Todo análisis de datos para una tesis comienza con estadísticas descriptivas. Antes de ejecutar pruebas t, ANOVA o regresión, necesitas saber cómo se ven realmente tus datos: las medias, las desviaciones estándar, la forma de las distribuciones, y si hay algo inusual con valores faltantes o atípicos.
SPSS ofrece tres procedimientos distintos para esto, y la mayoría de los estudiantes solo conoce uno. Esta guía cubre los tres (Descriptives, Frequencies y Explore), te muestra cómo leer el output, e incluye plantillas de reporte en formato APA 7.ª edición para tu capítulo de Resultados.
Puntos clave:
- SPSS ofrece tres procedimientos para estadísticas descriptivas: Descriptives (resúmenes numéricos rápidos), Frequencies (datos categóricos y conteos de frecuencia), y Explore (análisis a profundidad con pruebas de normalidad y gráficos)
- Valores de asimetría entre -1 y +1 sugieren normalidad aproximada; valores más allá de -2 o +2 indican desviación sustancial
- Reporta media y DE para variables continuas con distribución normal; reporta mediana y RIC para datos asimétricos o variables ordinales
- El procedimiento Explore es la opción más completa: produce intervalos de confianza, pruebas Shapiro-Wilk, boxplots y Q-Q plots en una sola ejecución
- Siempre reporta las estadísticas descriptivas antes de los análisis inferenciales en tu capítulo de Resultados
Antes de comenzar: Esta guía asume que tienes SPSS instalado y tus datos ingresados en la Vista de Datos con las variables definidas correctamente en la Vista de Variables. Si necesitas verificar la confiabilidad de una escala de múltiples ítems antes de resumirla, consulta nuestra guía sobre Alfa de Cronbach en SPSS.
Conjunto de Datos de Ejemplo
Este tutorial utiliza un conjunto de datos de tesis con 150 encuestados que puedes descargar desde la barra lateral y seguir paso a paso. El conjunto incluye seis variables comúnmente encontradas en investigaciones de ciencias sociales:
- Satisfaction (Escala, 1.00 a 5.00) y GPA (Escala, 1.80 a 4.00): variables continuas con distribuciones aproximadamente normales, utilizadas para los procedimientos Descriptives y Explore
- StudyHours (Escala, 3.40 a 35.00): una variable continua con distribución asimétrica a la derecha y dos valores atípicos leves, útil para demostrar cómo aparece la asimetría en el output de SPSS y cómo los valores atípicos se muestran en los boxplots de Explore
- Gender (Nominal, 1 = Masculino, 2 = Femenino) y EducationLevel (Ordinal, 1 = Preparatoria, 2 = Licenciatura, 3 = Maestría): variables categóricas utilizadas para el procedimiento Frequencies
- Age (Escala, 18 a 40): una variable continua adicional para mayor variedad en el output de Descriptives
El conjunto de datos incluye intencionalmente de 2 a 3 valores faltantes por variable para que puedas ver cómo SPSS maneja los datos faltantes en el output (la columna N válido).
Si abres el archivo .sav, las variables ya están configuradas en la Vista de Variables con los niveles de medición y etiquetas de valor correctos. Si importaste la versión .xlsx, necesitarás configurarlos manualmente. Cambia a la Vista de Variables (pestaña en la parte inferior de la ventana de SPSS) y verifica lo siguiente:

Figura 1: Configuración de la Vista de Variables: Satisfaction, StudyHours, GPA y Age configurados como Escala; Gender como Nominal con etiquetas de valor (1 = Masculino, 2 = Femenino); EducationLevel como Ordinal con etiquetas de valor (1 = Preparatoria, 2 = Licenciatura, 3 = Maestría)
Configurar el nivel de medición correctamente es importante. Si una variable continua está incorrectamente establecida como Nominal, algunos procedimientos de SPSS la excluirán o producirán resultados sin sentido. Si una variable categórica se deja como Escala, SPSS calculará una media sin advertencia (ver Error Común #1 más adelante).
¿Qué Son las Estadísticas Descriptivas?
Las estadísticas descriptivas resumen tu conjunto de datos sin hacer inferencias sobre una población mayor. Responden las preguntas más básicas sobre tus variables: ¿cuál es el promedio? ¿Qué tan dispersos están los valores? ¿La distribución es simétrica o sesgada?
Estas medidas se dividen en cuatro categorías:
Tendencia central indica dónde se encuentra el centro de tus datos. La media (promedio aritmético) es la más común, seguida de la mediana (el valor central cuando se ordenan) y la moda (el valor más frecuente). Cuál reportar depende de la forma de tu distribución.
Dispersión (variabilidad) captura qué tan dispersos están los valores. La desviación estándar es la medida principal, pero también encontrarás el rango, la varianza y el rango intercuartílico (RIC) en el output de SPSS.
Forma de la distribución describe si tus datos son simétricos o asimétricos. La asimetría (skewness) cuantifica la falta de simetría, mientras que la curtosis (kurtosis) mide qué tan pesadas o ligeras son las colas comparadas con una distribución normal. Ambas importan para decidir qué pruebas inferenciales son apropiadas.
Posición ubica valores específicos en relación con el resto de los datos: percentiles, cuartiles y puntuaciones z.
Por Qué las Estadísticas Descriptivas Importan para Tu Tesis
Para el trabajo de tesis específicamente, las estadísticas descriptivas cumplen tres funciones que tu comité espera ver:
Primero, caracterizan tu muestra. Tus lectores necesitan saber quiénes participaron, cómo se ven las distribuciones de puntajes, y si algo destaca. Esta sección típicamente abre tu capítulo de Resultados o cierra tu capítulo de Método.
Segundo, verifican tus supuestos. Las pruebas t, ANOVA y regresión asumen normalidad aproximada. La asimetría, curtosis y los gráficos visuales de SPSS te ayudan a evaluar si esos supuestos se cumplen antes de ejecutar las pruebas propiamente.
Tercero, revelan problemas de calidad de datos. Valores faltantes, atípicos, puntajes imposibles (un 6 en una escala Likert de 1 a 5) y patrones inesperados aparecen en el output descriptivo. Detectar estos problemas temprano te evita ejecutar análisis sobre datos defectuosos.
¿Qué Procedimiento de SPSS Deberías Usar?
SPSS tiene tres procedimientos bajo Analizar > Estadísticos descriptivos, y no son intercambiables. La mayoría de los análisis de tesis requieren al menos dos de ellos.
| Procedimiento | Ideal Para | El Output Incluye | Úsalo Cuando |
|---|---|---|---|
| Descriptives | Resúmenes numéricos rápidos de variables continuas | Media, DE, mínimo, máximo, varianza, asimetría, curtosis | Necesitas una tabla resumen compacta para varias variables numéricas a la vez |
| Frequencies | Datos categóricos y distribuciones de frecuencia | Tablas de frecuencia, porcentajes, porcentajes acumulados, media, mediana, moda | Tienes variables nominales/ordinales, o necesitas la mediana y la moda para variables continuas |
| Explore | Investigación a profundidad de variables | Intervalos de confianza, pruebas de normalidad (Shapiro-Wilk, K-S), boxplots, stem-and-leaf, Q-Q plots, identificación de atípicos | Necesitas verificar supuestos de normalidad, identificar atípicos o producir gráficos de calidad publicable |
Tabla 1: Comparación de los tres procedimientos de estadísticas descriptivas en SPSS
Para una tesis típica, ejecuta Descriptives primero para obtener un panorama rápido de tus variables continuas. Luego ejecuta Frequencies para cualquier variable categórica u ordinal. Finalmente, usa Explore en tus variables continuas clave para verificar normalidad e identificar atípicos antes de pasar a las pruebas inferenciales.
Procedimiento 1: Descriptives (Resumen Numérico Rápido)
Descriptives es el más simple de los tres. Calcula estadísticas de resumen básicas para variables continuas (de escala) y las muestra en una sola tabla. Si necesitas un panorama compacto de varias variables lado a lado, comienza aquí.
Paso 1: Abre el Cuadro de Diálogo de Descriptives
Navega a Analizar > Estadísticos descriptivos > Descriptivos desde el menú superior.
Figura 2: Navegación al procedimiento Descriptives en SPSS
Paso 2: Selecciona Tus Variables
En el cuadro de diálogo de Descriptives, mueve las variables continuas que quieres resumir del panel izquierdo a la lista de Variable(s) en la derecha. Puedes seleccionar múltiples variables a la vez manteniendo presionada la tecla Ctrl (Cmd en Mac) y haciendo clic en cada variable, luego haz clic en el botón de flecha.
Figura 3: Cuadro de diálogo de Descriptives con las variables movidas a la lista de Variable(s)
Paso 3: Configura las Opciones
Haz clic en el botón Opciones para personalizar qué estadísticas calcula SPSS. Por defecto, SPSS calcula la media, desviación estándar, mínimo y máximo. En el cuadro de Opciones, puedes habilitar adicionalmente:
- Varianza (el cuadrado de la desviación estándar)
- Rango (máximo menos mínimo)
- E.T. media (error estándar de la media)
- Asimetría (simetría de la distribución)
- Curtosis (peso de las colas relativo a la normal)
Para el trabajo de tesis, habilita Asimetría y Curtosis como mínimo. Estos valores son esenciales para evaluar si tus datos se aproximan a una distribución normal, requisito que la mayoría de las pruebas paramétricas exigen.
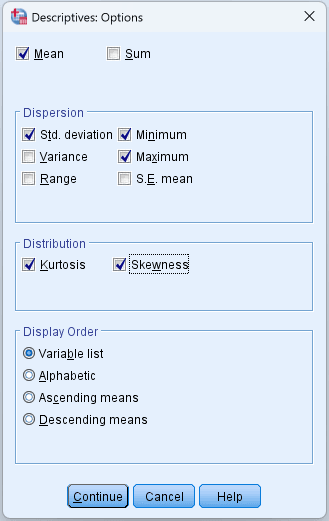
Figura 4: Cuadro de diálogo Opciones de Descriptives con asimetría y curtosis habilitados
Haz clic en Continuar para regresar al cuadro principal, luego haz clic en Aceptar para ejecutar el análisis.
Paso 4: Interpreta el Output
SPSS produce una tabla única de Estadísticas Descriptivas con una fila por variable.
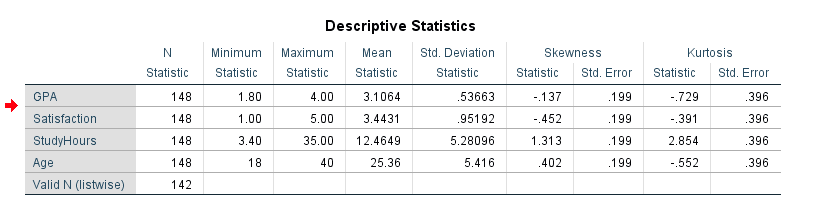
Figura 5: Tabla de Estadísticas Descriptivas en el output de SPSS
Cómo leer cada columna:
- N es el número de casos válidos (no faltantes). Compáralo con el tamaño de muestra esperado. Si los números difieren, tienes datos faltantes que necesitan atención.
- Mínimo / Máximo muestran los valores observados más pequeño y más grande. Verifica estos contra el rango esperado de tus datos. Un puntaje de 6 en una escala Likert de 1 a 5, por ejemplo, señala un error de captura.
- Media es el promedio aritmético. Para datos con distribución normal, esta es la mejor medida de tendencia central.
- Desv. típ. (desviación estándar) cuantifica qué tan lejos caen típicamente las observaciones de la media. Una DE muy grande relativa a la media frecuentemente apunta a alta variabilidad o valores atípicos que jalan la distribución.
- Asimetría mide la falta de simetría de la distribución. Consulta la guía de interpretación más adelante.
- Curtosis mide el peso de las colas. Consulta la guía de interpretación más adelante.
Procedimiento 2: Frequencies (Datos Categóricos y Conteos)
Frequencies es lo que necesitas para variables categóricas (género, nivel educativo, grupo de tratamiento) y para cualquier situación donde quieras conteos y porcentajes. También calcula la mediana y la moda para variables continuas, algo que Descriptives no ofrece. Si tienes ítems de escala Likert y quieres ver cómo se distribuyen las respuestas a lo largo de la escala, este es el procedimiento indicado.
Paso 1: Abre el Cuadro de Diálogo de Frequencies
Navega a Analizar > Estadísticos descriptivos > Frecuencias.
Paso 2: Selecciona Variables y Configura los Estadísticos
Mueve tus variables a la lista de Variable(s). Haz clic en el botón Estadísticos para elegir qué medidas de resumen calcular.
Para variables categóricas (nominales/ordinales), la tabla de frecuencias por defecto es generalmente suficiente. También puedes habilitar la Moda para identificar la categoría más común.
Para variables continuas donde necesitas la mediana, marca las siguientes opciones bajo Estadísticos:
- Media, Mediana, Moda (bajo Tendencia central)
- Desv. típ., Varianza, Rango (bajo Dispersión)
- Asimetría, Curtosis (bajo Distribución)
- Cuartiles o Percentil(es) específicos si los necesitas
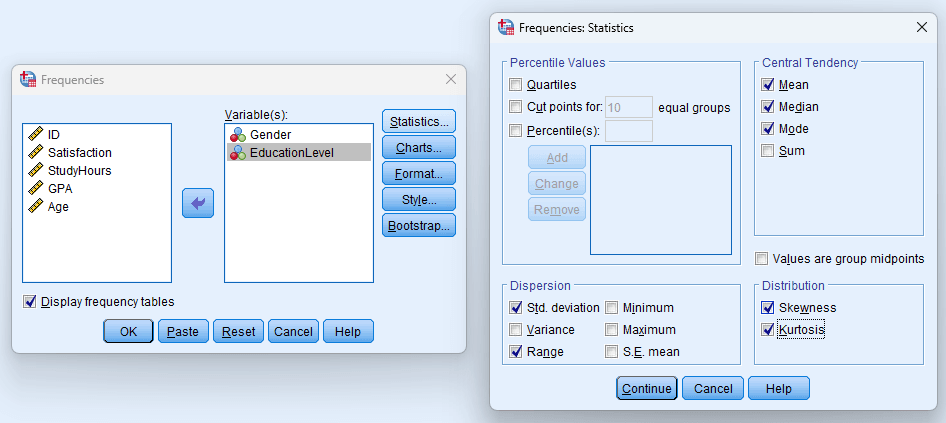
Figura 6: Cuadro de diálogo Estadísticos de Frequencies con las opciones recomendadas para análisis de tesis
Paso 3: Interpreta el Output
Frequencies produce dos tipos de output:
Tabla de estadísticos: Una tabla resumen que muestra las medidas que seleccionaste (media, mediana, moda, DE, asimetría, curtosis, N válido, N faltante).
Tabla(s) de frecuencias: Una tabla por variable que muestra cada valor único, su frecuencia (conteo), porcentaje, porcentaje válido (excluyendo faltantes) y porcentaje acumulado.
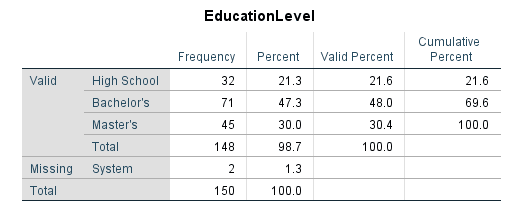
Figura 7: Tabla de frecuencias para una variable categórica
Puntos clave para la interpretación:
- Porcentaje incluye los valores faltantes en el denominador; Porcentaje válido los excluye. Reporta el Porcentaje válido en tu tesis porque refleja la distribución real entre los encuestados que respondieron.
- Porcentaje acumulado muestra el total acumulado. Esto es útil para datos ordinales: "El 73% de los encuestados calificó la satisfacción en 4 o menos en una escala de 5 puntos."
- Para ítems de escala Likert, la tabla de frecuencias frecuentemente es más informativa que la media sola. Una media de 3.5 se ve diferente cuando el 80% de los encuestados eligió 3 o 4, versus cuando las respuestas se dividen entre 1 y 5.
Procedimiento 3: Explore (Análisis a Profundidad)
Explore es el más potente de los tres y el que tu comité probablemente preguntará. Produce pruebas de normalidad (Shapiro-Wilk y Kolmogorov-Smirnov), intervalos de confianza, tablas de valores atípicos y gráficos de calidad publicable (histogramas, boxplots, Q-Q plots) en una sola ejecución.
Paso 1: Abre el Cuadro de Diálogo de Explore
Navega a Analizar > Estadísticos descriptivos > Explorar.
Paso 2: Configura el Análisis
- Mueve tus variables continuas a la Lista de dependientes.
- Opcionalmente, mueve una variable categórica de agrupación a la Lista de factores si quieres estadísticas descriptivas desglosadas por grupo (por ejemplo, descriptivos para hombres vs. mujeres).
- En la sección Mostrar en la parte inferior, selecciona Ambos para generar tanto estadísticas como gráficos.
Paso 3: Configura los Gráficos y Estadísticos
Haz clic en Gráficos para configurar el output visual. Para trabajo de tesis, habilita:
- Histograma (con curva normal superpuesta)
- Gráficos de normalidad con pruebas (produce las pruebas Shapiro-Wilk y Kolmogorov-Smirnov, más Q-Q plots)
Haz clic en Estadísticos para confirmar que:
- Descriptivos está marcado (proporciona media, mediana, varianza, DE, mínimo, máximo, rango, RIC, asimetría, curtosis, e intervalo de confianza del 95% para la media)
- Valores atípicos está marcado (identifica los cinco valores más grandes y más pequeños)
- Percentiles está marcado si necesitas valores de cuartiles o percentiles
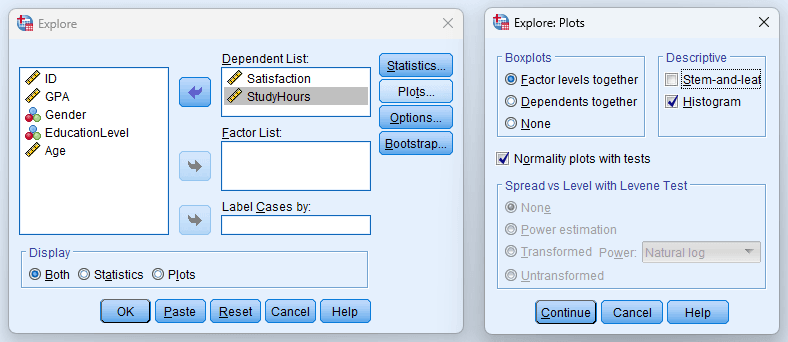
Figura 8: Cuadro de diálogo Gráficos de Explore con las opciones recomendadas para análisis de tesis
Paso 4: Interpreta el Output
El procedimiento Explore produce varias secciones de output:
Tabla de descriptivos: Incluye la media (con intervalo de confianza del 95%), media recortada al 5%, mediana, varianza, desviación estándar, mínimo, máximo, rango, rango intercuartílico, asimetría y curtosis.
Presta atención a la media recortada al 5%. SPSS elimina el 5% superior e inferior de los casos y recalcula la media. Si la media recortada difiere notablemente de la media regular, los valores atípicos están jalando tu promedio en una dirección.
Tabla de Pruebas de Normalidad: Contiene los resultados de las pruebas Kolmogorov-Smirnov (K-S) y Shapiro-Wilk. La prueba Shapiro-Wilk es preferida para muestras menores a 50. Un resultado significativo (p < .05) indica que la distribución se desvía significativamente de la normalidad.
Boxplots: Identifican valores atípicos (círculos) y valores extremos (asteriscos). Los casos que aparecen como atípicos en el boxplot ameritan investigación.
Q-Q Plot: Los puntos que caen a lo largo de la línea diagonal sugieren normalidad. Desviaciones sistemáticas de la línea indican no normalidad.
Cómo Interpretar la Asimetría y Curtosis
Estos dos valores aparecen tanto en el output de Descriptives como de Explore, y determinan si puedes proceder con pruebas paramétricas o necesitas considerar alternativas.
Interpretación de la Asimetría
| Valor de Asimetría | Interpretación | Implicación |
|---|---|---|
| Aproximadamente 0 | Distribución simétrica | Los datos son aproximadamente normales (bien) |
| Positivo (> 0) | Asimetría a la derecha (positiva) | La cola se extiende hacia la derecha; la mayoría de los valores se agrupan a la izquierda |
| Negativo (< 0) | Asimetría a la izquierda (negativa) | La cola se extiende hacia la izquierda; la mayoría de los valores se agrupan a la derecha |
| Entre -1 y +1 | Aproximadamente normal | Aceptable para la mayoría de las pruebas paramétricas |
| Entre -2 y +2 | Moderadamente asimétrica | Aceptable con precaución; algunas pruebas son robustas a este nivel |
| Más allá de -2 o +2 | Sustancialmente asimétrica | Considera transformación de datos o alternativas no paramétricas |
Tabla 2: Guía de interpretación de valores de asimetría
Interpretación de la Curtosis
SPSS reporta la curtosis de exceso, lo que significa que la distribución normal tiene un valor de curtosis de 0 (no 3, que es la curtosis matemática de una distribución normal).
| Valor de Curtosis | Interpretación | Implicación |
|---|---|---|
| Aproximadamente 0 | Mesocúrtica (pico normal) | Las colas son similares a una distribución normal |
| Positivo (> 0) | Leptocúrtica (colas pesadas) | Más valores extremos que una distribución normal; posibles atípicos |
| Negativo (< 0) | Platicúrtica (colas ligeras) | Menos valores extremos que una distribución normal |
| Entre -1 y +1 | Aproximadamente normal | Aceptable para pruebas paramétricas |
| Más allá de -2 o +2 | Sustancialmente no normal | Investiga los atípicos; considera transformación |
Tabla 3: Guía de interpretación de valores de curtosis
Como regla práctica: si tanto la asimetría como la curtosis caen dentro del rango -1 a +1, procede con pruebas paramétricas. Si alguno de los valores excede -2 o +2, considera transformación de datos (logarítmica, raíz cuadrada) o cambia a alternativas no paramétricas. Valores entre -1 y -2 (o +1 y +2) son una decisión de juicio que depende de tu tamaño de muestra y la robustez de la prueba elegida.
Reporte de Estadísticas Descriptivas en Formato APA
APA 7.ª edición tiene convenciones específicas para reportar estadísticas descriptivas. Las plantillas a continuación están diseñadas para adaptarse directamente a tu capítulo de Resultados.
Plantilla APA para Variables Continuas
Como mínimo, reporta el tamaño de muestra, la media y la desviación estándar para cada variable continua. Si tu comité espera documentación de normalidad (la mayoría lo hace), incluye también la asimetría y curtosis.
Reporte en texto:
Los puntajes de satisfacción de los participantes oscilaron entre 1.00 y 5.00 (M = 3.44, DE = 0.95, N = 148). La distribución fue aproximadamente normal (asimetría = -0.45, curtosis = -0.39).
Formato de tabla (recomendado para múltiples variables):
| Variable | N | M | DE | Mín | Máx | Asimetría | Curtosis |
|---|---|---|---|---|---|---|---|
| Satisfaction | 148 | 3.44 | 0.95 | 1.00 | 5.00 | -0.45 | -0.39 |
| Study Hours | 148 | 12.46 | 5.28 | 3.40 | 35.00 | 1.31 | 2.85 |
| GPA | 148 | 3.11 | 0.54 | 1.80 | 4.00 | -0.14 | -0.73 |
Tabla 4: Ejemplo de tabla de estadísticas descriptivas en formato APA
Recordatorios de formato APA:
- Cursiva para los símbolos estadísticos: M, DE, N, n
- Dos decimales para la mayoría de los estadísticos
- Los valores de la tabla no van en negritas; solo la fila de encabezado
- Numera tus tablas secuencialmente ("Tabla 1", "Tabla 2") con un título descriptivo sobre cada una
- Las tablas de estadísticas descriptivas van al inicio de tu sección de Resultados, antes de los análisis inferenciales
Plantilla APA para Variables Categóricas
Para variables categóricas, reporta frecuencias y porcentajes.
Reporte en texto:
La muestra estuvo compuesta por 87 mujeres (58.4%) y 62 hombres (41.6%). La mayoría de los participantes tenía licenciatura (n = 71, 48.0%), seguido de maestría (n = 45, 30.4%) y preparatoria (n = 32, 21.6%).
Formato de tabla:
| Variable | Categoría | n | % |
|---|---|---|---|
| Género | Femenino | 87 | 58.4 |
| Masculino | 62 | 41.6 | |
| Educación | Preparatoria | 32 | 21.6 |
| Licenciatura | 71 | 48.0 | |
| Maestría | 45 | 30.4 |
Tabla 5: Ejemplo de tabla de frecuencias en formato APA para variables categóricas
Dónde Aparecen las Estadísticas Descriptivas en una Tesis
Las estadísticas descriptivas típicamente aparecen en una de dos ubicaciones:
-
Final del capítulo de Método (demografía de la muestra). Reporta las características de tu muestra: distribución por género, rango de edad, nivel educativo y otras variables demográficas relevantes.
-
Inicio del capítulo de Resultados (resúmenes de variables). Reporta las estadísticas descriptivas de tus variables de investigación (medias, desviaciones estándar, propiedades de distribución) antes de presentar los resultados de pruebas inferenciales.
Algunos comités de tesis prefieren todas las estadísticas descriptivas en el capítulo de Resultados. Confirma la ubicación esperada con tu asesor.
Errores Comunes al Ejecutar Estadísticas Descriptivas en SPSS
1. Usar Descriptives para Variables Categóricas
Si el género está codificado como 1 = Masculino y 2 = Femenino, SPSS calculará una media de 1.58 sin quejarse. Ese número no tiene significado. Descriptives calcula medias y desviaciones estándar, que solo tienen sentido para variables continuas. Usa Frequencies para datos categóricos.
2. Ignorar el N Válido
SPSS reporta el número de casos válidos (no faltantes) como N en el output. Si tu conjunto de datos tiene 200 casos pero una variable muestra N = 185, 15 valores están faltantes. Siempre verifica el N válido y reporta los datos faltantes en tu tesis.
3. Reportar Solo la Media Sin Variabilidad
Un puntaje promedio de satisfacción de 3.5 podría venir de una muestra donde todos puntuaron entre 3 y 4, o de una donde la mitad puntuó 1 y la otra mitad puntuó 5. La media sola no te dice cuál es el caso. Siempre acompáñala con la desviación estándar.
4. No Verificar la Asimetría Antes de Pruebas Paramétricas
Muchos estudiantes pasan directamente de las estadísticas descriptivas a pruebas t o ANOVA sin verificar la normalidad. Si tus datos son sustancialmente asimétricos (más allá de +/-2), los resultados de las pruebas paramétricas pueden no ser confiables. El procedimiento Explore facilita esta verificación al producir tanto pruebas numéricas como gráficos visuales.
5. Confundir Porcentaje y Porcentaje Válido en Tablas de Frecuencia
SPSS reporta tanto Porcentaje (incluye los valores faltantes en el denominador) como Porcentaje válido (excluye los valores faltantes). En tu tesis, reporta el Porcentaje válido porque representa la distribución real entre los encuestados que respondieron la pregunta.
6. Reportar Demasiados Decimales
El output de SPSS frecuentemente muestra ocho o más decimales. Copiar M = 3.4527189 directamente en tu tesis se ve poco profesional e implica un nivel de precisión que tu instrumento de medición casi con certeza no tiene. APA recomienda dos decimales: M = 3.45.
7. Ejecutar Descriptives Sin Verificar el Nivel de Medición de las Variables
SPSS usa el nivel de medición definido en la Vista de Variables (Nominal, Ordinal, Escala) para determinar qué estadísticas son apropiadas. Si tu variable continua está incorrectamente establecida como Nominal, algunos procedimientos pueden excluirla. Verifica los niveles de medición en la Vista de Variables antes de ejecutar cualquier análisis.
Lo Que Tu Comité de Tesis Preguntará
Estas preguntas surgen en prácticamente toda defensa de tesis que involucra datos cuantitativos:
"¿Cómo sabes que tus datos tienen distribución normal?" Aquí es donde tu output de Explore demuestra su valor. Señala los valores de asimetría y curtosis, los resultados de la prueba Shapiro-Wilk y el Q-Q plot. Indica el umbral que aplicaste: "Los valores de asimetría y curtosis cayeron dentro del rango aceptable de -1 a +1 para todas las variables del estudio, y los Q-Q plots no mostraron desviación sistemática de la normalidad."
"¿Por qué elegiste media y DE en lugar de mediana y RIC?" La respuesta debe demostrar que tomaste una decisión deliberada, no una por defecto. Explica que evaluaste la forma de la distribución primero y que los datos eran aproximadamente normales, lo que justificó el uso de medidas de resumen paramétricas.
"¿Cuántos datos faltantes tienes y cómo los manejaste?" Tu output descriptivo ya contiene esta información en la columna de N válido. Indica el porcentaje de datos faltantes por variable y explica tu estrategia de manejo (eliminación por lista, eliminación por pares o imputación) con justificación.
"¿Hay valores atípicos en tus datos?" Referencia los boxplots y la tabla de Valores Extremos de Explore. Si identificaste valores atípicos, explica si los retuviste o excluiste, y por qué. Los comités quieren ver que investigaste en lugar de ignorar posibles problemas.
Preguntas Frecuentes
Próximos Pasos
Con tu output descriptivo revisado, los siguientes pasos dependen de lo que encontraste. Si la asimetría o curtosis señalaron posible falta de normalidad, necesitas pruebas formales. Si tus variables son escalas de múltiples ítems, necesitas verificar su confiabilidad antes de calcular puntajes compuestos.
Si necesitas verificar formalmente la normalidad de tus datos, consulta nuestra guía sobre cómo verificar la normalidad en SPSS, que cubre la prueba Shapiro-Wilk, Q-Q plots y qué hacer cuando la normalidad falla. Una vez que tus datos estén limpios y los supuestos verificados, puedes avanzar a pruebas inferenciales como la regresión lineal en SPSS.
Referencias
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). American Psychological Association.
Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). SAGE Publications.
George, D., & Mallery, P. (2019). IBM SPSS statistics 26 step by step: A simple guide and reference (16th ed.). Routledge.
Hair, J. F., Babin, B. J., Anderson, R. E., & Black, W. C. (2019). Multivariate data analysis (8th ed.). Cengage Learning.
Pallant, J. (2020). SPSS survival manual (7th ed.). Open University Press.
Tabachnick, B. G., & Fidell, L. S. (2019). Using multivariate statistics (7th ed.). Pearson.