La regresión lineal múltiple es una de las técnicas estadísticas más poderosas para analizar la relación entre múltiples variables independientes y una sola variable dependiente. En esta guía completa, aprenderás a ejecutar la regresión múltiple en SPSS, interpretar los resultados y comprender cada componente del análisis.
Ya sea que investigues la efectividad del marketing, predicas el rendimiento académico o analices cualquier relación con múltiples predictores, este tutorial cubre todo, desde la preparación de datos hasta la interpretación de resultados. Te proporcionaré un conjunto de datos SPSS completo para el análisis de regresión lineal múltiple para que puedas seguir paso a paso.
El análisis de regresión múltiple en SPSS es sencillo. Si sabes cómo calcular una regresión lineal simple en SPSS, encontrarás que el proceso es casi idéntico. La diferencia principal es interpretar los resultados con múltiples predictores, y cubriremos cada parámetro en detalle.
Qué es la Regresión Lineal Múltiple: Explicación con Ejemplo
Con la regresión lineal simple, analizamos la relación causal entre una sola variable independiente y una variable dependiente. En otras palabras, buscamos ver si la variable independiente (predictor) tiene un efecto significativo sobre la variable dependiente (resultado). Pero, ¿cómo analizamos la regresión cuando un modelo contiene múltiples variables independientes?
Aquí es donde entra el análisis de regresión lineal múltiple.
En el análisis de regresión lineal múltiple, evaluamos el efecto de dos o más predictores sobre la variable resultado; de ahí el término regresión lineal múltiple.
 Figura 1: La regresión lineal múltiple analiza la relación entre múltiples predictores y un resultado
Figura 1: La regresión lineal múltiple analiza la relación entre múltiples predictores y un resultado
En términos de análisis, tanto para la regresión lineal simple como para la múltiple, el objetivo sigue siendo prácticamente el mismo: determinar si existe significancia (valor P) entre los múltiples predictores y el resultado. Si el valor P es igual o inferior a 0.05 (P ≤ 0.05), la relación predictor-resultado es significativa.
Veamos un ejemplo de regresión lineal múltiple. Supongamos que queremos investigar la relación entre los esfuerzos de marketing y la intención de compra del consumidor de una empresa. En este caso, la variable predictora es esfuerzos de marketing y el resultado es intención de compra.
Sé lo que estás pensando. "Esfuerzos de marketing" es un término muy amplio y muchos factores pueden contribuir a ello. No tiene sentido investigar los esfuerzos de marketing en su totalidad si no podemos identificar qué factores son más importantes que otros, ¿verdad?
Dividamos los esfuerzos de marketing en varias variables independientes (X), por ejemplo, marketing de contenidos (X1), marketing en redes sociales (X2) y email marketing (X3). Así luce el marco conceptual para este ejemplo:
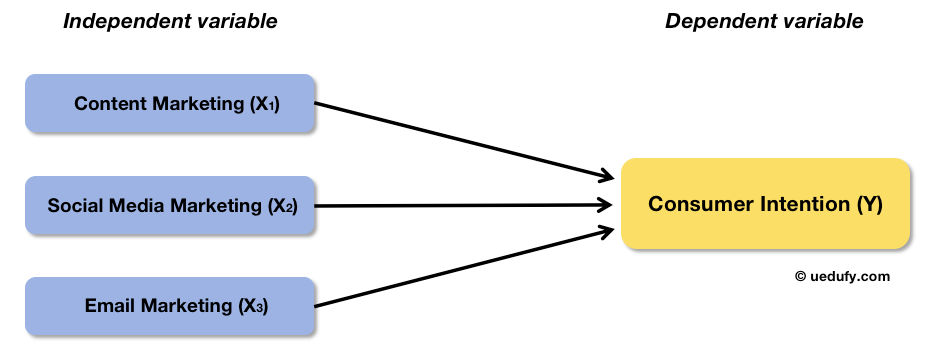 Figura 2: Marco conceptual de ejemplo: esfuerzos de marketing divididos en tres predictores
Figura 2: Marco conceptual de ejemplo: esfuerzos de marketing divididos en tres predictores
Ahora que tenemos nuestro marco conceptual, pasemos a la acción y realicemos el análisis de regresión múltiple en SPSS usando el ejemplo que discutimos.
Calcular la Regresión Lineal Múltiple en SPSS
Calcular la regresión lineal múltiple en SPSS es muy similar a realizar un análisis de regresión lineal simple en SPSS. Si deseas seguir el tutorial, descarga el conjunto de datos SPSS desde la sección Download en la barra lateral.
El conjunto de datos de ejemplo contiene 30 muestras donde Content, SocialMedia y Email son variables independientes (predictores), y Consumer_Intention es la variable dependiente (resultado). Después de descargar, descomprime el archivo y haz doble clic en el archivo con extensión .sav para importar el conjunto de datos en SPSS.
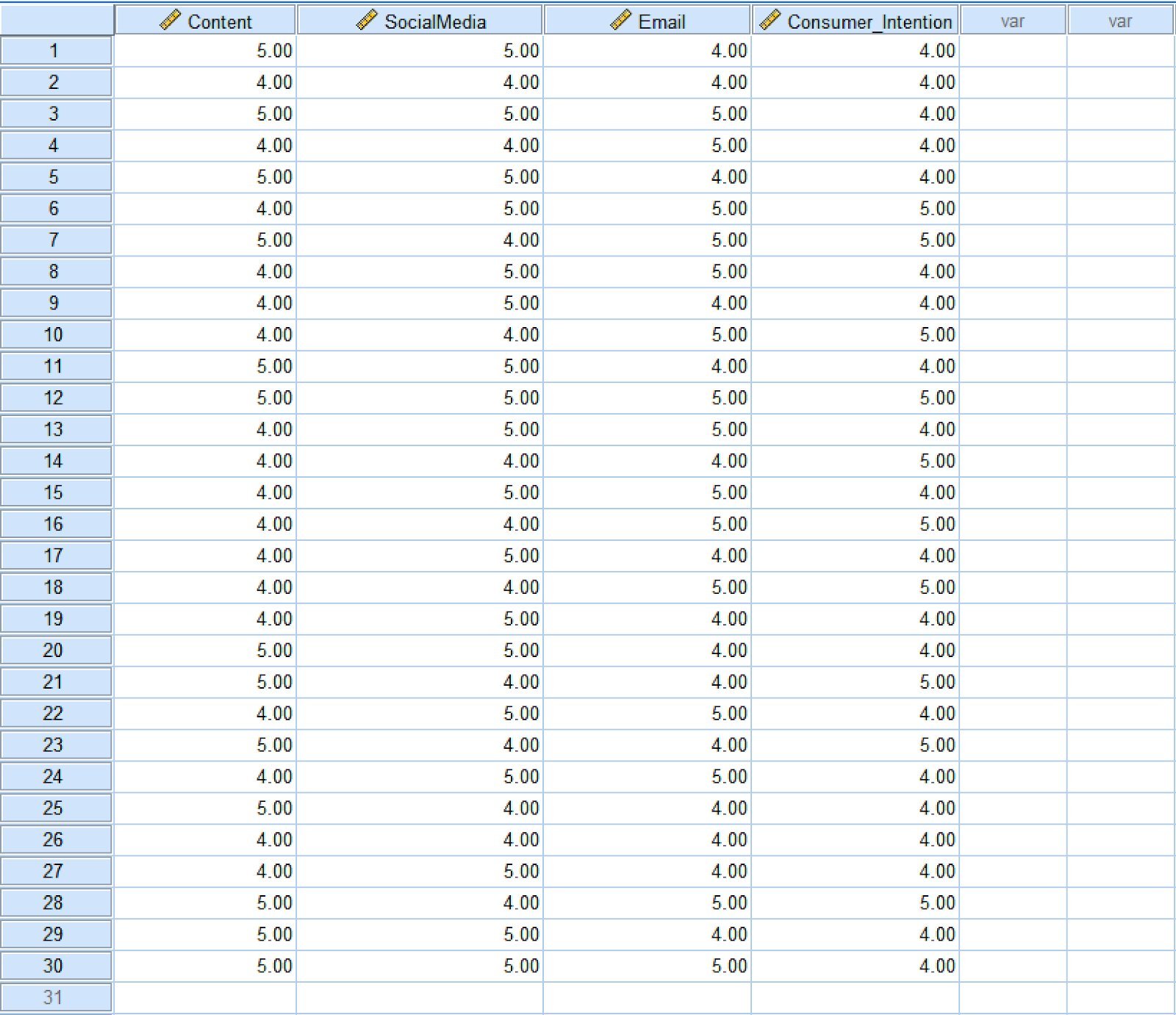 Figura 3: Conjunto de datos de ejemplo con tres predictores y una variable resultado
Figura 3: Conjunto de datos de ejemplo con tres predictores y una variable resultado
A continuación, aprendamos cómo calcular la regresión lineal múltiple en SPSS para este ejemplo.
- En el menú superior de SPSS, ve a Analyze → Regression → Linear.
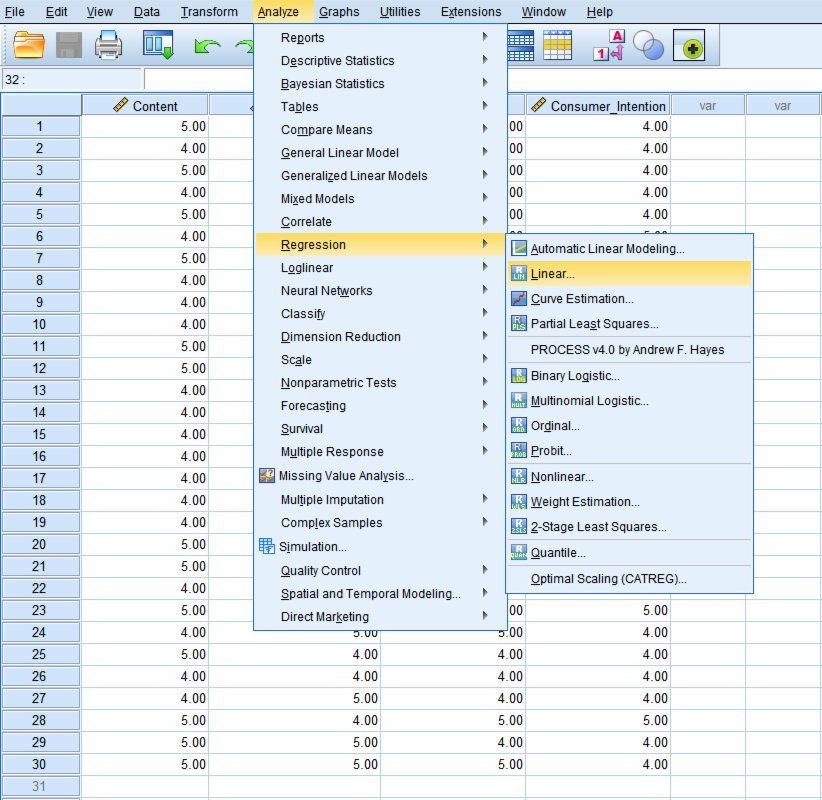 Figura 4: Navega a Analyze → Regression → Linear en SPSS
Figura 4: Navega a Analyze → Regression → Linear en SPSS
- En la ventana Linear Regression, usa el botón de flecha para mover Consumer_Intention al cuadro Dependent. Haz lo mismo con las variables predictoras Email, Content y SocialMedia para moverlas al cuadro Independent(s).
Asegura que el método de regresión lineal esté configurado en Enter.
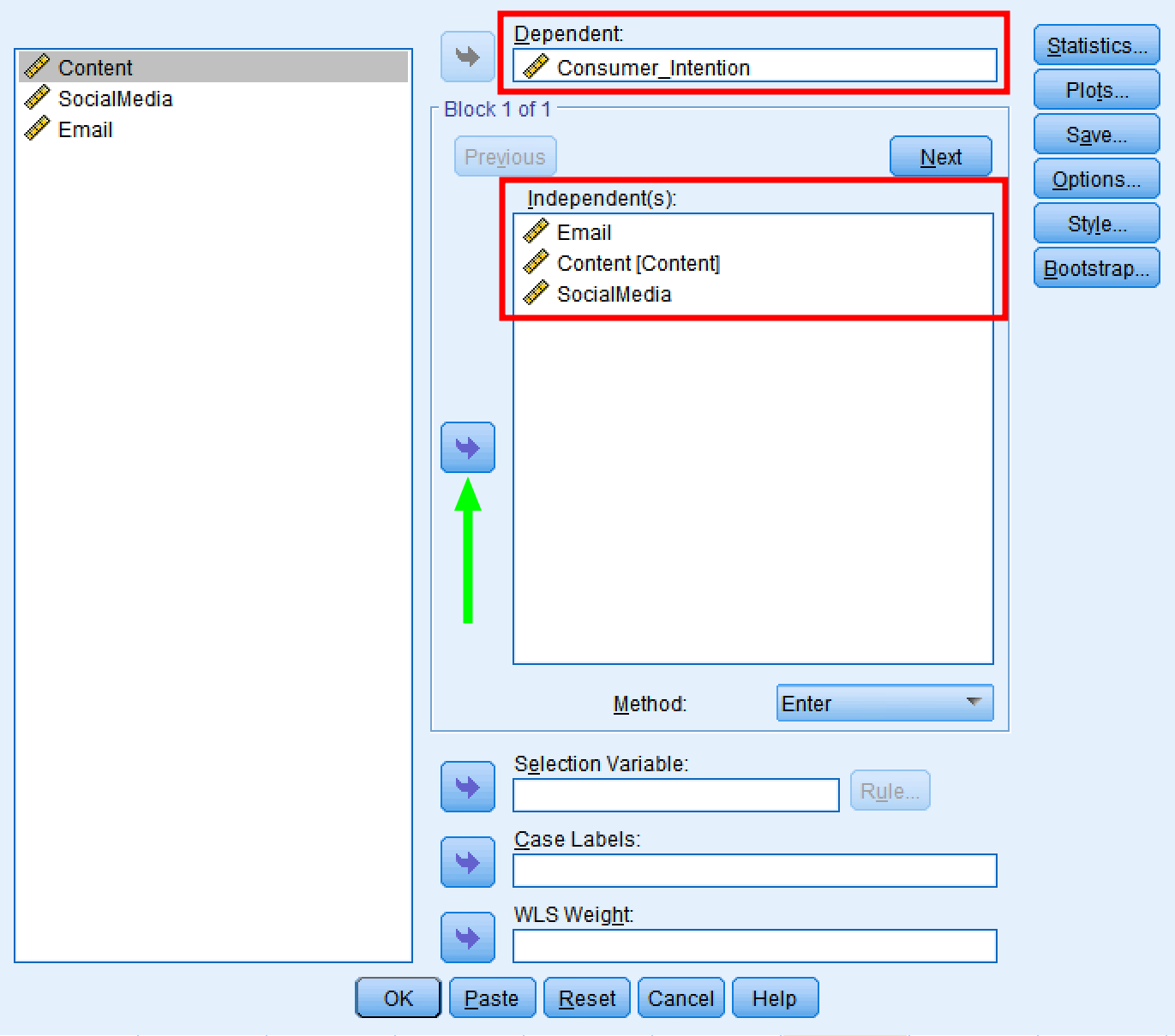 Figura 5: Selecciona las variables dependiente e independientes en el cuadro de diálogo Linear Regression
Figura 5: Selecciona las variables dependiente e independientes en el cuadro de diálogo Linear Regression
- Haz clic en el botón OK para calcular la regresión lineal múltiple en SPSS. Aparecerá una nueva ventana con los resultados de la regresión lineal múltiple.
Interpretar los Resultados de la Regresión Lineal Múltiple en SPSS
Ahora que tenemos los resultados de la regresión lineal múltiple en SPSS, veamos cómo interpretar los resultados. Por defecto, SPSS muestra cuatro tablas en los resultados de regresión:
- Variables Entered/Removed
- Model Summary
- ANOVA
- Coefficients
Revisemos cada tabla y entendamos qué significan esos términos y valores.
Variables Entered/Removed
Esta tabla contiene un resumen del análisis de la regresión lineal múltiple en SPSS: el modelo de regresión utilizado, las variables independientes y dependientes ingresadas en el análisis, así como el método de regresión.
En algunos casos, SPSS eliminará variables del modelo si se encuentra que causan problemas de multicolinealidad. En este análisis de regresión, no se eliminaron variables; por lo tanto, podemos deducir que ninguna variable presentó dependencia lineal entre sí.
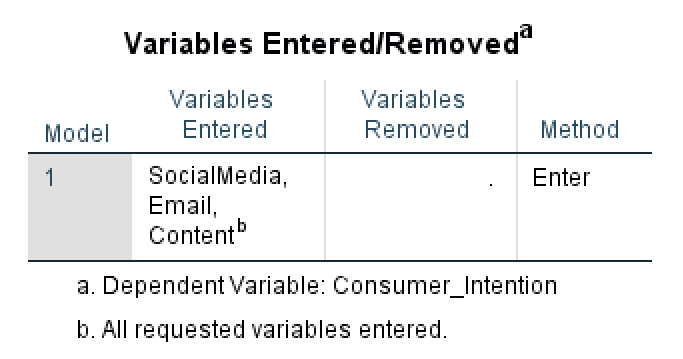 Figura 6: La tabla Variables Entered/Removed muestra el resumen del modelo
Figura 6: La tabla Variables Entered/Removed muestra el resumen del modelo
Model Summary
La tabla Model Summary proporciona estadísticas clave sobre qué tan bien el modelo de regresión se ajusta a los datos. Esta tabla incluye tres medidas fundamentales: R, R² y R² Ajustado.
R (Coeficiente de Correlación Múltiple) representa la correlación entre los valores observados y los valores predichos de la variable dependiente. Varía de 0 a 1, donde valores más altos indican mejor predicción. En nuestro ejemplo, R indica la fuerza de la relación entre los tres predictores combinados y Consumer_Intention.
R² (Coeficiente de Determinación) nos dice la proporción de varianza en la variable dependiente explicada por las variables independientes. Se calcula como:
En nuestro caso:
Esto significa que nuestros tres predictores (Email, Content, SocialMedia) explican el 44.3% de la variación en Consumer_Intention. El 55.7% restante es varianza no explicada.
R² Ajustado modifica R² para tener en cuenta la cantidad de predictores en el modelo. Es más preciso para comparar modelos con diferente número de predictores porque penaliza la adición de variables innecesarias. La fórmula es:
Donde:
- n = tamaño de la muestra (30 en nuestro caso)
- k = número de predictores (3 en nuestro caso)
El R² Ajustado siempre será ligeramente menor que R², especialmente con muestras más pequeñas o más predictores. Al comparar modelos, prefiere el que tenga mayor R² Ajustado.
ANOVA
La tabla ANOVA en la regresión múltiple evalúa si el modelo de regresión en su conjunto explica significativamente la varianza en la variable dependiente. Compara la varianza explicada por el modelo (Regresión) contra la varianza no explicada (Residual). Si el modelo explica significativamente más varianza que el error, el test F será significativo.
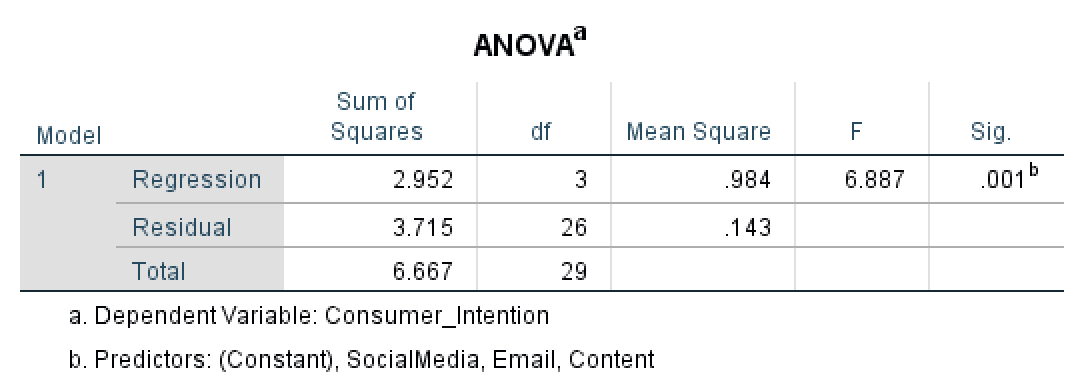 Figura 7: La tabla ANOVA muestra las estadísticas de ajuste del modelo de regresión
Figura 7: La tabla ANOVA muestra las estadísticas de ajuste del modelo de regresión
Comencemos con la columna Sum of Squares en ANOVA. La Suma de Cuadrados de Regresión (SSR) muestra la cantidad de variación en la variable dependiente explicada por las variables independientes. En nuestro caso, el modelo de regresión explica 2.952 unidades de variación. Valores más altos de SSR indican que el modelo explica más varianza en el resultado, lo cual es deseable.
La Suma de Cuadrados Residual (SSE) mide la variación no explicada o error en el modelo. En nuestro caso, la Suma de Cuadrados Residual es 3.715. Valores residuales más bajos son mejores, ya que indican menos varianza no explicada. Un residual de cero significaría predicción perfecta.
La Suma de Cuadrados Total se calcula sumando la Suma de Cuadrados de Regresión y la Residual: 6.667 en nuestro caso.
A continuación, veamos la columna de Grados de Libertad (df) en ANOVA.
Los df de Regresión equivalen al número de variables predictoras en el modelo (k). En nuestro caso, tenemos 3 predictores (Email, Content, SocialMedia), por lo que df de regresión = 3.
Los df Residuales se calculan como: n - k - 1, donde n es el tamaño de la muestra, k es el número de predictores y 1 corresponde al intercepto. Con 30 muestras y 3 predictores:
Los df Totales equivalen a n - 1 (tamaño de la muestra menos uno), que es 29 en nuestro ejemplo.
El Mean Square de Regresión se calcula dividiendo la suma de cuadrados de regresión entre los grados de libertad de regresión: 0.984 en nuestro ejemplo. El Mean Square Residual se calcula de la misma forma, dividiendo la suma de cuadrados residual entre los grados de libertad residuales: 0.143 en nuestro caso.
La columna F en ANOVA representa el estadístico F, que es probablemente la cantidad más importante en el test ANOVA. El estadístico F es el cociente entre el Mean Square de Regresión y el Mean Square Residual, y se utiliza para calcular el valor P. En nuestro ejemplo, el estadístico F es 6.887.
Finalmente, la columna Sig. en ANOVA (valor P) nos indica si la diferencia entre los grupos en el modelo de regresión es significativa. Dado que en nuestro caso P es 0.001 (es decir, ≤ 0.05), la diferencia entre los grupos Content, SocialMedia y Email es estadísticamente significativa.
Coefficients
La última tabla en los resultados de regresión es la tabla Coefficients. Aquí encontramos detalles sobre el Beta de Coeficiente No Estandarizado y el Error Estándar, el Beta de Coeficiente Estandarizado, el estadístico t y el valor P de los predictores en nuestro modelo.
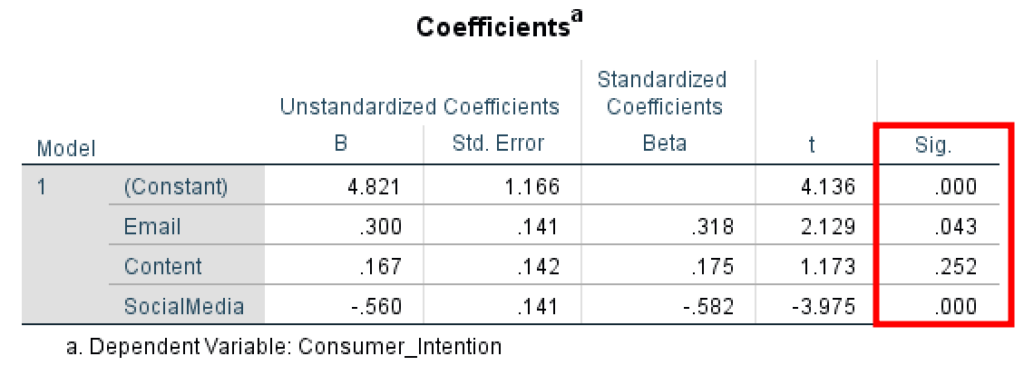 Figura 8: La tabla Coefficients muestra la significancia estadística de cada predictor
Figura 8: La tabla Coefficients muestra la significancia estadística de cada predictor
El Beta de Coeficiente No Estandarizado mide la variación en la variable resultado por una unidad de cambio en la variable predictora, donde los valores brutos se muestran en la escala original.
El Error Estándar de las estimaciones mide la distancia promedio de los puntos de datos observados respecto a la línea de regresión. Un valor alto de error estándar indica que las medias de la muestra se distribuyen ampliamente alrededor de la media poblacional. Un valor bajo de error estándar indica que la media de la muestra y la media de la población están estrechamente correlacionadas, lo cual es positivo.
Los Coeficientes Beta Estandarizados (también conocidos como pesos beta) miden el efecto de cada predictor cuando todas las variables se estandarizan con media 0 y desviación estándar 1. Esto te permite comparar la importancia relativa de predictores medidos en diferentes escalas. Un beta estandarizado absoluto mayor indica un efecto más fuerte.
La columna del estadístico t muestra la medida de la desviación estándar del coeficiente y se calcula dividiendo el coeficiente Beta entre su error estándar. En general, un valor mayor que +2 o -2 se considera aceptable.
Finalmente, la columna Sig. (valor P) en los coeficientes de regresión muestra la significancia estadística de cada predictor sobre la variable resultado, donde un valor P ≤ 0.05 se considera aceptable.
En nuestro ejemplo, podemos observar que la variable predictora Email tiene un efecto sobre la variable resultado Consumer_Intention (P = 0.043, < 0.05); por lo tanto, la relación es estadísticamente significativa.
El predictor Content no tiene efecto sobre Consumer_Intention (P = 0.252, > 0.05); por lo tanto, no hay significancia estadística en el modelo de regresión.
El predictor SocialMedia tiene un efecto sobre Consumer_Intention (P = 0.000, < 0.05); por lo tanto, la relación entre las dos variables es estadísticamente significativa.
En conclusión, los valores más importantes que debes verificar al interpretar los resultados de la regresión lineal múltiple en SPSS son:
- Los resultados del test ANOVA nos indican si la diferencia entre los grupos en el modelo de regresión es significativa a P ≤ 0.05.
- Los coeficientes de regresión que muestran un efecto significativo entre predictor y variable resultado a P ≤ 0.05.
Exportar los Resultados de Regresión Lineal en SPSS
Finalmente, exportemos los resultados de la regresión lineal múltiple en SPSS como archivo .pdf para uso posterior. En la ventana de resultados de regresión, haz clic en File → Export.
- En la ventana Export Output, selecciona la opción Portable Document Format (*.pdf). Otras opciones como Word/RTF (.doc) y PowerPoint (.ppt) están disponibles si prefieres esos formatos.
- Escribe un nombre de archivo y busca la ubicación donde prefieras guardar los resultados de la regresión lineal múltiple en SPSS.
- Haz clic en el botón OK para exportar los resultados.
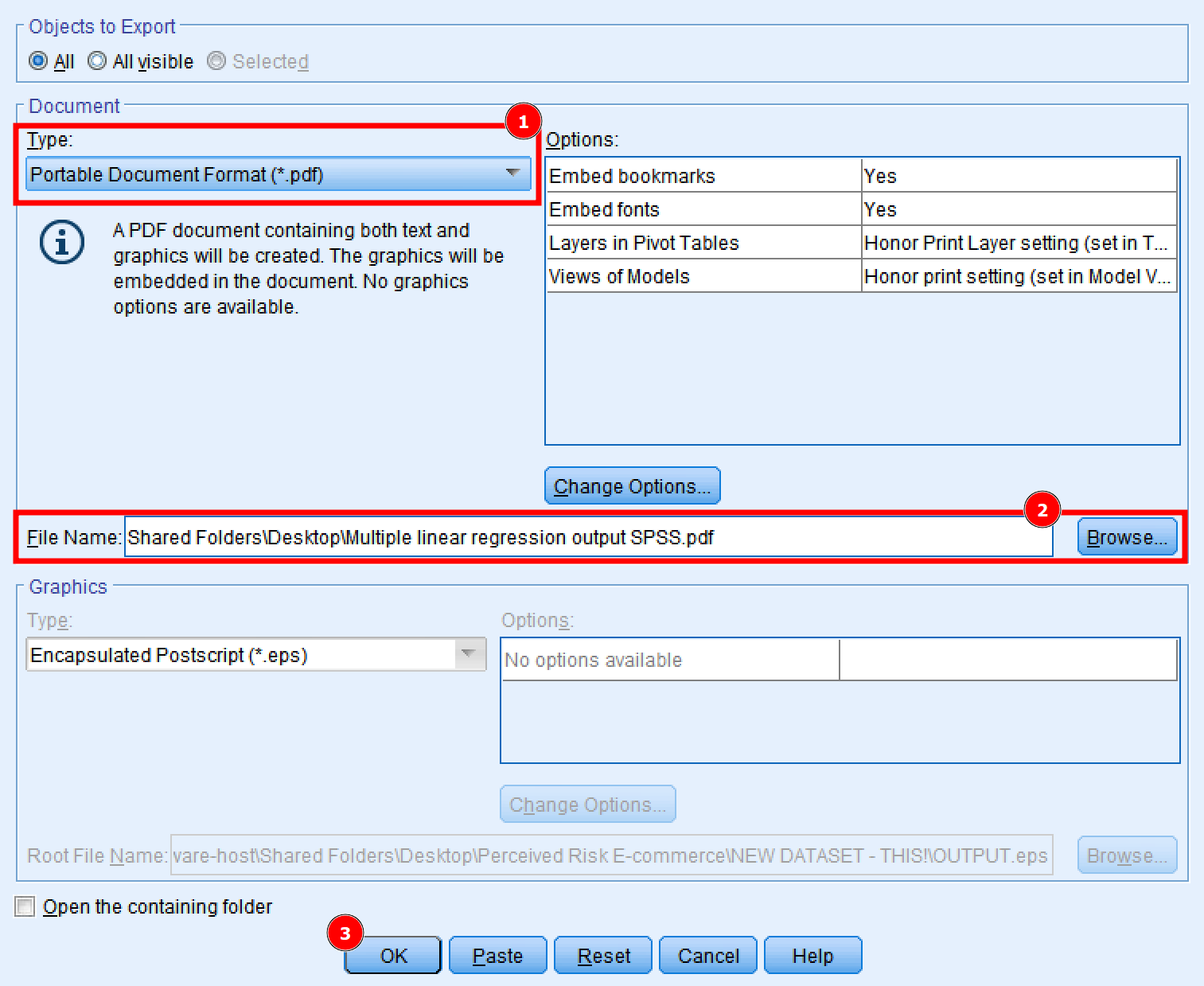 Figura 9: Exporta los resultados de regresión a formato PDF, Word o PowerPoint
Figura 9: Exporta los resultados de regresión a formato PDF, Word o PowerPoint
El archivo con los resultados de la regresión lineal múltiple en SPSS ya está disponible para tu uso.
Supuestos de la Regresión Lineal Múltiple
Antes de interpretar tus resultados, es fundamental verificar que tus datos cumplan con los supuestos de la regresión lineal múltiple. Violar estos supuestos puede llevar a resultados inexactos o engañosos.
1. Linealidad
La relación entre cada variable independiente y la variable dependiente debe ser lineal. Puedes verificar esto creando diagramas de dispersión de cada predictor contra la variable resultado.
Cómo verificar en SPSS: Crea diagramas de dispersión (Graphs → Legacy Dialogs → Scatter/Dot) para cada par predictor-resultado. Busca un patrón lineal en lugar de relaciones curvas.
2. Independencia de las Observaciones
Las observaciones deben ser independientes entre sí. Este supuesto se viola en casos como medidas repetidas, datos de series temporales o datos agrupados.
Cómo verificar: Revisa tu diseño de investigación. Si tienes medidas repetidas o datos agrupados, necesitarás técnicas más avanzadas como modelos mixtos o ecuaciones de estimación generalizadas.
3. Homocedasticidad
La varianza de los residuos debe ser constante en todos los niveles de las variables independientes. En otras palabras, la dispersión de los residuos debe ser aproximadamente igual a lo largo de la línea de regresión. Aprende más sobre qué significa la homocedasticidad en estadística.
Cómo verificar en SPSS: En el cuadro de diálogo Linear Regression, haz clic en Plots → agrega ZPRED al eje X y ZRESID al eje Y. El diagrama de dispersión resultante debe mostrar puntos dispersos aleatoriamente sin patrón de cono o abanico.
4. Normalidad de los Residuos
Los residuos (errores) deben estar aproximadamente distribuidos de forma normal. Esto es especialmente importante para muestras de tamaño reducido.
Cómo verificar en SPSS: En el cuadro de diálogo Linear Regression, haz clic en Plots → marca "Histogram" y "Normal probability plot". El histograma debe parecerse a una curva de campana, y los puntos en el gráfico P-P deben caer cerca de la línea diagonal.
5. Ausencia de Multicolinealidad
Las variables independientes no deben estar altamente correlacionadas entre sí. La alta multicolinealidad infla los errores estándar y dificulta evaluar el efecto individual de cada predictor.
Cómo verificar en SPSS: En el cuadro de diálogo Linear Regression, haz clic en Statistics → marca "Collinearity diagnostics". Observa los valores VIF (Factor de Inflación de la Varianza). Valores VIF superiores a 10 indican multicolinealidad problemática. Valores de Tolerancia inferiores a 0.1 también sugieren problemas.
6. Ausencia de Valores Atípicos Significativos o Casos Influyentes
Los valores extremos pueden afectar desproporcionadamente la línea de regresión y producir resultados engañosos.
Cómo verificar en SPSS: En el cuadro de diálogo Linear Regression, haz clic en Save → marca "Cook's distance" y "Standardized residuals". Valores de distancia de Cook superiores a 1 sugieren casos influyentes. Residuos estandarizados superiores a ±3 indican posibles valores atípicos.
Preguntas Frecuentes
Conclusión
Espero que ahora tengas una comprensión clara de cómo calcular la regresión lineal múltiple en SPSS y cómo interpretar los resultados. Como puedes ver, no es tan difícil.
Si es la primera vez que realizas una regresión lineal en SPSS, te recomiendo repetir el proceso algunas veces más y también probar con tu propio conjunto de datos para el análisis de regresión lineal múltiple.