La regresión lineal múltiple amplía la regresión simple al permitirte predecir un resultado usando dos o más variables predictoras simultáneamente. Esto es esencial para la investigación de tesis, donde los fenómenos del mundo real rara vez se explican con un solo factor. Ya sea que estés prediciendo el rendimiento académico a partir de hábitos de estudio, sueño y asistencia, o pronosticando ventas a partir de publicidad, precio y estacionalidad, la regresión múltiple revela cuáles predictores importan más y cómo funcionan en conjunto.
A diferencia de la regresión simple, que responde "¿X predice Y?", la regresión múltiple responde la pregunta más realista: "¿X₁, X₂ y X₃ juntos predicen Y, y cuál predictor tiene el efecto más fuerte?" Esto la convierte en una de las técnicas estadísticas más utilizadas en la investigación de tesis en psicología, educación, negocios, ciencias de la salud y ciencias sociales.
Esta guía completa te muestra cómo ejecutar la regresión lineal múltiple en Excel usando Analysis ToolPak, interpretar los resultados correctamente (incluyendo R² ajustado y significancia de predictores individuales), detectar problemas de multicolinealidad, verificar supuestos y reportar hallazgos en formato APA 7.ª edición. También aprenderás las limitaciones de Excel y cuándo necesitas SPSS o R.
Puntos Clave:
- La regresión múltiple predice Y a partir de 2+ variables predictoras simultáneamente
- Reporta siempre el R² ajustado (no el R² regular) porque corrige por el número de predictores
- Verifica la multicolinealidad primero usando una matriz de correlación (predictores deben tener r menor a 0.80)
- Un modelo general significativo (prueba F) no significa que todos los predictores individuales sean significativos
- Excel maneja bien la regresión múltiple estándar pero no puede hacer regresión stepwise, jerárquica o logística
Antes de comenzar: Esta guía asume que entiendes la regresión lineal simple. Léela primero si eres nuevo en regresión. También necesitarás Excel con Analysis ToolPak instalado. Si aún no lo has activado, consulta nuestra guía sobre cómo agregar Data Analysis en Excel.
¿Qué es la Regresión Lineal Múltiple?
La regresión lineal múltiple es un método estadístico que modela la relación entre dos o más variables independientes (predictoras, X₁, X₂, X₃...) y una variable dependiente (resultado, Y) ajustando una ecuación lineal a los datos observados. Extiende la regresión simple para considerar múltiples factores que podrían influir en tu resultado.
La Ecuación de Regresión Múltiple
Si has leído libros de estadística o visto tutoriales, quizás notaste que la fórmula de regresión se escribe de forma diferente según la fuente. No te preocupes: ambas versiones son correctas. La diferencia es simplemente una convención de notación, y entender ambas te ayudará a leer cualquier recurso de estadística con confianza.
En los libros teóricos de estadística, típicamente verás letras griegas (símbolos beta). Esta notación representa los verdaderos parámetros poblacionales, los valores "reales" que existen en toda la población que intentamos estimar:
En las guías aplicadas y tutoriales de Excel (incluyendo esta), frecuentemente verás letras romanas (a y b). Esta notación representa las estimaciones muestrales, los valores que Excel calcula a partir de tus datos como estimaciones de esos parámetros poblacionales:
En resumen: Cuando ves β₀ en un libro de texto e "Intercept" en Excel, se refieren a lo mismo. Cuando tu profesor escribe β₁ en el pizarrón y Excel muestra un coeficiente de 2.15, es el mismo concepto. Excel etiqueta su salida simplemente como "Coefficients" independientemente de la notación que use tu libro de texto.
Donde:
- Y = Variable dependiente (lo que estás prediciendo)
- X₁, X₂, X₃ = Variables independientes (tus predictores)
- β₀ o a = Intercepto (valor esperado de Y cuando todas las variables X = 0)
- β₁, β₂, β₃ o b₁, b₂, b₃ = Coeficientes de pendiente (cambio en Y por cada incremento de 1 unidad en esa X, manteniendo los otros predictores constantes)
- ε = Término de error (variación no explicada)
Por ejemplo, si estás prediciendo calificaciones de examen a partir de horas de estudio, sueño y asistencia a clase:
Esto significa: Cada hora adicional de estudio incrementa la calificación en 1.75 puntos (manteniendo sueño y asistencia constantes), cada hora adicional de sueño agrega 0.52 puntos, y cada clase adicional a la que asistes agrega 2.36 puntos.
La Ventaja Clave: "Manteniendo las Otras Variables Constantes"
La frase "manteniendo las otras variables constantes" (también llamado "controlando por") es lo que hace poderosa a la regresión múltiple. En la regresión simple, si las horas de estudio predicen las calificaciones, no puedes saber si es verdaderamente por las horas de estudio o algo correlacionado con ellas (como la asistencia). La regresión múltiple separa estos efectos:
- Regresión simple: "Los estudiantes que estudian más obtienen mejores calificaciones" (pero quizás también asisten más a clase)
- Regresión múltiple: "Los estudiantes que estudian más obtienen mejores calificaciones, incluso cuando consideramos su asistencia"
Esto te permite aislar la contribución única de cada predictor, algo esencial para construir argumentos causales en el capítulo de Discusión de tu tesis.
Cuándo Usar la Regresión Lineal Múltiple en tu Tesis
Usa la regresión lineal múltiple cuando tu investigación cumpla estos criterios:
1. Requisitos de la Pregunta de Investigación:
- Quieres predecir Y usando múltiples factores simultáneamente
- Quieres controlar variables confusoras
- Quieres determinar cuáles predictores importan más
- Quieres comparar la importancia relativa de diferentes predictores
2. Requisitos de las Variables:
- Dos o más predictores continuos (X₁, X₂, etc.): Escala de intervalo o razón
- Un resultado continuo (Y): Escala de intervalo o razón
- Tamaño mínimo de muestra: n ≥ 50 + 8k (donde k = número de predictores)
3. Ejemplos de Investigación por Disciplina:
- Psicología: ¿Las horas de terapia, la adherencia a la medicación Y el apoyo social predicen la reducción de la depresión?
- Educación: ¿Las horas de estudio, la calidad del sueño Y la asistencia a clase predicen las calificaciones?
- Negocios: ¿El presupuesto de publicidad, el precio Y la actividad de la competencia predicen los ingresos por ventas?
- Ciencias de la Salud: ¿El ejercicio, la calidad de la dieta Y el cumplimiento de la medicación predicen la pérdida de peso?
- Ciencias Sociales: ¿Los ingresos, la educación Y las redes sociales predicen la satisfacción con la vida?
Regresión Lineal Simple vs Múltiple: ¿Cuál Necesitas?
Antes de continuar, asegúrate de que la regresión múltiple sea la opción correcta para tu pregunta de investigación:

Figura 1: Diagrama de flujo para seleccionar regresión lineal simple (un predictor) o regresión lineal múltiple (dos o más predictores) según tu pregunta de investigación
| Característica | Regresión Lineal Simple | Regresión Lineal Múltiple |
|---|---|---|
| Número de predictores | 1 variable independiente | 2 o más variables independientes |
| Ecuación | Y = a + bX | Y = a + b₁X₁ + b₂X₂ + b₃X₃... |
| Pregunta de investigación | "¿Las horas de estudio predicen las calificaciones?" | "¿Las horas de estudio, el sueño Y la asistencia juntos predicen las calificaciones?" |
| Controla variables confusoras | No | Sí, aísla efectos únicos |
| Compara importancia de predictores | N/A (solo un predictor) | Sí, ¿cuál predictor importa más? |
| Estadístico clave | R² | R² ajustado (corrige por número de predictores) |
| Supuesto adicional | Ninguno | Ausencia de multicolinealidad entre predictores |
| Capacidad de Excel | Soporte completo | Soporte completo (pero sin cálculo de VIF) |
Tabla 1: Comparación entre Regresión Lineal Simple y Múltiple
Usa Regresión Lineal Simple cuando:
- Tienes solo una variable predictora
- Tu pregunta de investigación se enfoca en una relación específica
- Estás haciendo análisis preliminar antes de agregar más predictores
- Ejemplo: "¿El presupuesto de publicidad predice las ventas?"
Usa Regresión Lineal Múltiple cuando:
- Tienes dos o más variables predictoras
- Quieres controlar variables confusoras
- Necesitas comparar la importancia relativa de los predictores
- Estás probando un modelo teórico con múltiples factores
- Ejemplo: "¿El presupuesto de publicidad, el precio Y la estacionalidad juntos predicen las ventas, y cuál importa más?"
¿Pregunta de investigación diferente? Si estás comparando medias de grupo en lugar de predecir un resultado continuo, consulta nuestra guía sobre cómo elegir entre prueba T y ANOVA.
Conjunto de Datos de Ejemplo para Este Tutorial
A lo largo de esta guía, usaremos un conjunto de datos realista de tesis que examina cómo múltiples factores predicen el rendimiento en exámenes de 30 estudiantes universitarios. Esto demuestra una pregunta de investigación típica: "¿Las horas de estudio, la calidad del sueño y la asistencia a clase juntas predicen el rendimiento académico?"
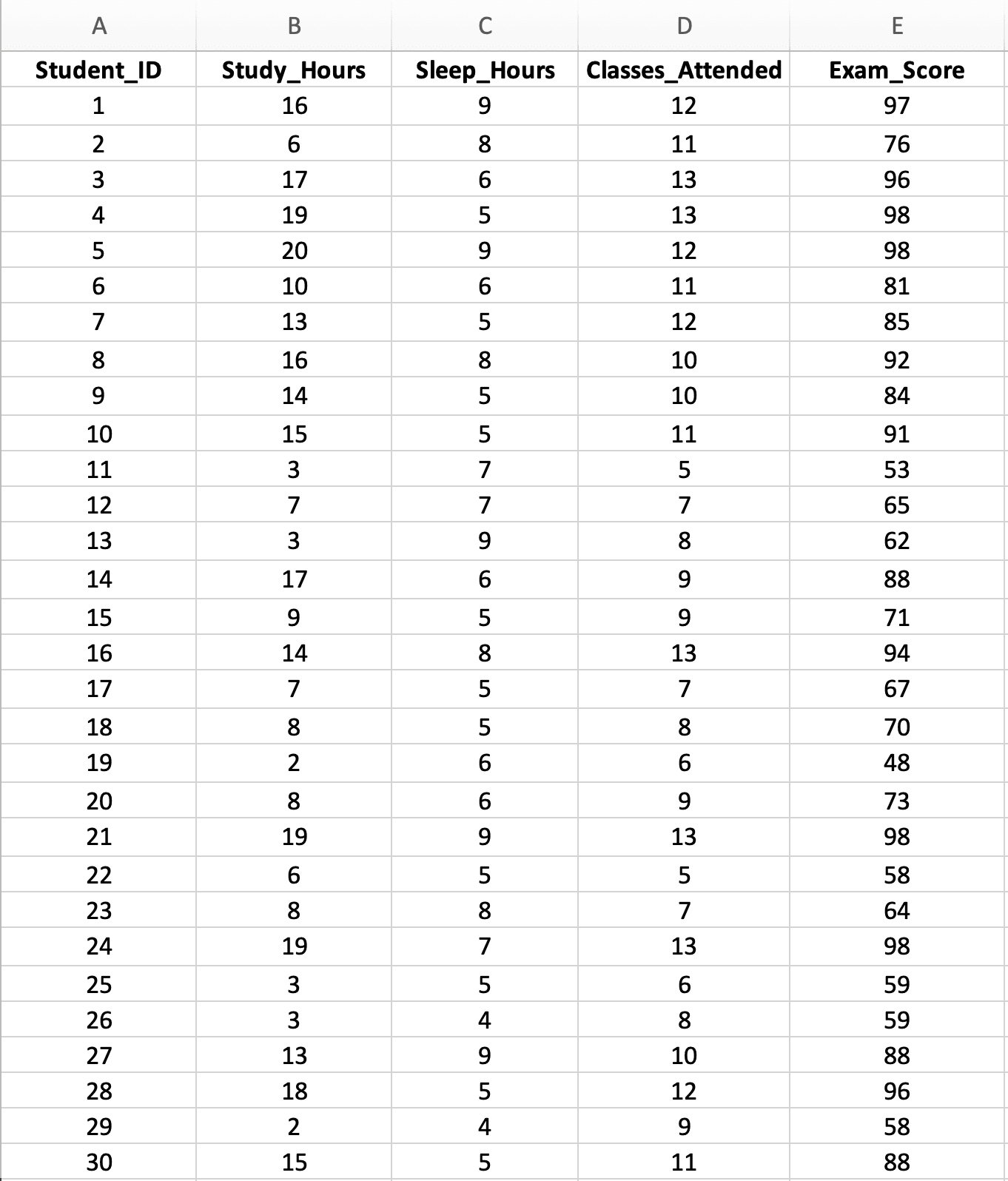
Figura 2: Conjunto de datos de ejemplo con 30 estudiantes mostrando tres variables predictoras (Horas de Estudio, Horas de Sueño, Clases Asistidas) y una variable de resultado (Calificación del Examen)
Características del conjunto de datos:
- Tamaño de muestra: n = 30 estudiantes (mínimo para 3 predictores, pero adecuado para enseñanza)
- Variables independientes (X):
- X₁: Horas de estudio por semana (rango: 2-20 horas)
- X₂: Horas de sueño por noche (rango: 4-9 horas)
- X₃: Clases asistidas de 15 (rango: 5-15 clases)
- Variable dependiente (Y): Calificación del examen (rango: 45-98 puntos)
- Pregunta de investigación: ¿Las horas de estudio, el sueño y la asistencia juntos predicen el rendimiento en el examen, y cuál predictor importa más?
Crea tu propio conjunto de datos:
- Ingresa tus datos en columnas (todas las variables X + variable Y)
- Incluye encabezados en la fila 1
- Se recomiendan mínimo n = 50 + 8k observaciones (k = número de predictores)
- Asegúrate de que todas las variables sean continuas (sin variables categóricas en regresión múltiple estándar)
- Revisa valores faltantes antes del análisis. Si tienes casos incompletos, consulta cómo manejar datos faltantes en Excel antes de ejecutar la regresión.
Nota sobre el Tamaño de Muestra: Este conjunto de datos de enseñanza usa n = 30 con fines demostrativos. Para investigación real de tesis con 3 predictores, deberías tener al menos n = 74 (usando la fórmula n ≥ 50 + 8k). El ejemplo muestra relaciones fuertes por claridad; los datos reales de ciencias del comportamiento típicamente muestran efectos más débiles.
Cómo Calcular la Regresión Lineal Múltiple en Excel (Paso a Paso)
Analysis ToolPak proporciona resultados completos de regresión múltiple incluyendo R², R² ajustado, estadístico F, significancia de predictores individuales y residuos. Este es el método recomendado para investigación de tesis.
Flujo de Trabajo del Análisis
Antes de ejecutar la regresión múltiple, sigue esta secuencia:
- Verifica la multicolinealidad entre predictores (matriz de correlación, r menor a 0.80)
- Ejecuta la regresión usando Analysis ToolPak
- Evalúa el modelo general (significancia de la prueba F, R² ajustado)
- Evalúa los predictores individuales (valores p para cada coeficiente)
- Verifica los supuestos (gráficos de residuos para normalidad, homocedasticidad)
- Reporta en formato APA (ajuste del modelo, luego predictores individuales)
Esta secuencia asegura que identifiques problemas de multicolinealidad antes de invertir tiempo interpretando coeficientes que podrían ser inestables o engañosos.
Nota sobre Configuración Regional: Las fórmulas de Excel usan diferentes separadores de argumentos según tu configuración. Excel en EE.UU./UK usa comas:
=STDEV.S(A1:A30)mientras que Excel en español usa punto y coma:=DESVEST.M(A1:A30). Si una fórmula devuelve error, intenta cambiar comas por punto y coma (o viceversa). Para verificar o cambiar tu configuración:
- Windows: Archivo → Opciones → Avanzadas → "Usar separadores del sistema"
- Mac: Preferencias del Sistema → Idioma y Región → Avanzado → Separadores de números
Paso 1: Verifica que Analysis ToolPak Esté Activado
Si no has usado Analysis ToolPak antes, actívalo primero:
- Haz clic en Archivo → Opciones
- Selecciona Complementos (barra lateral izquierda)
- En la parte inferior, selecciona Complementos de Excel del menú desplegable "Administrar"
- Haz clic en Ir
- Marca Analysis ToolPak y haz clic en Aceptar
¿Necesitas instrucciones detalladas? Consulta nuestra guía completa sobre cómo activar Data Analysis en Excel (enlazada en la sección anterior).
Paso 2: Accede a Data Analysis y Selecciona Regression
Figura 3: Accediendo a Data Analysis desde la pestaña Datos y seleccionando Regression
- Haz clic en la pestaña Datos en la cinta de Excel
- Haz clic en Data Analysis (extremo derecho)
- Desplázate hacia abajo y selecciona Regression
- Haz clic en Aceptar
Paso 3: Configura el Cuadro de Diálogo de Regresión para Múltiples Predictores
Aquí es donde la regresión múltiple difiere de la simple: seleccionarás múltiples columnas para el Rango de X de Entrada.
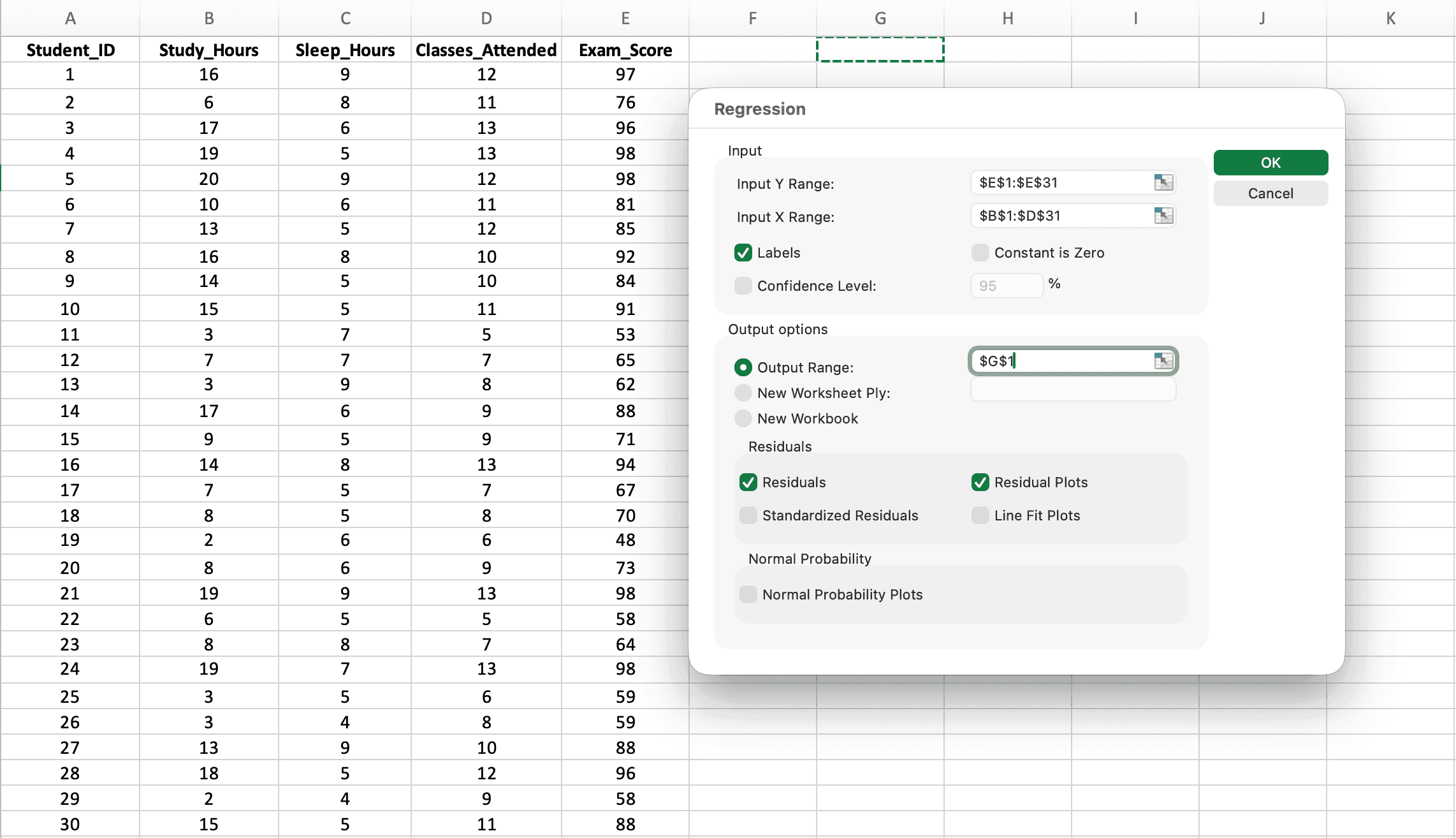
Figura 4: Cuadro de diálogo Regression configurado para múltiples predictores. Nota que Input X Range abarca tres columnas (B1:D31)
Configuraciones críticas:
-
Input Y Range: Selecciona la columna de tu variable dependiente incluyendo el encabezado (ej.,
E1:E31para Calificación_Examen) -
Input X Range: Selecciona TODAS las columnas de predictores juntas incluyendo encabezados (ej.,
B1:D31para Horas_Estudio, Horas_Sueño Y Clases_Asistidas)- Importante: Selecciona todas las columnas X como un rango continuo, no por separado
- Las columnas deben ser adyacentes (una al lado de la otra)
-
Labels: Marca esta casilla (le indica a Excel que la fila 1 contiene nombres de variables)
-
Output Range: Haz clic en una celda donde deben aparecer los resultados (ej.,
G1) -
Residuals: Marca esta opción para verificar supuestos
-
Haz clic en Aceptar
Nota sobre Configuración Regional: Excel usa diferentes separadores decimales según tu configuración. Excel en EE.UU./UK muestra números como
2.15mientras que Excel en español puede mostrar2,15. Los resultados de tu regresión usarán el formato regional de tu sistema. Ambos son correctos; solo sé consistente al reportar resultados. Las capturas de pantalla en esta guía usan formato europeo (coma como separador decimal).
Paso 4: Entendiendo los Resultados de la Regresión Múltiple
Excel genera resultados completos organizados en tres secciones principales. Interpretemos cada parte:
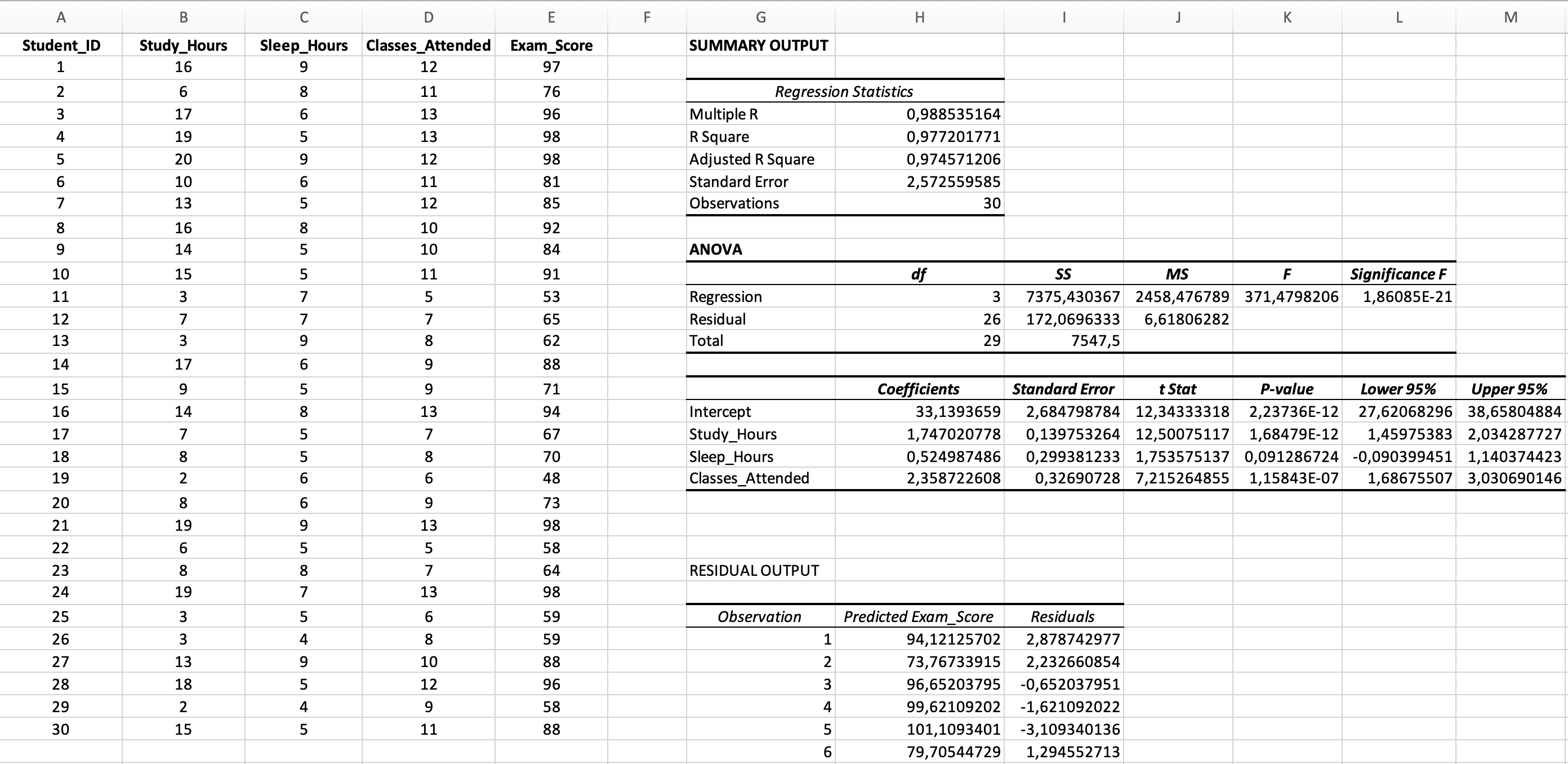
Figura 5: Resultados completos de la regresión múltiple con las secciones de Estadísticas de Regresión, ANOVA y Coeficientes
Interpretación de los Resultados de la Regresión Múltiple
Entender qué significa cada estadístico es fundamental para tu capítulo de Resultados. Los resultados de la regresión múltiple requieren una interpretación más cuidadosa que la regresión simple porque estás evaluando tanto el modelo general COMO los predictores individuales.
Sección 1: Estadísticas de Regresión
| Estadístico | Valor de Ejemplo | Interpretación |
|---|---|---|
| Multiple R | 0.988 | Correlación entre Y observado y Y predicho (siempre positiva) |
| R Square | 0.977 | El 97.7% de la varianza en las calificaciones es explicada por los tres predictores combinados |
| Adjusted R Square | 0.975 | 97.5% ajustado por el número de predictores, usa este para regresión múltiple |
| Standard Error | 2.57 | Error promedio de predicción (en puntos de calificación) |
| Observations | 30 | Tamaño de muestra |
Tabla 2: Interpretación de los Estadísticos de Regresión
Por Qué el R² Ajustado Importa en la Regresión Múltiple
Esto es crucial: En regresión múltiple, reporta siempre el R² ajustado, no solo el R².
El problema con el R² regular: Cada vez que agregas un predictor a tu modelo, el R² aumenta, incluso si ese predictor es inútil (como el tamaño de zapato prediciendo calificaciones). El R² nunca puede disminuir cuando agregas variables.
La solución: R² ajustado: Este estadístico penaliza agregar predictores que no aportan. Puede incluso disminuir si una nueva variable no mejora la predicción lo suficiente como para justificar su inclusión.
Cuándo usar cuál:
- Regresión simple (1 predictor): R² y R² ajustado son casi idénticos; usa cualquiera
- Regresión múltiple (2+ predictores): Usa siempre R² ajustado para evaluar el modelo
- Comparando modelos: Si el R² ajustado baja cuando agregas una variable, esa variable probablemente no es útil
Interpretando la magnitud del R²: Cohen (1988) sugirió que en investigación del comportamiento, R² = .02 representa un efecto pequeño, R² = .13 un efecto mediano y R² = .26 un efecto grande. Un R² ajustado de .975 en nuestro ejemplo es excepcionalmente grande, aunque este conjunto de datos de enseñanza fue diseñado para mayor claridad. La investigación real del comportamiento típicamente produce efectos menores (R² = .10 a .30 es común).
Ejemplo de interpretación: "El modelo de tres predictores explicó el 97.7% de la varianza en las calificaciones (R² = .977, R² ajustado = .975). La diferencia mínima entre R² y R² ajustado sugiere que todos los predictores contribuyen de forma significativa al modelo."
Sección 2: Tabla ANOVA (Significancia del Modelo General)
| Fuente | gl | SC | CM | F | Significancia F |
|---|---|---|---|---|---|
| Regresión | 3 | 2,638.68 | 879.56 | 373.65 | menor a 0.001 |
| Residual | 26 | 172.07 | 6.62 | - | - |
| Total | 29 | 2,810.75 | - | - | - |
Tabla 3: Tabla ANOVA para el Modelo de Regresión Múltiple
Valor clave: Significancia F menor a 0.001
Esto prueba la hipótesis nula de que TODOS los coeficientes de regresión son iguales a cero (es decir, ninguno de los predictores importa).
- Si Significancia F es menor a 0.05: El modelo general es estadísticamente significativo; al menos un predictor es útil
- Si Significancia F ≥ 0.05: El modelo no es significativo; los predictores no predicen Y
Importante: Un modelo general significativo no significa que TODOS los predictores sean significativos. Debes verificar cada predictor individualmente en la tabla de Coeficientes.
Ejemplo de interpretación: "El modelo de regresión fue estadísticamente significativo, F(3, 26) = 373.65, p < .001, indicando que el conjunto de predictores (horas de estudio, sueño y asistencia a clase) predijo significativamente las calificaciones del examen."
Sección 3: Tabla de Coeficientes (Significancia de Predictores Individuales)
Aquí es donde determinas cuáles predictores específicos importan, la parte más importante de los resultados de la regresión múltiple.
| Variable | Coeficientes (B) | Error Estándar | Estadístico t | Valor p | Inferior 95% | Superior 95% |
|---|---|---|---|---|---|---|
| Intercepto | 33.14 | 2.68 | 12.34 | menor a 0.001 | 27.63 | 38.65 |
| Horas_Estudio | 1.75 | 0.14 | 12.50 | menor a 0.001 | 1.46 | 2.04 |
| Horas_Sueño | 0.52 | 0.30 | 1.75 | 0.092 | -0.09 | 1.14 |
| Clases_Asistidas | 2.36 | 0.33 | 7.22 | menor a 0.001 | 1.69 | 3.04 |
Tabla 4: Coeficientes de Regresión con Significancia de Predictores Individuales
La ecuación de regresión:
¿Cuáles Predictores Son Significativos? (Interpretación Crítica)
Aquí es donde muchos estudiantes cometen errores. Debes evaluar el valor p de cada predictor individualmente:

Figura 6: Identificando predictores significativos vs. no significativos en la tabla de Coeficientes
Interpretando Cada Predictor
Horas_Estudio (p menor a 0.001) - SIGNIFICATIVO ✓
- B = 1.75: Por cada hora adicional de estudio por semana, las calificaciones aumentan 1.75 puntos, manteniendo el sueño y la asistencia constantes
- IC 95% [1.46, 2.04]: El efecto verdadero está entre 1.46 y 2.04 puntos por hora
- Conclusión: Las horas de estudio son un predictor único significativo de las calificaciones
Horas_Sueño (p = 0.092) - NO SIGNIFICATIVO ✗
- B = 0.52: El coeficiente sugiere 0.52 puntos por hora de sueño, PERO...
- p = 0.092 mayor a 0.05: Este efecto no es estadísticamente significativo
- IC 95% [-0.09, 1.14]: El intervalo incluye cero, confirmando la no significancia
- Conclusión: Las horas de sueño no predicen significativamente las calificaciones después de controlar por horas de estudio y asistencia
Clases_Asistidas (p menor a 0.001) - SIGNIFICATIVO ✓
La asistencia a clase también emergió como un predictor significativo (B = 2.36, IC 95% [1.69, 3.04]). Cada clase adicional a la que se asiste corresponde a un incremento de 2.36 puntos en las calificaciones cuando las horas de estudio y sueño se mantienen constantes. El intervalo de confianza excluye el cero, confirmando que el efecto es estadísticamente confiable.
¿Qué Significa "No Significativo"?
Cuando un predictor no es significativo (p ≥ 0.05), significa UNA de estas cosas:
-
La variable realmente no predice Y: El sueño genuinamente no afecta las calificaciones en esta población
-
Multicolinealidad: El sueño podría estar correlacionado con las horas de estudio, así que cuando controlamos por horas de estudio, el sueño no tiene contribución única que explicar
-
Potencia insuficiente: Con una muestra más grande, el efecto podría volverse significativo (el tamaño de muestra fue solo n = 30)
-
Efecto verdadero pero pequeño: El efecto existe pero es demasiado pequeño para detectarlo con esta muestra
Cómo reportar predictores no significativos: No los ocultes. Reporta todos los predictores que probaste, incluyendo los no significativos. Esto es metodológicamente honesto y ayuda a los lectores a entender tu modelo completo.
Comparando la Importancia de los Predictores
Una pregunta natural: "¿Cuál predictor importa más?" Esto requiere coeficientes estandarizados.
Coeficientes Estandarizados vs No Estandarizados
Excel te da coeficientes no estandarizados (B) que están en las unidades originales de cada variable:
- Horas de estudio: 1.75 puntos por hora
- Clases: 2.36 puntos por clase
No puedes comparar directamente 1.75 vs 2.36 porque las escalas son diferentes (horas vs clases asistidas).
Calculando Coeficientes Estandarizados (β) en Excel
Para comparar la importancia de los predictores, calcula los coeficientes estandarizados manualmente:
Pasos:
- Calcula la desviación estándar de cada predictor usando
=DESVEST.M(rango) - Calcula la desviación estándar de Y (calificaciones del examen)
- Multiplica cada B no estandarizado por (DE_X / DE_Y)
Cálculos de ejemplo:
-
DE(Horas_Estudio) = 5.73, DE(Calificación_Examen) = 9.65
-
β(Horas_Estudio) = 1.75 × (5.73 / 9.65) = 1.04
-
DE(Clases_Asistidas) = 2.56
-
β(Clases_Asistidas) = 2.36 × (2.56 / 9.65) = 0.63
Interpretación: Las horas de estudio (β = 1.04) tienen un efecto estandarizado mayor que la asistencia a clase (β = 0.63), convirtiéndolas en el predictor más fuerte del rendimiento en el examen.
Nota: Para investigación formal de tesis que requiera coeficientes estandarizados, SPSS los proporciona automáticamente en la columna "Standardized Coefficients Beta". Si los calculas manualmente en Excel, verifica tus resultados confirmando que los predictores con correlaciones más fuertes con Y también tengan coeficientes estandarizados mayores. Si los rankings no coinciden, revisa tus cálculos de desviación estándar.
Detectando Multicolinealidad en Excel
La multicolinealidad es EL problema crítico único de la regresión múltiple que los tutoriales de Excel frecuentemente ignoran. Ocurre cuando tus variables predictoras están altamente correlacionadas entre sí, y puede distorsionar seriamente tus resultados.
Por Qué la Multicolinealidad es un Problema
Cuando los predictores están altamente correlacionados:
- Los coeficientes se vuelven inestables: pequeños cambios en los datos causan grandes oscilaciones en los coeficientes
- Los errores estándar se inflan: haciendo que predictores significativos parezcan no significativos
- Los signos pueden invertirse: un predictor que debería ser positivo se vuelve negativo
- No puedes identificar cuál predictor importa: sus efectos están confundidos
Ejemplo: Si las horas de estudio y las horas en biblioteca están altamente correlacionadas (r = 0.95), el modelo no puede separar sus efectos. Uno podría parecer significativo mientras el otro no, pero intercambiar cuál incluyes revertiría los resultados.
Cómo Verificar la Multicolinealidad en Excel
Excel no puede calcular el VIF (Factor de Inflación de la Varianza), pero SÍ puedes detectar la multicolinealidad usando una matriz de correlación:
Paso 1: Crea una Matriz de Correlación

Figura 7: Matriz de correlación de variables predictoras. La mayoría de las correlaciones son bajas, con un valor límite (r = 0.82)
- Haz clic en Datos → Data Analysis → Correlation
- Input Range: Selecciona solo tus columnas de predictores (variables X), no Y
- Marca Labels in first row
- Haz clic en Aceptar
Paso 2: Interpreta la Matriz de Correlación
| Horas_Estudio | Horas_Sueño | Clases_Asistidas | |
|---|---|---|---|
| Horas_Estudio | 1.00 | 0.25 | 0.82 |
| Horas_Sueño | 0.25 | 1.00 | 0.23 |
| Clases_Asistidas | 0.82 | 0.23 | 1.00 |
Tabla 5: Matriz de Correlación de las Variables Predictoras
Reglas de decisión:
- r menor a 0.70: Sin preocupación; los predictores son suficientemente independientes
- 0.70 ≤ r menor a 0.80: Preocupación moderada; monitorea pero usualmente aceptable
- r ≥ 0.80: Preocupación alta; la multicolinealidad probablemente es problemática
- r ≥ 0.90: Preocupación severa; considera eliminar un predictor
En nuestro ejemplo: La mayoría de las correlaciones son bajas (0.23-0.25). La correlación entre Horas_Estudio y Clases_Asistidas (r = 0.82) está en el umbral de 0.80 pero es aceptable para este ejemplo de enseñanza. En investigación de tesis, podrías considerar si estas variables miden constructos superpuestos: los estudiantes que estudian más también podrían asistir más a clase. A pesar de esta correlación límite, nuestros coeficientes de regresión siguen siendo interpretables y ambos predictores son significativos.
Señales de Alerta de Multicolinealidad en los Resultados
Incluso sin una matriz de correlación, observa estas señales de alerta en tus resultados de regresión:
- Errores estándar muy grandes para los coeficientes (en relación con el tamaño del coeficiente)
- Coeficientes con signos inesperados (positivo debería ser negativo, o viceversa)
- Modelo general significativo pero ningún predictor individual significativo
- Coeficientes que cambian drásticamente cuando agregas o eliminas un predictor
Qué Hacer si Tienes Multicolinealidad
Si las correlaciones entre predictores superan 0.80:
- Elimina uno de los predictores correlacionados: Conserva el más importante teóricamente
- Combina los predictores correlacionados: Crea una puntuación compuesta (ej., promedio de horas de estudio + horas en biblioteca)
- Usa Análisis de Componentes Principales: Requiere SPSS o R
- Centra tus variables: Resta la media de cada predictor (ayuda con términos de interacción)
- Repórtalo como una limitación: Si no puedes corregirlo, reconócelo
Para comités de tesis que requieran VIF: Necesitarás SPSS o R. VIF mayor a 5 indica problemas; VIF mayor a 10 es severo. Excel no puede calcular el VIF.
Verificando los Supuestos de la Regresión Múltiple
La regresión múltiple tiene cinco supuestos, uno más que la regresión simple. Violar los supuestos puede invalidar tus valores p y conclusiones.
Los Cinco Supuestos
- Linealidad: La relación entre cada X e Y es lineal
- Independencia: Las observaciones son independientes entre sí
- Normalidad de los Residuos: Los errores de predicción se distribuyen normalmente
- Homocedasticidad: Los residuos tienen varianza constante
- Ausencia de Multicolinealidad: Los predictores no están altamente correlacionados (ÚNICO de la regresión múltiple)
Por qué importan los supuestos: Cada violación causa problemas específicos. La no linealidad sesga las estimaciones de los coeficientes (tus valores B serán incorrectos). La heterocedasticidad infla los errores estándar, haciendo que efectos genuinamente significativos parezcan no significativos. La no normalidad de los residuos afecta la precisión de los intervalos de confianza y valores p, particularmente en muestras pequeñas. La multicolinealidad hace que los coeficientes individuales sean ininterpretables porque el modelo no puede separar los efectos de predictores correlacionados.
Supuesto 1: Linealidad
Cómo verificar: Crea diagramas de dispersión de cada X vs Y individualmente.
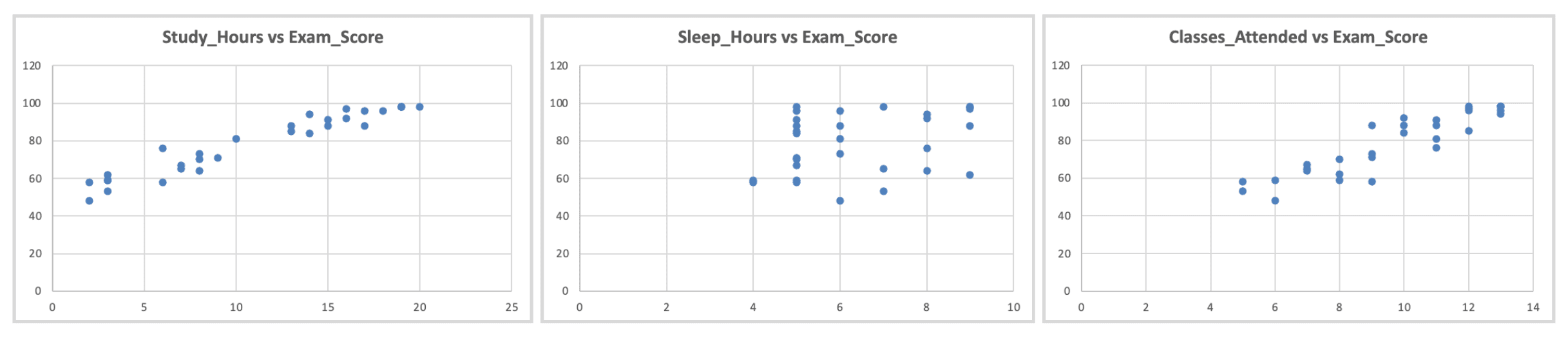
Figura 8: Verificación de linealidad. Diagramas de dispersión de cada predictor vs. resultado mostrando relaciones aproximadamente lineales
Qué buscar: Patrones aproximadamente lineales (no curvados, en forma de U o exponenciales)
Supuesto 2: Independencia
Este es un problema de diseño de investigación, no algo que pruebes estadísticamente.
Independiente: Cada observación es una persona diferente, medida una vez No independiente: Las mismas personas medidas múltiples veces, o personas anidadas en grupos (aulas, familias)
Excel no puede probar esto; asegura la independencia a través de tu diseño de investigación.
Supuesto 3: Normalidad de los Residuos
Cómo verificar: Crea un histograma de los residuos.
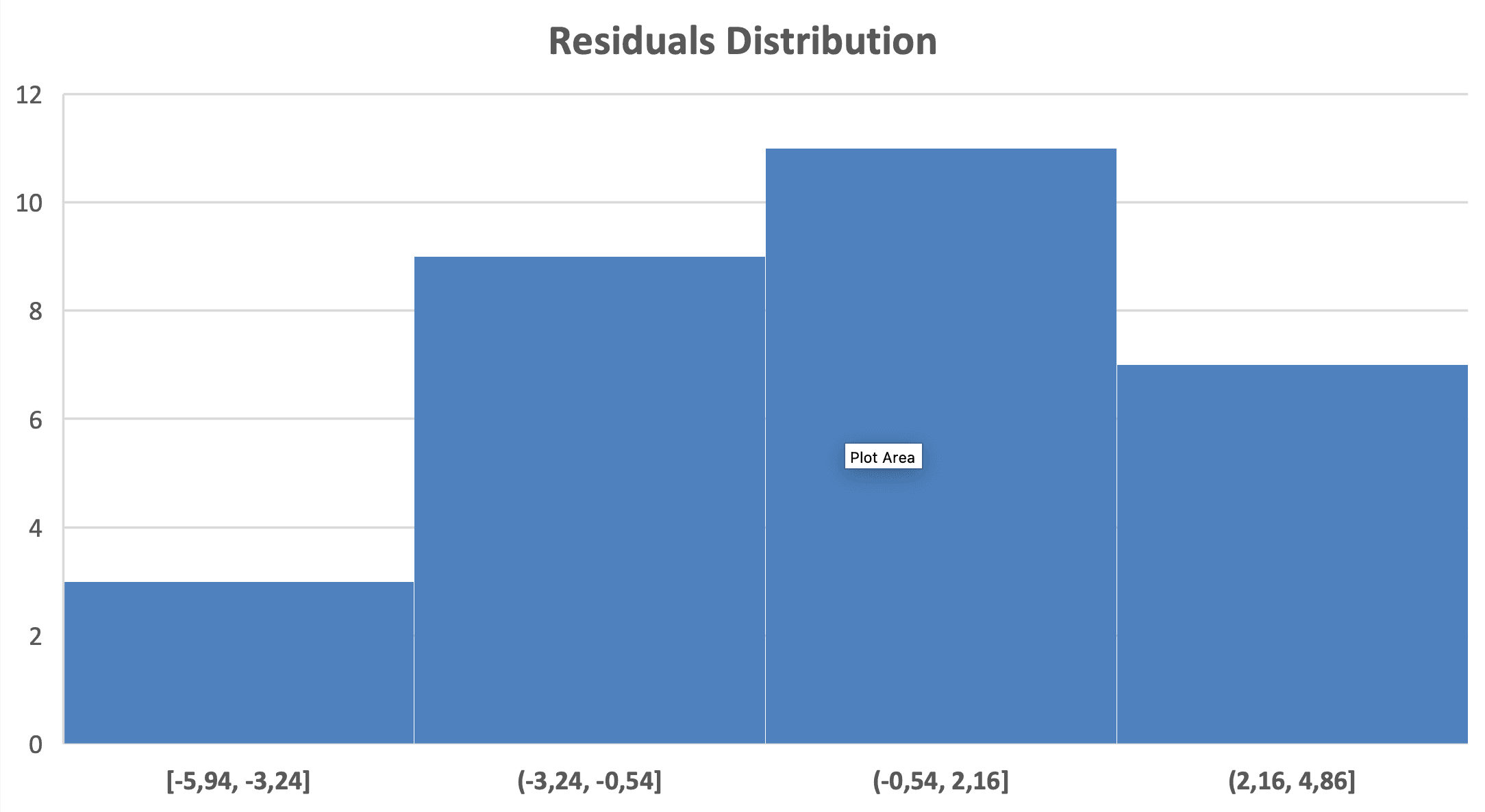
Figura 9: Verificación de normalidad. El histograma de residuos muestra distribución aproximadamente normal
Pasos:
- Marca la casilla Residuals en el cuadro de diálogo de regresión
- Encuentra la columna de Residuos en los resultados
- Crea histograma: Selecciona residuos → Insertar → Histograma (para creación detallada de histogramas, consulta nuestra guía de estadísticas descriptivas)
Qué buscar: Distribución en forma de campana, simétrica, centrada alrededor de cero.
Supuesto 4: Homocedasticidad (Varianza Constante)
Cómo verificar: Grafica los residuos vs. los valores predichos (ajustados).
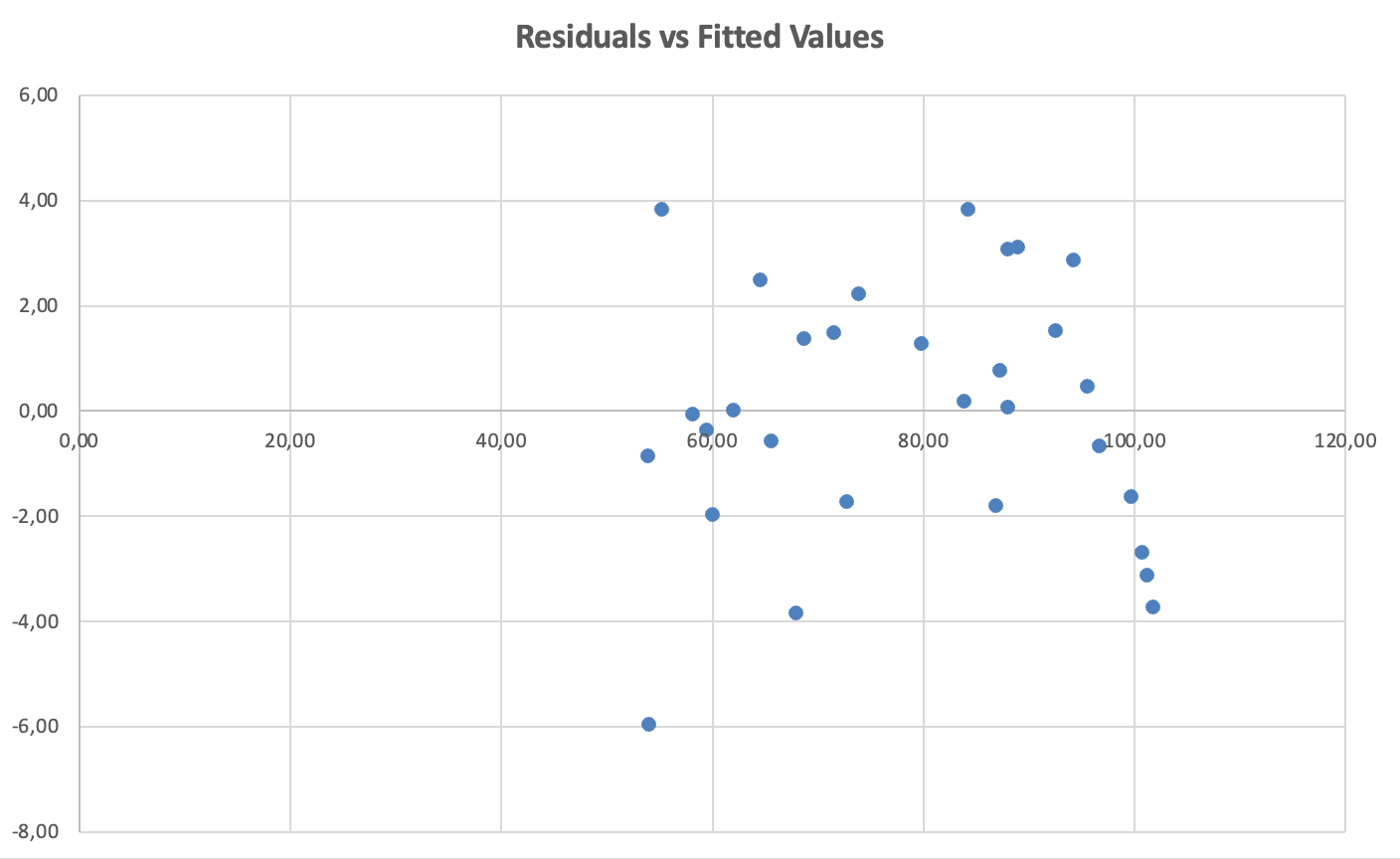
Figura 10: Verificación de homocedasticidad. Residuos vs. valores ajustados muestran dispersión constante (sin patrón de embudo)
Qué buscar: Dispersión aleatoria alrededor de cero con extensión aproximadamente constante en todos los valores ajustados. Violación: Forma de embudo o cono (la dispersión aumenta o disminuye).
Supuesto 5: Ausencia de Multicolinealidad (ÚNICO de la Regresión Múltiple)
Cómo verificar: Matriz de correlación de predictores (cubierta en la sección anterior).
Regla: Las correlaciones entre predictores deben estar por debajo de 0.80.
Reportando los Supuestos en tu Tesis
En la sección de Método:
Antes del análisis, se evaluaron los supuestos de la regresión lineal múltiple. Los diagramas de dispersión indicaron relaciones lineales entre cada predictor y la variable de resultado. El estadístico de Durbin-Watson no estaba disponible en Excel; sin embargo, las observaciones fueron independientes por diseño de investigación (diferentes estudiantes con mediciones únicas). Los histogramas de residuos mostraron una distribución aproximadamente normal, y los gráficos de residuos indicaron varianza constante (homocedasticidad). La multicolinealidad se evaluó usando una matriz de correlación de las variables predictoras; la mayoría de las correlaciones fueron bajas (r = 0.23-0.25), aunque Horas_Estudio y Clases_Asistidas mostraron una correlación límite (r = 0.82) que se monitoreó pero no afectó sustancialmente la interpretabilidad de los coeficientes.
Cómo Reportar la Regresión Múltiple en Formato APA 7.ª Edición
Tu comité de tesis espera que los resultados de regresión múltiple se reporten con elementos específicos. Aquí tienes el formato completo.
Plantilla de la Sección de Resultados APA
Formato de párrafo:
Se realizó una regresión lineal múltiple para examinar si las horas de estudio, las horas de sueño y la asistencia a clase predecían las calificaciones finales del examen. Los análisis preliminares confirmaron que se cumplían los supuestos de linealidad, independencia, normalidad de los residuos, homocedasticidad y ausencia de multicolinealidad.
El modelo de regresión múltiple predijo significativamente las calificaciones del examen, F(3, 26) = 373.65, p < .001, R² = .98, R² ajustado = .97. Los tres predictores juntos explicaron el 97.7% de la varianza en las calificaciones. Los coeficientes de regresión se presentan en la Tabla [X].
Las horas de estudio predijeron significativamente las calificaciones (B = 1.75, IC 95% [1.46, 2.04], p < .001), al igual que la asistencia a clase (B = 2.36, IC 95% [1.69, 3.04], p < .001). Las horas de sueño no fueron un predictor estadísticamente significativo (B = 0.52, IC 95% [-0.09, 1.14], p = .092). Por cada hora adicional de estudio semanal, las calificaciones aumentaron 1.75 puntos, controlando por sueño y asistencia. Cada clase adicional a la que se asistió se asoció con un incremento de 2.36 puntos en las calificaciones, controlando por los otros predictores.
Formato de Tabla de Regresión APA
Tabla [X]
Regresión Lineal Múltiple Prediciendo Calificaciones del Examen
| Variable | B | EE | β | t | p | IC 95% |
|---|---|---|---|---|---|---|
| Intercepto | 33.14 | 2.68 | — | 12.34 | < .001 | [27.63, 38.65] |
| Horas de Estudio | 1.75 | 0.14 | 1.04 | 12.50 | < .001 | [1.46, 2.04] |
| Horas de Sueño | 0.52 | 0.30 | .09 | 1.75 | .092 | [-0.09, 1.14] |
| Clases Asistidas | 2.36 | 0.33 | .63 | 7.22 | < .001 | [1.69, 3.04] |
Tabla 6: Regresión Lineal Múltiple Prediciendo Calificaciones del Examen a partir de Horas de Estudio, Horas de Sueño y Asistencia a Clase
Nota. n = 30. R² = .98, R² ajustado = .97, F(3, 26) = 373.65, p < .001. B = coeficiente no estandarizado. EE = error estándar. β = coeficiente estandarizado. IC = intervalo de confianza.
Lista de Verificación para Reportar Regresión Múltiple
Incluye TODOS estos elementos:
En texto (párrafo de Resultados):
- Tipo de análisis ("Se realizó una regresión lineal múltiple...")
- Variables probadas (todos los predictores y resultado)
- Declaración de verificación de supuestos
- Significancia del modelo general: F(gl_regresión, gl_residual) = valor F, valor p
- R² Y R² ajustado con interpretación
- Para CADA predictor: valor B, IC 95% y valor p
- Declaración clara de cuáles predictores fueron/no fueron significativos
- Interpretación de coeficientes significativos con dirección
En tabla:
- Número de tabla y título en cursiva
- Todos los predictores incluyendo intercepto
- B (coeficientes no estandarizados)
- EE (errores estándar)
- β (coeficientes estandarizados) si se calcularon
- Estadísticos t
- Valores p
- Intervalos de confianza del 95%
- Nota al pie con n, R², R² ajustado, estadístico F
Errores Comunes en la Regresión Múltiple
Evita estos errores frecuentes que pueden comprometer tu investigación de tesis:
1. Reportar R² en Lugar de R² Ajustado
Error: "El modelo explicó el 97.5% de la varianza (R² = .975)"
Por qué está mal: El R² siempre aumenta con más predictores, incluso si son inútiles. El R² ajustado corrige esto.
Cómo corregirlo: Reporta el R² ajustado como tu medida principal del tamaño del efecto, o reporta ambos: "R² = .972, R² ajustado = .969"
2. Ignorar la Multicolinealidad
Error: Agregar predictores altamente correlacionados sin verificar.
Por qué está mal: Los coeficientes se vuelven inestables, los errores estándar se inflan y no puedes interpretar cuál predictor importa.
Cómo corregirlo: Siempre crea una matriz de correlación de predictores antes de ejecutar la regresión. Elimina o combina variables con r mayor a 0.80.
3. Eliminar Predictores No Significativos Sin Justificación
Error: "El sueño no fue significativo, así que lo eliminé y volví a ejecutar el análisis."
Por qué está mal: Eliminar variables cambia el significado de los otros coeficientes. La eliminación selectiva puede producir resultados sesgados.
Cómo corregirlo: Conserva todos los predictores teóricamente relevantes. Reporta los no significativos como no significativos. Solo elimina si tienes razones teóricas sólidas Y reportas que lo hiciste.
4. Interpretar Coeficientes como "Más Importantes"
Error: "Las horas de estudio (B = 2.15) son más importantes que la asistencia (B = 1.85) porque 2.15 mayor a 1.85."
Por qué está mal: Los coeficientes no estandarizados dependen de la escala de cada variable. Estás comparando horas con clases, unidades diferentes.
Cómo corregirlo: Calcula y compara coeficientes estandarizados (β) para comparaciones de importancia.
5. Afirmar Causalidad a Partir de la Regresión
Error: "Estudiar más CAUSA mejores calificaciones."
Por qué está mal: La regresión muestra predicción y asociación, no causalidad. La causalidad requiere diseño experimental con asignación aleatoria.
Cómo corregirlo: Usa lenguaje cuidadoso: "predijo", "se asoció con", "se relacionó con" en lugar de "causó", "llevó a", "resultó en".
6. No Verificar los Supuestos
Error: Ejecutar la regresión sin verificar linealidad, normalidad, homocedasticidad y multicolinealidad.
Por qué está mal: Los supuestos violados producen coeficientes sesgados y valores p inválidos.
Cómo corregirlo: Siempre verifica los cinco supuestos antes de finalizar los resultados. Reporta la verificación de supuestos en Método.
7. Usar Demasiados Predictores para el Tamaño de Muestra
Error: Incluir 10 predictores con solo 50 observaciones.
Por qué está mal: El sobreajuste ocurre cuando el modelo se ajusta a tu muestra pero falla al generalizar. El requisito mínimo es n ≥ 50 + 8k.
Cómo corregirlo: Sigue las guías de tamaño de muestra. Para 10 predictores, necesitas al menos n = 130 observaciones. Si los datos faltantes han reducido tu muestra disponible, aborda esto primero consultando cómo manejar datos faltantes (enlazado en la sección de conjunto de datos).
Qué No Puede Hacer Excel: Limitaciones para Investigación de Tesis
Analysis ToolPak de Excel maneja bien la regresión lineal múltiple estándar, pero tiene limitaciones significativas para técnicas avanzadas. Entender estas limitaciones te ayuda a elegir el software correcto.
Tipos de Regresión que Requieren SPSS o R
| Técnica | Qué Hace | ¿Excel? | Usa en Su Lugar |
|---|---|---|---|
| Regresión Logística | Predice resultados binarios (sí/no) | No | SPSS, R |
| Regresión Stepwise | Selección automática de variables | No | SPSS, R |
| Regresión Jerárquica | Agrega predictores en bloques | No | SPSS |
| Análisis de Moderación | Prueba efectos de interacción | No | SPSS PROCESS |
| Análisis de Mediación | Prueba efectos indirectos | No | SPSS PROCESS |
| Cálculo de VIF | Prueba formal de multicolinealidad | No | SPSS, R |
| Durbin-Watson | Prueba de autocorrelación | No | SPSS, R |
| Regresión Polinomial | Relaciones curvilíneas | Sí (manual) | SPSS, R |
| Regresión Lineal Múltiple | 2+ predictores continuos | Sí | Todos los software |
Tabla 7: Capacidades de Regresión de Excel vs. Requisitos de Software Estadístico
Cuándo Usar Excel vs SPSS/R
Usa Excel cuando:
- Solo regresión lineal múltiple estándar
- Variable de resultado continua
- No necesitas VIF (la matriz de correlación es suficiente)
- El comité acepta los resultados de Excel
- Estás aprendiendo regresión antes de métodos avanzados
Usa SPSS/R cuando:
- Resultados binarios/categóricos (regresión logística)
- Necesitas regresión stepwise o jerárquica
- Pruebas de moderación o mediación
- El comité requiere VIF, Durbin-Watson
- Publicas en revistas que requieren salidas de SPSS/R
Punto clave: Excel es excelente para aprender regresión múltiple y para análisis básicos de tesis. Para técnicas avanzadas o pruebas formales de multicolinealidad, necesitarás SPSS o R. Verifica con tu asesor los requisitos de software.
Preguntas Frecuentes
Preguntas del Comité que Deberías Estar Preparado para Responder
Los comités de tesis frecuentemente hacen estas preguntas sobre los análisis de regresión múltiple. Preparar respuestas con anticipación demuestra competencia estadística y fortalece tu defensa.
"¿Por qué incluiste estos predictores específicos?"
Prepárate para justificar cada variable basándote en la teoría e investigación previa, no solo en conveniencia estadística. Cita literatura que muestre por qué cada predictor debería lógicamente relacionarse con tu resultado. Los comités desconfían del "data dredging" donde los predictores se incluyeron simplemente porque los datos estaban disponibles.
"¿Verificaste la multicolinealidad?"
Muestra tu matriz de correlación y explica que todas las correlaciones entre predictores estuvieron por debajo de 0.80 (o cualquier umbral que hayas usado). Si preguntan por el VIF y usaste Excel, explica que aunque Excel no puede calcular el VIF directamente, el método de la matriz de correlación identifica la multicolinealidad problemática. Reconoce que se necesitaría SPSS o R para pruebas formales de VIF.
"¿Por qué [variable] no es significativa?"
Un predictor no significativo no significa que la variable no sea importante. Explica que al controlar por los otros predictores, la contribución única de esta variable no fue estadísticamente distinguible de cero. Las razones posibles incluyen: solapamiento con otros predictores (varianza compartida), tamaño de muestra insuficiente para detectar un efecto pequeño, o genuinamente no hay relación única después de controlar por variables confusoras.
"¿Cuál es la significancia práctica de estos resultados?"
La significancia estadística no es lo mismo que la importancia práctica. Prepárate para explicar qué significa un coeficiente en términos reales. Por ejemplo: "Cada hora adicional de estudio se asocia con un incremento de 1.75 puntos en la calificación. A lo largo de un semestre, un estudiante que estudia 10 horas más por semana que el promedio podría esperar aproximadamente 17.5 puntos adicionales, potencialmente la diferencia entre una B y una A."
"¿Por qué no usaste SPSS o R?"
Si te preguntan, explica que Analysis ToolPak de Excel maneja adecuadamente la regresión lineal múltiple estándar para tu diseño de investigación. Reconoce las limitaciones de Excel (sin VIF, sin regresión stepwise, sin regresión logística) y explica por qué estas no fueron necesarias para tu análisis específico. Si tu comité prefiere fuertemente los resultados de SPSS, ofrece replicar el análisis en SPSS para la entrega final.
Próximos Pasos
Ya tienes un marco completo para realizar la regresión lineal múltiple en Excel: desde entender cuándo usarla, pasando por ejecutar el análisis, hasta interpretar resultados y reportar en formato APA. La clave del éxito no es solo ejecutar el análisis, sino entender qué significa cada resultado y verificar que tus datos cumplan los supuestos.
Si quieres aplicar técnicas similares con más predictores o en un entorno estadístico más completo, estos recursos te ayudarán a profundizar:
-
En SPSS: Regresión Lineal Múltiple en SPSS te permite obtener VIF, coeficientes estandarizados automáticos y diagnósticos avanzados de residuos sin cálculos manuales.
-
Analizar datos de encuestas: Cómo Analizar Datos de Encuestas en Excel te guía en el proceso completo de preparar y analizar datos de encuestas, un paso previo frecuente antes de aplicar regresión.
Referencias
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). https://doi.org/10.1037/0000165-000
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
Green, S. B. (1991). How many subjects does it take to do a regression analysis? Multivariate Behavioral Research, 26(3), 499–510. https://doi.org/10.1207/s15327906mbr2603_7
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2019). Multivariate data analysis (8th ed.). Cengage Learning.
Tabachnick, B. G., & Fidell, L. S. (2019). Using multivariate statistics (7th ed.). Pearson.