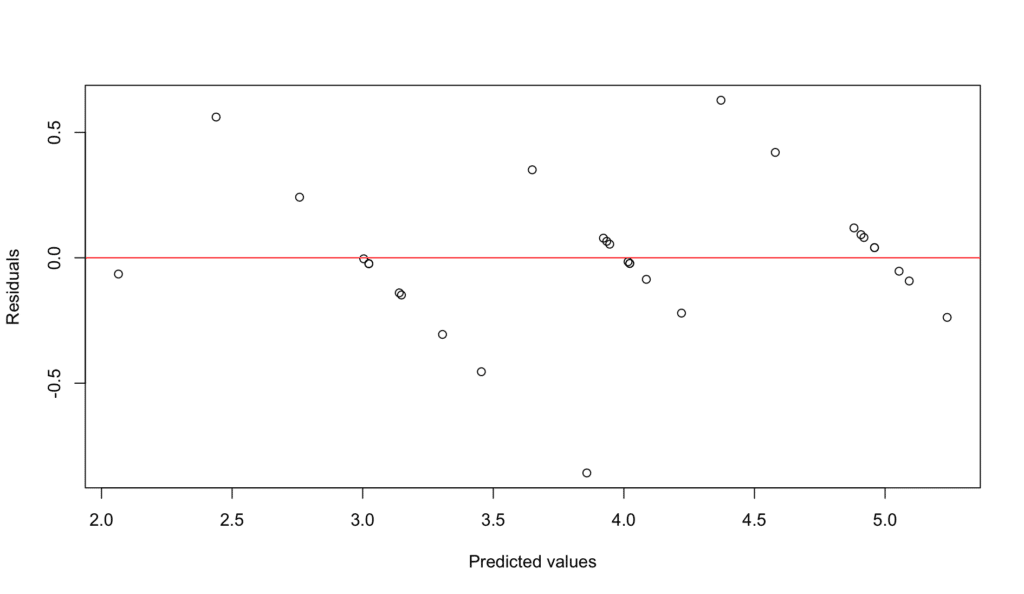
Figura 5: Verificación del supuesto de linealidad - gráfico de residuos vs valores ajustados
2. Independencia de Residuos
Los residuos (errores) del modelo, es decir, las diferencias entre los valores observados y predichos de la variable de resultado, deben ser independientes. Esto implica que el valor del residuo para una observación no debe predecir el valor del residuo de otra.
Podemos verificar este supuesto usando una prueba de Durbin-Watson o creando un gráfico de Función de Autocorrelación (ACF) para datos de series temporales o agrupados. Dado que tenemos datos transversales, este supuesto no es tan relevante.
Sin embargo, si tus datos son de series temporales o datos donde el orden de las observaciones importa, el script a continuación genera un gráfico ACF en R. Ten en cuenta que el paquete forecast debe instalarse y cargarse primero:
# Cargar el paquete
install.packages("forecast")
library(forecast)
# Crear el gráfico ACF
Acf(model$residuals, main="ACF of Model Residuals")
En este gráfico, el eje x representa el rezago, y el eje y representa la autocorrelación en cada rezago. Cada línea vertical (o pico) en el gráfico corresponde a la autocorrelación en ese rezago. Si las líneas cruzan la línea azul discontinua (el límite de significancia), sugiere que los residuos no son independientes en ese rezago.
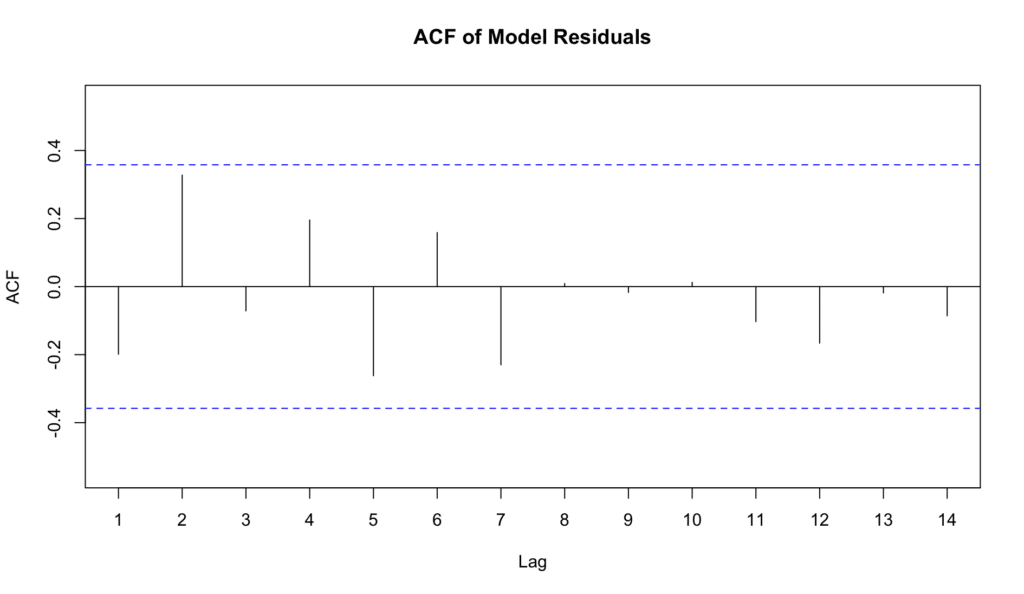
Figura 6: Gráfico ACF para evaluar la independencia de residuos
3. Homocedasticidad
La varianza de los residuos debe ser constante a través de todos los niveles de los predictores. Esto significa que la dispersión de los residuos debe ser aproximadamente la misma para todos los valores de tus predictores.
Aquí está el código para evaluar la homocedasticidad en R:
# Verificar homocedasticidad
plot(model$fitted.values, abs(model$residuals),
xlab = "Predicted values", ylab = "Absolute Residuals")
Podemos verificar esto observando el mismo gráfico de residuos vs valores ajustados que usamos para la linealidad. Si los puntos están dispersos aleatoriamente alrededor de la línea horizontal sin un patrón discernible, el supuesto se cumple.
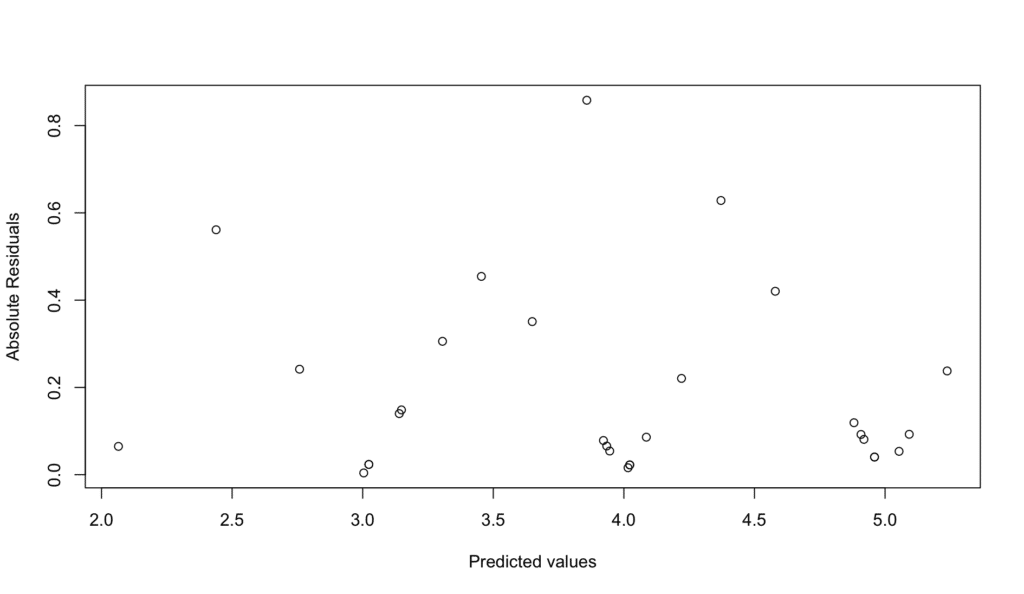
Figura 7: Verificación de homocedasticidad - gráfico de escala-ubicación
4. Normalidad de Errores
Los residuos del modelo deben estar aproximadamente distribuidos de forma normal. Esto significa que si graficamos la frecuencia de los residuos, el gráfico debería formar aproximadamente la forma de una campana.
Para evaluar la normalidad de errores en R, usa el siguiente código:
# Verificar normalidad
qqnorm(model$residuals)
qqline(model$residuals)
Podemos verificar esto creando un gráfico Q-Q. Los puntos deben ubicarse aproximadamente sobre la línea diagonal.
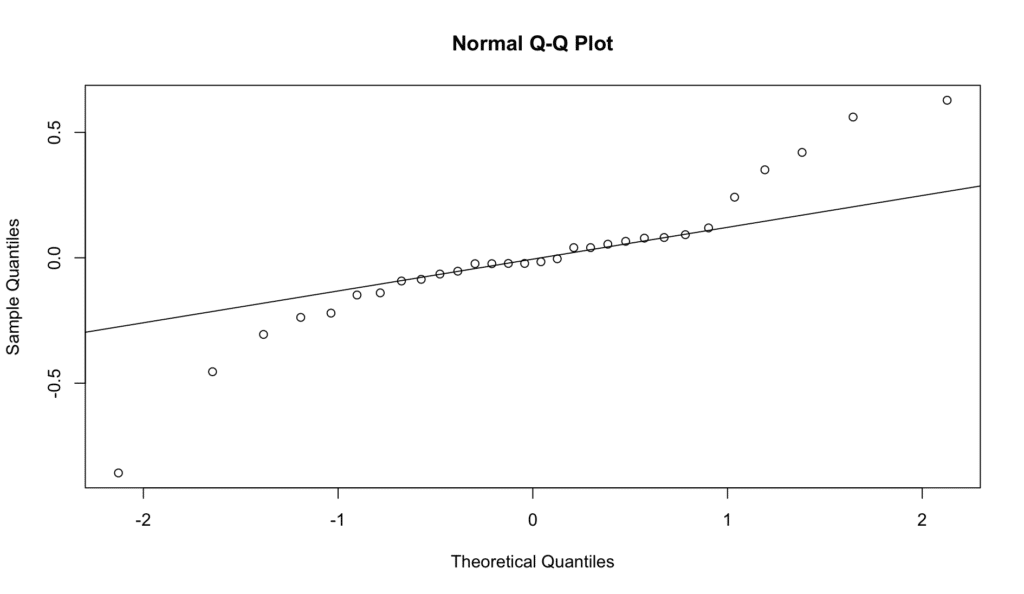
Figura 8: Gráfico Q-Q para evaluar la normalidad de residuos
5. Ausencia de Multicolinealidad
Los predictores en el modelo no deben estar perfectamente correlacionados entre sí. Si existe multicolinealidad perfecta (o incluso alta multicolinealidad), implica que dos o más predictores están proporcionando la misma información sobre la variación en la variable de resultado, dificultando la identificación del efecto independiente de cada predictor.
Podemos verificar la multicolinealidad calculando los Factores de Inflación de Varianza (VIF) para los predictores. Valores de VIF superiores a 5 indican alta multicolinealidad.
Aquí está el código para evaluar el VIF en R:
# Verificar multicolinealidad
library(car)
vif(model)
Los valores de VIF en nuestro resultado sugieren que podría existir multicolinealidad en nuestro conjunto de datos ficticio, ya que valores de VIF mayores a 5 o 10 se utilizan frecuentemente como indicador de alta multicolinealidad. Esto significa que los predictores en nuestro modelo están correlacionados, lo que puede complicar la interpretación del efecto de cada predictor.

Figura 9: Valores VIF para la evaluación de multicolinealidad
Sin embargo, nuestro modelo incluye términos de interacción, que pueden inflar los valores de VIF, así que estos valores altos pueden no necesariamente indicar un problema. Es algo a tener en cuenta, ya que podría influir en la interpretabilidad de los coeficientes de nuestro modelo.
Para este ejercicio educativo, continuaremos con nuestro modelo. En un contexto no educativo, considera abordar la multicolinealidad severa con estrategias como eliminar algunos predictores, combinar predictores correlacionados o usar técnicas de regularización.
NOTA: Para tu información, la multicolinealidad no afecta la capacidad del modelo para predecir la variable dependiente. Solo complica la interpretación de los coeficientes de los predictores. Si el objetivo principal es la predicción y no la interpretación, la multicolinealidad podría no ser una preocupación significativa.
6. Sin Valores Atípicos Influyentes
No debe haber un solo punto de datos que influya innecesariamente en las estimaciones del modelo. Aunque los valores atípicos no son inusuales, los particularmente influyentes pueden distorsionar los resultados del modelo y reducir la precisión de tus predicciones.
Podemos verificar los valores atípicos influyentes usando la distancia de Cook, con un punto de corte comúnmente utilizado de 4/(n-k-1) marcado por una línea roja, donde n es el número de observaciones y k es el número de predictores. Aquí está el script de R para la distancia de Cook:
# Definir el umbral
threshold <- 4/length(cooksd)
# Determinar el rango del eje y
# Aquí usamos 1.1 para asegurar que el valor máximo esté dentro del área del gráfico
yrange <- c(0, max(cooksd, threshold)* 1.1)
# Graficar la distancia de Cook con límites del eje y establecidos manualmente
plot(cooksd, ylim = yrange,
main = "Influential Observations by Cook's distance",
pch = 16)
# Agregar la línea de umbral
abline(h = threshold, col = "red")
Si todas las observaciones están por debajo de la línea roja que representa el umbral en un gráfico de distancia de Cook, indica que no hay valores atípicos particularmente influyentes en los datos, tal como en nuestro caso.
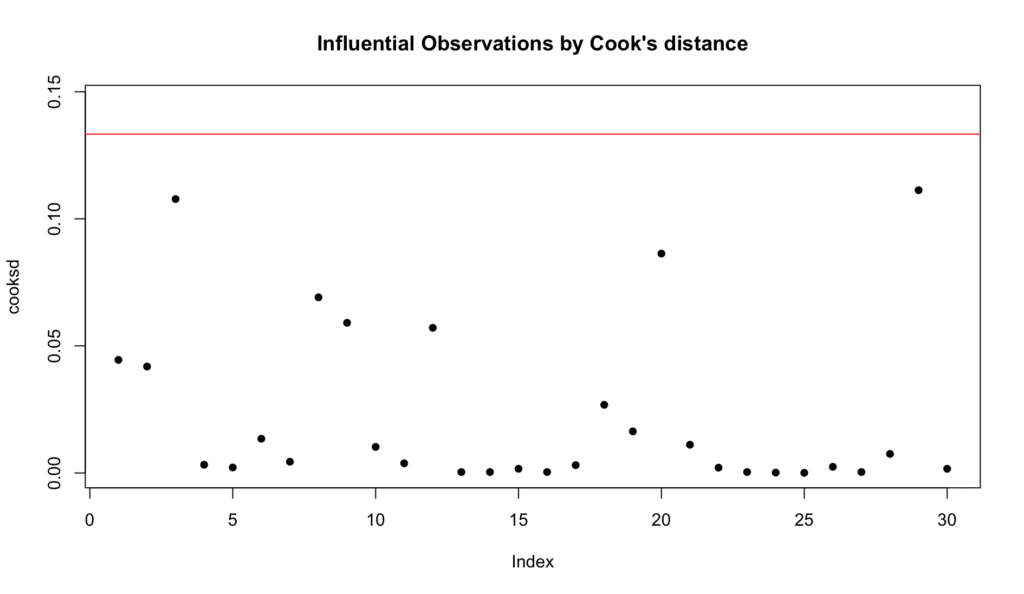
Figura 10: Distancia de Cook para identificar valores atípicos influyentes
Los valores atípicos influyentes pueden distorsionar los resultados del análisis y disminuir la precisión de las predicciones hechas a partir del modelo. Por lo tanto, encontrar que no existen tales valores atípicos influyentes ayuda a asegurar la validez y robustez de los resultados del análisis de moderación.
Y aquí está tu bonus por leer y practicar con nosotros hasta este punto: un script de R que resume los cuatro gráficos diagnósticos generados por la función plot() anterior y los guarda en un PDF llamado "model_diagnostic_plots.pdf" en tu directorio de trabajo.
# Abrir el archivo PDF
pdf("model_diagnostic_plots.pdf")
# Crear gráficos diagnósticos
par(mfrow = c(2, 2))
plot(model)
# Cerrar el archivo PDF
dev.off()
Y aquí está la salida:
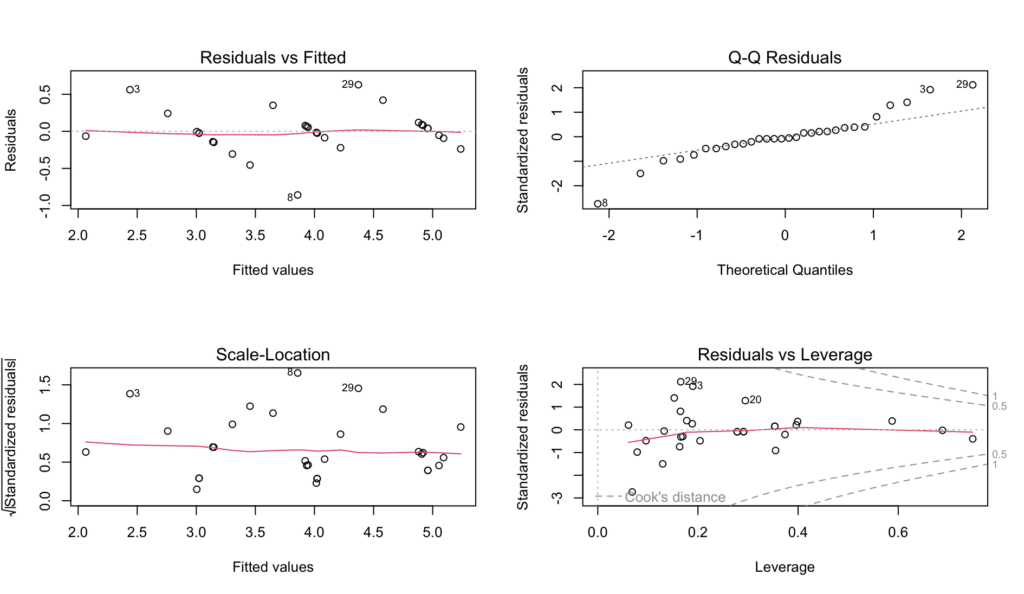
Figura 11: Panel completo de gráficos diagnósticos generado por la función plot()
Paso 8: Reportar y Discutir el Análisis de Moderación Múltiple en Tu Estudio
Ahora que concluimos nuestro análisis, es momento de aprender cómo reportar y discutir los hallazgos en tu trabajo de investigación. Así debería verse:
IMPORTANTE: al reportar y discutir resultados en un trabajo de investigación, hay algunas pautas generales a seguir:
-
Usa Tiempo Pasado: Dado que la investigación ya se realizó y los resultados se obtuvieron, es estándar usar el tiempo pasado al discutirlos.
-
Evita Pronombres Personales: El uso de pronombres personales (yo, nosotros, tú) típicamente se desaconseja en la escritura académica. En su lugar, intenta escribir en un tono más objetivo y formal.
-
Sé Claro y Conciso: Es importante expresar tus hallazgos de forma clara y concisa.
-
Evita Certeza Absoluta: Los hallazgos científicos rara vez, si acaso, son absolutos. Por lo tanto, evita usar "prueba" o "confirma" en tus discusiones. Usa términos como "sugiere", "indica" o "respalda".
-
Usa Figuras y Tablas Apropiadamente: Las figuras, tablas y otras representaciones visuales de datos pueden ayudar enormemente a comprender tus resultados.
-
Discute en el Contexto de la Literatura: Al discutir tus resultados, es importante relacionarlos con investigaciones previas en el campo. Esto ayuda a ubicar tus hallazgos en contexto y muestra cómo contribuyen al cuerpo de conocimiento más amplio.
-
Considera las Limitaciones: Todo estudio tiene limitaciones, y es crucial reconocerlas. Esto no solo añade credibilidad a tu trabajo, sino que también proporciona caminos para investigación futura.
-
Aborda las Hipótesis: Después de reportar tus hallazgos, discute cómo se relacionan con tus hipótesis iniciales. Ya sea que tus datos respalden o contradigan tus hipótesis, esta discusión es clave para cerrar el ciclo de tu pregunta de investigación.
Ejemplo de Sección de Resultados:
En el estudio realizado, se examinó el efecto del ejercicio físico (exercise) sobre la salud mental (mental_health), teniendo en cuenta los roles moderadores potenciales de la calidad del sueño (sleep_quality) y una dieta equilibrada (balanced_diet). El método elegido fue un análisis de moderación múltiple, empleando un modelo de regresión de mínimos cuadrados ordinarios (OLS). Los factores de inflación de varianza (VIF), habiendo permanecido por debajo del umbral común de 10 después de centrar los predictores, sugirieron que la multicolinealidad fue gestionada efectivamente. La independencia de errores se verificó usando el estadístico de Durbin-Watson, que cayó dentro del rango aceptable (1.5 a 2.5). Un gráfico de función de autocorrelación (ACF) fue inspeccionado visualmente para verificar aún más este supuesto. Los residuos fueron examinados para normalidad y homocedasticidad. Un gráfico Q-Q confirmó la distribución normal de los residuos. La inspección del gráfico de residuos vs. valores ajustados no reveló ningún patrón aparente, implicando que el supuesto de homocedasticidad se cumplió. Los valores atípicos influyentes se verificaron usando la Distancia de Cook. Todos los puntos de datos se encontraron por debajo del umbral (1.00), implicando la ausencia de cualquier valor atípico excesivamente influyente. El modelo de moderación múltiple explicó una proporción significativa de la varianza en salud mental, R² = .9027, F(7, 22) = 29.16, p menor a 0.001. Los predictores individuales, a saber, exercise, sleep_quality y balanced_diet, no predijeron significativamente la salud mental. No obstante, los términos de interacción estuvieron significativamente asociados con los resultados de salud mental. El efecto de interacción triple entre exercise, sleep_quality y balanced_diet no fue significativo (B = -0.03971, p = 0.2464), indicando que sleep_quality y balanced_diet combinados no moderaron significativamente la relación entre exercise y mental health. La interpretación adicional de los términos de interacción de dos vías sugirió un efecto moderador significativo de sleep_quality sobre la relación entre exercise y mental health (B = 0.17452, p = 0.0887). Por el contrario, balanced_diet no demostró un efecto moderador significativo ni con exercise (B = 0.05188, p = 0.6160) ni con sleep_quality (B = 0.06690, p = 0.5713). Estos resultados deben interpretarse con cautela, dado el tamaño pequeño de la muestra y la naturaleza preliminar de este análisis. Una comprensión integral de las relaciones complejas entre estas variables puede requerir investigación adicional.
Finalmente, recuerda que este análisis se realizó con un conjunto de datos construido con fines educativos. En consecuencia, controles estadísticos más complejos pueden ser necesarios, y diferentes resultados pueden obtenerse con conjuntos de datos del mundo real.
Preguntas Frecuentes
Próximos Pasos
Si completaste este tutorial sobre moderación múltiple en R, hay dos caminos naturales para continuar tu aprendizaje:
-
Explora nuestro tutorial sobre Análisis de Mediación en R para comprender el "cómo" y "por qué" de las relaciones entre variables, complementando el "cuándo" y "para quién" que revela el análisis de moderación.
-
Consulta nuestra guía sobre Moderador vs Mediador para consolidar las diferencias conceptuales entre ambos enfoques analíticos y saber cuándo aplicar cada uno en tu investigación.
Referencias
Cohen, J., Cohen, P., West, S. G., & Aiken, L. S. (2003). Applied multiple regression/correlation analysis for the behavioral sciences (3rd ed.). Lawrence Erlbaum Associates.
Aiken, L. S., & West, S. G. (1991). Multiple regression: Testing and interpreting interactions. Sage Publications.
Hayes, A. F. (2022). Introduction to mediation, moderation, and conditional process analysis: A regression-based approach (3rd ed.). Guilford Press.