Tutorial de regresión lineal en SPSS que cubre cómo ejecutar, calcular e interpretar el análisis de regresión en SPSS. Esta guía demuestra cómo calcular la regresión lineal en SPSS usando instrucciones paso a paso con un conjunto de datos de ejemplo.
Aprenderás cómo ejecutar la regresión lineal en SPSS, interpretar los resultados de la ecuación de regresión en SPSS y comprender estadísticas clave como R cuadrado, ANOVA y coeficientes. Este tutorial se enfoca en el análisis de regresión lineal simple en SPSS: la técnica fundamental de análisis de regresión en SPSS para examinar relaciones entre dos variables.
Qué es el análisis de regresión lineal
La regresión lineal es un método estadístico fundamental para examinar la relación entre variables. Utiliza una línea de regresión (también llamada línea de mínimos cuadrados) para modelar cómo una o más variables independientes (predictoras) influyen en una variable dependiente (resultado).
La regresión lineal es una de las técnicas de modelado predictivo más utilizadas en investigación y análisis de datos, lo que la hace esencial para estudiantes, investigadores y científicos de datos.
Como su nombre indica, la regresión lineal usa una línea (también llamada línea de regresión) para medir la relación entre una o más variables. Piensa en esta relación como la causa (variable independiente) y el efecto (variable dependiente) donde la regresión lineal genera una línea para mostrar el resultado.
En estadística, la variable independiente frecuentemente se llama variable predictora o explicativa. La variable dependiente a veces se denomina variable predicha o de resultado.
Existen dos tipos de regresión lineal:
- Regresión lineal simple usa UNA variable independiente para predecir un resultado
- Regresión lineal múltiple usa dos o más variables independientes
Este tutorial se enfoca en el análisis de regresión lineal simple. En investigación, la relación de predicción se formula a través de una hipótesis; por ejemplo, investigar el impacto de la publicidad sobre los ingresos.
Importar datos en SPSS
Como este es un tutorial práctico sobre cómo calcular un análisis de regresión lineal en SPSS, necesitaremos algunos datos para generar una línea de regresión.
Descarga el conjunto de datos de ejemplo a continuación para seguir este tutorial.
Supongamos que queremos investigar el efecto de la Publicidad sobre las Ventas de una empresa determinada. Así es como se ve el conjunto de datos de ejemplo en Excel que descargaste arriba.
Asumiendo que descargaste el conjunto de datos de Excel, abre SPSS Statistics y en el menú superior navega a Archivo → Importar datos → Excel.
Busca la ubicación del archivo de ejemplo en Excel, selecciónalo y haz clic en Abrir. Haz clic en Aceptar cuando se te pida leer el archivo de Excel. Una vez que el conjunto de datos se importa en SPSS, debería verse así:
Ahora, veamos cómo calcular la regresión lineal en SPSS. En el menú superior de SPSS navega a Analizar → Regresión → Lineal.
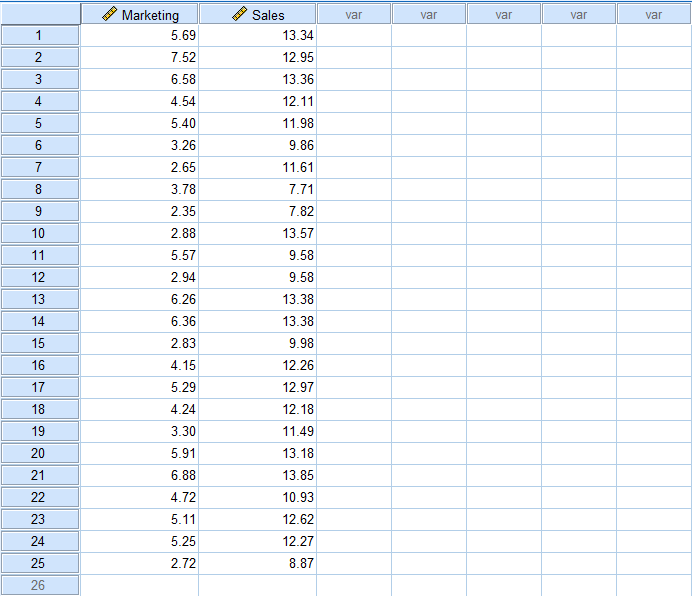 Figura 1: Acceso a la regresión lineal en SPSS mediante Analizar → Regresión → Lineal.
Figura 1: Acceso a la regresión lineal en SPSS mediante Analizar → Regresión → Lineal.
A continuación, debemos indicarle a SPSS cuál es nuestra variable dependiente e independiente en el conjunto de datos.
Recuerda, en la regresión lineal investigamos una relación causal entre una variable independiente y una variable dependiente. En nuestro ejemplo de Excel, la variable independiente es Marketing (causa) y la variable dependiente es Ventas (efecto). En otras palabras, queremos predecir si la variable Ventas se ve afectada por cambios en la variable Marketing.
En la ventana de Regresión Lineal, selecciona la variable Ventas y haz clic en el botón de flecha junto al cuadro Dependiente para agregar Ventas como variable dependiente en el análisis de regresión.
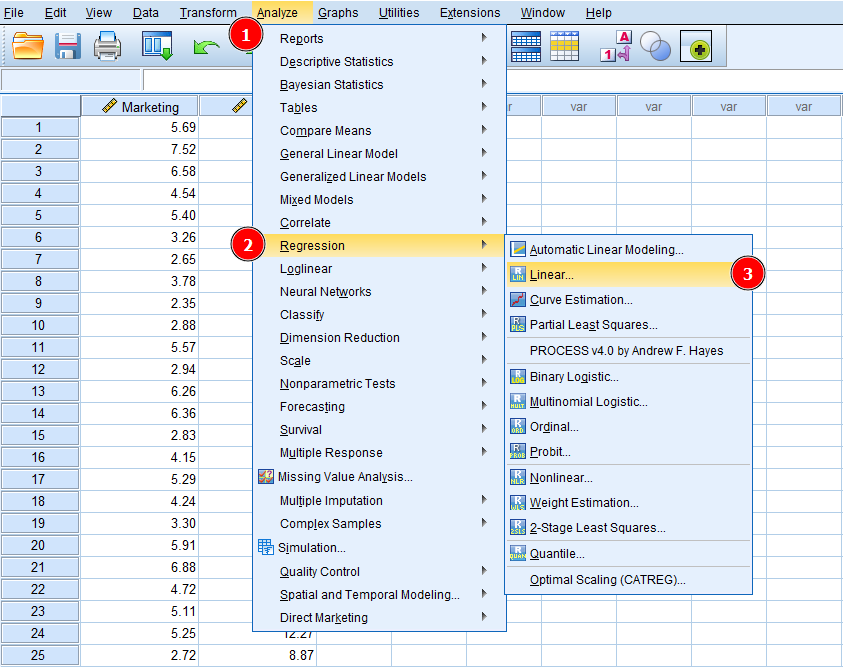 Figura 2: Agregando la variable dependiente (Ventas) en la regresión lineal de SPSS.
Figura 2: Agregando la variable dependiente (Ventas) en la regresión lineal de SPSS.
Haz lo mismo con la variable Marketing pero esta vez haz clic en la flecha junto al cuadro Independiente. Tu ventana de análisis de regresión debería verse así:
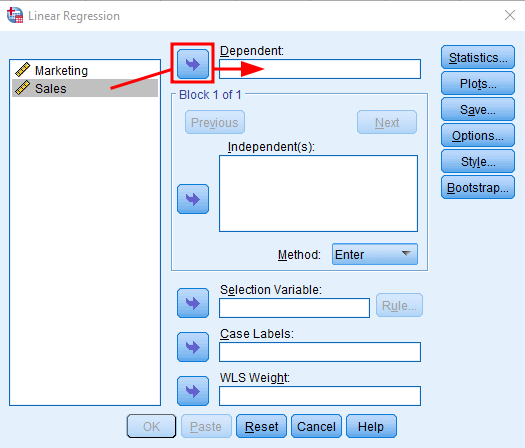 Figura 3: Agregando la variable independiente (Marketing) en la regresión lineal de SPSS.
Figura 3: Agregando la variable independiente (Marketing) en la regresión lineal de SPSS.
Podemos usar otras opciones de entrada para personalizar el análisis de regresión lineal, como Método, Estadísticas, Gráficos, Estilo, etc. Por ahora, mantendremos la configuración predeterminada ya que es suficiente para este caso.
Haz clic en Aceptar para iniciar el análisis. Y así es como se ven los resultados del análisis de regresión lineal en SPSS:
 Figura 4: Resultados completos de la regresión lineal en SPSS con todas las estadísticas clave.
Figura 4: Resultados completos de la regresión lineal en SPSS con todas las estadísticas clave.
Los resultados muestran las variables independientes y dependientes utilizadas en este análisis, el Resumen del modelo, ANOVA, Coeficientes y las estadísticas asociadas. Veamos qué nos dicen los resultados del análisis de regresión.
Interpretación de los resultados del análisis de regresión lineal
Esta sección explica el significado de cada término y valor en los resultados de SPSS, enfocándose en los aspectos más importantes para tu análisis de investigación.
-
La tabla de Variables introducidas/eliminadas muestra un resumen descriptivo del análisis de regresión lineal.
-
Modelo 1 (Introducir) simplemente significa que todas las variables solicitadas se ingresaron en un solo paso y reciben igual importancia. El modelo Introducir se usa comúnmente en el análisis de regresión, razón por la cual Modelo 1 es el modelo de regresión predeterminado en SPSS.
-
Variables introducidas muestra la variable independiente (Marketing) utilizada en este análisis. No se eliminaron variables, por lo tanto la columna Variables eliminadas está en blanco.
-
En SPSS, la variable dependiente, en nuestro caso Ventas, se especifica debajo de la tabla descriptiva.
-
La tabla Resumen del modelo nos muestra un resumen de los resultados del análisis de regresión en SPSS.
 Figura 5: Tabla de Resumen del modelo en los resultados de regresión lineal de SPSS.
Figura 5: Tabla de Resumen del modelo en los resultados de regresión lineal de SPSS.
- R se refiere a la correlación entre las variables. La correlación es importante para el análisis de regresión porque podemos suponer que una variable afecta a otra si ambas variables están correlacionadas. Si dos variables no están correlacionadas, probablemente no tiene sentido buscar una relación de causa y efecto.
La correlación no garantiza una relación de causa y efecto, pero es una condición necesaria para que exista una relación causal.
El valor de R varía de -1 a +1, donde -1 es una correlación negativa perfecta, +1 es una correlación positiva perfecta y 0 representa ninguna correlación lineal entre variables.
En nuestro caso, R = 0.663 muestra que las variables Marketing y Ventas están correlacionadas.
-
R cuadrado mide la influencia total de las variables independientes sobre la variable dependiente. Ten en cuenta que el valor de R cuadrado se expresa en porcentaje (%). Por ejemplo, en nuestro caso, R cuadrado = 0.440, lo que significa que el 44% de las Ventas están influenciadas por la estrategia de Marketing de la empresa.
-
R cuadrado ajustado es una penalización que se aplica cuando tu modelo no es parsimonioso (no es simple o eficiente). En palabras simples, si tu marco conceptual de investigación contiene variables innecesarias para predecir un resultado, habrá una penalización expresada en el valor de R cuadrado ajustado.
En nuestro ejemplo, la diferencia entre el R cuadrado ajustado (0.416) y el R cuadrado (0.440) es 0.024, lo cual es insignificante.
Recuerda, debemos buscar explicaciones simples y no complicadas para el fenómeno bajo investigación.
- Error estándar de la estimación se refiere a qué tan precisa es la predicción alrededor de la línea de regresión. Si tu valor de Error estándar está entre -2 y +2, entonces la línea de regresión se considera cercana al valor verdadero.
En nuestro caso, el Error estándar de la estimación = 1.40, lo cual es un buen resultado.
- La prueba ANOVA es un precursor del análisis de regresión lineal. En otras palabras, nos indica si los resultados de la regresión lineal obtenidos con nuestra muestra pueden generalizarse a la población que la muestra representa.
Ten en cuenta que para que un análisis de regresión lineal sea válido, el resultado de ANOVA debe ser significativo (p < 0.05). Además, los modelos de regresión deben cumplir supuestos clave como la homocedasticidad (varianza constante), linealidad y normalidad de los residuos.
 Figura 6: Tabla ANOVA en los resultados de regresión lineal de SPSS.
Figura 6: Tabla ANOVA en los resultados de regresión lineal de SPSS.
- Suma de cuadrados mide cuánto se desvían los puntos de datos de tu conjunto respecto a la línea de regresión y te ayuda a entender qué tan bien un modelo de regresión representa los datos modelados.
La regla general para la Suma de cuadrados de Regresión y Residual es que cuanto menor sea el valor, mejor representan los datos tu modelo.
Ten en cuenta que la Suma de cuadrados siempre será un número positivo, donde 0 es el valor más bajo y representa el mejor ajuste del modelo.
- gl en ANOVA significa grados de libertad. En palabras simples, gl muestra el número de valores independientes que se usaron para calcular la estimación.
Ten en cuenta que un tamaño de muestra menor generalmente significa menos grados de libertad (como en nuestro ejemplo). Por el contrario, un tamaño de muestra mayor permite más grados de libertad, lo que puede ser útil para rechazar una hipótesis nula falsa y obtener un resultado significativo.
-
Media cuadrática en ANOVA se usa para determinar la significancia de los tratamientos (factores, respectivamente la variación entre las medias muestrales). La Media cuadrática es importante para calcular la razón F.
-
La prueba F en ANOVA se usa para determinar si las medias entre dos poblaciones son significativamente diferentes. El valor F calculado a partir de los datos (F=18.071) generalmente se denomina estadístico F y es útil cuando se evalúa el rechazo de una hipótesis nula.
-
Sig. significa Significancia. Si no quieres entrar en los detalles técnicos de la prueba ANOVA, esta es probablemente la columna del resultado de ANOVA que deseas revisar primero. Un valor Sig. < 0.05 se considera significativo. En nuestro ejemplo, Sig. = 0.000, que es menor que 0.05 y por lo tanto significativo.
Finalmente, estamos listos para pasar a la tabla de resultados del análisis de regresión en SPSS.
- En la tabla de Coeficientes, solo un valor es esencial para la interpretación: el valor Sig. (la última columna), así que comencemos con él.
 Figura 7: Tabla de Coeficientes en los resultados de regresión lineal de SPSS.
Figura 7: Tabla de Coeficientes en los resultados de regresión lineal de SPSS.
- Sig. (también conocido como valor p) muestra el nivel de significancia que la variable independiente tiene sobre la variable dependiente. Similar a ANOVA, si el valor Sig. es < 0.05, existe significancia entre las variables en la regresión lineal.
En nuestro caso, Sig. = 0.000 muestra una fuerte significancia entre la variable independiente (Marketing) y la variable dependiente (Ventas).
- B no estandarizado (Beta) básicamente representa la pendiente de la línea de regresión entre las variables independiente y dependiente, e indica cuánto aumentará la variable dependiente por cada unidad de aumento en la variable independiente.
En nuestro caso, por cada unidad de aumento en Marketing, las Ventas aumentarán 0.808. La unidad de aumento puede expresarse, por ejemplo, en moneda.
La fila Constante en la tabla de Coeficientes muestra el valor de la variable dependiente cuando la variable independiente = 0.
- El Error estándar de los coeficientes es similar a la desviación estándar para una media.
Cuanto mayor sea el valor del Error estándar, más dispersos estarán los puntos de datos sobre la línea de regresión. Cuanto más dispersos estén los puntos de datos, menos probable será encontrar significancia entre las variables.
- El valor de Beta de coeficientes estandarizados varía de -1 a +1, donde 0 significa ninguna relación; de 0 a -1 indica una relación negativa y de 0 a +1 una relación positiva. Cuanto más cercano esté el valor Beta del coeficiente estandarizado a -1 o +1, más fuerte será la relación entre las variables.
En nuestro caso, el coeficiente Beta estandarizado = 0.663 muestra una relación positiva entre la variable independiente (Marketing) y la variable dependiente (Ventas).
- t representa la prueba t y se usa para calcular el valor p (Sig.). En términos generales, la prueba t se usa para comparar el valor medio de dos conjuntos de datos y determinar si provienen de la misma población.
Preguntas frecuentes
Conclusión
Como puedes ver, aprender cómo calcular la regresión lineal en SPSS no es difícil. Por otro lado, entender los resultados de la regresión lineal puede ser un poco desafiante, especialmente si no sabes cuáles valores son relevantes para tu análisis.
Lo más importante a tener en cuenta al evaluar el resultado de tu análisis de regresión lineal es buscar significancia estadística (Sig. < 0.05).
Antes de ejecutar la regresión, considera revisar tus datos con estadísticas descriptivas en SPSS para verificar valores atípicos, asimetría y problemas de normalidad que podrían afectar tus resultados.
Para técnicas de regresión avanzadas, explora el análisis de moderación en SPSS para probar efectos de interacción entre variables.