Aprender a efectuar un análisis de moderación en R es esencial para comprender las relaciones condicionales en tus datos de investigación. Esta guía completa te muestra cómo realizar un análisis de moderación usando una sola variable moderadora, interpretar los efectos de moderación, construir modelos de moderación y validar los supuestos del análisis de moderación con ejemplos paso a paso y datos reales.
Ya sea que necesites entender cómo una variable moderadora cambia la relación entre variables, probar los efectos de moderación en tus modelos de regresión, o aprender cómo hacer un análisis de moderación desde la preparación de datos hasta el reporte de resultados, este tutorial cubre todo lo que necesitas. Exploraremos el análisis de moderación en R usando los paquetes lmtest, car e interactions para realizar un análisis completo de moderación.
Esta guía te enseña los fundamentos de la moderación en R, cómo interpretar los efectos de moderación, evaluar el ajuste de tu modelo de moderación y reportar hallazgos siguiendo las directrices APA. Dominarás la verificación de supuestos del análisis de moderación, la visualización de efectos de interacción y la comprensión de cuándo las variables moderadoras influyen significativamente en los resultados de tu investigación.
Sin embargo, si trabajas con múltiples moderadores, consulta nuestra guía completa sobre cómo efectuar análisis de moderación múltiple en R.
¿Qué es el análisis de moderación?
El análisis de moderación es un método analítico utilizado frecuentemente en la investigación estadística para examinar los efectos condicionales de una variable independiente sobre una variable dependiente. En términos más simples, evalúa cómo una tercera variable, conocida como moderador, altera la relación entre la causa (variable independiente) y el resultado (variable dependiente).
En el lenguaje de la estadística, esta relación puede describirse usando una ecuación de regresión múltiple moderada:
Donde:
-
Y representa la variable dependiente
-
X es la variable independiente
-
Z simboliza la variable moderadora
-
β0, β1, β2 y β3 denotan los coeficientes que representan el intercepto, el efecto de la variable independiente, el efecto del moderador y el efecto de interacción entre la variable independiente y el moderador respectivamente
-
ε representa el término de error
En el análisis de moderación, el componente clave es el término de interacción (β3*XZ). Si el coeficiente β3 es estadísticamente significativo (valor p menor a 0.05), indica la presencia de un efecto de moderación.
El valor del análisis de moderación radica en su capacidad para revelar relaciones condicionales. En lugar de preguntar "¿X afecta a Y?", preguntamos "¿La relación X→Y depende de Z?" Esto nos ayuda a entender bajo qué condiciones o para quién ocurren los efectos.
Supuestos del análisis de moderación
Se deben cumplir varios supuestos al realizar un análisis de moderación. Estos supuestos son similares a los de la regresión lineal múltiple, dado que el análisis de moderación típicamente involucra una regresión múltiple donde se incluye un término de interacción. Los principales supuestos son:
-
Linealidad: La relación entre cada predictor (variable independiente y moderador) y el resultado (variable dependiente) es lineal. Este supuesto puede verificarse visualmente usando gráficos de dispersión que generaremos y explicaremos en detalle en este artículo.
-
Independencia de las observaciones: Se asume que las observaciones son independientes entre sí. Esto es más un aspecto del diseño del estudio que algo que pueda probarse directamente. Si tus datos son series temporales o datos agrupados, es probable que este supuesto se viole.
-
Homocedasticidad: Se refiere al supuesto de que la varianza de los errores es constante en todos los niveles de las variables independientes. En otras palabras, la dispersión de los residuos debería ser aproximadamente igual en todos los valores predichos. Esto puede verificarse observando un gráfico de residuos versus valores predichos.
-
Normalidad de los residuos: Se asume que los residuos (errores) siguen una distribución normal. Esto puede verificarse usando un gráfico Q-Q.
-
Ausencia de multicolinealidad: La variable independiente y el moderador no deben estar altamente correlacionados. Una alta correlación (multicolinealidad) puede inflar la varianza de los coeficientes de regresión y hacer las estimaciones muy sensibles a cambios menores en el modelo. El factor de inflación de la varianza (VIF) se usa frecuentemente para verificar la multicolinealidad.
-
Ausencia de casos influyentes: El análisis no debe estar excesivamente influenciado por una sola observación. La distancia de Cook puede usarse para verificar casos influyentes que podrían afectar indebidamente la estimación de los coeficientes de regresión.
Formulación del modelo de moderación
Supongamos que buscamos responder la siguiente pregunta de investigación:
"¿Cómo varía la relación entre el consumo de café (medido por el número de tazas consumidas) y la productividad laboral según la tolerancia individual a la cafeína?"
Por lo tanto, podemos formular la siguiente hipótesis:
"El nivel de tolerancia a la cafeína de un individuo modera la relación entre el consumo de café y la productividad."
Lo que esencialmente intentamos responder con esta hipótesis es si el impacto del consumo de café sobre la productividad es el mismo para todos los individuos, o si cambia según su tolerancia a la cafeína. En otras palabras, investigamos si los beneficios (o desventajas) de productividad del café son iguales para todos, o si difieren según qué tan tolerante sea una persona a la cafeína.
Por lo tanto, nuestro estudio consiste en las siguientes variables: consumo de café (variable independiente), productividad (variable dependiente) y tolerancia a la cafeína (el moderador).
El siguiente diagrama explica el tipo de variables en nuestro estudio y la relación entre ellas en el contexto del análisis de moderación:
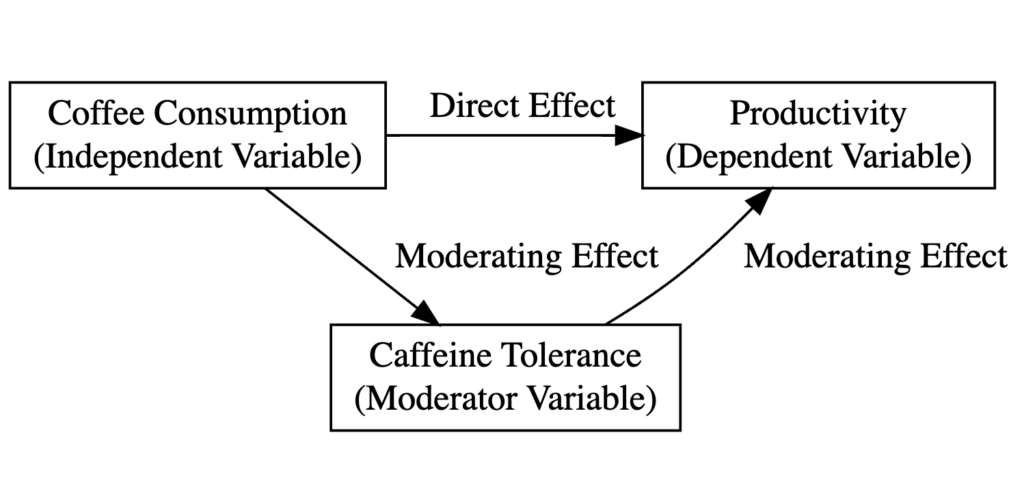
Figura 1: Diagrama del modelo de moderación ilustrando la relación entre consumo de café (X), productividad (Y) y tolerancia a la cafeína (moderador).
Donde:
-
Consumo de café (Tazas) es la variable independiente.
-
Productividad laboral (Productividad) es la variable dependiente.
-
Tolerancia individual a la cafeína (Tolerancia) es la variable moderadora.
-
El efecto directo muestra cómo el consumo de café impacta la productividad en general.
-
El efecto moderador (interacción) muestra si esta relación difiere según los niveles de tolerancia a la cafeína. Si es significativo, significa que la relación café-productividad es más fuerte (o más débil) para personas con alta vs. baja tolerancia a la cafeína.
Cómo efectuar el análisis de moderación en R
Ahora que hemos cubierto suficiente base teórica, es momento de aprender a efectuar el análisis de moderación en R. Esperamos que ya tengas R/RStudio funcionando, pero si no, aquí tienes una guía rápida sobre cómo instalar R y RStudio en tu computadora.
Continuaremos con el ejemplo del "café" mencionado anteriormente para esta lección. Recuerda, planteamos la hipótesis de que el nivel de tolerancia a la cafeína de un individuo modera la relación entre el consumo de café y la productividad.
Paso 1: Instalar y cargar los paquetes necesarios en R
R ofrece muchos paquetes que facilitan el análisis de moderación. En nuestro caso, usaremos cuatro paquetes: lmtest, car, interactions y ggplot2. A continuación la descripción de cada paquete y su propósito:
-
lmtest: El paquete
lmtestproporciona herramientas para la verificación diagnóstica en modelos de regresión lineal, que son esenciales para asegurar que nuestro modelo satisface los supuestos clave. Este paquete puede realizar pruebas de Wald, F y razón de verosimilitud. En el contexto del análisis de moderación, puedes usarlmtestpara verificar la heterocedasticidad (varianza no constante de los errores), entre otras cosas. -
car: El paquete
car(Companion to Applied Regression) es otra herramienta para diagnósticos de regresión e incluye funciones para el cálculo del factor de inflación de la varianza (VIF), que puede ayudar a detectar problemas de multicolinealidad (cuando las variables independientes están altamente correlacionadas entre sí). La multicolinealidad puede causar problemas en la estimación de los coeficientes de regresión y sus errores estándar. -
interactions: El paquete
interactionsse usa para crear visualizaciones y análisis de pendientes simples de los términos de interacción en modelos de regresión. Puede producir varios tipos de gráficos para ayudar a visualizar el efecto de moderación y cómo cambia la relación entre la variable independiente y la variable dependiente en diferentes niveles del moderador. -
ggplot2: El paquete
ggplot2es uno de los más populares para la visualización de datos en R. En el análisis de moderación,ggplot2puede usarse para crear gráficos de dispersión, gráficos de líneas y otras visualizaciones que te ayuden a comprender mejor tus datos y las relaciones entre variables. Adicionalmente, puede ayudar a visualizar el efecto de moderación, es decir, cómo el efecto de una variable independiente sobre una variable dependiente cambia a través de los niveles de la variable moderadora.
Podemos instalar los paquetes listados anteriormente de una sola vez copiando y pegando el siguiente comando en la consola de R:
install.packages("lmtest")
install.packages("car")
install.packages("interactions")
install.packages("ggplot2")
Una vez instalados, carga los paquetes en la sesión de R:
library(lmtest)
library(car)
library(interactions)
library(ggplot2)
Paso 2: Importar los datos
Para facilitar tu aprendizaje sobre cómo efectuar el análisis de moderación en R, puedes descargar el conjunto de datos de práctica desde la barra lateral: un conjunto de datos con 30 encuestados que contiene puntuaciones para las variables de nuestro estudio: consumo de café (Cups), tolerancia a la cafeína (Tolerance) y productividad (Productivity).
Si tu conjunto de datos no es muy grande, puedes insertar los datos manualmente en R en forma de data frame de la siguiente manera:
data <- data.frame(
Respondent = 1:30,
Cups = c(2, 4, 1, 3, 2, 3, 1, 2, 2, 4, 2, 3, 1, 3, 3, 2, 2, 4, 1, 3, 2, 3, 1, 2, 2, 4, 2, 3, 1, 3),
Tolerance = c(7, 5, 6, 7, 8, 6, 7, 7, 6, 8, 7, 7, 6, 7, 8, 6, 7, 5, 6, 7, 8, 6, 7, 7, 6, 8, 7, 7, 6, 7),
Productivity = c(5, 6, 4, 6, 7, 7, 4, 6, 5, 7, 5, 6, 4, 6, 7, 5, 5, 6, 4, 6, 7, 7, 4, 6, 5, 7, 5, 6, 4, 6)
)
IMPORTANTE: Este conjunto de datos solo puede usarse con fines educativos porque contiene valores aleatorios y puede no reflejar un escenario del mundo real. "Cups" (variable independiente) refleja el número de tazas de café consumidas por día, "Tolerance" (variable moderadora) es una puntuación sobre 10 que refleja qué tan bien el individuo tolera la cafeína, y "Productivity" (variable dependiente) es una puntuación sobre 10 que indica el nivel de productividad del individuo.
Paso 3: Ajustar el modelo de regresión múltiple moderada
Para ajustar un modelo de regresión múltiple moderada, usaremos la función lm() en R. Nota que data es nuestro data frame y Cups, Tolerance y Productivity son columnas en ese data frame.
model <- lm(Productivity ~ Cups*Tolerance, data)
summary(model)
Este comando mostrará el resumen del modelo incluyendo un análisis detallado del ajuste del modelo y la significancia de cada término, como vemos en la captura a continuación:
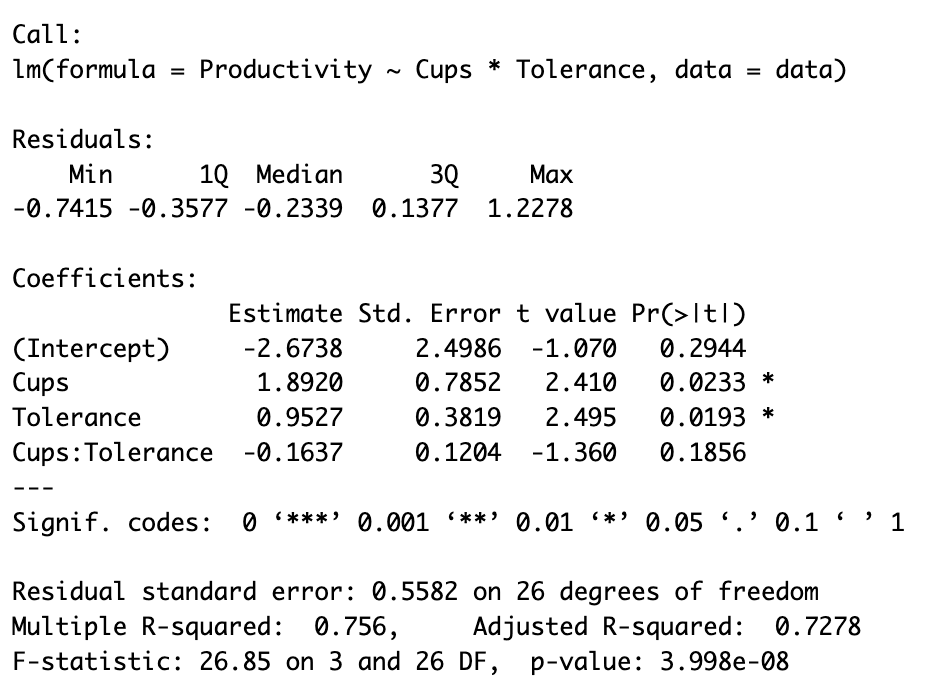
Figura 2: Salida de R mostrando los resultados de la regresión múltiple moderada con el coeficiente del término de interacción (Cups:Tolerance) y niveles de significancia.
Paso 4: Interpretar el efecto de moderación
La salida de lm() proporciona la información clave para interpretar la moderación. Enfócate en estos coeficientes:
- Cups: Efecto positivo (1.8920, p menor a 0.05) - el consumo de café aumenta la productividad
- Tolerance: Efecto positivo (0.9527, p menor a 0.05) - mayor tolerancia a la cafeína aumenta la productividad
- Cups:Tolerance: El término de interacción (-0.1637, p > 0.05) - no estadísticamente significativo
Dado que el valor p de la interacción excede 0.05, concluimos que no hay un efecto de moderación significativo. La relación entre café y productividad no depende de manera significativa de la tolerancia a la cafeína en esta muestra.
Desempeño del modelo:
- R² = 0.756: El modelo explica el 75.6% de la varianza en productividad
- R² ajustado = 0.728: Se mantiene alto después de ajustar por predictores
- Estadístico F (p menor a 0.001): El modelo general es estadísticamente significativo
Paso 5: Visualizar el efecto de interacción
Podemos generar fácilmente un gráfico para visualizar el efecto de interacción usando la función interact_plot en R con el siguiente código:
`interactions::interact_plot(model, pred = Cups, modx = Tolerance)`
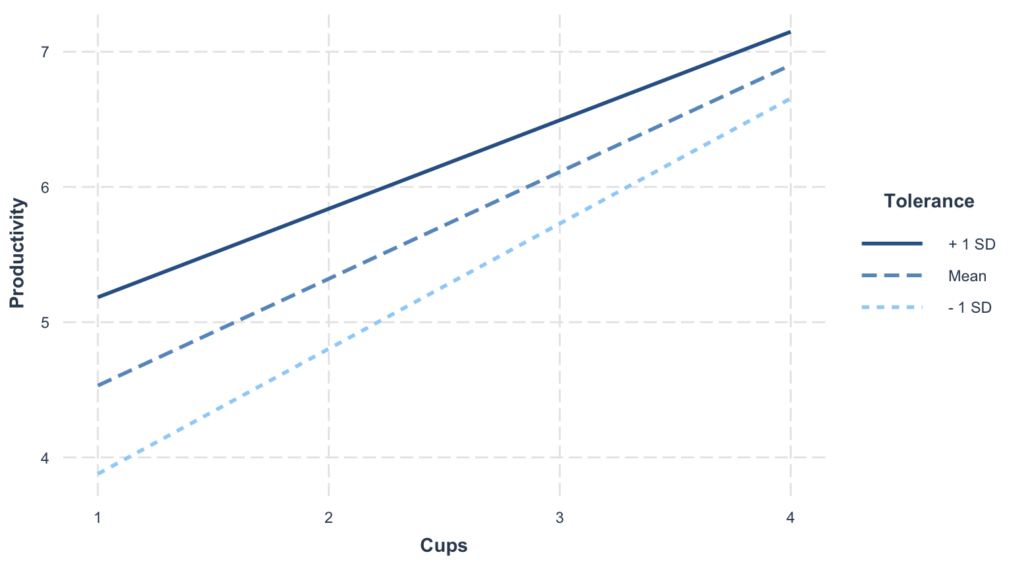
Figura 3: Gráfico de interacción visualizando el efecto moderador de la tolerancia a la cafeína sobre la relación entre consumo de café y productividad.
Este gráfico muestra cómo la relación café-productividad cambia en diferentes niveles de tolerancia. Cada línea representa un nivel diferente del moderador (baja, media, alta tolerancia).
Interpretación clave:
- Líneas no paralelas = Existe moderación (el efecto del café depende de la tolerancia)
- Líneas paralelas = No hay moderación (el efecto del café es el mismo sin importar la tolerancia)
- Bandas de confianza muestran la incertidumbre alrededor de cada pendiente
Paso 6: Evaluar los supuestos y diagnósticos del modelo
Antes de confiar en nuestros resultados, debemos verificar los supuestos de la regresión: linealidad, independencia, homocedasticidad, normalidad y ausencia de multicolinealidad. También verificaremos la presencia de valores atípicos y observaciones influyentes que podrían distorsionar nuestros hallazgos.
1. Linealidad y aditividad
Grafica los residuos contra los valores ajustados. Una dispersión aleatoria alrededor de cero indica que se cumple la linealidad.
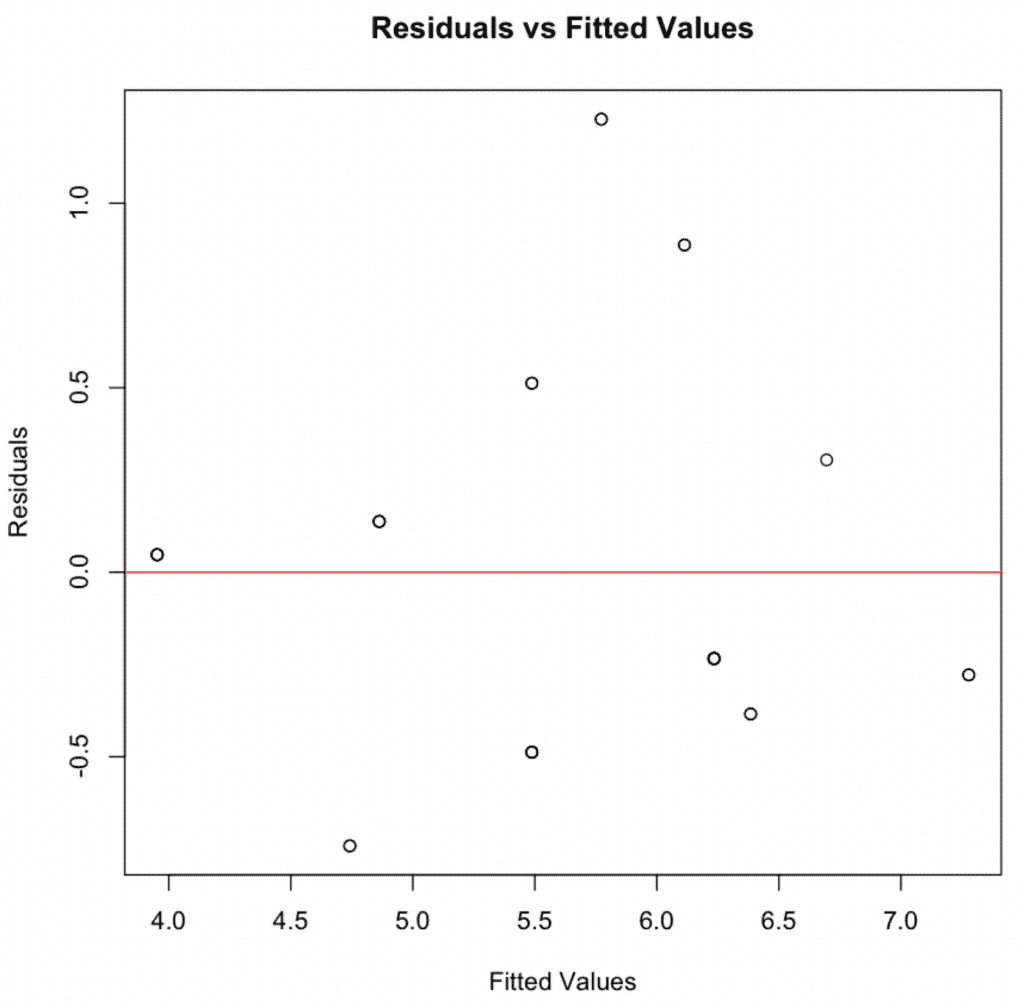
Figura 4: Gráfico de residuos vs. valores ajustados demostrando que se cumple el supuesto de linealidad con un patrón de dispersión aleatorio.
2. Independencia de los residuos
La prueba de Durbin-Watson detecta autocorrelación en los residuos:
`print(dwtest(model))`
Durbin-Watson = 1.9833 (cercano a 2), valor p = 0.5468 → No hay autocorrelación. Se cumple el supuesto de independencia.

Figura 5: Salida de la prueba Durbin-Watson mostrando DW = 1.9833, confirmando el supuesto de independencia de los residuos.
3. Homocedasticidad
Verifica la igualdad de varianza de los residuos a través de los valores ajustados:
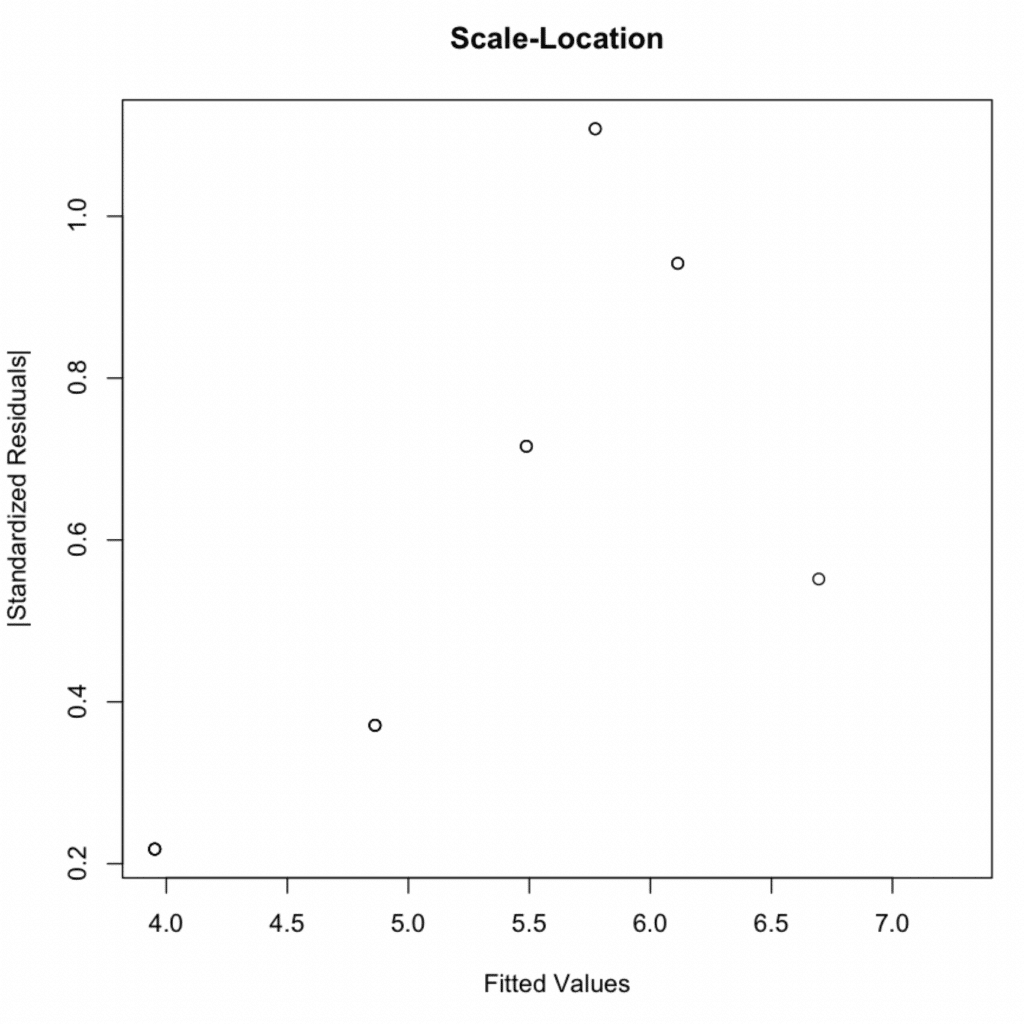
Figura 6: Gráfico diagnóstico Scale-Location demostrando homocedasticidad con varianza constante a través de los valores ajustados.
Confirma con la prueba de Breusch-Pagan:
`print(bptest(model))`

Figura 7: Salida de la prueba Breusch-Pagan con valor p = 0.2488, confirmando que se cumple el supuesto de igualdad de varianza.
Valor p = 0.2488 > 0.05 → Se cumple el supuesto de homocedasticidad.
4. Normalidad de los residuos
Usa un gráfico Q-Q para verificar si los residuos siguen una distribución normal. Los puntos deben estar sobre la línea diagonal.
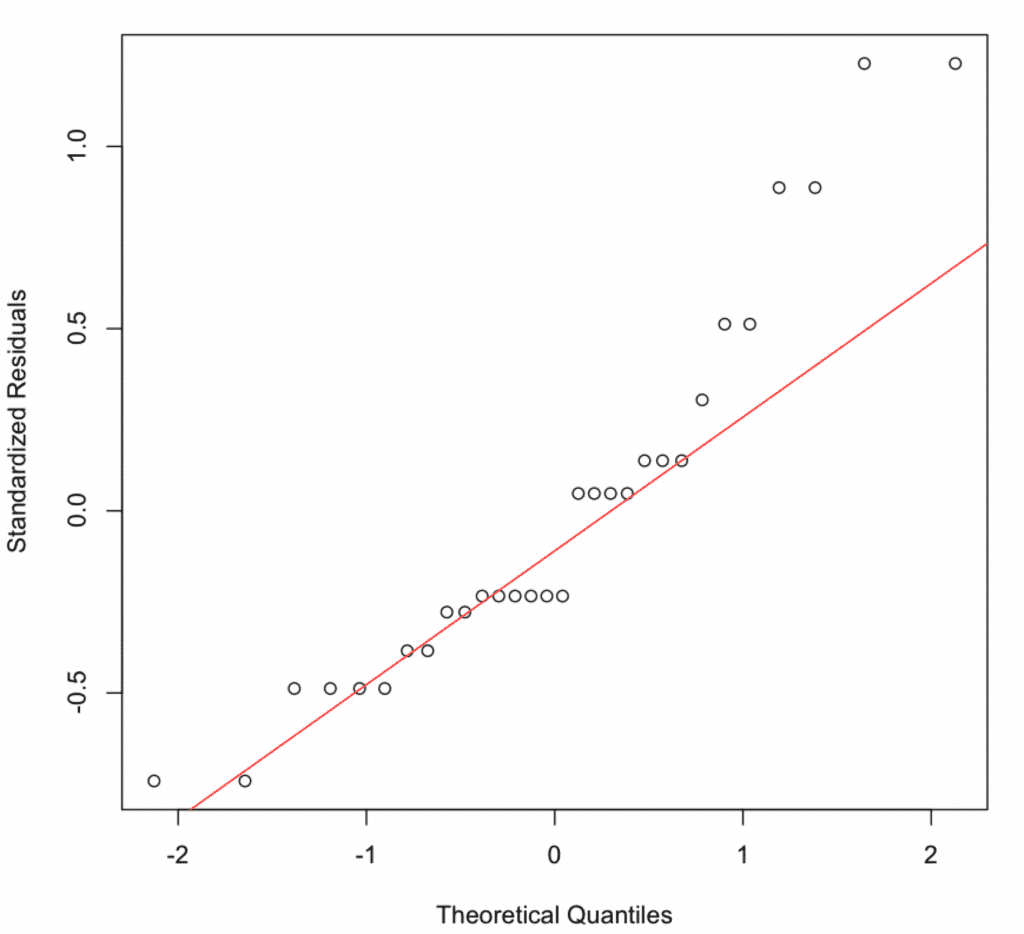
Figura 8: Gráfico Q-Q normal mostrando residuos parcialmente siguiendo la línea diagonal con ligeras desviaciones en las colas.
El gráfico Q-Q muestra ligeras desviaciones. Confirma con la prueba de Shapiro-Wilk:
`shapiro.test(resid(model))`

Figura 9: Salida de la prueba Shapiro-Wilk mostrando valor p = 0.0088, indicando una ligera desviación de la normalidad perfecta.
Valor p = 0.0088 menor a 0.05 indica que los residuos no están perfectamente distribuidos normalmente. Sin embargo, con muestras pequeñas (n=30), esta prueba es altamente sensible a desviaciones menores. El gráfico Q-Q muestra solo ligeras desviaciones, y la regresión es robusta ante violaciones moderadas de normalidad gracias al Teorema del Límite Central.
5. Multicolinealidad
Verifica la multicolinealidad usando el factor de inflación de la varianza (VIF). VIF mayor a 10 indica alta multicolinealidad.
`print(vif(model))`

Figura 10: Salida de VIF mostrando la alta multicolinealidad esperada debido al término de interacción en el análisis de moderación.
Valores de VIF: Cups = 53.36, Tolerance = 9.30, Cups:Tolerance = 65.12. Estos valores altos son esperados y aceptables en el análisis de moderación. Los términos de interacción están por definición correlacionados con sus variables componentes. Para reducir el VIF, centra las variables antes de crear el término de interacción (resta la media de cada valor).
6. Valores atípicos y observaciones influyentes
Detecta valores atípicos usando la prueba de Bonferroni para valores atípicos:
`print(outlierTest(model))`

Figura 11: Salida de la prueba de Bonferroni para valores atípicos indicando que no hay valores atípicos estadísticamente significativos después de la corrección por pruebas múltiples.
La observación 6 tiene el residuo más grande (2.517), pero el valor p de Bonferroni = 0.559 > 0.05 → No se detectaron valores atípicos significativos.
Verifica las observaciones influyentes usando la distancia de Cook:
# Observaciones influyentes
influence <- influence.measures(model)
# Imprimir valores de distancia de Cook para cada observación
print(influence$is.inf)
# Graficar la distancia de Cook
plot(influence$infmat[, "cook.d"],
main = "Cook's distance plot",
ylab = "Cook's distance",
ylim = c(0, max(1, max(influence$infmat[, "cook.d"]))))
# Agregar línea de referencia para distancia de Cook = 1
abline(h = 1, col = "red")
Los valores de distancia de Cook superiores a 1 indican observaciones altamente influyentes.

Figura 12: Medidas de influencia de la distancia de Cook para el análisis de moderación en R.
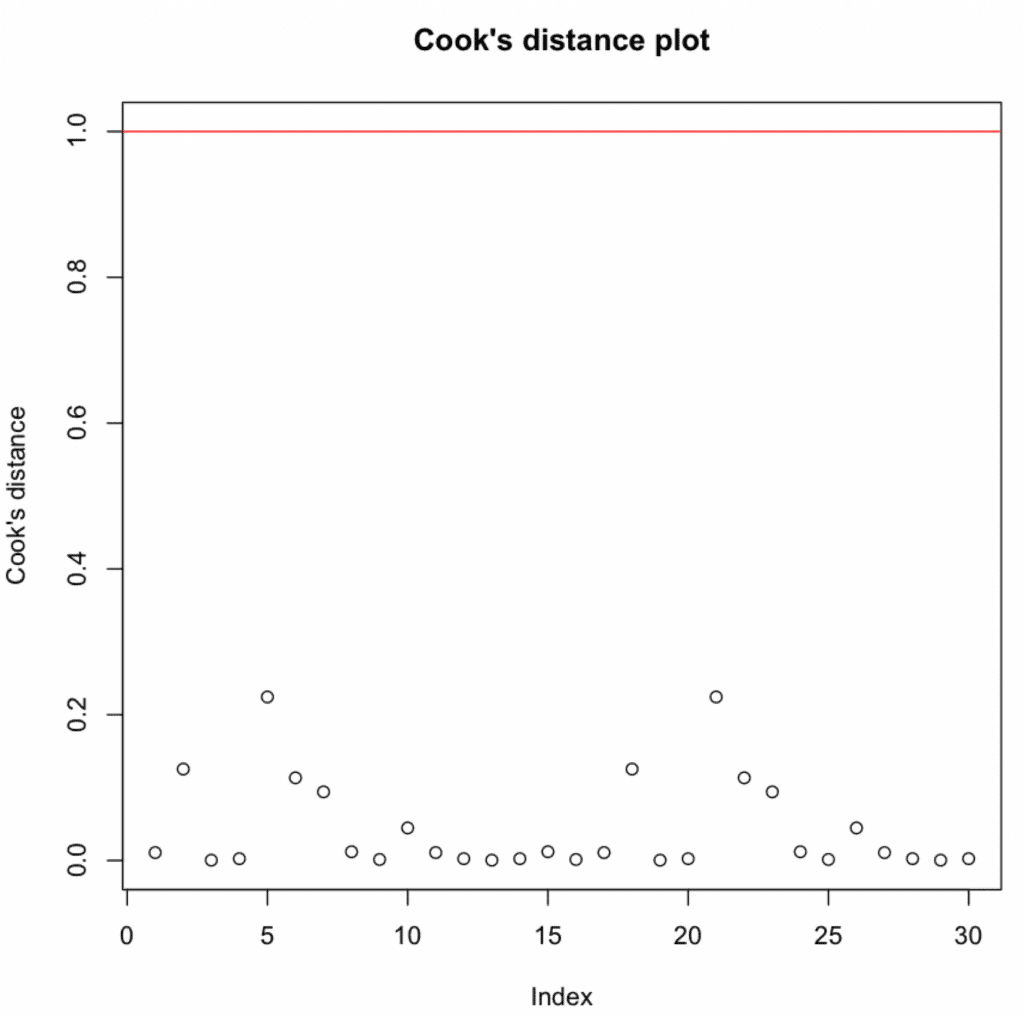
Figura 13: Gráfico de distancia de Cook mostrando todas las observaciones por debajo del umbral de 1.
Todos los valores están por debajo de 1 → No se detectaron observaciones influyentes.
Exportar gráficos diagnósticos a PDF:
# Ajustar el modelo
model <- lm(Productivity ~ Cups*Tolerance, data = data)
# Gráficos diagnósticos
par(mfrow = c(2, 2), oma = c(0, 0, 2, 0))
plot(model, las = 1)
mtext("Diagnostic Plots", outer = TRUE, line = -1, cex = 1.5)
# Guardar los gráficos como archivo PDF
pdf("Diagnostic_Plots.pdf")
par(mfrow = c(2, 2), oma = c(0, 0, 2, 0))
plot(model, las = 1)
mtext("Diagnostic Plots", outer = TRUE, line = -1, cex = 1.5)
dev.off()
El script anterior ajusta el modelo, crea cuatro gráficos diagnósticos relevantes y luego guarda estos gráficos como un archivo PDF llamado "Diagnostic_Plots.pdf". Estos gráficos diagnósticos nos ayudan a verificar los supuestos de linealidad, independencia, homocedasticidad y ausencia de observaciones influyentes, respectivamente.
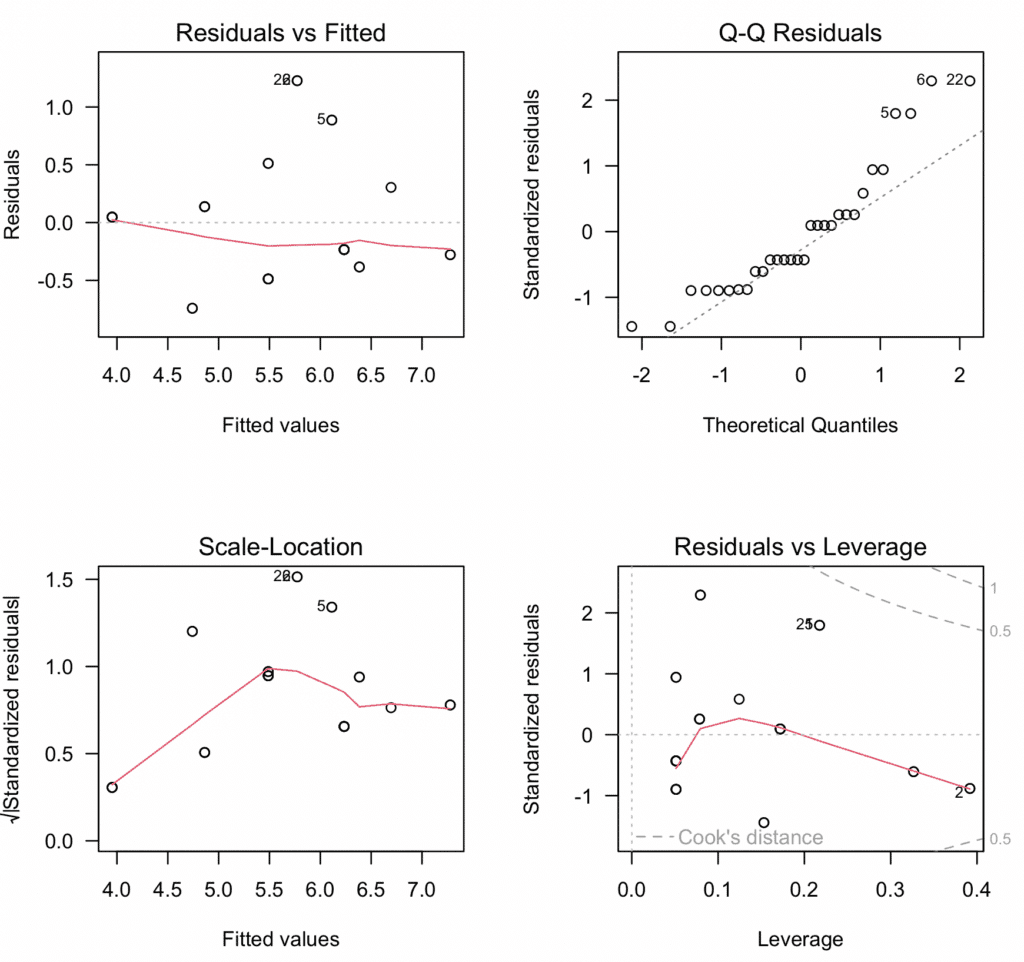
Figura 14: Gráfico diagnóstico completo de cuatro paneles para el análisis de moderación mostrando todas las pruebas de supuestos en una sola visualización.
Paso 7: Reportar los resultados
Finalmente, es momento de resumir nuestros hallazgos y reportar los resultados del análisis de moderación que realizamos en R de la siguiente manera:
En nuestro análisis de moderación en R, buscamos investigar el efecto de la ingesta de cafeína (medida por el número de tazas de café consumidas) y la tolerancia al estrés sobre la productividad, considerando también el potencial efecto moderador de la tolerancia al estrés sobre la relación entre la ingesta de cafeína y la productividad. Esto se logró mediante un modelo de regresión múltiple, especificado con un término de interacción para tazas de café y tolerancia al estrés.
El modelo ajustado proporcionó información valiosa sobre las relaciones hipotetizadas. El término de interacción (Cups*Tolerance) no fue estadísticamente significativo (p > 0.05), sugiriendo que no hay un efecto de moderación significativo de la tolerancia a la cafeína sobre la relación entre el consumo de café y la productividad en esta muestra. Esto implica que el efecto del café sobre la productividad no difiere significativamente según el nivel de tolerancia a la cafeína de un individuo, al menos no en este conjunto de datos.
Un análisis adicional de los supuestos y diagnósticos del modelo reveló que el modelo es un ajuste adecuado para nuestros datos:
-
Linealidad y aditividad: El gráfico de residuos vs valores ajustados indicó que la relación era lineal y aditiva, sin patrones discernibles ni desviaciones de la media cero.
-
Independencia de los residuos: La prueba de Durbin-Watson resultó en un estadístico de 1.9833 (valor p = 0.5468), indicando que no hay evidencia de autocorrelación en los residuos.
-
Homocedasticidad: El gráfico Scale-Location y la prueba de Breusch-Pagan (valor p = 0.2488) confirmaron el supuesto de varianza igual (homocedasticidad) de los residuos.
-
Normalidad de los residuos: La prueba de Shapiro-Wilk indicó que los residuos no seguían una distribución perfectamente normal (valor p = 0.0088 menor a 0.05). Sin embargo, dado el tamaño pequeño de la muestra (n=30), esta prueba es altamente sensible a desviaciones menores, y el gráfico Q-Q visual mostró solo ligeras desviaciones de la normalidad. Con muestras más grandes, los modelos de regresión son robustos ante violaciones moderadas de normalidad gracias al Teorema del Límite Central.
-
Multicolinealidad: Los factores de inflación de la varianza (VIF) para los predictores estuvieron por encima del umbral típico de 5, indicando la presencia de multicolinealidad. Sin embargo, considerando que esto era esperado debido a la inclusión de términos de interacción, esto no invalida nuestro modelo.
-
Valores atípicos y observaciones influyentes: La prueba de Bonferroni para valores atípicos no detectó valores atípicos significativos. Los valores de distancia de Cook estuvieron todos por debajo del umbral de 1, sugiriendo que no hay puntos excesivamente influyentes.
En conclusión, nuestro análisis de moderación en R no encontró un efecto de moderación estadísticamente significativo de la tolerancia a la cafeína sobre la relación entre el consumo de café y la productividad. Aunque el modelo explicó una proporción sustancial de la varianza (R² = 0.756), el término de interacción no fue significativo. Esto sugiere que, en esta muestra, el efecto del café sobre la productividad no varía significativamente según los niveles de tolerancia a la cafeína. Estos hallazgos resaltan la importancia de un tamaño de muestra adecuado y la necesidad de estudios de replicación para detectar efectos de moderación de manera confiable.
IMPORTANTE: Recuerda ajustar la interpretación a tus resultados y contexto reales. Este es un ejemplo genérico y podría no alinearse completamente con tus objetivos y resultados de investigación específicos.
Preguntas Frecuentes
Próximos Pasos
Ahora que dominas el análisis de moderación con un solo moderador en R, puedes profundizar tus conocimientos explorando técnicas complementarias:
-
Análisis de mediación en R: Mientras que la moderación revela cuándo y para quién ocurren los efectos, la mediación te ayuda a entender cómo y por qué una variable independiente afecta a la dependiente. Juntas, proporcionan una comprensión integral de las relaciones entre variables.
-
Análisis de moderación en SPSS: Si prefieres una interfaz gráfica o necesitas comparar resultados entre plataformas, esta guía te muestra cómo realizar el mismo análisis usando SPSS con el macro PROCESS.
Referencias
Baron, R. M., & Kenny, D. A. (1986). The moderator-mediator variable distinction in social psychological research: Conceptual, strategic, and statistical considerations. Journal of Personality and Social Psychology, 51(6), 1173-1182.
Aiken, L. S., & West, S. G. (1991). Multiple regression: Testing and interpreting interactions. Sage Publications.
Cohen, J., Cohen, P., West, S. G., & Aiken, L. S. (2003). Applied multiple regression/correlation analysis for the behavioral sciences (3rd ed.). Lawrence Erlbaum Associates.