Verificar la normalidad en R es un paso fundamental antes de ejecutar análisis estadísticos paramétricos como pruebas t, ANOVA o regresión lineal. Estos análisis asumen que tus datos siguen una distribución normal, y violar este supuesto puede generar conclusiones inválidas.
En esta guía cubrimos métodos visuales (histogramas, gráficos QQ), pruebas estadísticas (Shapiro-Wilk, Kolmogorov-Smirnov, Anderson-Darling) y cómo interpretar los resultados de las pruebas de normalidad en R. Si aún no tienes R instalado, consulta nuestra guía para instalar R y RStudio.
¿Qué es la Normalidad?
La normalidad se refiere a si los datos siguen una distribución normal. Una distribución normal, también llamada distribución Gaussiana, es una curva en forma de campana caracterizada por su media y desviación estándar. La media representa el centro de la distribución, mientras que la desviación estándar representa la dispersión de los datos alrededor de la media.
Figura 1: Curva de distribución normal (Gaussiana)
La distribución normal es importante porque muchas pruebas estadísticas paramétricas (pruebas t, ANOVA, regresión lineal) asumen que los datos analizados siguen una distribución normal. Si tus datos violan este supuesto de normalidad, estas pruebas pueden producir resultados inexactos o conclusiones inválidas. Si necesitas un repaso de conceptos básicos, consulta nuestra guía sobre estadísticas descriptivas en R.
Métodos Visuales para Verificar Normalidad en R
Los métodos visuales proporcionan una forma intuitiva de evaluar si tus datos siguen una distribución normal. Estos son los dos enfoques visuales más comunes:
1. Histograma
Un histograma es una representación gráfica que muestra la distribución de frecuencia de tus datos. Si los datos siguen una distribución normal, el histograma mostrará una curva simétrica en forma de campana.
Así se crea un histograma en R:
# Crear datos de ejemplo
data <- rnorm(100)
# Crear histograma
hist(data, main = "Histograma de Datos de Ejemplo",
xlab = "Valor", col = "lightblue")Este código genera 100 números aleatorios de una distribución normal estándar (media = 0, desviación estándar = 1) usando la función rnorm() y crea un histograma con la función hist().
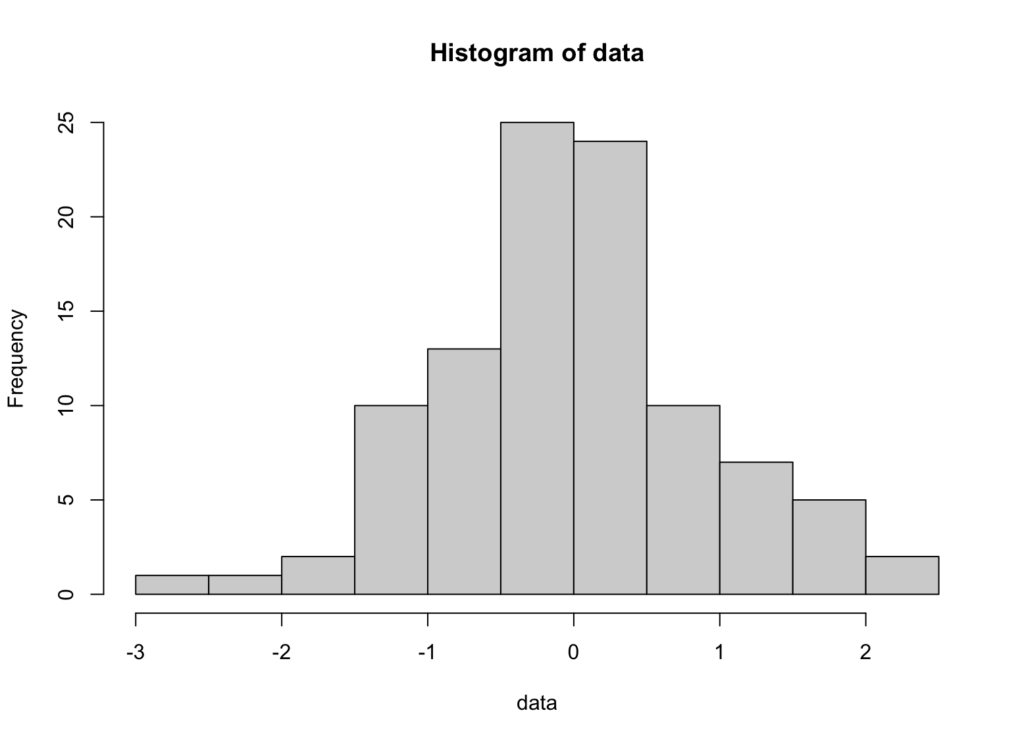
Figura 2: Histograma mostrando datos distribuidos normalmente
Interpretación: Si el histograma muestra una curva simétrica en forma de campana centrada alrededor de la media, tus datos probablemente siguen una distribución normal. Las distribuciones asimétricas o multimodales indican desviaciones de la normalidad.
2. Gráfico QQ (Quantile-Quantile Plot)
Un gráfico QQ (quantile-quantile plot) compara los cuantiles de tus datos con los cuantiles de una distribución normal teórica. Es uno de los métodos visuales más confiables para evaluar la normalidad.
Así se crea un gráfico QQ en R:
# Crear datos de ejemplo
data <- rnorm(100)
# Crear gráfico QQ
qqnorm(data, main = "Gráfico Q-Q Normal")
qqline(data, col = "red")Este código genera 100 números aleatorios de una distribución normal estándar y crea un gráfico QQ con la función qqnorm(). La función qqline() agrega una línea de referencia que representa una distribución normal perfecta.
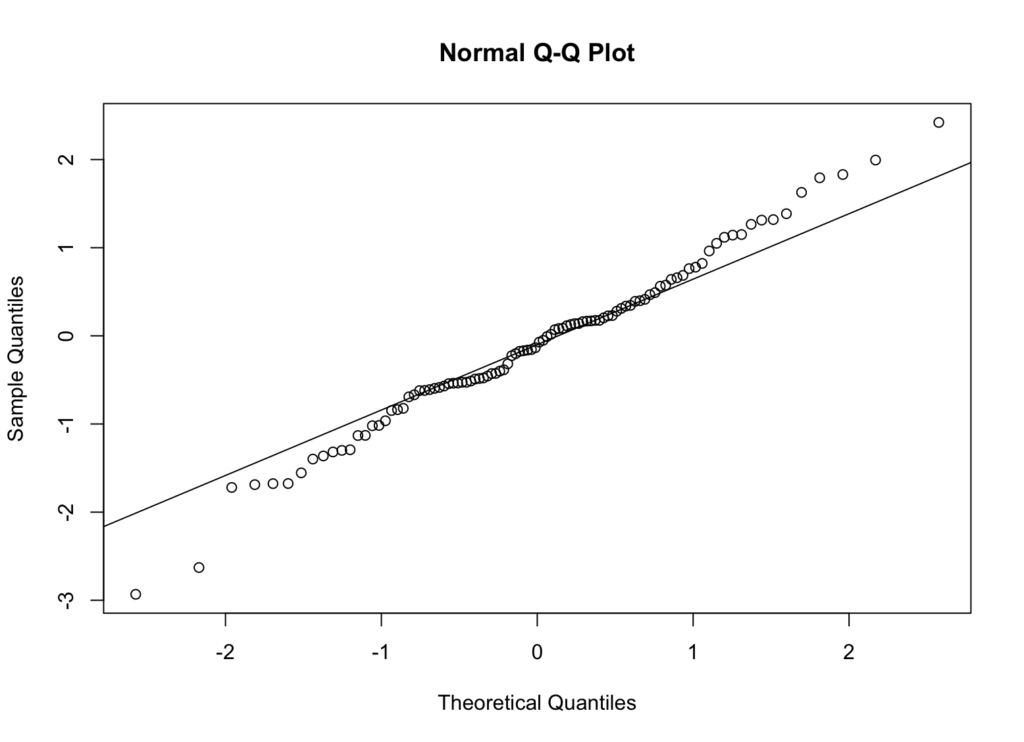
Figura 3: Gráfico QQ para datos distribuidos normalmente
Interpretación: Si tus datos siguen una distribución normal, los puntos deberían caer aproximadamente a lo largo de la línea de referencia. Las desviaciones sistemáticas de la línea indican no normalidad:
- Puntos curvándose por encima de la línea en los extremos sugieren colas pesadas
- Puntos curvándose por debajo de la línea en los extremos sugieren colas ligeras
- Patrones en forma de S indican asimetría
Pruebas Estadísticas de Normalidad en R
Los métodos visuales son útiles, pero las pruebas estadísticas proporcionan evaluaciones objetivas y cuantitativas de la normalidad. Estas son las pruebas de normalidad más comunes en R:
1. Prueba de Shapiro-Wilk
La prueba de Shapiro-Wilk es una de las pruebas de normalidad más potentes, especialmente para tamaños de muestra pequeños a medianos (n menor a 2,000). Si ya trabajaste con normalidad en SPSS, el concepto es el mismo pero con sintaxis diferente en R.
Hipótesis:
- Hipótesis nula (H₀): Los datos siguen una distribución normal
- Hipótesis alternativa (H₁): Los datos no siguen una distribución normal
Así se realiza la prueba de Shapiro-Wilk en R:
# Crear datos de ejemplo
data <- rnorm(100)
# Realizar prueba de Shapiro-Wilk
shapiro.test(data)Este código genera 100 números aleatorios de una distribución normal estándar y realiza una prueba de Shapiro-Wilk con la función shapiro.test().

Figura 4: Resultados de la prueba de Shapiro-Wilk
Interpretación:
- valor p mayor a 0.05: No rechazas la hipótesis nula; los datos parecen distribuirse normalmente
- valor p menor o igual a 0.05: Rechazas la hipótesis nula; los datos se desvían significativamente de la normalidad
Nota: La prueba de Shapiro-Wilk puede ser excesivamente sensible con muestras grandes, detectando desviaciones triviales de la normalidad que tienen poco impacto práctico.
2. Prueba de Kolmogorov-Smirnov
La prueba de Kolmogorov-Smirnov (K-S) compara la función de distribución acumulada de tus datos con una distribución normal teórica.
# Crear datos de ejemplo
data <- rnorm(100)
# Realizar prueba de Kolmogorov-Smirnov
ks.test(data, "pnorm", mean = mean(data), sd = sd(data))Interpretación: Similar a la prueba de Shapiro-Wilk, un valor p mayor a 0.05 sugiere que los datos siguen una distribución normal.
Nota: La prueba K-S es menos potente que la prueba de Shapiro-Wilk para detectar desviaciones de la normalidad, especialmente en las colas de la distribución.
3. Prueba de Anderson-Darling
La prueba de Anderson-Darling asigna más peso a las colas de la distribución que la prueba de Kolmogorov-Smirnov, lo que la hace más sensible a desviaciones en las colas. Este test requiere el paquete nortest. Si necesitas ayuda con la instalación, consulta nuestra guía para instalar paquetes en R.
# Instalar y cargar el paquete si es necesario
# install.packages("nortest")
library(nortest)
# Crear datos de ejemplo
data <- rnorm(100)
# Realizar prueba de Anderson-Darling
ad.test(data)Interpretación: Un valor p mayor a 0.05 indica que los datos son consistentes con una distribución normal.
Cómo Elegir la Prueba de Normalidad Adecuada
Las diferentes pruebas de normalidad tienen fortalezas distintas y son adecuadas para situaciones diferentes:
Prueba de Shapiro-Wilk:
- La mejor opción para tamaños de muestra pequeños a medianos (n menor a 2,000)
- La prueba de normalidad más potente
- Puede ser excesivamente sensible con muestras grandes
Prueba de Kolmogorov-Smirnov:
- Adecuada para cualquier tamaño de muestra
- Prueba de propósito general
- Menos potente que Shapiro-Wilk
Prueba de Anderson-Darling:
- Efectiva para detectar desviaciones en las colas de la distribución
- Funciona con cualquier tamaño de muestra
- Requiere el paquete nortest
Recomendación: Para la mayoría de aplicaciones con tamaños de muestra menores a 2,000, usa la prueba de Shapiro-Wilk combinada con gráficos QQ para confirmación visual.
Preguntas Frecuentes
Próximos Pasos
Ahora que sabes cómo verificar la normalidad de tus datos en R, puedes avanzar en tu análisis:
-
Importa tus datos: Si trabajas con archivos externos, consulta nuestra guía para importar archivos CSV en R y preparar tus datos antes del análisis.
-
Realiza tu análisis paramétrico: Una vez confirmada la normalidad, puedes proceder con pruebas como la regresión lineal en SPSS u otros análisis paramétricos.
Referencias
Shapiro, S. S., & Wilk, M. B. (1965). An analysis of variance test for normality (complete samples). Biometrika, 52(3-4), 591-611.
Razali, N. M., & Wah, Y. B. (2011). Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests. Journal of Statistical Modeling and Analytics, 2(1), 21-33.