¿Estás listo para llevar tus habilidades de análisis de datos al siguiente nivel con estadísticas descriptivas en R? Entonces comencemos.
Las estadísticas descriptivas son un conjunto de técnicas que nos ayudan a resumir y describir las características principales de un conjunto de datos. Nos permiten obtener una comprensión rápida y sencilla de los datos, y suelen ser el primer paso en cualquier proceso de análisis de datos.
En esta lección, exploraremos el mundo de las estadísticas descriptivas en R. Comenzaremos preparando nuestro conjunto de datos de ventas y luego calcularemos estadísticas descriptivas importantes como la media, mediana y moda, el rango, la desviación estándar y la varianza. Una vez que tengamos estas estadísticas, las usaremos para comprender mejor nuestros datos y tomar decisiones informadas.
Pero eso no es todo. También veremos algunas visualizaciones básicas en R, como histogramas, box plots, scatter plots y líneas de tendencia. Estas visualizaciones nos ayudarán a comprender mejor la distribución y las relaciones dentro de nuestros datos.
Paso 1: Prepara tu Conjunto de Datos
El primer paso es preparar tu conjunto de datos y almacenarlo en R como un vector. En este ejemplo, usaremos 12 cifras de ventas, cada una representando el volumen de ventas para los meses de enero a diciembre:
sales <- c(16, 18, 13, 13, 14, 16, 21, 20, 19, 17, 15, 13)Si aún no tienes R instalado, consulta nuestra guía sobre cómo instalar R y RStudio antes de continuar.
Paso 2: Calcula la Media
Nuestra primera parada es la media, que nos da una idea de la cifra promedio de ventas del año. Para calcular la media en R, usamos la función mean():
mean(sales)El resultado de nuestro cálculo de la media es 16.25, lo que nos indica que la cifra promedio de ventas del año fue de 16.25 unidades.
Paso 3: Calcula la Mediana
A continuación, calculemos la mediana. La mediana es el valor central en un conjunto de datos y puede ser un mejor indicador de la cifra típica de ventas si los datos están sesgados. Para calcular la mediana en R, usamos la función median():
median(sales)El resultado de nuestro cálculo de la mediana es 16, lo que nos indica que el valor central de las cifras de ventas del año fue de 16 unidades.
Paso 4: Calcula la Moda
Otra estadística descriptiva importante es la moda, que es el valor que aparece con mayor frecuencia en un conjunto de datos. Para calcular la moda en R, usamos las funciones table() y which.max():
mode <- table(sales)
mode[which.max(mode)]El resultado de nuestro cálculo de la moda es 13, lo que nos indica que la cifra de ventas más frecuente del año fue de 13 unidades.
Paso 5: Calcula el Rango
También podemos calcular el rango, que nos da una idea de qué tan dispersos están los datos. Para calcular el rango en R, usamos la función range():
range(sales)El resultado de nuestro cálculo del rango es 8, lo que nos indica que las cifras de ventas variaron en 8 unidades entre la cifra mínima (13) y máxima (21) de ventas del año.
Paso 6: Calcula la Desviación Estándar
A continuación, calculemos la desviación estándar. La desviación estándar es una medida de qué tan dispersos están los datos y nos indica cuánto varían las cifras de ventas respecto a la media.
Para calcular la desviación estándar en R, usamos la función sd():
sd(sales)El resultado de nuestro cálculo de la desviación estándar es 2.8, lo que nos indica que las cifras de ventas variaron respecto a la media en un promedio de 2.8 unidades. Si quieres profundizar en este tema, consulta nuestra guía sobre estadísticas descriptivas en Excel para comparar los métodos.
Paso 7: Calcula la Varianza
Finalmente, calcularemos la varianza. La varianza es similar a la desviación estándar, pero en lugar de darnos la desviación promedio de la media en unidades, nos da la desviación promedio de la media al cuadrado. Para calcular la varianza en R, usamos la función var():
var(sales)El resultado de nuestro cálculo de la varianza es 7.84, lo que nos indica que las cifras de ventas variaron respecto a la media en un promedio de 7.84 unidades al cuadrado.
Paso 8: Crea un Histograma
Ahora que hemos calculado algunas estadísticas descriptivas básicas, veamos los datos visualmente mediante un histograma. Para crear un histograma en R, usamos la función hist():
hist(sales)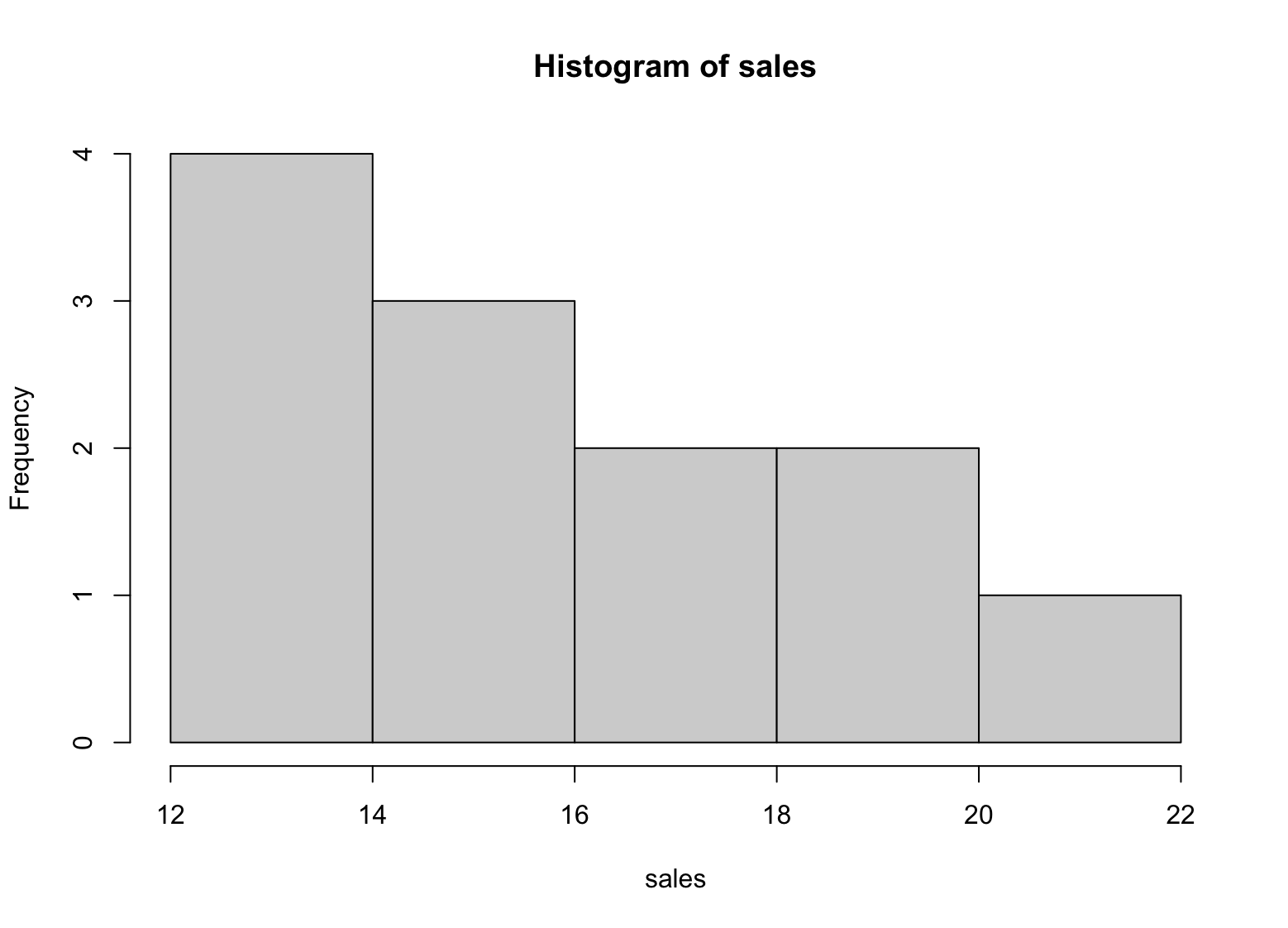
Figura 1: Histograma de estadísticas descriptivas en R
El histograma nos da una representación visual de la distribución de las cifras de ventas del año. Nos muestra que la mayoría de las cifras de ventas se encuentran entre 13 y 18, y hay menos cifras de ventas en los extremos superior e inferior del rango.
Paso 9: Agrega un Scatter Plot
Para crear un scatter plot en R, puedes usar la función plot(). La sintaxis básica es la siguiente:
plot(x, y, main = "Scatter Plot", xlab = "X Variable", ylab = "Y Variable", pch = 16)Aquí, x e y son las variables que quieres graficar. El argumento main es el título del gráfico, xlab e ylab son las etiquetas para el eje x y el eje y, respectivamente, y pch es el símbolo de representación utilizado.
Como solo tenemos una variable en nuestros datos de ventas, podemos graficarla contra la secuencia de números de ventas para crear un scatter plot:
x <- 1:12
plot(x, sales, main = "Scatter Plot of Sales", xlab = "Month", ylab = "Sales", pch = 16)Esto creará un scatter plot de los datos de ventas, con los meses en el eje x y las cifras de ventas en el eje y. El argumento pch establece el símbolo de representación como un círculo sólido (16).
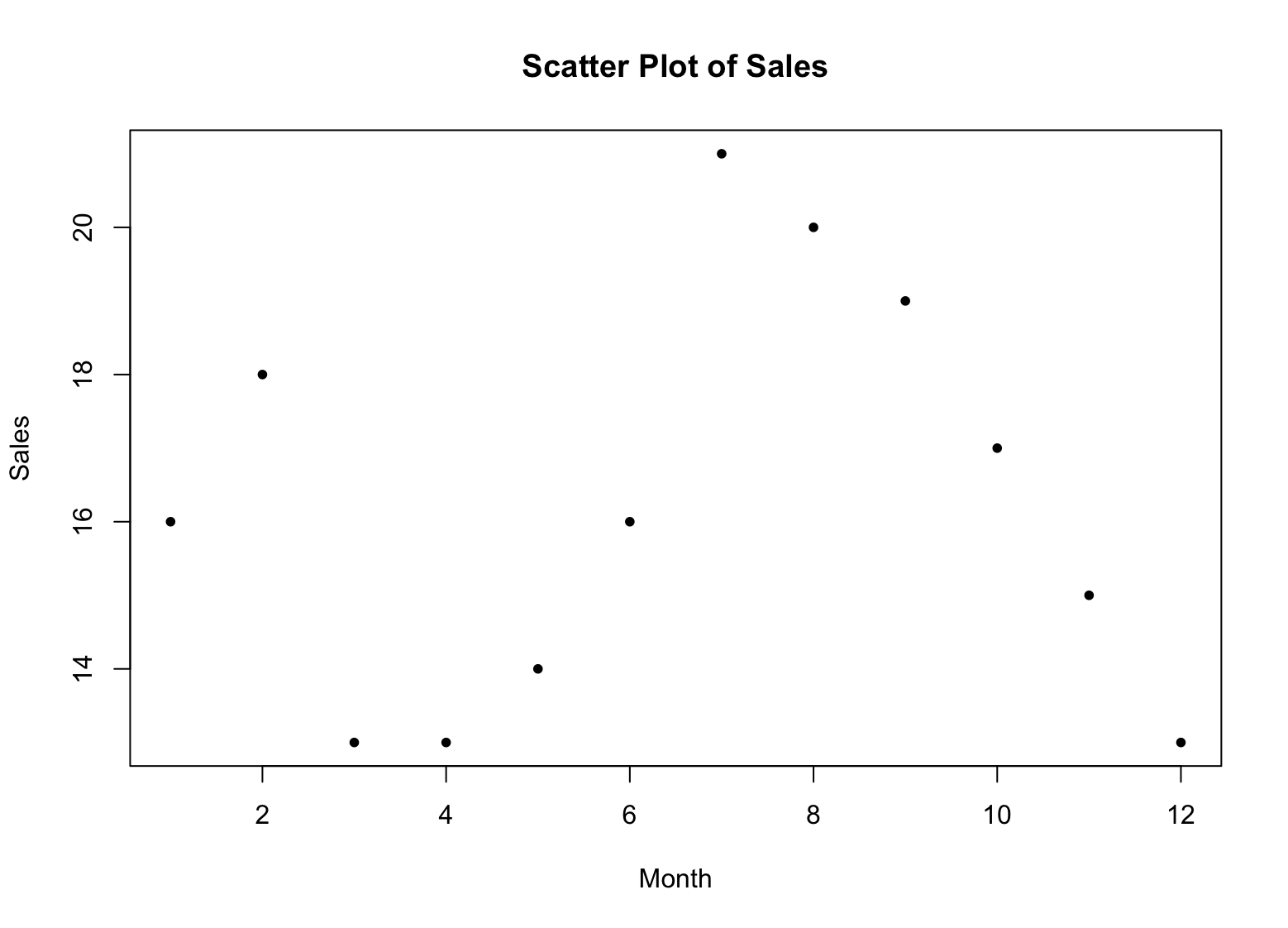
Figura 2: Scatter plot de ventas en R
Obtenemos una serie de puntos, pero resulta más fácil de visualizar si agregamos una línea conectando estos puntos. Aquí está la sintaxis para conectar los puntos con una línea azul:
lines(x, sales, type = "l", col = "blue")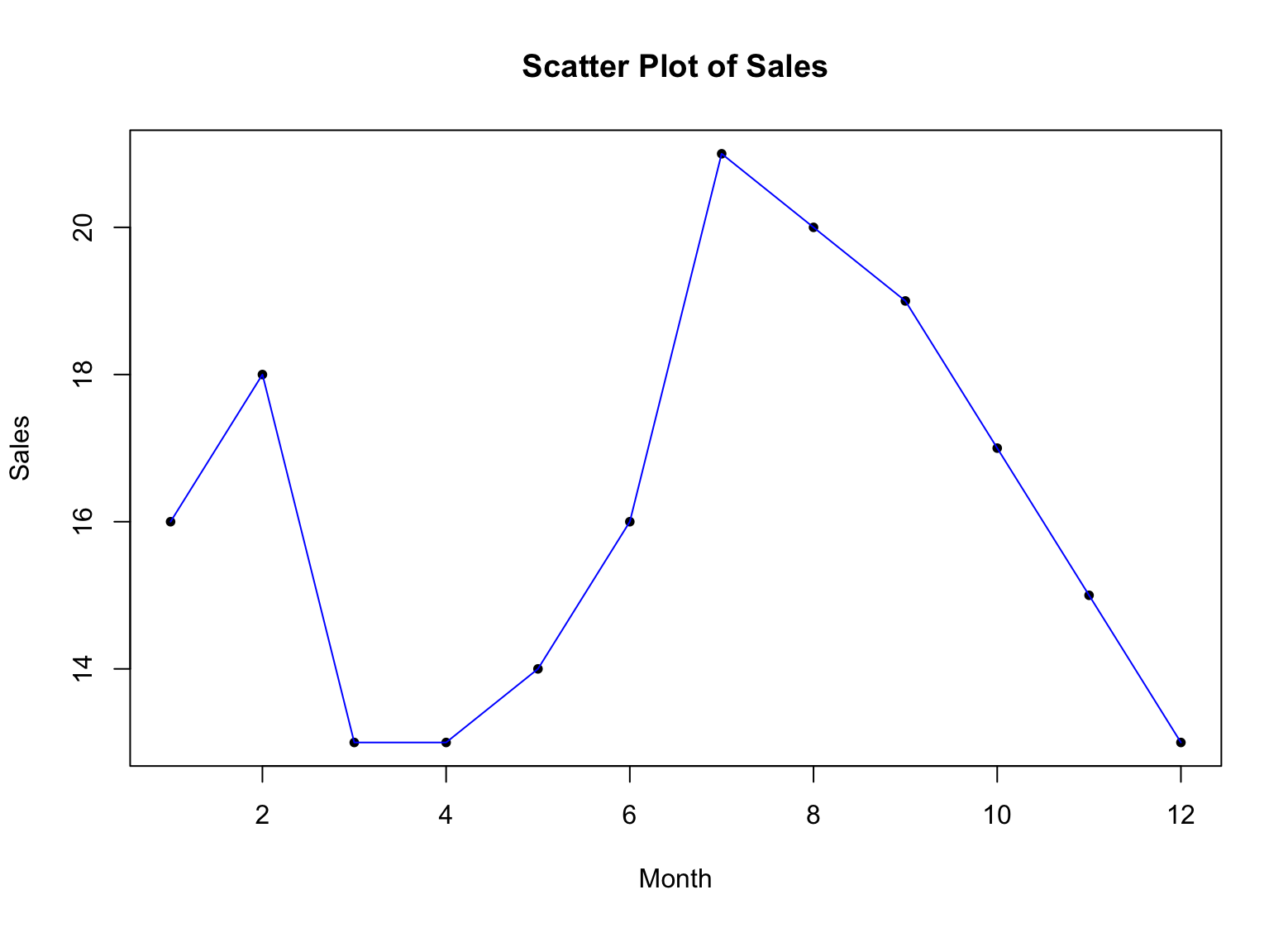
Figura 3: Scatter plot con líneas en R
Bien, ahora ¿cómo interpretamos este gráfico en el contexto de nuestros datos de ventas?
-
Cada punto en el scatter plot representa un dato individual, con el eje x representando los meses y el eje y representando las cifras de ventas.
-
Al observar la distribución de puntos en el scatter plot, puedes tener una idea de cómo se distribuyen las cifras de ventas a lo largo de los meses. Si los puntos están agrupados estrechamente, sugiere que las cifras de ventas son similares entre los meses. Si los puntos están más dispersos, sugiere que las cifras de ventas son más variables entre los meses.
-
Al buscar patrones en la distribución de puntos, puedes identificar tendencias en los datos. Por ejemplo, si los puntos forman una línea recta, sugiere que existe una relación lineal entre los meses y las cifras de ventas. Si los puntos forman una línea curva, sugiere que existe una relación no lineal.
-
Los valores atípicos se representan como puntos individuales que son significativamente diferentes del resto de los datos. Al identificar valores atípicos, puedes ver si hay meses con cifras de ventas significativamente más altas o bajas, lo que puede requerir investigación adicional.
Hagamos nuestro scatter plot más significativo y agreguemos una línea de tendencia usando la función abline():
fit <- lm(sales ~ x)
abline(fit, col = "red")Esto agregará una línea de regresión al gráfico, mostrando la tendencia general en los datos de ventas. El argumento col establece el color de la línea en rojo. Si quieres aprender más sobre regresión, consulta cómo importar datos CSV en R para preparar tus propios conjuntos de datos.
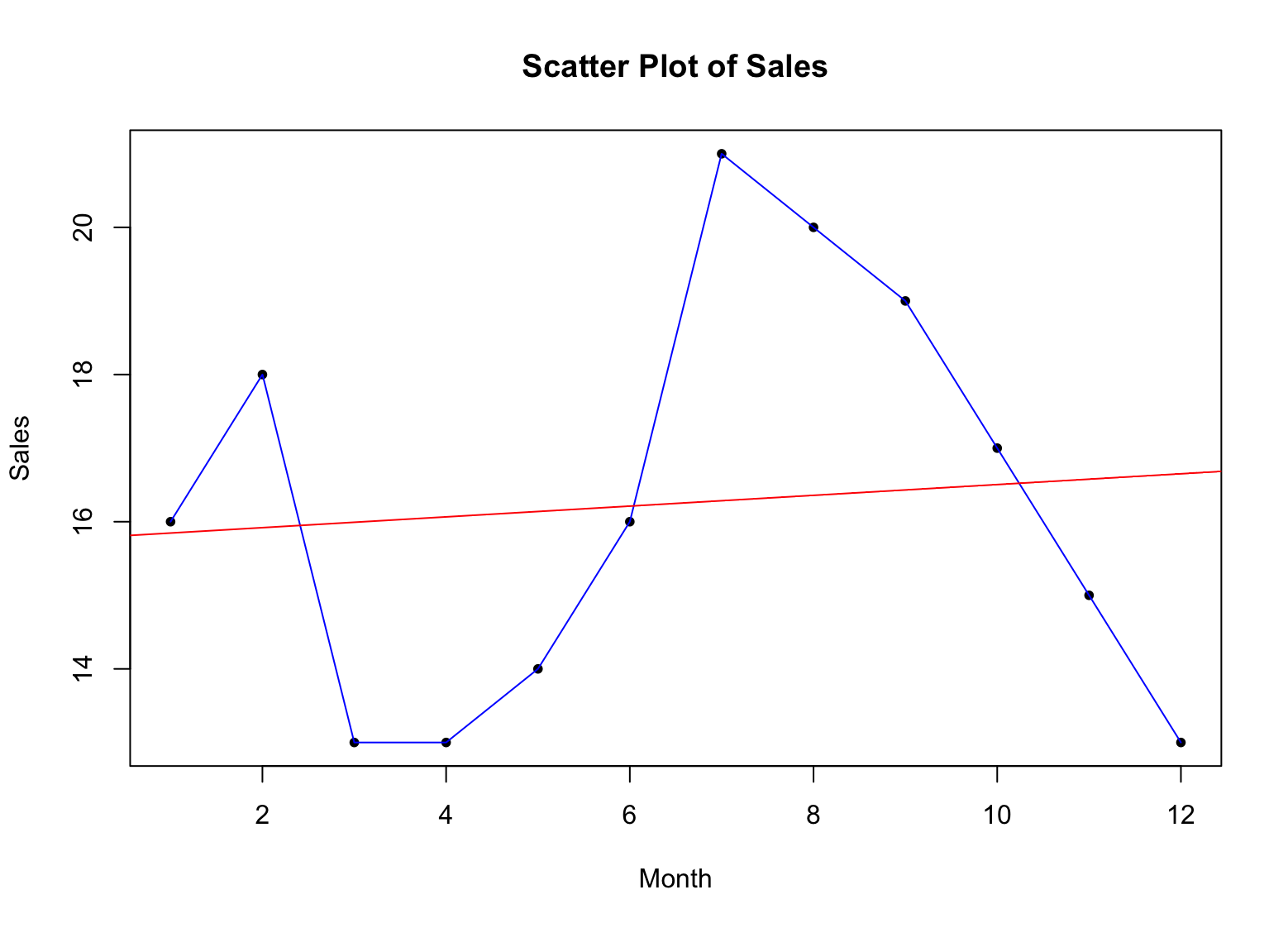
Figura 4: Scatter plot con línea de tendencia en R
Paso 10: Crea un Box Plot
En R, puedes crear un box plot (diagrama de caja y bigotes) usando la función boxplot(). La sintaxis básica es la siguiente:
boxplot(x, main = "Box and Whisker Plot", xlab = "Group", ylab = "Value", col = "blue")Aquí, x es la variable que quieres graficar, main es el título del gráfico, xlab e ylab son las etiquetas para el eje x y el eje y, respectivamente, y col es el color del boxplot.
Por ejemplo, para crear un box plot de los datos de ventas, puedes usar el siguiente código:
boxplot(sales, main = "Box and Whisker Plot of Sales", xlab = "Month", ylab = "Sales", col = "blue")Esto creará un box plot de los datos de ventas, con los meses en el eje x y las cifras de ventas en el eje y. El argumento col establece el color del boxplot en azul.
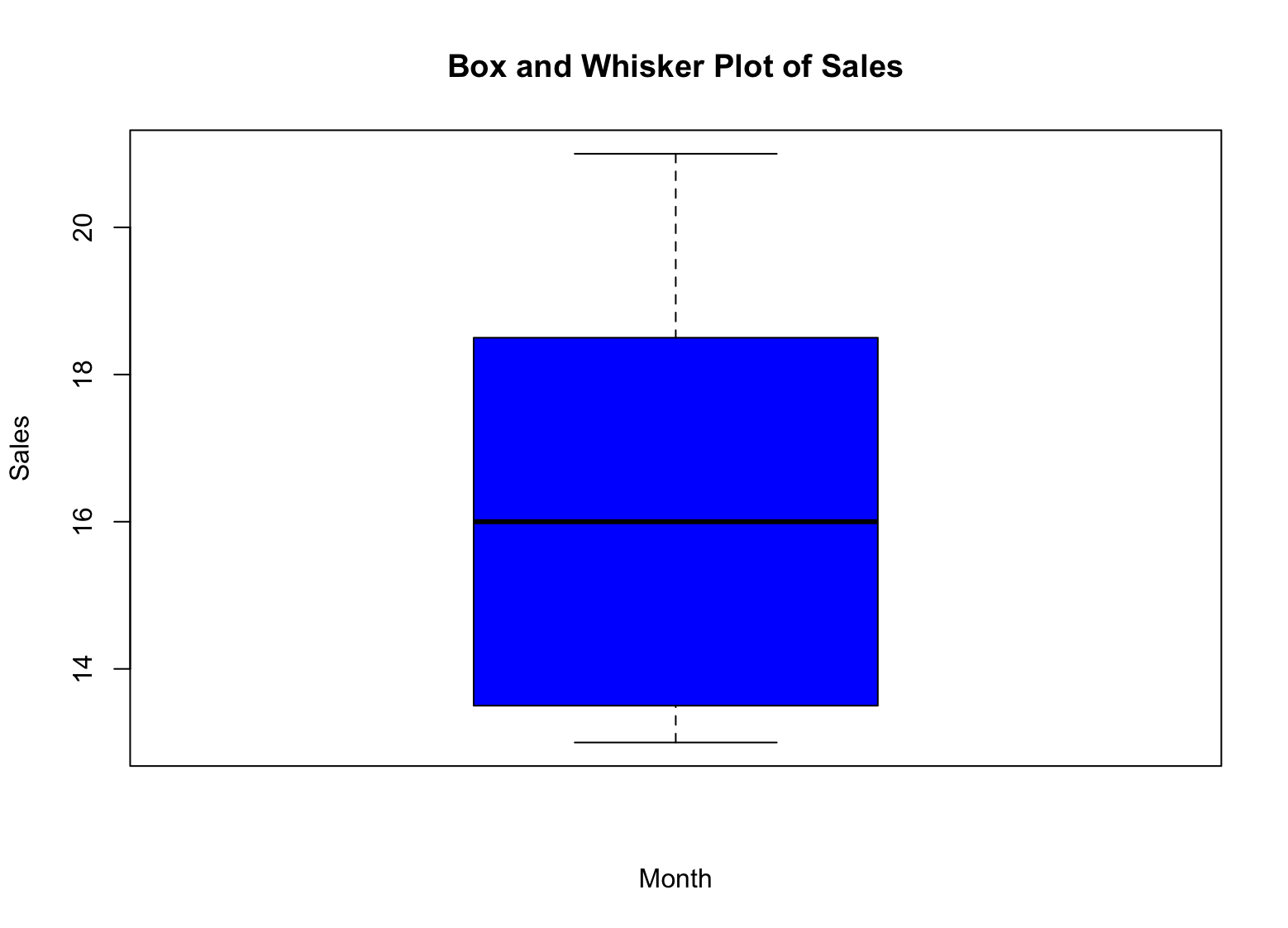
Figura 5: Box plot de ventas en R
Entonces, ¿cómo interpretamos el box plot para nuestros datos de ventas?
-
La caja representa el rango intercuartílico (IQR), que es el rango entre el primer y tercer cuartil (percentiles 25 y 75) de los datos. La altura de la caja representa el IQR.
-
La mediana se representa con una línea dentro de la caja. Es el valor que separa las mitades superior e inferior de los datos.
-
Los bigotes representan los valores mínimo y máximo de los datos, excluyendo cualquier valor atípico. Los valores atípicos se representan como puntos individuales fuera de los bigotes.
-
Los valores atípicos son puntos individuales fuera de los bigotes. Representan valores que son significativamente diferentes del resto de los datos.
Al analizar el box plot de los datos de ventas, puedes ver rápidamente la distribución de las cifras de ventas del año. Puedes observar dónde se encuentra la mediana, el rango de valores (IQR) y cualquier posible valor atípico. Esta información te ayuda a tomar decisiones informadas sobre tus datos e identificar áreas que pueden requerir investigación adicional. Para profundizar en la verificación de normalidad en SPSS, consulta nuestra guía dedicada.
Preguntas Frecuentes
Próximos Pasos
Ahora que dominas las estadísticas descriptivas en R, el siguiente paso lógico es verificar si tus datos siguen una distribución normal. Consulta nuestra guía sobre pruebas de normalidad en R para aprender a evaluar la distribución de tus datos antes de elegir pruebas estadísticas.
Si prefieres avanzar hacia el modelado, revisa nuestro ejemplo de regresión lineal en R para aprender a identificar relaciones entre variables.
Referencias
- R Core Team (2024). R: A language and environment for statistical computing. R Foundation for Statistical Computing.
- Wickham, H. (2016). ggplot2: Elegant graphics for data analysis. Springer-Verlag.