El análisis de moderación te ayuda a entender cuándo cambia la relación entre dos variables. En lugar de preguntar si X afecta a Y, el análisis de moderación pregunta: "¿Depende la intensidad de la relación X→Y de una tercera variable (el moderador)?"
En esta guía aprenderás dos métodos prácticos para realizar el análisis de moderación en SPSS: el método manual con estandarización de variables y el método moderno con PROCESS Macro.
¿Qué es el Análisis de Moderación?
El análisis de moderación evalúa si la relación entre una variable independiente (X) y una variable dependiente (Y) cambia según el nivel de una tercera variable llamada moderador (M).
Piénsalo así: el efecto de X sobre Y no es igual para todos. Depende de M.
Pregunta de investigación de ejemplo: "¿Modera la edad (M) la relación entre la calidad de la relación con el cliente (X) y la lealtad del consumidor (Y)?"
En este ejemplo:
- Variable Independiente (X): Calidad de la Relación con el Cliente
- Variable Moderadora (M): Edad
- Variable Dependiente (Y): Lealtad del Consumidor
La pregunta de investigación es: ¿Es la relación entre calidad de la relación y lealtad más fuerte o más débil en clientes mayores frente a clientes jóvenes?
Moderación vs. Mediación
La moderación es fundamentalmente diferente a la mediación:
Moderación: M cambia la intensidad o dirección de la relación X→Y (efecto de interacción)
Mediación: M transmite el efecto de X a Y (efecto indirecto)
En moderación, M no tiene una relación causal con X. El moderador es independiente del predictor.
Más información: Moderadores vs. Mediadores en Investigación
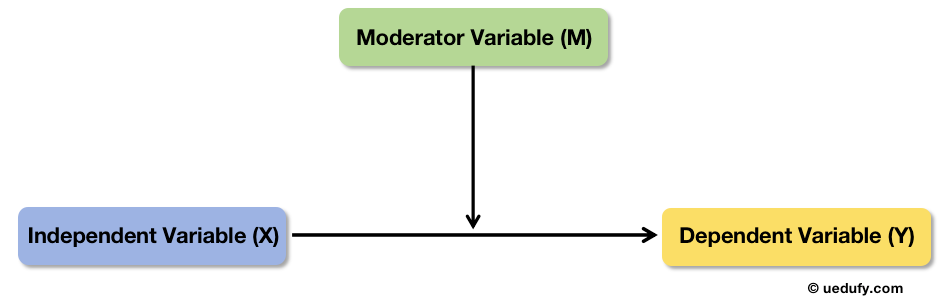
Figura 1: Diagrama conceptual de moderación: M influye en la intensidad de la relación X→Y.
El Término de Interacción
La moderación se evalúa mediante un término de interacción (también llamado término producto), calculado como:
Interacción = X × M
Cuando incluyes este término de interacción en un modelo de regresión, un efecto de interacción significativo indica moderación.
Método 1: Análisis de Moderación Manual
El método manual requiere más pasos, pero te ayuda a comprender la mecánica subyacente del análisis de moderación. Este enfoque implica estandarizar las variables, crear un término de interacción y ejecutar una regresión lineal.
Dataset de muestra:
Para este tutorial usaremos un dataset de muestra con tres variables: Relationship (Relación), Loyalty (Lealtad) y Age (Edad). Si deseas seguir los pasos, descarga el archivo de datos de muestra de SPSS e impórtalo. El dataset debe verse así:
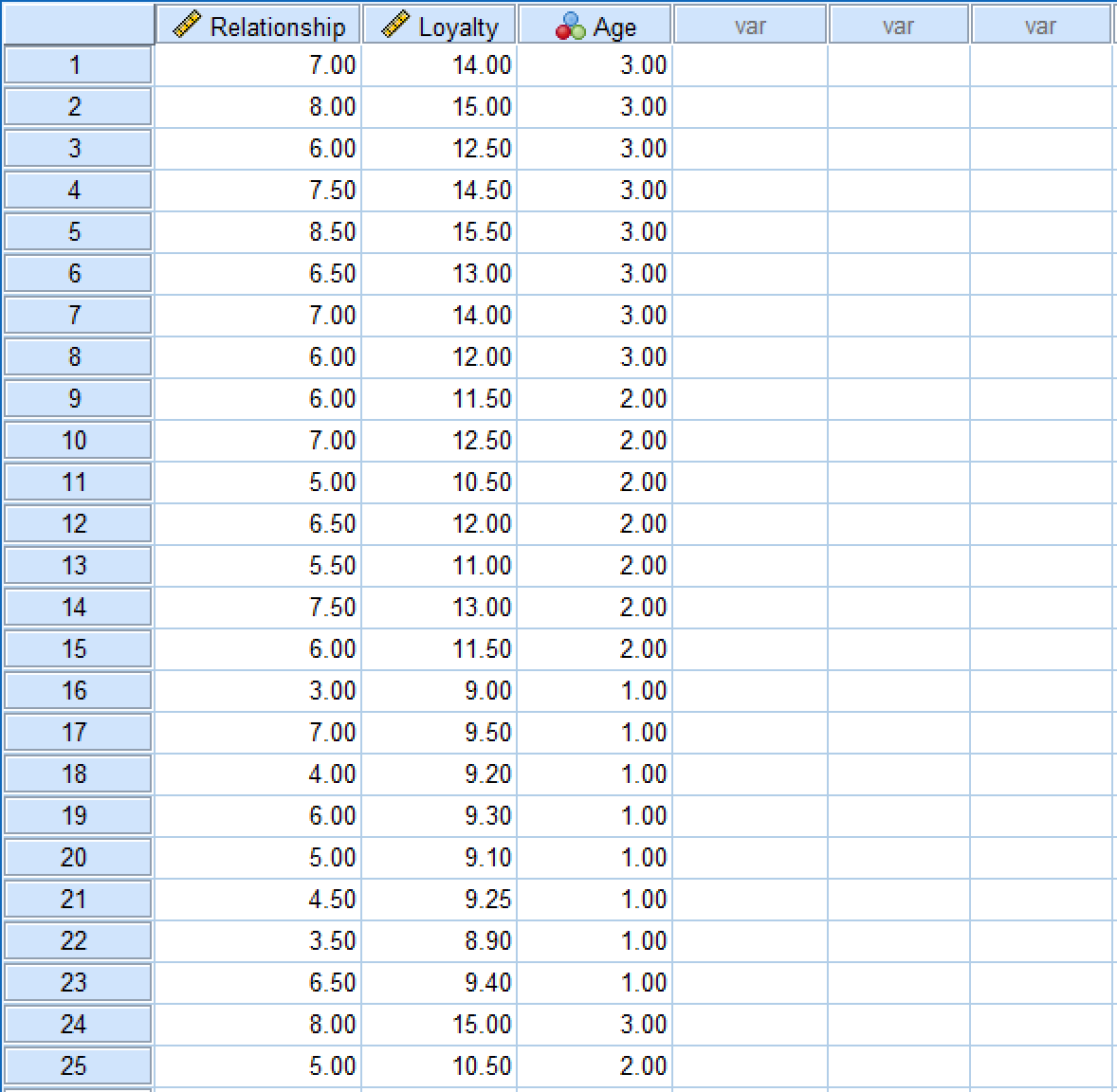
Figura 2: Dataset de muestra de SPSS con las variables Relationship, Loyalty y Age.
Paso 1: Estandarizar las Variables Continuas
Nota importante: En este método manual usaremos la estandarización Z (creando puntuaciones estandarizadas con media = 0 y DE = 1). Esto es diferente del centrado en la media que usa PROCESS Macro, que solo resta la media (media = 0 pero conserva la DE original).
Ambos enfoques reducen la multicolinealidad entre el término de interacción y sus componentes. La estandarización Z tiene la ventaja de colocar todas las variables en la misma escala, lo que hace que los coeficientes sean directamente comparables.
¿Por qué estandarizar? Cuando multiplicas X × M para crear el término de interacción, la variable resultante suele estar muy correlacionada con X y M. La estandarización minimiza este problema y facilita la interpretación.
Para estandarizar las variables, navega a Analizar → Estadísticos descriptivos → Descriptivos en el menú superior de SPSS.
Figura 3: Navegar a Estadísticos descriptivos en SPSS para estandarizar variables.
En la ventana de Descriptivos:
- Mueve Relationship y Age al cuadro Variable(s)
- Marca "Guardar valores tipificados como variables"
- Haz clic en
Aceptar
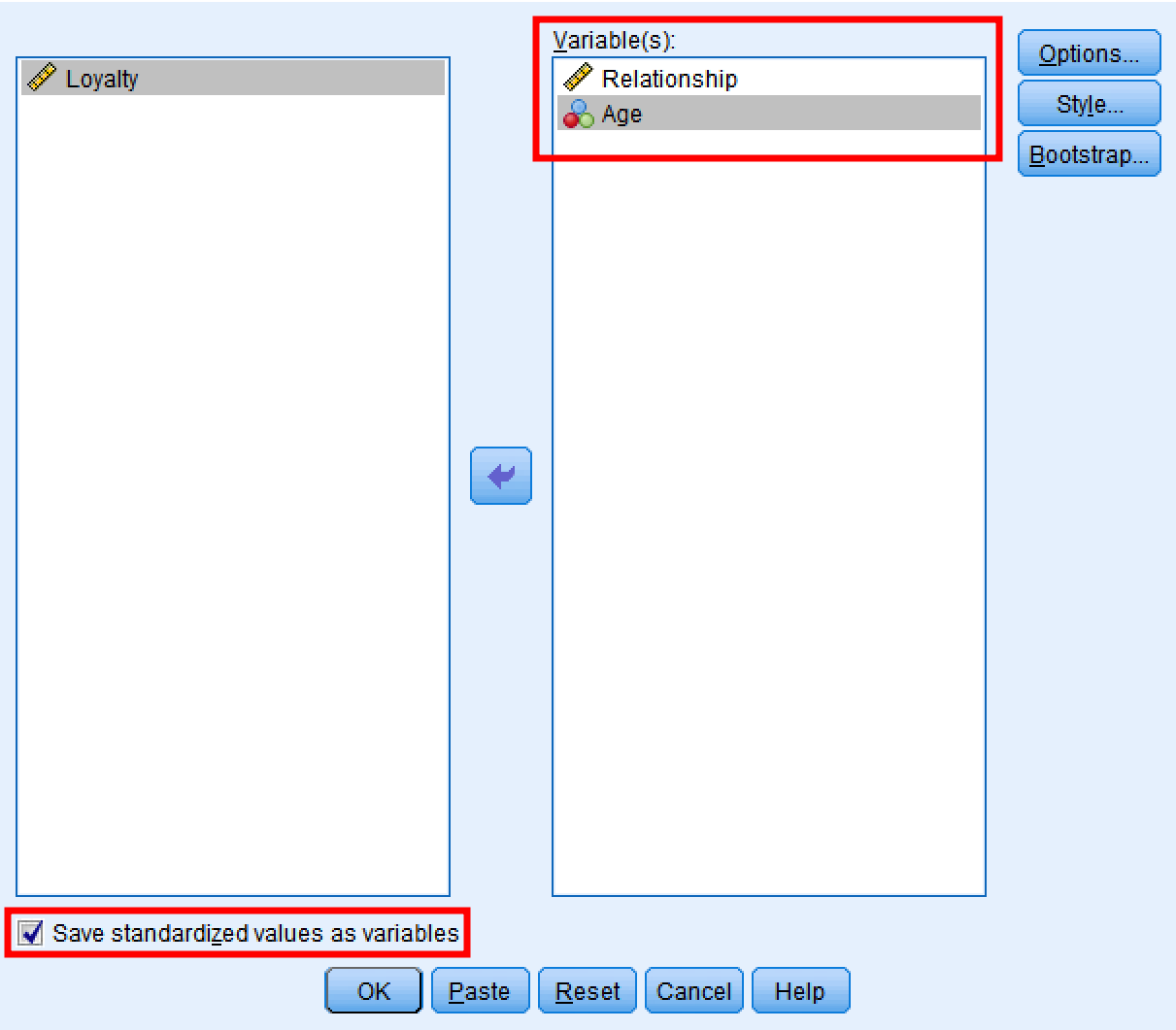
Figura 4: Ventana de Descriptivos de SPSS con la selección de variables y la opción de estandarización.
SPSS creará nuevas variables con el prefijo Z: ZRelationship y ZAge.

Figura 5: Vista de datos de SPSS con las variables originales y estandarizadas con prefijo Z.
Qué hace la estandarización:
| Antes de estandarizar | Después de estandarizar |
|---|---|
| Escala original (p. ej., 1-7) | Escala Z (media = 0, DE = 1) |
| La media varía por variable | Media = 0 para todas las variables |
| Unidades diferentes | Unidades estandarizadas |
Tabla 1: Comparación de valores antes y después de la estandarización
Paso 2: Crear el Término de Interacción
Ahora crea el término producto multiplicando las variables estandarizadas.
En SPSS:
- Ve a
Transformar→Calcular variable - En Variable objetivo, escribe:
INT(abreviatura del término de interacción) - En el cuadro Expresión numérica, escribe:
ZRelationship * ZAge - Haz clic en
Aceptar
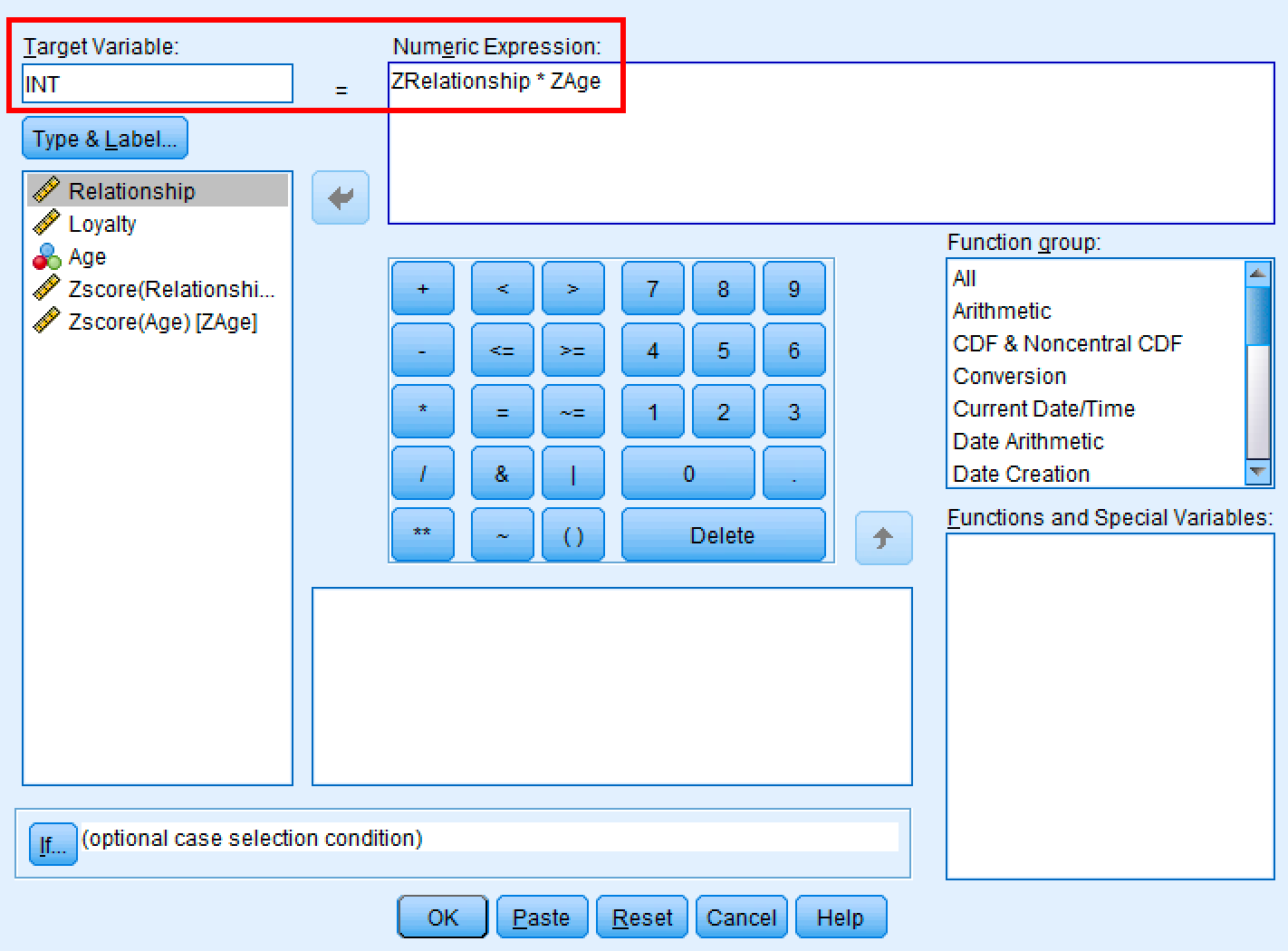
Figura 6: Cuadro de diálogo Calcular variable de SPSS para crear el término de interacción.
SPSS crea una nueva variable llamada INT que contiene el producto de las dos variables estandarizadas.

Figura 7: Vista de datos de SPSS con la nueva variable INT creada.
Paso 3: Ejecutar la Regresión Lineal
Ahora evalúa si el término de interacción predice significativamente la variable dependiente.
En SPSS:
- Ve a
Analizar→Regresión→Lineal - Mueve Loyalty (Y) al cuadro Dependiente
- Mueve ZRelationship, ZAge e INT al cuadro Independientes
- Haz clic en
Aceptar
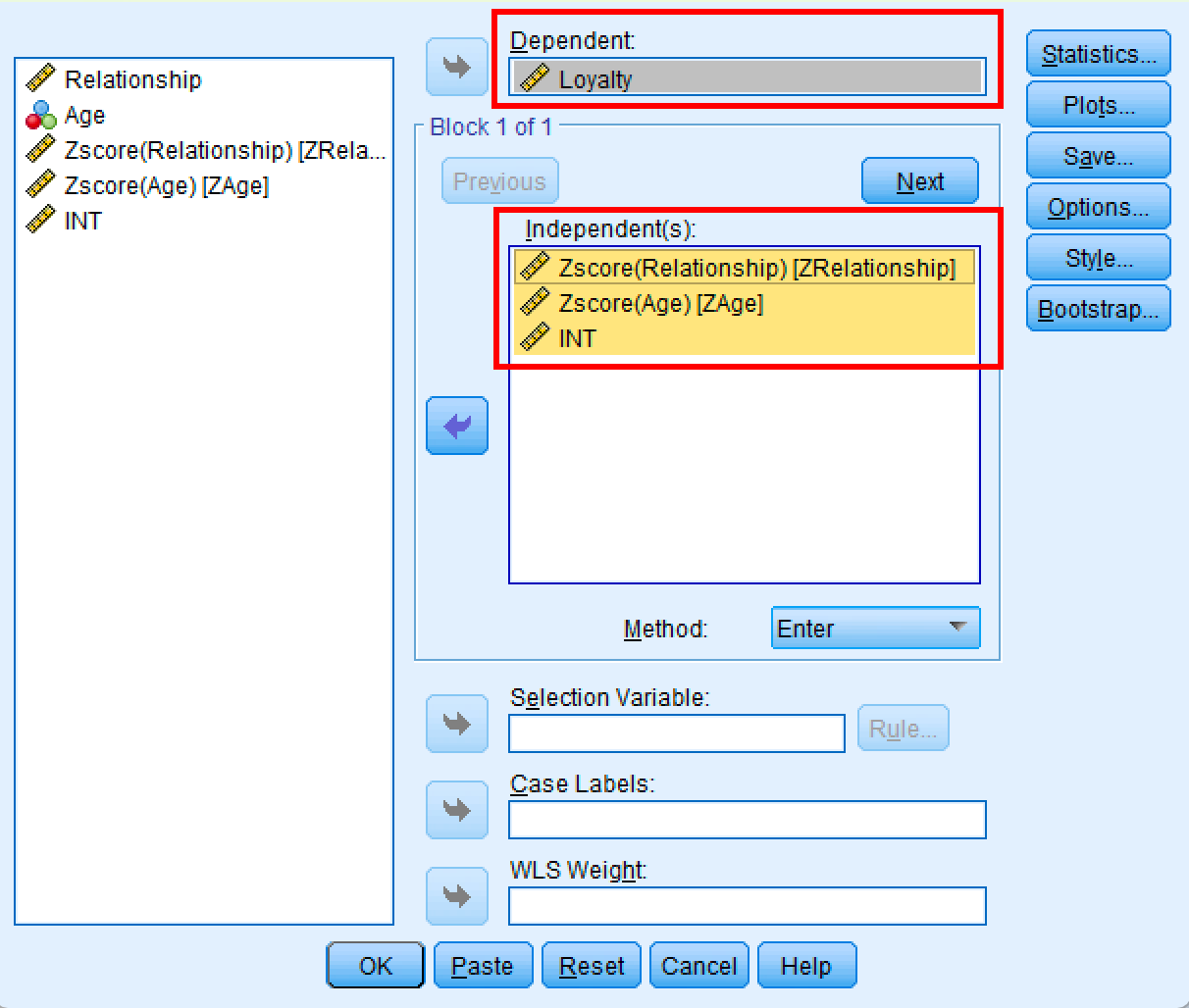
Figura 8: Cuadro de diálogo de Regresión lineal de SPSS para el análisis de moderación.
Interpretar el Análisis de Moderación en SPSS
El análisis de regresión lineal produce tres tablas: Resumen del modelo, ANOVA y Coeficientes. Para determinar si la edad modera la relación entre Relationship y Loyalty, debes examinar el valor de significancia en la tabla de Coeficientes.
Paso 1: Revisar la tabla Resumen del modelo
Primero observa el valor de R cuadrado en la tabla Resumen del modelo.
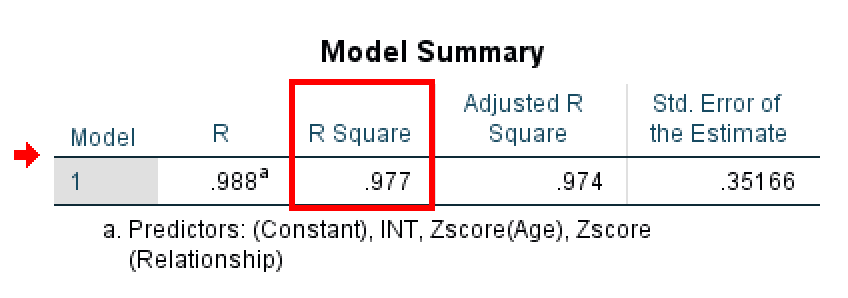
Figura 9: Tabla Resumen del modelo con el valor R cuadrado del modelo de moderación.
R cuadrado indica qué proporción de la varianza en la variable dependiente (Loyalty) explica tu modelo. En este ejemplo, R cuadrado = 0.977, lo que significa que el modelo explica el 97.7 % de la variación en la lealtad del cliente.
⚠️ Nota importante sobre este ejemplo: Este valor de R² = 0.977 es artificialmente alto porque se trata de datos simulados creados con fines didácticos. En investigación real, los valores de R² para modelos de moderación suelen oscilar entre 0.20 y 0.60. No esperes valores tan altos en tu investigación. Si ves valores superiores a 0.90, puede indicar problemas en los datos, sobreajuste o trabajo con datos experimentales muy controlados. Este ejemplo usa un R² poco realista para que los patrones estadísticos sean claros con fines de aprendizaje.
Paso 2: Revisar la tabla ANOVA
A continuación, examina la tabla ANOVA para evaluar si el modelo de regresión en su conjunto es estadísticamente significativo.
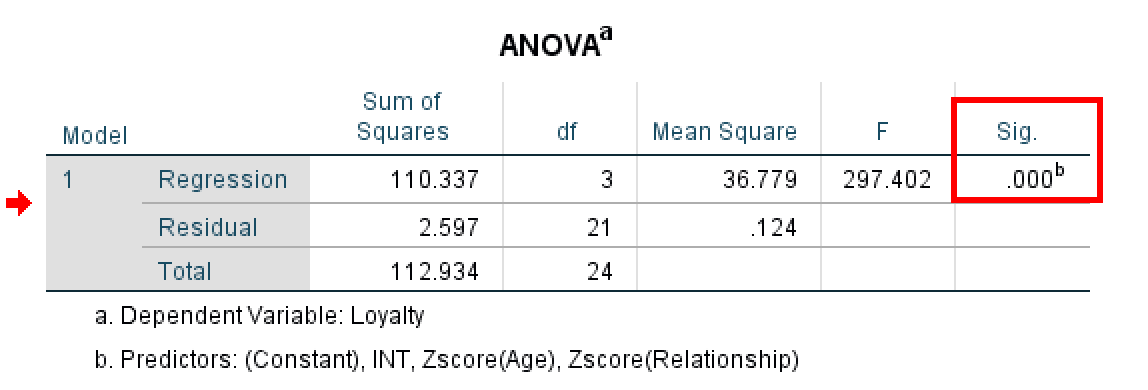
Figura 10: Tabla ANOVA con la significancia global del modelo.
La tabla ANOVA evalúa si tu modelo de regresión (con todos los predictores incluidos) explica una cantidad estadísticamente significativa de varianza en la variable dependiente. Observa la columna Sig.:
- Si Sig. < 0.05 (frecuentemente mostrado como 0.000): Tu modelo es estadísticamente significativo. Al menos uno de los predictores (ZRelationship, ZAge o INT) tiene un efecto significativo sobre Loyalty. Esto es lo que se busca.
- Si Sig. > 0.05: Tu modelo no es significativo. Los predictores no explican significativamente la variación en el resultado. Esto sugiere que las variables pueden no tener relaciones sustantivas.
En este ejemplo, la tabla ANOVA muestra F = 297.402 con Sig. = .000 (p < 0.001). Este resultado altamente significativo confirma que el modelo en su conjunto es estadísticamente significativo y que los predictores colectivamente explican una cantidad sustantiva de varianza en la lealtad del cliente.
Paso 3: Examinar la tabla de Coeficientes
Por último, verifica la tabla de Coeficientes para ver si el término de interacción (INT) es significativo.
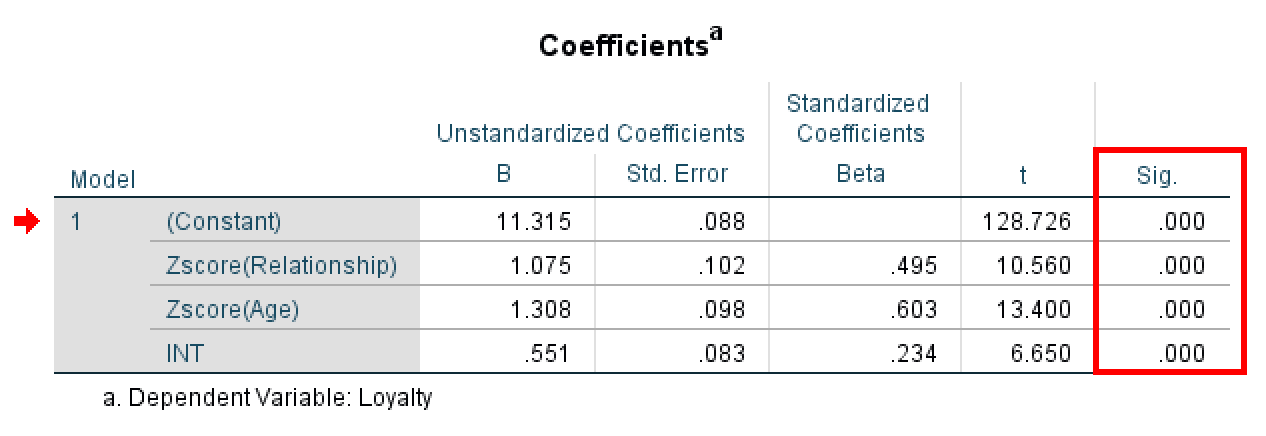
Figura 11: Tabla de coeficientes de regresión de SPSS con el efecto de interacción.
Antes de interpretar los resultados, veamos qué indica cada fila en la tabla de Coeficientes:
| Variable | Qué indica |
|---|---|
| (Constante) | El valor de referencia de Loyalty cuando todos los predictores son cero |
| Zscore(Relationship) | Efecto principal de la calidad de la relación sobre la lealtad |
| Zscore(Age) | Efecto principal de la edad sobre la lealtad |
| INT | El efecto de moderación: ¿cambia la relación entre X e Y según la edad? |
Tabla 2: Interpretación de cada fila en la tabla de coeficientes de regresión
Ahora observa la fila INT (tu término de interacción) y revisa la columna Sig.:
- Si Sig. < 0.05: La variable moderadora (Edad) afecta significativamente la relación entre Relationship y Loyalty. Existe moderación.
- Si Sig. > 0.05: La edad no modera la relación. No hay efecto de moderación.
En este ejemplo, el valor Sig. para INT es .000 (p < 0.001). Es altamente significativo, muy por debajo del umbral de 0.05. Podemos concluir con confianza que el efecto de moderación es estadísticamente significativo. Esto significa que la edad sí modera la relación entre Relationship y Loyalty. En otras palabras, el efecto de la calidad de la relación sobre la lealtad depende de la edad del cliente.
Paso 4: Interpretar la Dirección
Una vez confirmada la significancia de la interacción, debes comprender la dirección del efecto de moderación. Observa el valor B (coeficiente no estandarizado) en la fila INT.
En este ejemplo, el valor B para INT es 0.551. Al ser un coeficiente positivo, indica que la relación entre Relationship y Loyalty se vuelve más fuerte a medida que aumenta la Edad.
¿Qué significa esto?
El coeficiente positivo (B = 0.551) indica que el efecto de la calidad de la relación sobre la lealtad es más fuerte en clientes mayores que en clientes jóvenes. Es decir, construir relaciones sólidas tiene un mayor impacto en la lealtad entre los clientes de mayor edad.
Coeficientes positivos vs. negativos:
- Coeficiente positivo (+): La relación X→Y se fortalece a medida que M aumenta. Los valores altos del moderador amplifican el efecto.
- Coeficiente negativo (−): La relación X→Y se debilita a medida que M aumenta. Los valores altos del moderador reducen el efecto.
En nuestro ejemplo, la edad potencia la relación entre calidad de la relación y lealtad.
Método 2: PROCESS Macro (Recomendado)
PROCESS Macro, desarrollado por Andrew Hayes, es el estándar moderno para el análisis de moderación. Gestiona automáticamente la estandarización, crea los términos de interacción y proporciona efectos condicionales en diferentes niveles del moderador.
Instalación de PROCESS Macro
Antes de usar PROCESS, debes instalarlo en SPSS. La instalación toma aproximadamente 5 minutos.
Para instrucciones detalladas de instalación, consulta nuestra guía: Cómo instalar PROCESS Macro en SPSS.
Ejecutar la Moderación con PROCESS
Una vez instalado PROCESS, puedes acceder desde el menú de SPSS.
Figura 12: Acceder a PROCESS Macro desde el menú de SPSS: Analizar → Regresión → PROCESS.
En SPSS:
- Ve a
Analizar→Regresión→PROCESS v5.0 por Andrew F. Hayes - Selecciona el Modelo 1 (modelo de moderación simple)
- Mueve Loyalty al cuadro Variable Y
- Mueve Relationship al cuadro Variable(s) X
- Mueve Age al cuadro W: Moderador principal (no al cuadro M: Mediador)
- Deja vacíos los cuadros M: Mediadores, Z: Moderador secundario y COV: Covariables
- Haz clic en
Opciones
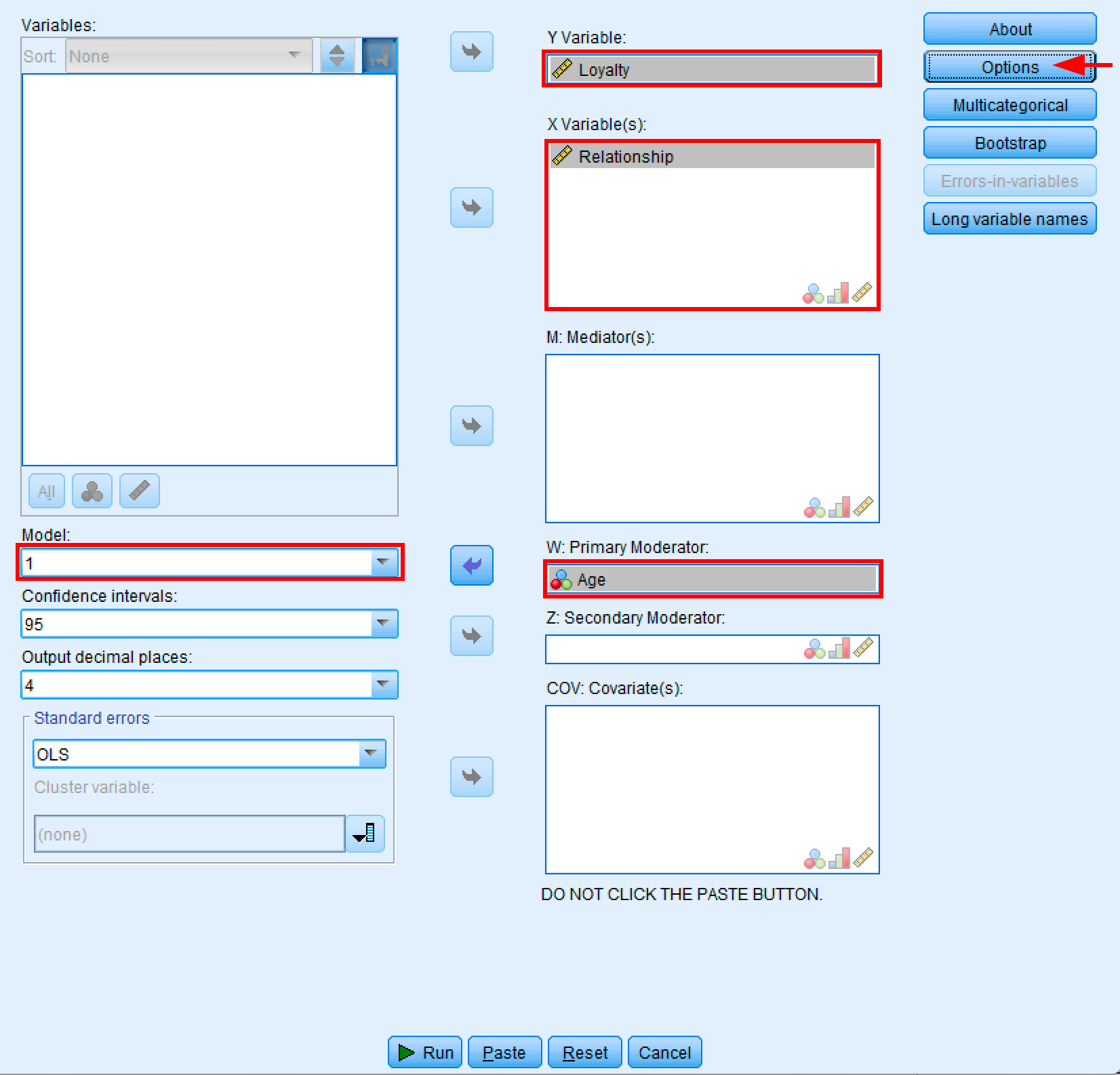
Figura 13: Cuadro de diálogo de PROCESS Macro configurado para el análisis de moderación simple con el Modelo 1.
Importante: Asegúrate de colocar Age en el cuadro W: Moderador principal, no en el cuadro M: Mediadores. El cuadro M es para análisis de mediación (modelos diferentes), mientras que el cuadro W es específicamente para moderación. Si colocas Age en el cuadro M por error, las opciones de moderación aparecerán desactivadas en la ventana de Opciones.
En la ventana de Opciones:
- En "Centrado para moderación:" asegúrate de que "Centrar en la media los componentes de los productos" esté marcado (esto centra automáticamente las variables para reducir la multicolinealidad)
- Mantén seleccionada la opción predeterminada "Componentes continuos y dicotómicos"
- En "Análisis de moderación:" asegúrate de que "Analizar interacciones" esté marcado
- Mantén los "Percentiles" predeterminados para los valores del moderador
- Marca "Técnica de Johnson-Neyman" para identificar las regiones de significancia
- En "Visualizar moderación:" marca "Generar datos para visualizar la moderación"
- Haz clic en
Aceptar
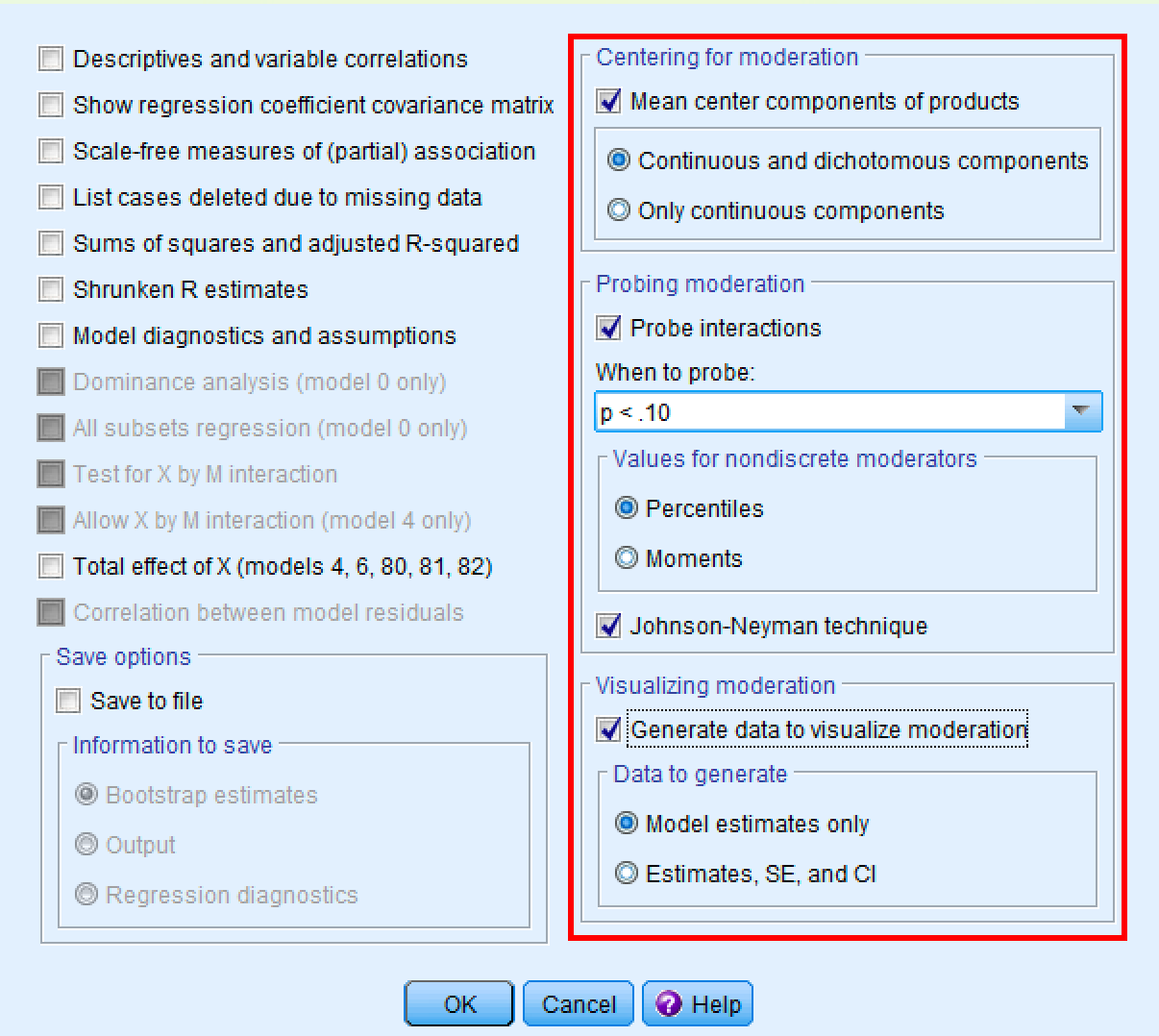
Figura 14: Ventana de opciones de PROCESS con los ajustes recomendados para el análisis de moderación.
Una vez configuradas las opciones, haz clic en el botón Ejecutar en la ventana principal de PROCESS. PROCESS ejecutará el análisis y producirá resultados detallados en el Visor de resultados de SPSS.
Comprender el Output de PROCESS
PROCESS produce las mismas tablas de regresión que viste en el Método 1, pero gestiona todos los cálculos de forma automática.
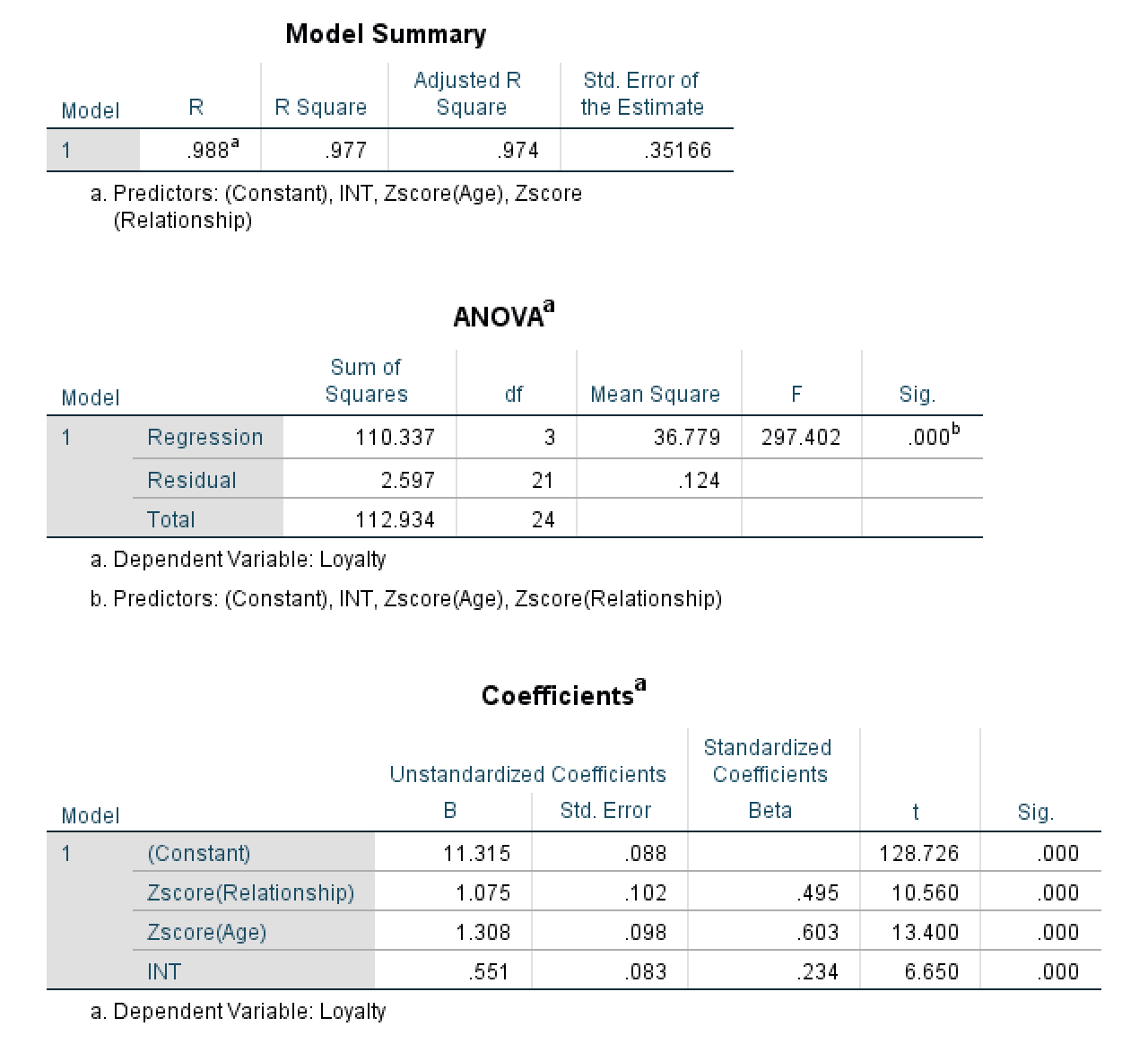
Figura 15: Output de PROCESS con las tablas Resumen del modelo, ANOVA y Coeficientes.
Los resultados son idénticos al Método 1 (R² = .977, F = 297.402, INT Sig. = .000), lo que confirma el efecto de moderación significativo. Para la interpretación detallada de las tablas Resumen del modelo, ANOVA y Coeficientes, consulta la sección de interpretación del Método 1.
Qué aporta PROCESS más allá del Método 1:
La verdadera ventaja de PROCESS es el output adicional que proporciona:
- Tabla de efectos condicionales: Muestra cómo cambia el efecto de Relationship sobre Loyalty en diferentes niveles de Age (bajo, promedio, alto)
- Output de Johnson-Neyman: Identifica los valores exactos de Age donde el efecto de moderación pasa a ser significativo o no significativo
- Datos de visualización: Valores precalculados listos para graficar la interacción
Estas funciones hacen de PROCESS el método preferido en investigación y publicaciones, ya que ofrecen una comprensión más profunda de cómo opera la moderación a lo largo de todo el rango del moderador.
Interpretar las Pendientes Simples (Efectos Condicionales)
Encontrar un término de interacción significativo indica que existe moderación, pero no dice cómo afecta el moderador a la relación X→Y. Aquí es donde el análisis de pendientes simples se vuelve fundamental.
¿Qué son las Pendientes Simples?
Las pendientes simples (también llamadas efectos condicionales) representan la relación entre X e Y en valores específicos del moderador. En lugar de preguntar "¿Afecta el moderador a la relación?" (respondido por el término de interacción), las pendientes simples responden: "¿Cuál es la relación X→Y en diferentes niveles del moderador?"
Para nuestro ejemplo, las pendientes simples indican:
- ¿Cuál es el efecto de Relationship sobre Loyalty para clientes jóvenes?
- ¿Cuál es el efecto de Relationship sobre Loyalty para clientes de edad media?
- ¿Cuál es el efecto de Relationship sobre Loyalty para clientes mayores?
Output de Efectos Condicionales de PROCESS
Al ejecutar el Modelo 1 de PROCESS con "Analizar interacciones" habilitado, PROCESS calcula automáticamente las pendientes simples en tres valores del moderador:
Figura 16: Output de efectos condicionales de PROCESS: relación entre Calidad de la Relación y Lealtad en los niveles bajo, medio y alto de Edad.
Significado de cada columna:
| Columna | Significado |
|---|---|
| Age | Valor del moderador (centrado). Negativo = por debajo de la media, 0 = media, positivo = por encima de la media |
| Effect | Pendiente de Relationship→Loyalty en este nivel de Age (esta es tu pendiente simple) |
| se | Error estándar del efecto |
| t | Estadístico t que evalúa si esta pendiente simple es significativamente diferente de cero |
| p | Valor p. Si p < .05, la relación X→Y es significativa en este nivel del moderador |
| LLCI, ULCI | Intervalo de confianza del 95 %. Si no incluye cero, el efecto es significativo |
Tabla 3: Significado de cada columna en la tabla de efectos condicionales de PROCESS
Cómo Interpretar las Pendientes Simples
Usando los valores de nuestro análisis, la interpretación es la siguiente:
En Age bajo (-1.04, clientes jóvenes):
- Efecto = 0.2775, p = .0031
- Interpretación: Para clientes jóvenes, un aumento de una unidad en Calidad de la Relación produce un aumento de 0.28 unidades en Lealtad. Esta relación es estadísticamente significativa.
En Age medio (-0.04, clientes de edad media):
- Efecto = 0.7414, p < .001
- Interpretación: Para clientes de edad media, un aumento de una unidad en Calidad de la Relación produce un aumento de 0.74 unidades en Lealtad. Este es un efecto sustancialmente más fuerte que para clientes jóvenes.
En Age alto (0.96, clientes mayores):
- Efecto = 1.2052, p < .001
- Interpretación: Para clientes mayores, un aumento de una unidad en Calidad de la Relación produce un aumento de 1.21 unidades en Lealtad. Este es el efecto más fuerte de todos los grupos de edad.
La Historia Completa de la Moderación
Combinando el término de interacción y las pendientes simples:
- El término de interacción es significativo (β = 0.464, p < .001) → La edad modera la relación Relationship→Loyalty
- Las tres pendientes simples son positivas y significativas → La calidad de la relación incrementa la lealtad en todos los niveles de edad
- Las pendientes simples aumentan de 0.28 → 0.74 → 1.21 → El efecto se vuelve progresivamente más fuerte a medida que aumenta la edad
En palabras simples: Si bien la calidad de la relación siempre mejora la lealtad, importa más en clientes mayores que en jóvenes. Una empresa que invierte en relaciones con los clientes verá mayores retornos en lealtad entre los clientes de mayor edad.
Reportar las Pendientes Simples en tu Investigación
Ejemplo de reporte en formato APA:
"El análisis de pendientes simples reveló que la relación entre la calidad de la relación y la lealtad fue significativa y positiva en todos los niveles de edad. Sin embargo, de forma consistente con el efecto de moderación hipotetizado, la intensidad de esta relación aumentó con la edad. Para clientes jóvenes (percentil 16, Age = -1.04), el efecto fue B = 0.28, t = 3.34, p = .003. Para clientes de edad media (percentil 50, Age = -0.04), el efecto fue B = 0.74, t = 10.43, p < .001. Para clientes mayores (percentil 84, Age = 0.96), el efecto fue B = 1.21, t = 10.61, p < .001. Estos resultados confirman que la edad modera positivamente la relación entre la calidad de la relación y la lealtad."
Cuando las Pendientes Simples no son Todas Significativas
No todas las pendientes simples tienen que ser significativas. En ocasiones encontrarás:
Patrón 1: El efecto solo existe en valores altos del moderador
- M bajo: B = 0.12, p = .35 (no significativo)
- M alto: B = 0.89, p < .001 (significativo)
- Interpretación: La relación X→Y solo "se activa" cuando el moderador es alto
Patrón 2: El efecto invierte su dirección
- M bajo: B = -0.45, p < .05 (efecto negativo)
- M alto: B = 0.52, p < .001 (efecto positivo)
- Interpretación: Esta es una interacción cruzada. X beneficia a Y cuando M es alto, pero perjudica a Y cuando M es bajo
Patrón 3: El efecto se reduce a cero
- M bajo: B = 1.25, p < .001 (efecto fuerte)
- M alto: B = 0.15, p = .28 (no significativo)
- Interpretación: La relación X→Y solo opera cuando M es bajo; con M alto, X ya no afecta a Y
Cada patrón cuenta una historia teórica diferente. Interpreta siempre las pendientes simples en el contexto de tu pregunta de investigación.
Técnica de Johnson-Neyman (Avanzado)
PROCESS también proporciona el output de Johnson-Neyman, que identifica el valor exacto del moderador donde la pendiente simple transita de significativa a no significativa (o viceversa).
Ejemplo de output:
Moderator value(s) defining Johnson-Neyman significance region(s)
Value % below % above
0.3521 18.25% 81.75%
Interpretación: El efecto de Relationship sobre Loyalty pasa a ser significativo cuando Age supera 0.3521 (en la escala centrada). Esto representa el percentil 18 de la distribución de edad. Es decir, el efecto de la calidad de la relación es significativo para el 82 % de los clientes (los que se encuentran por encima del percentil 18 en edad).
Cuándo usarla: Johnson-Neyman es especialmente útil cuando algunas pendientes simples no son significativas. Identifica con precisión dónde en el rango del moderador el efecto "se activa" o "se desactiva".
Calcular el Tamaño del Efecto de Moderación
Más allá de la significancia estadística, debes reportar el tamaño del efecto de la moderación. Esto indica cuánta varianza adicional explica el término de interacción.
El Método ΔR²
El tamaño del efecto de moderación se calcula como el cambio en R² al añadir el término de interacción:
ΔR² = R²(modelo completo) − R²(solo efectos principales)
Donde:
- R²(modelo completo) = Modelo con X, M y la interacción X×M
- R²(solo efectos principales) = Modelo solo con X y M
Interpretar los Tamaños del Efecto
Pautas de tamaño del efecto para moderación (Cohen, 1988):
| Valor ΔR² | Tamaño del efecto | Interpretación |
|---|---|---|
| .01 - .03 | Pequeño | Moderación modesta pero potencialmente relevante |
| .03 - .05 | Mediano | Efecto de moderación sustancial |
| > .05 | Grande | Efecto de moderación fuerte |
Tabla 4: Pautas de tamaño del efecto para la moderación (Cohen, 1988)
Importante: Incluso los tamaños del efecto pequeños pueden ser teóricamente relevantes. Un ΔR² de .02 significa que la interacción explica un 2 % adicional de la varianza, lo que podría representar diferencias significativas en cómo opera la relación X→Y a lo largo de los niveles del moderador.
Reportar el Tamaño del Efecto
Ejemplo: "La incorporación del término de interacción produjo un incremento significativo en R² (ΔR² = .05, p < .001), lo que indica un efecto de moderación de tamaño mediano a grande."
Supuestos Estadísticos del Análisis de Moderación
Antes de interpretar tus resultados, verifica que se cumplen estos supuestos:
1. Variable Dependiente Continua
Tu variable de resultado (Y) debe medirse en una escala continua (intervalo o razón). Ejemplos: puntuaciones en pruebas, ingresos, valoraciones de satisfacción (si se tratan como continuas).
2. Independencia de las Observaciones
Cada participante debe aportar un único dato. Las medidas repetidas requieren enfoques analíticos diferentes (modelos mixtos o ANOVA de medidas repetidas).
3. Relaciones Lineales
La relación entre X e Y debe ser aproximadamente lineal en cada nivel del moderador.
Cómo verificarlo: Crea diagramas de dispersión de X vs. Y para diferentes grupos del moderador (bajo, medio, alto). Busca patrones aproximadamente lineales.
4. Sin Multicolinealidad
Los predictores no deben estar demasiado correlacionados entre sí (tras el centrado).
Cómo verificarlo: Solicita estadísticas FIV (Factor de Inflación de la Varianza) en la regresión. Los valores FIV deben ser < 10, idealmente < 5.
Solución si se viola: Por eso estandarizamos o centramos las variables antes de crear los términos de interacción. El centrado generalmente reduce los valores FIV de forma considerable.
5. Homocedasticidad
La varianza de los residuos debe ser constante en todos los valores predichos.
Cómo verificarlo: Grafica los residuos vs. los valores predichos. Busca un patrón de dispersión aleatoria (no en forma de embudo).
6. Normalidad de los Residuos
Los residuos deben seguir una distribución aproximadamente normal.
Cómo verificarlo: Examina el histograma de los residuos o el gráfico Q-Q. La normalidad perfecta no es necesaria en muestras grandes (n > 100).
7. Sin Valores Atípicos Influyentes
Los casos extremos no deben influir desproporcionadamente en los coeficientes de regresión.
Cómo verificarlo: Examina los valores de distancia de Cook. Valores > 1.0 indican casos potencialmente influyentes.
8. Independencia del Moderador
Fundamental: El moderador (M) no debe ser causado por la variable independiente (X). El moderador debe ser teóricamente independiente de X.
Ejemplo: La edad puede moderar la relación X→Y porque X no causa la edad. Sin embargo, si M es "motivación" y X es "capacitación", esto viola el supuesto porque la capacitación podría aumentar la motivación.
¿Qué hacer si se violan los supuestos?
- No linealidad: Considera términos polinómicos o modelos no lineales
- Multicolinealidad (incluso tras el centrado): Elimina los predictores altamente correlacionados o usa regresión Ridge
- Heterocedasticidad: Usa errores estándar robustos (disponibles en PROCESS)
- Residuos no normales: Con muestras grandes (n > 100), la regresión es robusta a estas violaciones. En caso contrario, considera transformaciones
- Valores atípicos: Investiga y elimínalos si son errores de ingreso de datos. De lo contrario, reporta los resultados con y sin los valores atípicos
Trabajar con Moderadores Categóricos
¿Qué ocurre si tu moderador es categórico (p. ej., género, grupo de tratamiento, país)?
Diferencias Clave
Los moderadores categóricos no necesitan centrado. SPSS crea automáticamente variables dummy para los predictores categóricos.
Cómo Proceder
-
Moderador binario (2 grupos): Codifica como 0/1 y procede con normalidad. La interacción evalúa si la pendiente X→Y difiere entre grupos.
-
Múltiples grupos (3 o más categorías): Crea variables dummy para k-1 categorías (SPSS lo hace automáticamente). Obtendrás k-1 términos de interacción.
Cambios en la Interpretación
Con moderadores categóricos, la interacción evalúa diferencias entre grupos en las pendientes en lugar de cómo cambian las pendientes a lo largo de una dimensión continua.
Ejemplo: Si el género modera la relación entre capacitación y rendimiento:
- Interacción significativa = El efecto de la capacitación sobre el rendimiento difiere entre hombres y mujeres
- Interacción no significativa = La capacitación afecta al rendimiento de forma similar en ambos grupos
Usar PROCESS con Moderadores Categóricos
PROCESS gestiona los moderadores categóricos automáticamente:
- Codifica tu variable categórica con valores numéricos (0, 1, 2, etc.)
- Introdúcela en el cuadro W como de costumbre
- PROCESS creará las variables dummy y los términos de interacción necesarios
Para moderadores multicategóricos (3 o más grupos), marca la opción "Multicategórica" en las Opciones de PROCESS.
Comparar los Dos Métodos
| Característica | Método Manual | PROCESS Macro |
|---|---|---|
| Facilidad de uso | Requiere estandarización manual y creación de variables | Estandarización y cálculo automáticos |
| Efectos condicionales | No se proporcionan | Se calculan automáticamente |
| Visualización | Requiere graficación manual | Proporciona valores para graficar fácilmente |
| Potencia estadística | Estándar | Errores estándar robustos disponibles |
| Estándar actual | Educativo | Mejor práctica vigente |
| Recomendación | Para aprendizaje | Para investigación |
Tabla 5: Comparación del método manual y PROCESS Macro para el análisis de moderación
Reportar los Resultados de Moderación
Al reportar los resultados del análisis de moderación, incluye:
- Bondad de ajuste del modelo (R², estadístico F, significancia)
- Efectos principales de X y M (coeficientes y significancia)
- Efecto de interacción (coeficiente B, estadístico t, valor p)
- Dirección de la moderación (interpretación del coeficiente positivo o negativo)
Ejemplo de reporte de resultados:
"Se realizó un análisis de moderación para evaluar si la edad modera la relación entre la calidad de la relación con el cliente y la lealtad. El modelo en su conjunto fue significativo, F(3, 21) = 297.40, p < .001, R² = .977. El término de interacción fue significativo (B = 0.551, t = 6.65, p < .001), lo que indica que la edad modera la relación entre la calidad de la relación y la lealtad. El coeficiente positivo sugiere que el efecto de la calidad de la relación sobre la lealtad se fortalece a medida que aumenta la edad."
Consideraciones Importantes
Requisitos de Tamaño de Muestra
Los efectos de interacción son notoriamente difíciles de detectar y requieren muestras más grandes que los efectos principales por sí solos.
Recomendaciones mínimas:
- Efectos pequeños: 200 o más participantes
- Efectos medianos: 100-150 participantes
- Efectos grandes: 50-80 participantes
Realiza siempre un análisis de potencia antes de recopilar los datos. Herramientas como G*Power te ayudan a determinar el tamaño de muestra requerido según los tamaños del efecto esperados.
El Centrado es Recomendable (No Siempre Obligatorio)
Generalmente se recomienda centrar las variables continuas (ya sea centrado en la media o estandarización Z) antes de crear los términos de interacción. Esto:
- Reduce la multicolinealidad entre X, M y X×M
- Hace que los efectos principales sean interpretables como efectos en la media del moderador
- Estabiliza los estimados de regresión
Sin embargo, algunos investigadores debaten si el centrado es siempre necesario, especialmente cuando las variables ya están en escalas con significado. Sigue las convenciones de tu disciplina y justifica tu elección.
La Teoría Debe Guiar el Análisis
No evalúes moderación simplemente porque puedes. Debes contar con:
- Justificación teórica: ¿Por qué M cambiaría la relación X→Y?
- Hipótesis a priori: ¿La moderación fortalece o debilita la relación?
- Interpretación sustantiva: ¿Qué significa la moderación en la práctica?
El análisis exploratorio de moderación es aceptable, pero debe identificarse claramente como tal y requiere replicación.
Preguntas Frecuentes
Conclusión
Aprendiste dos métodos para realizar el análisis de moderación en SPSS:
- Método Manual: Estandarizar variables, crear el término de interacción, ejecutar la regresión (ideal para aprender)
- PROCESS Macro: Análisis automatizado con efectos condicionales y opciones robustas (óptimo para investigación)
Para tu tesis o proyecto de investigación, recomendamos el Modelo 1 de PROCESS porque proporciona centrado automático, efectos condicionales en múltiples niveles y opciones para errores estándar robustos.
Recuerda: el análisis de moderación revela cuándo ocurren las relaciones, mientras que la mediación revela cómo o por qué ocurren. Comprender esta distinción es fundamental para elegir el análisis correcto.
Próximos pasos:
- Ejecuta estadísticos descriptivos en SPSS como paso preliminar para verificar las distribuciones de las variables antes de evaluar efectos de interacción
- Descarga los datos de práctica y ejecuta ambos métodos tú mismo
- Aprende el análisis de mediación para comprender los mecanismos subyacentes: Cómo Realizar el Análisis de Mediación en SPSS
- Explora técnicas avanzadas: Cómo Realizar el Análisis de Moderación en R
- Combina ambas: Análisis de Moderación Mediada (guía próximamente)