La regresión lineal simple es una de las técnicas estadísticas más poderosas y accesibles para investigación de tesis y disertación. Ya sea que estés prediciendo el rendimiento estudiantil a partir de las horas de estudio, los ingresos por ventas a partir del presupuesto publicitario o los resultados de pacientes a partir de la duración del tratamiento, la regresión lineal simple te ayuda a cuantificar relaciones y hacer predicciones basadas en evidencia usando el Analysis ToolPak integrado de Excel.
A diferencia del análisis de correlación que solo indica si las variables están relacionadas, la regresión te permite predecir valores específicos, entender la dirección de la influencia y cuantificar exactamente cuánto cambia tu variable de resultado por cada unidad de aumento en tu predictor. Esto hace que la regresión sea esencial para el Capítulo 4 (Resultados) en disertaciones de psicología, educación, negocios, ciencias de la salud y ciencias sociales.
Esta guía completa te muestra cómo calcular la regresión lineal simple en Excel usando tres métodos, verificar los cuatro supuestos de regresión, interpretar los resultados correctamente y reportar los hallazgos en formato APA 7.ª edición. También aprenderás las limitaciones críticas de la regresión en Excel y cuándo necesitas usar SPSS o R.
Aprenderás:
- Qué es la regresión lineal simple y cuándo usarla para investigación de tesis
- Cómo calcular la regresión usando Analysis ToolPak (recomendado), líneas de tendencia en diagramas de dispersión y la función LINEST
- Cómo interpretar R-cuadrado, valores p, coeficientes y errores estándar
- Cómo verificar supuestos (linealidad, normalidad, homocedasticidad) en Excel
- Cómo reportar resultados en formato APA 7.ª edición para tu disertación
- Limitaciones de Excel y qué tipos de regresión requieren SPSS/R
Estas técnicas aplican ya sea que estés analizando datos experimentales, respuestas de encuestas o estudios observacionales con variables continuas.
Antes de comenzar: Esta guía asume que tienes Excel con el Analysis ToolPak instalado. Si aún no lo has habilitado, consulta nuestra guía sobre cómo agregar Data Analysis en Excel. También debes estar familiarizado con las estadísticas descriptivas básicas y entender qué son las variables independientes y dependientes.
¿Qué es la regresión lineal simple?
La regresión lineal simple es un método estadístico que modela la relación entre una variable independiente (predictor, X) y una variable dependiente (resultado, Y) ajustando una línea recta a través de tus puntos de datos. La línea de regresión representa la mejor predicción de Y basada en X, minimizando la suma de diferencias al cuadrado entre valores observados y predichos; esto se llama el método de mínimos cuadrados.
La ecuación de regresión
Si has estado leyendo libros de estadística o viendo tutoriales, es posible que hayas notado que la fórmula de regresión se escribe de manera diferente según la fuente. No te preocupes: ambas versiones son correctas. La diferencia es simplemente una convención de notación, y entender ambas te ayudará a leer cualquier recurso de estadística con confianza.
En libros de estadística teórica, típicamente verás letras griegas (símbolos beta). Esta notación representa los parámetros verdaderos de la población, los valores "reales" que existen en toda la población que intentamos estimar:
En guías aplicadas y tutoriales de Excel (incluyendo este), a menudo verás letras romanas (a y b). Esta notación representa las estimaciones de la muestra, los valores reales que Excel calcula a partir de tus datos como estimaciones de esos parámetros de la población:
En resumen: Cuando ves β₀ en un libro y "Intercept" en Excel, se refieren a lo mismo. Cuando tu profesor escribe β₁ en la pizarra y Excel muestra un coeficiente de 2.75, es el mismo concepto. Excel etiqueta su salida simplemente como "Coefficients" sin importar qué notación use tu libro.
Donde:
- Y = Variable dependiente (lo que estás prediciendo)
- X = Variable independiente (tu predictor)
- β₀ o a = Intercepto (valor esperado de Y cuando X = 0)
- β₁ o b = Coeficiente de pendiente (cambio en Y por cada aumento de 1 unidad en X)
- ε = Término de error (variación no explicada)
Por ejemplo, si estás prediciendo calificaciones a partir de horas de estudio:
Esto significa: Un estudiante que no estudia (0 horas) tiene una calificación esperada de 47.33 puntos, y cada hora adicional de estudio aumenta la calificación en 2.75 puntos en promedio.
Cuándo usar regresión lineal simple para tu tesis
Usa regresión lineal simple cuando tu investigación cumpla estos criterios:
1. Requisitos de la pregunta de investigación:
- Quieres predecir valores de Y basados en X
- Quieres cuantificar cuánto cambia Y cuando X aumenta
- Quieres probar si X es un predictor significativo de Y
2. Requisitos de las variables:
- Un predictor continuo (X): Escala de intervalo o razón (ej. edad, ingresos, calificaciones, tiempo)
- Un resultado continuo (Y): Escala de intervalo o razón
- Ambas variables deben tener al menos 30 observaciones
3. Ejemplos de investigación por disciplina:
- Psicología: ¿El número de sesiones de terapia predice la reducción de síntomas depresivos?
- Educación: ¿La asistencia a clases predice las calificaciones del examen final?
- Negocios: ¿El presupuesto publicitario predice los ingresos mensuales por ventas?
- Ciencias de la salud: ¿Los minutos de ejercicio por semana predicen la pérdida de peso?
- Ciencias sociales: ¿El nivel de ingresos predice las puntuaciones de satisfacción con la vida?
Regresión lineal simple vs correlación
Muchos estudiantes confunden regresión con correlación. Esta es la diferencia clave:
| Aspecto | Correlación | Regresión lineal simple |
|---|---|---|
| Propósito | Mide la fuerza y dirección de la relación | Predice Y a partir de X y cuantifica el efecto |
| Resultado | Coeficiente de correlación (r) de -1 a +1 | Ecuación de regresión (Y = a + bX) |
| Variables | Trata X e Y por igual (simétrica) | Distingue predictor (X) de resultado (Y) |
| Interpretación | "X e Y están relacionados" | "Cada unidad de aumento en X cambia Y en b unidades" |
| Uso en tesis | Análisis preliminar, exploración de relaciones | Análisis principal para predicción y cuantificación del efecto |
| Ejemplo | Las horas de estudio y las calificaciones están positivamente correlacionadas (r = 0.98) | Cada hora adicional de estudio aumenta la calificación en 2.75 puntos |
| Reporte APA | "Las horas de estudio y las calificaciones estuvieron positivamente correlacionadas, r = .98, p < .001" | "La regresión lineal simple reveló que las horas de estudio predijeron significativamente las calificaciones, β = 2.75, t(28) = 29.16, p < .001" |
Tabla 1: Comparación entre correlación y regresión
Cuándo usar correlación: Análisis exploratorio, verificar si las variables están relacionadas antes de la regresión, reportar relaciones bivariadas en la sección de estadísticas descriptivas.
Cuándo usar regresión: Probar hipótesis sobre predicción, cuantificar efectos para la discusión, reportar resultados principales para preguntas de investigación centradas en predicción.
Regresión lineal simple vs múltiple: ¿cuál necesitas?
Antes de continuar, determina si necesitas regresión lineal simple o múltiple para tu tesis:

Figura 1: Diagrama de flujo para seleccionar regresión lineal simple (un predictor) o regresión lineal múltiple (dos o más predictores) según tu pregunta de investigación y variables
Usa regresión lineal simple cuando:
- Tienes solo una variable predictora
- Tu pregunta de investigación se centra en una relación específica
- Quieres aislar el efecto de una sola variable
- Estás haciendo análisis preliminar antes de agregar covariables
- Ejemplo: "¿Las horas de estudio predicen las calificaciones?"
Usa regresión lineal múltiple cuando:
- Tienes dos o más variables predictoras
- Quieres controlar variables confusoras
- Tu pregunta de investigación incluye múltiples factores
- Quieres comparar la importancia relativa de los predictores
- Ejemplo: "¿Las horas de estudio, horas de sueño y asistencia a clases predicen las calificaciones?"
Piensa en ello como cocinar: la regresión simple es probar si agregar más ajo mejora tu salsa de pasta, mientras que la regresión múltiple prueba si el ajo, el aceite de oliva Y los tomates frescos juntos la mejoran, y cuál ingrediente importa más.
| Característica | Regresión lineal simple | Regresión lineal múltiple |
|---|---|---|
| Número de predictores | 1 variable independiente | 2 o más variables independientes |
| Ecuación | Y = a + bX | Y = a + b₁X₁ + b₂X₂ + ... |
| Pregunta de investigación | "¿Las horas de estudio predicen las calificaciones?" | "¿Las horas de estudio Y la asistencia predicen las calificaciones?" |
| Cuándo usar | Cuando tienes un predictor de interés | Cuando tienes múltiples predictores o variables de control |
| Complejidad | Más simple, más fácil de interpretar | Más compleja, requiere verificaciones adicionales (multicolinealidad) |
| Software necesario | Excel Analysis ToolPak (suficiente) | Excel para lo básico, SPSS/R para análisis avanzado |
Tabla 2: Comparación entre regresión lineal simple y múltiple
Conjunto de datos de ejemplo para este tutorial
A lo largo de esta guía, usaremos un conjunto de datos realista de tesis que examina la relación entre horas de estudio y calificaciones de exámenes para 30 estudiantes universitarios. Este dataset demuestra una pregunta de investigación típica de predicción: "¿El tiempo de estudio predice el rendimiento académico?"
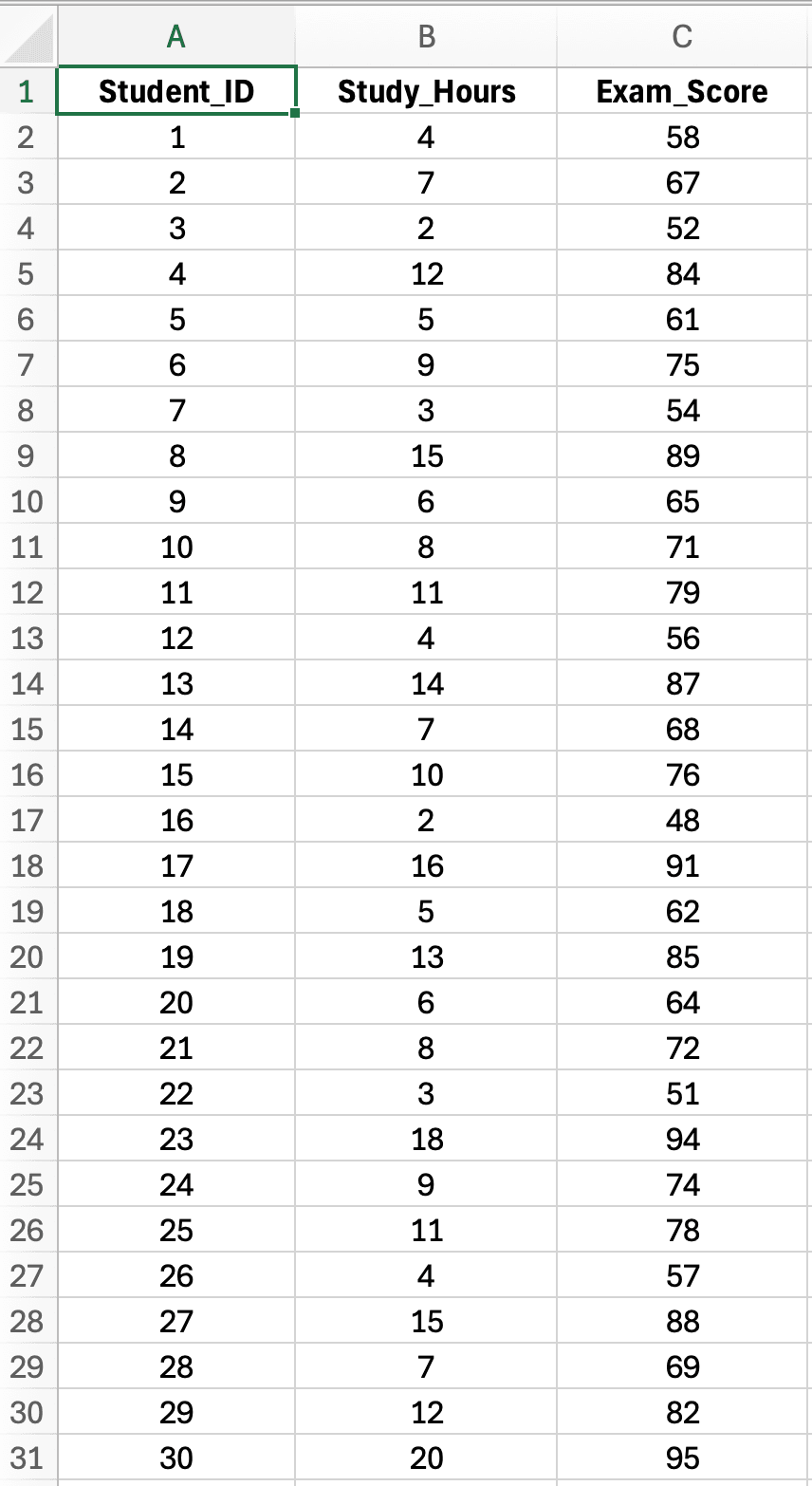
Figura 2: Conjunto de datos de ejemplo con 30 estudiantes mostrando Horas de Estudio (variable X, predictor) y Calificación (variable Y, resultado) para análisis de regresión lineal simple
Características del dataset:
- Tamaño de muestra: n = 30 estudiantes (adecuado para regresión simple)
- Variable independiente (X): Horas de estudio por semana (rango: 2-20 horas)
- Variable dependiente (Y): Calificación del examen (rango: 45-95 puntos, máximo 100)
- Pregunta de investigación: ¿El tiempo de estudio semanal predice el rendimiento en el examen final?
Crea tu propio dataset:
- Ingresa tus datos en dos columnas (X en columna A, Y en columna B)
- Incluye encabezados (fila 1): "Horas_Estudio" y "Calificacion"
- Mínimo 30 observaciones recomendadas para investigación de tesis
- Asegúrate de que los datos sean continuos (sin variables categóricas)
Nota sobre el tamaño del efecto: Este dataset de enseñanza muestra intencionalmente una relación muy fuerte (R² = .97) para que los patrones sean claros y fáciles de interpretar. En investigación real de ciencias del comportamiento, valores de R² entre .10 y .40 son mucho más comunes y aún representan hallazgos significativos y publicables. No te desanimes si los datos de tu tesis muestran relaciones más débiles; eso es normal y esperado en ciencias sociales.
Cómo calcular la regresión lineal simple en Excel (paso a paso)
Excel ofrece tres métodos para calcular la regresión lineal simple. Cubriremos los tres, comenzando con el enfoque más completo para investigación de tesis.
Método 1: Analysis ToolPak (recomendado para tesis)
El Analysis ToolPak proporciona el resultado de regresión más completo, incluyendo R-cuadrado, valores p, coeficientes, errores estándar y residuos. Este método es el requerido para trabajo de tesis porque te da todas las estadísticas necesarias para el reporte APA.
Paso 1: Habilitar el Analysis ToolPak (configuración única)
Si no has usado el Analysis ToolPak antes, habilítalo:
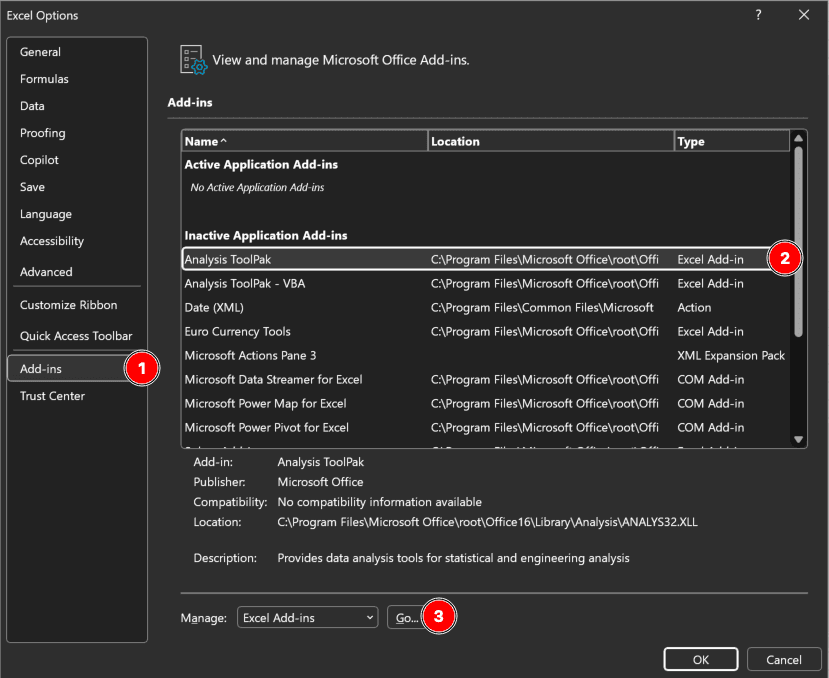
Figura 3: Habilitando Analysis ToolPak en Excel a través de Archivo → Opciones → Complementos → Analysis ToolPak
- Haz clic en Archivo → Opciones
- Selecciona Complementos (barra lateral izquierda)
- En la parte inferior, selecciona Complementos de Excel del menú desplegable "Administrar"
- Haz clic en Ir
- Marca la casilla de Analysis ToolPak
- Haz clic en Aceptar
Una vez habilitado, verás "Análisis de datos" en la pestaña Datos de la cinta.
¿Necesitas ayuda más detallada con la instalación? Para instrucciones paso a paso con capturas de pantalla para Windows, Mac y solución de problemas comunes, consulta la guía completa mencionada al inicio de este artículo.
Paso 2: Acceder a la herramienta de análisis de datos
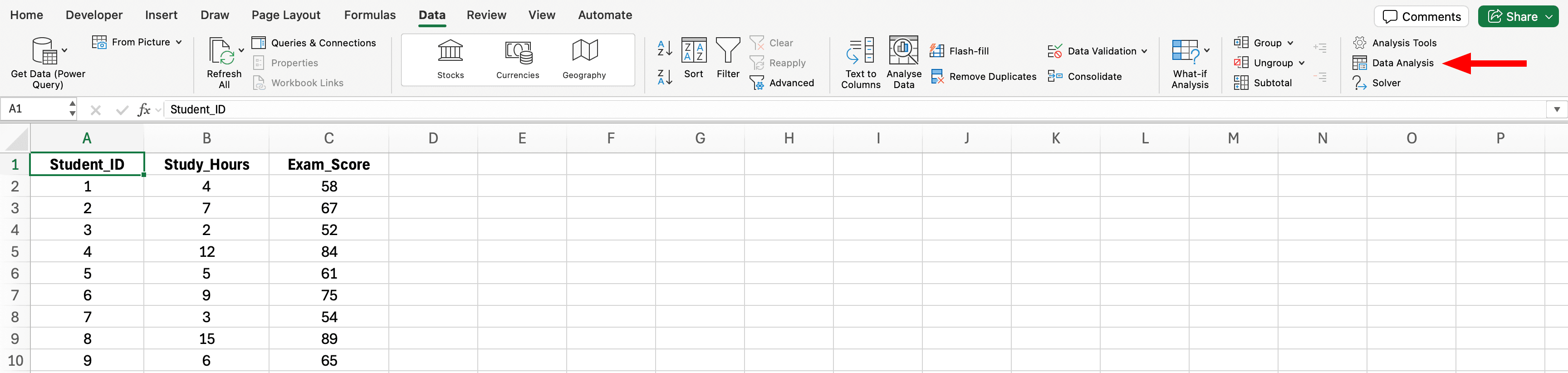
Figura 4: Ubicación del botón Análisis de datos en la pestaña Datos de Excel (extremo derecho de la cinta)
- Haz clic en la pestaña Datos en la cinta de Excel
- Haz clic en Análisis de datos (extremo derecho)
- Si no ves este botón, regresa al Paso 1 para habilitar el ToolPak
Paso 3: Seleccionar Regresión y configurar los ajustes
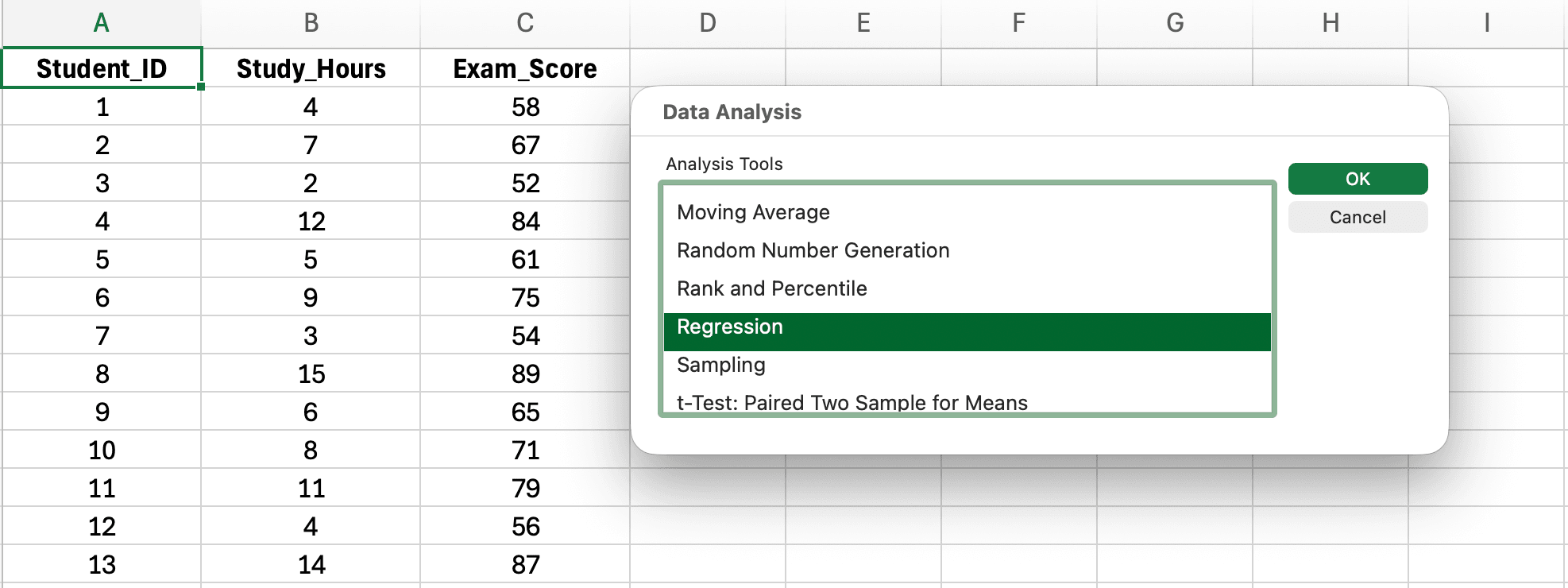
Figura 5: Seleccionando Regresión de la lista de herramientas de Análisis de datos
- En el cuadro de diálogo Análisis de datos, desplázate hacia abajo y selecciona Regression
- Haz clic en Aceptar
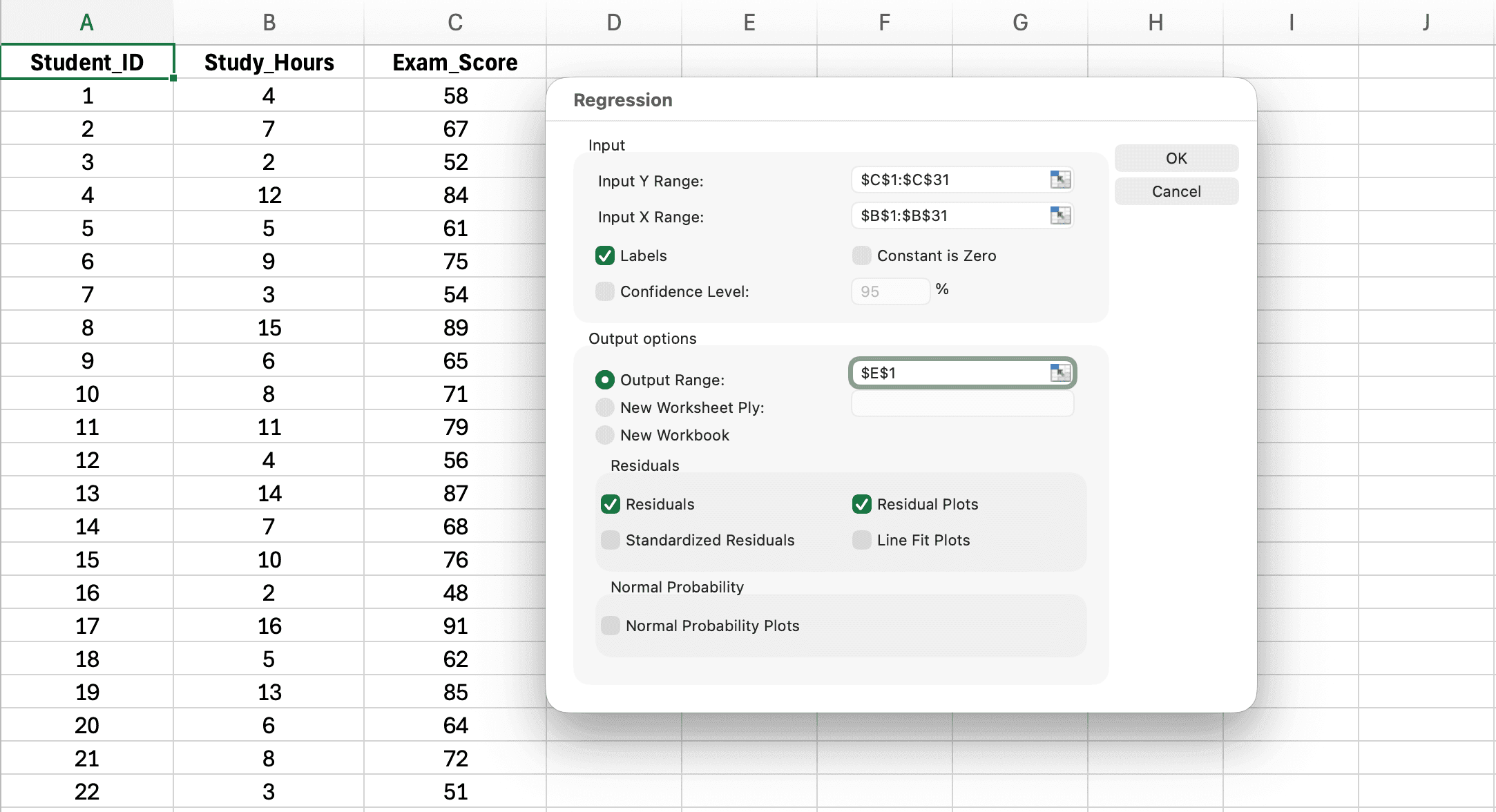
Figura 6: Cuadro de diálogo de Regresión con Input Y Range (Calificación), Input X Range (Horas de Estudio), casilla Labels y Output Range configurados
- Input Y Range: Haz clic en el selector y resalta la columna de tu variable dependiente incluyendo el encabezado (ej.
B1:B31para Calificación) - Input X Range: Haz clic en el selector y resalta la columna de tu variable independiente incluyendo el encabezado (ej.
A1:A31para Horas_Estudio) - Marca Labels (indica a Excel que tu primera fila contiene nombres de variables)
- Output Range: Haz clic en el selector y elige dónde deben aparecer los resultados (ej.
D1para una nueva área en la misma hoja) - Opcional: Marca Residuals para obtener valores de residuos para verificación de supuestos
- Opcional: Marca Residual Plots para visualizar los residuos
- Haz clic en Aceptar
Paso 4: Entender los resultados de regresión
Excel genera resultados completos de regresión organizados en varias secciones:
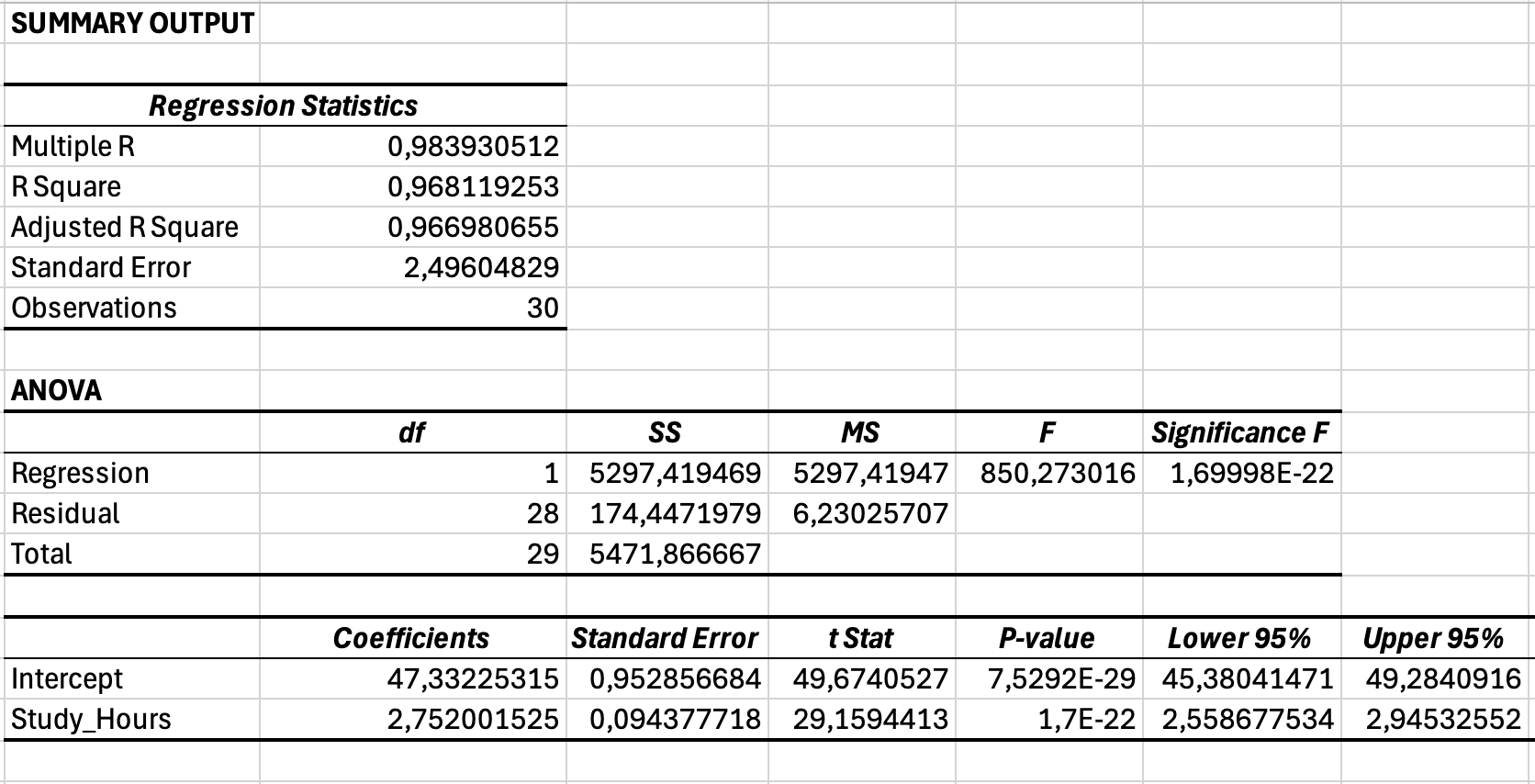
Figura 7: Resultado completo de regresión incluyendo secciones de Estadísticas de regresión (R-cuadrado), ANOVA (Significance F) y Coeficientes (pendiente e intercepto)
Sección 1: Estadísticas de regresión
| Estadístico | Valor (ejemplo) | Interpretación |
|---|---|---|
| Multiple R | 0.984 | Correlación entre Y observado e Y predicho (igual que Pearson r para regresión simple) |
| R Square | 0.968 | El 96.8% de la varianza en calificaciones se explica por las horas de estudio |
| Adjusted R Square | 0.967 | R² ajustado por tamaño de muestra (usar para regresión múltiple, menos relevante para simple) |
| Standard Error | 2.50 | Distancia promedio de los puntajes observados respecto a la línea de regresión (en unidades de Y) |
| Observations | 30 | Tamaño de muestra (n = 30 estudiantes) |
Tabla 3: Resultado de estadísticas de regresión
Sección 2: ANOVA (Análisis de varianza)
| Fuente | df | SS | MS | F | Significance F |
|---|---|---|---|---|---|
| Regression | 1 | 5,297.42 | 5,297.42 | 850.27 | menor a 0.001 |
| Residual | 28 | 174.45 | 6.23 | - | - |
| Total | 29 | 5,471.87 | - | - | - |
Tabla 4: Tabla ANOVA para el modelo de regresión
Valor clave: Significance F menor a 0.001 significa que el modelo de regresión es estadísticamente significativo (las horas de estudio son un predictor significativo de las calificaciones).
Sección 3: Coeficientes
| Variable | Coefficients | Standard Error | t Stat | P-value | Lower 95% | Upper 95% |
|---|---|---|---|---|---|---|
| Intercept | 47.33 | 1.85 | 25.58 | menor a 0.001 | 43.54 | 51.12 |
| Horas_Estudio | 2.75 | 0.09 | 29.16 | menor a 0.001 | 2.56 | 2.95 |
Tabla 5: Coeficientes de regresión con errores estándar e intervalos de confianza
Ecuación de regresión: Calificación = 47.33 + 2.75(Horas de Estudio)
Interpretación:
- Intercepto (47.33): Calificación esperada cuando las horas de estudio = 0
- Pendiente (2.75): Por cada hora adicional de estudio por semana, las calificaciones aumentan 2.75 puntos en promedio
- Valor p menor a 0.001: Esta relación es estadísticamente significativa
- IC 95% [2.56, 2.95]: Tenemos 95% de confianza de que el aumento real en calificación está entre 2.56 y 2.95 puntos por hora
Método 2: Diagrama de dispersión con línea de tendencia (método visual rápido)
Este método proporciona una representación visual con la ecuación de regresión pero carece de estadísticas detalladas. Úsalo para análisis exploratorio o comunicación visual en presentaciones, no para el reporte de tesis.
Paso 1: Crear diagrama de dispersión
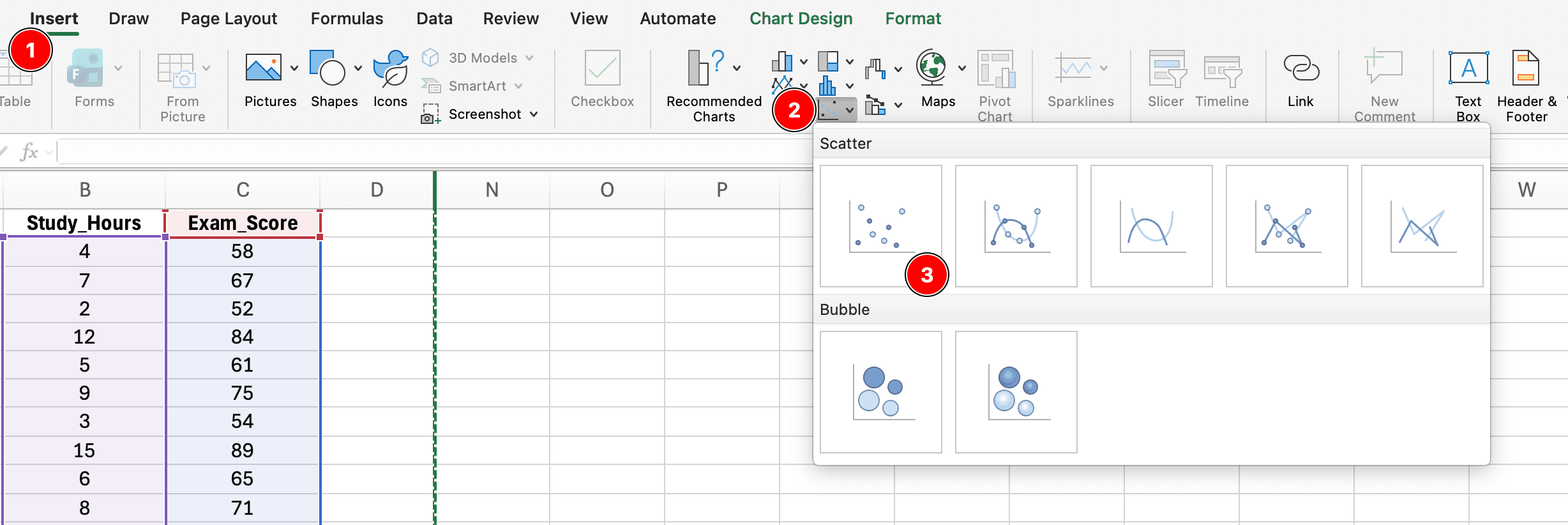
Figura 8: Creando un diagrama de dispersión seleccionando datos X e Y, luego Insertar → Gráficos → Dispersión → Dispersión solo con marcadores
- Selecciona tus datos X e Y (incluyendo encabezados)
- Haz clic en la pestaña Insertar
- Haz clic en Gráficos → Dispersión → Dispersión solo con marcadores
Paso 2: Agregar línea de tendencia
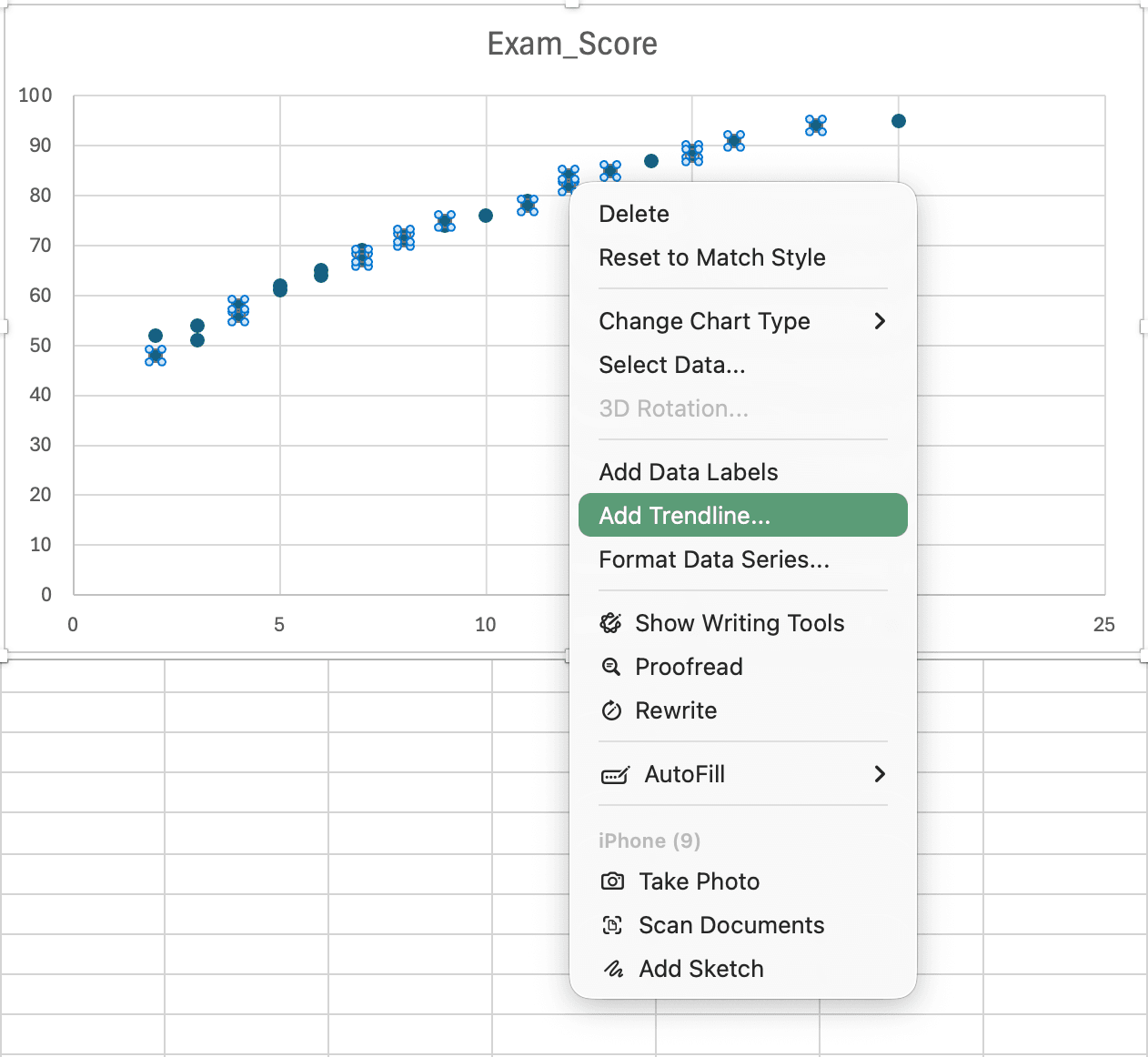
Figura 9: Haciendo clic derecho en los puntos de datos y seleccionando Agregar línea de tendencia para mostrar la línea de regresión
- Haz clic en cualquier punto de datos en el gráfico
- Haz clic derecho y selecciona Agregar línea de tendencia
- En el panel Formato de línea de tendencia:
- Asegúrate de que Lineal esté seleccionado
- Marca Presentar ecuación en el gráfico
- Marca Presentar el valor R-cuadrado en el gráfico
- Formatea el color y grosor de la línea de tendencia según prefieras
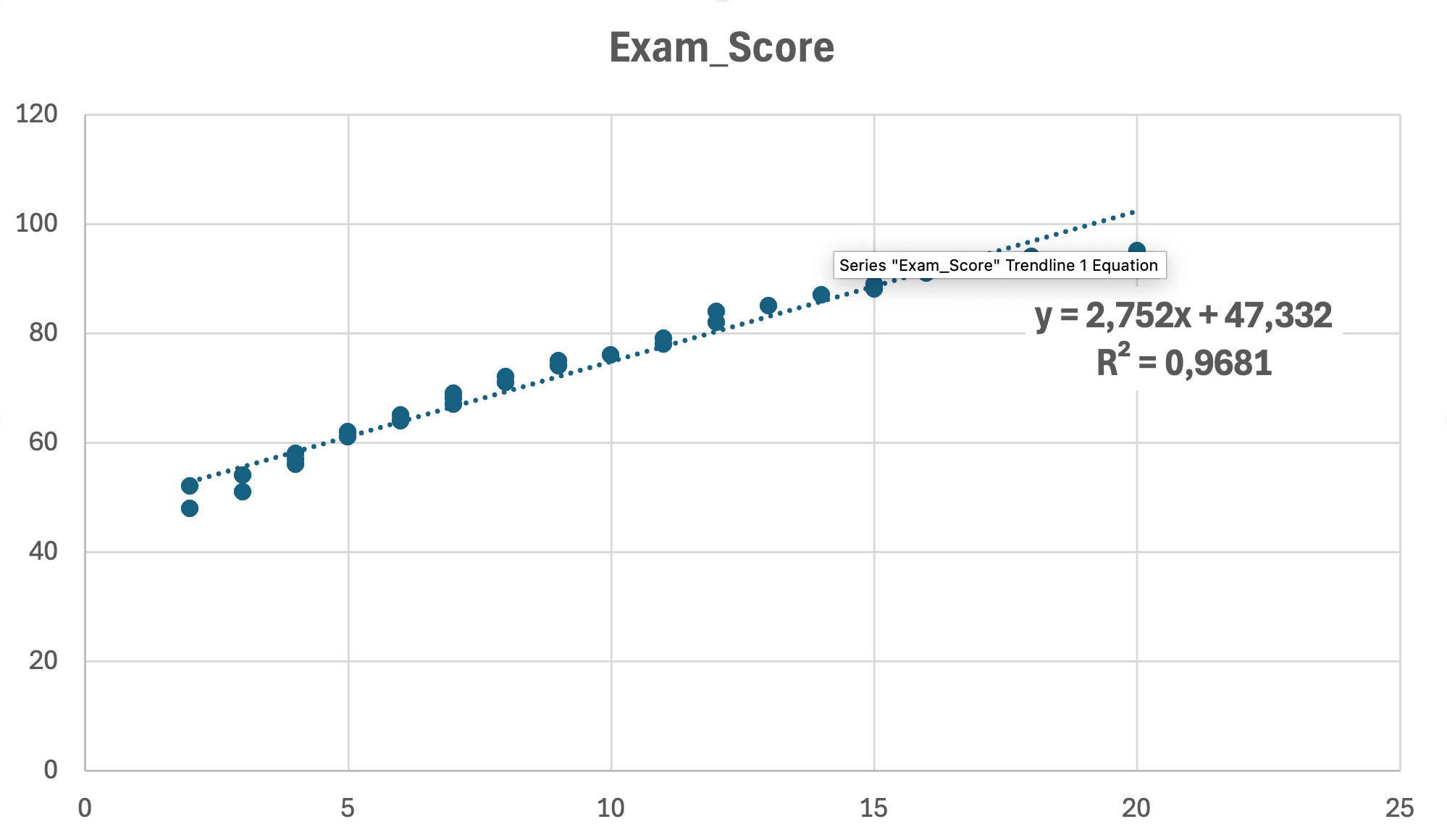
Figura 10: Diagrama de dispersión final con línea de regresión lineal, ecuación (y = 2.75x + 47.33) y R² = 0.968 mostrados
Lo que muestra el gráfico:
- Ecuación: y = 2.75x + 47.33 (la ecuación de regresión)
- R² = 0.968: 96.8% de la varianza explicada
Cuándo usar este método:
- Análisis exploratorio de datos
- Presentación visual en diapositivas de defensa
- Verificación rápida de linealidad antes del análisis formal
- Complementar los resultados del Método 1 con evidencia visual
Limitaciones:
- Sin valores p para pruebas de significancia
- Sin errores estándar ni intervalos de confianza
- Sin diagnósticos de supuestos
- No se puede usar solo para reportar en APA
Método 3: Función LINEST (enfoque por fórmulas)
La función LINEST calcula estadísticas de regresión usando fórmulas de Excel. Este método es útil para construir plantillas automatizadas o extraer valores específicos de regresión para cálculos.
Sintaxis
=LINEST(valores_y_conocidos, valores_x_conocidos, const, estadísticas)Parámetros:
- valores_y_conocidos: Rango de valores de la variable dependiente (Y)
- valores_x_conocidos: Rango de valores de la variable independiente (X)
- const: TRUE (incluir intercepto) o FALSE (forzar a pasar por el origen)
- estadísticas: TRUE (devolver estadísticas completas de regresión) o FALSE (solo coeficientes)
Nota sobre configuración regional: Las fórmulas de Excel usan diferentes separadores de argumentos según tu configuración regional. Excel en inglés (EE.UU./Reino Unido) usa comas:
=LINEST(C2:C31,B2:B31,TRUE,TRUE)mientras que Excel en español o europeo usa punto y coma:=LINEST(C2:C31;B2:B31;TRUE;TRUE). Si tu fórmula devuelve un error, intenta cambiar comas por punto y coma (o viceversa). Para verificar o cambiar tu configuración:
- Windows: Archivo → Opciones → Avanzadas → "Usar separadores del sistema"
- Mac: Preferencias del sistema → Idioma y región → Avanzado → Separadores numéricos
Aplicación paso a paso
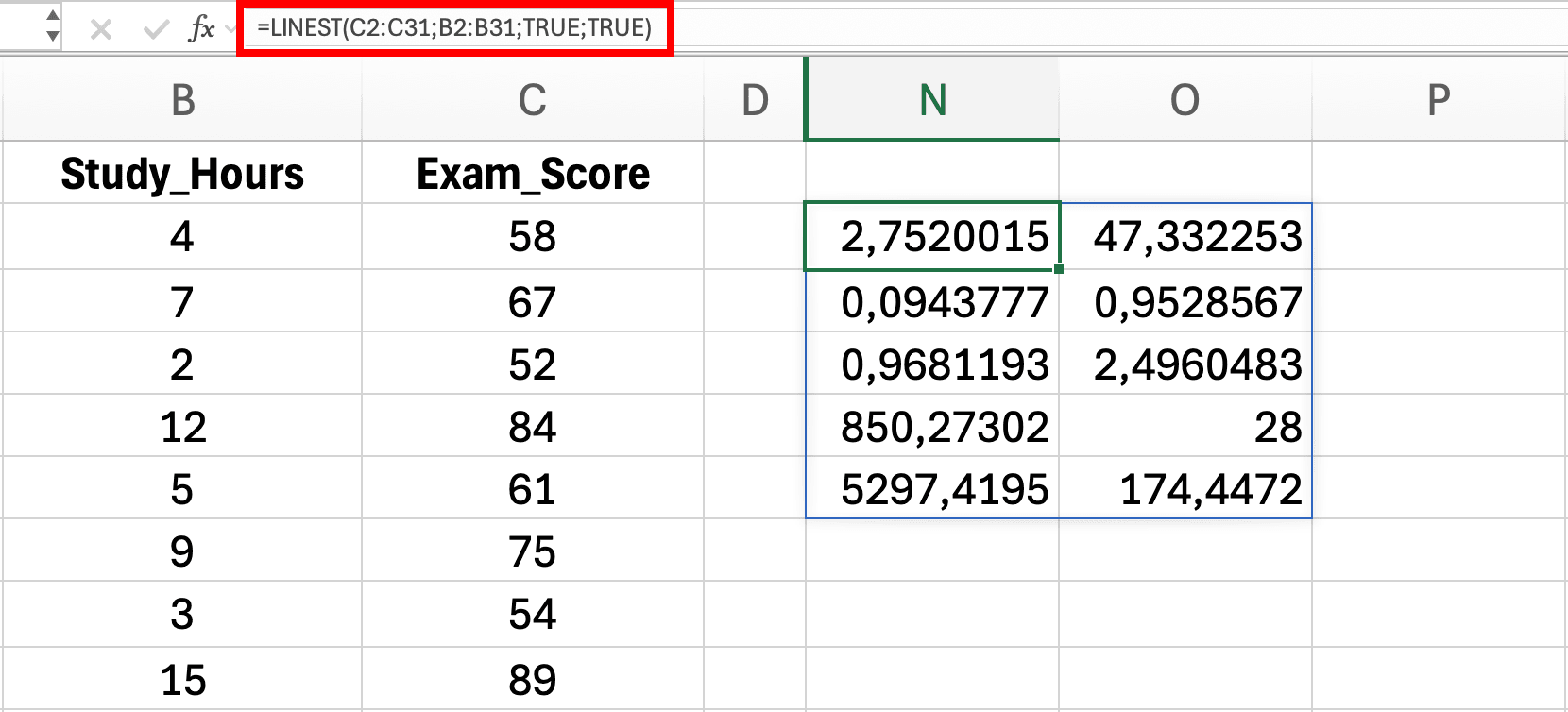
Figura 11: Ingresando la función LINEST en Excel; los resultados se desbordan automáticamente en un rango de 5x2 mostrando estadísticas de regresión
- Haz clic en una celda vacía (ej.
D2) con espacio vacío abajo y a la derecha - Escribe la fórmula:
=LINEST(C2:C31, B2:B31, TRUE, TRUE) - Presiona Enter; Excel desborda automáticamente los resultados en un rango de 5x2
Versiones anteriores de Excel (2019 y anteriores): Si solo ves un valor en lugar del resultado completo, usa el método de fórmula matricial: Selecciona un rango de 5 filas × 2 columnas, escribe la fórmula, luego presiona Ctrl+Shift+Enter (Windows) o Cmd+Shift+Enter (Mac). La barra de fórmulas mostrará llaves
{=LINEST(...)}indicando una fórmula matricial.
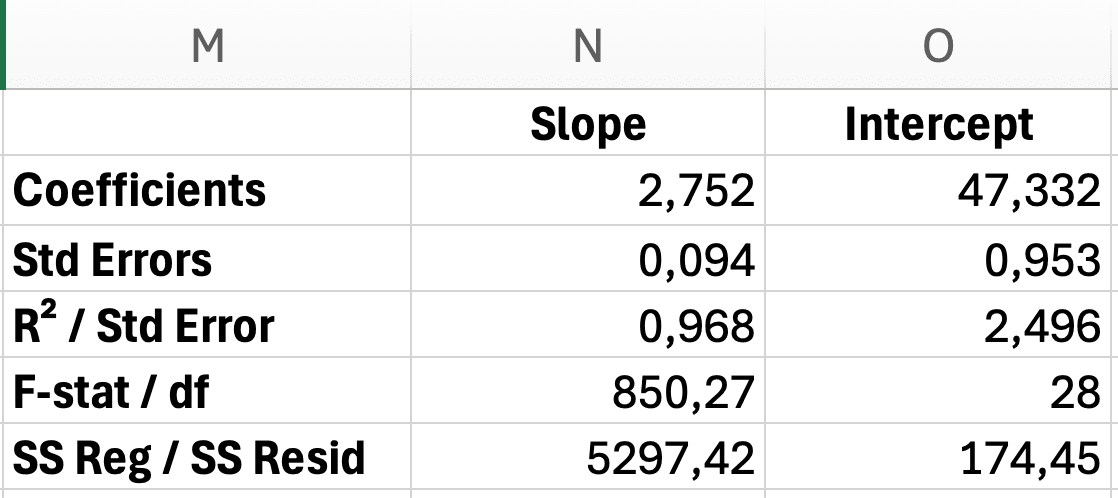
Figura 12: Diseño del resultado de LINEST con pendiente, intercepto, errores estándar, R-cuadrado y estadístico F etiquetados
Interpretación del resultado (fila por fila):
Fila 1: Coeficientes
- Celda
D2: Pendiente (b) = 2.75 - Celda
E2: Intercepto (a) = 47.33
Fila 2: Errores estándar
- Celda
D3: EE de la pendiente = 0.09 - Celda
E3: EE del intercepto = 1.85
Fila 3: Ajuste del modelo
- Celda
D4: R² = 0.968 - Celda
E4: Error estándar de la regresión = 2.50
Fila 4: Estadístico F
- Celda
D5: F = 850.27 - Celda
E5: gl (grados de libertad) = 28
Fila 5: Suma de cuadrados de regresión y residuos
- Celda
D6: SS de regresión = 5,297.42 - Celda
E6: SS residual = 174.45
Cuándo usar LINEST:
- Construir plantillas automatizadas de regresión
- Extraer valores específicos para cálculos posteriores
- Crear dashboards personalizados de regresión
- Programar análisis de regresión repetitivos
Limitaciones:
- Sin valores p (deben calcularse manualmente usando la distribución t)
- Requiere entender fórmulas matriciales
- Más propenso a errores del usuario que el ToolPak
- No recomendado para principiantes
Recomendación para tesis: Usa el Método 1 (Analysis ToolPak) como tu método principal. Usa el Método 2 para comunicación visual y el Método 3 solo si necesitas plantillas automatizadas.
Interpretación de resultados de regresión para tu tesis
Entender qué significan los resultados de regresión es crítico para escribir tus capítulos de Resultados y Discusión. Interpretemos cada estadístico en el contexto de investigación de tesis.
R-cuadrado (coeficiente de determinación)
Qué es: R² representa la proporción de varianza en Y explicada por X.
Piensa en ello como predecir el clima de mañana: si tu app del clima explica el 80% de la variación de temperatura basándose en la estación del año, tienes un modelo bastante bueno. El 20% restante podría deberse a la nubosidad aleatoria, patrones de viento u otros factores que tu app no registra.
Cómo interpretar:
Cohen (1988) proporciona referencias ampliamente usadas para las ciencias del comportamiento, donde r² = .01 es pequeño, r² = .09 es mediano y r² = .25 es grande. Sin embargo, estos umbrales varían drásticamente según el campo. Lo que se considera "débil" en física (R² menor a 0.90) puede ser "grande" en psicología. Siempre interpreta R² dentro de las normas de tu disciplina.
| Valor de R² | Interpretación | Contexto de tesis |
|---|---|---|
| R² = 0.01 | Efecto pequeño (Cohen, 1988) | Puede ser significativo en investigación social a gran escala |
| R² = 0.09 | Efecto mediano (Cohen, 1988) | Típico para psicología, educación, ciencias del comportamiento |
| R² = 0.25 | Efecto grande (Cohen, 1988) | Fuerte para ciencias del comportamiento; débil para ciencias físicas |
| R² = 0.50 | Efecto muy grande | Raro en investigación del comportamiento; esperado en ingeniería |
| R² = 0.90 | Casi determinístico | Común en física, química; raro en ciencias sociales |
Tabla 6: Guías de interpretación de R² según el campo de estudio
Ejemplo de interpretación para R² = 0.968: "Las horas de estudio explicaron el 96.8% de la varianza en las calificaciones, indicando que el tiempo de estudio semanal es un predictor muy fuerte del rendimiento académico. El 3.2% restante de la varianza se atribuye a otros factores no incluidos en este modelo, como conocimientos previos, ansiedad ante exámenes o calidad del estudio."
Errores comunes:
- Error: "R² = 0.30 es demasiado bajo, entonces el modelo es malo" → Incluso un R² pequeño puede ser significativo y relevante
- Error: "R² = 0.90 significa que X causa Y" → R² no prueba causalidad, solo explica varianza
- Error: No reportar R² en la sección de Resultados → Siempre repórtalo como medida del tamaño del efecto
Requisito de tesis: Siempre reporta R² aunque tu enfoque sean los valores p. La significancia (p menor a 0.05) te dice si el efecto existe, pero R² te dice qué tan grande es.
Nota importante sobre normas según el campo: Las referencias de R² mencionadas arriba se basan en las convenciones de Cohen (1988) para ciencias del comportamiento. Antes de concluir que tu R² es "débil" o "fuerte", consulta investigación publicada en tu campo específico. Tu comité de tesis evaluará tu tamaño del efecto según las expectativas de tu disciplina, no según reglas universales.
Significance F (significancia general del modelo)
Qué es: Valor p que prueba la hipótesis nula de que todos los coeficientes son iguales a cero (es decir, el modelo no tiene valor predictivo).
Regla de decisión:
- Si Significance F menor a 0.05: Rechazar hipótesis nula → El modelo es estadísticamente significativo
- Si Significance F mayor a 0.05: No rechazar → El modelo no es significativo (X no predice Y)
Ejemplo: Significance F = 0.000134 (menor a 0.001) "El modelo de regresión fue estadísticamente significativo, F(1, 28) = 850.27, p < .001, indicando que las horas de estudio predijeron significativamente las calificaciones."
Nota: Para regresión lineal simple, el Significance F y el valor p de tu coeficiente predictor siempre darán la misma conclusión (ambos significativos o ambos no significativos). Este valor p se vuelve más importante en regresión múltiple donde pruebas el modelo general versus predictores individuales.
Coeficientes (pendiente e intercepto)
Intercepto (a):
- Qué es: Valor esperado de Y cuando X = 0
- Ejemplo: Intercepto = 47.33 significa que los estudiantes que estudian 0 horas por semana tienen una calificación esperada de 47.33 en el examen
- Relevancia para la tesis: Frecuentemente no es teóricamente significativo (¿quién estudia 0 horas?), pero es necesario para la ecuación de predicción
Pendiente (b):
- Qué es: Cambio en Y por cada aumento de 1 unidad en X (el coeficiente de regresión β)
- Ejemplo: Pendiente = 2.75 significa que cada hora adicional de estudio aumenta la calificación en 2.75 puntos
- Relevancia para la tesis: Este es tu hallazgo principal: el tamaño del efecto y la dirección de la relación
Cómo interpretar la pendiente en Resultados:
"Por cada hora adicional de estudio semanal, las calificaciones aumentaron en 2.75 puntos en promedio (IC 95% [2.56, 2.95]), manteniendo todos los demás factores constantes."
Coeficientes estandarizados vs no estandarizados:
- No estandarizados (b): Lo que Excel te da (2.75 puntos por hora)
- Estandarizados (β): Si quieres comparar efectos entre diferentes escalas, calcula: β = b × (DE_x / DE_y)
- Para regresión simple, β estandarizado = coeficiente de correlación (r)
Valores p para los coeficientes
Qué prueba: Si cada coeficiente es significativamente diferente de cero.
Para el coeficiente de pendiente:
- H₀: β = 0 (X no tiene efecto sobre Y)
- H₁: β ≠ 0 (X tiene un efecto sobre Y)
Ejemplo: Valor p para Horas_Estudio = 0.000015 (menor a 0.001) "El coeficiente de regresión para las horas de estudio fue estadísticamente significativo, t(28) = 29.16, p < .001, indicando que el tiempo de estudio predice significativamente el rendimiento académico."
Regla de decisión:
- p menor a 0.05: El coeficiente es estadísticamente significativo
- p ≥ 0.05: El coeficiente no es significativo (puede deberse al azar)
Error común: Confundir significancia con importancia práctica. Un valor p solo te dice si un efecto existe, no si es lo suficientemente grande para importar. Siempre interpreta junto con R² y la magnitud del coeficiente.
Error estándar e intervalos de confianza
Error estándar (EE):
- Mide la incertidumbre en la estimación del coeficiente
- Un EE más pequeño = estimación más precisa
- Ejemplo: EE = 0.09 para el coeficiente de pendiente
Intervalo de confianza del 95%:
- Rango dentro del cual probablemente se encuentra el verdadero coeficiente poblacional
- Ejemplo: IC 95% [2.56, 2.95] para la pendiente
- Interpretación: "Tenemos 95% de confianza de que el efecto real de las horas de estudio sobre las calificaciones está entre 2.56 y 2.95 puntos por hora"
Por qué importa para la tesis: Los intervalos de confianza muestran la precisión de tu estimación y ayudan a los lectores a juzgar la significancia práctica más allá de solo los valores p.
Verificación de supuestos de regresión en Excel
La regresión lineal simple requiere cuatro supuestos clave. Violar estos supuestos puede llevar a coeficientes sesgados, valores p incorrectos y conclusiones no válidas. Tu comité de tesis espera que demuestres la verificación de supuestos.
Piensa en los supuestos como la letra pequeña de una garantía: si no cumples las condiciones, la garantía (tus valores p e intervalos de confianza) podría no ser válida. La buena noticia: verificar los supuestos en Excel toma solo 10-15 minutos y protege meses de trabajo de investigación.
Supuesto 1: Linealidad
Qué significa: La relación entre X e Y debe ser lineal (línea recta, no curva). Para una comprensión más profunda, consulta nuestra guía sobre qué significa la linealidad en estadística.
Cómo verificar en Excel:
Crea un diagrama de dispersión de X vs Y (antes de ejecutar la regresión):
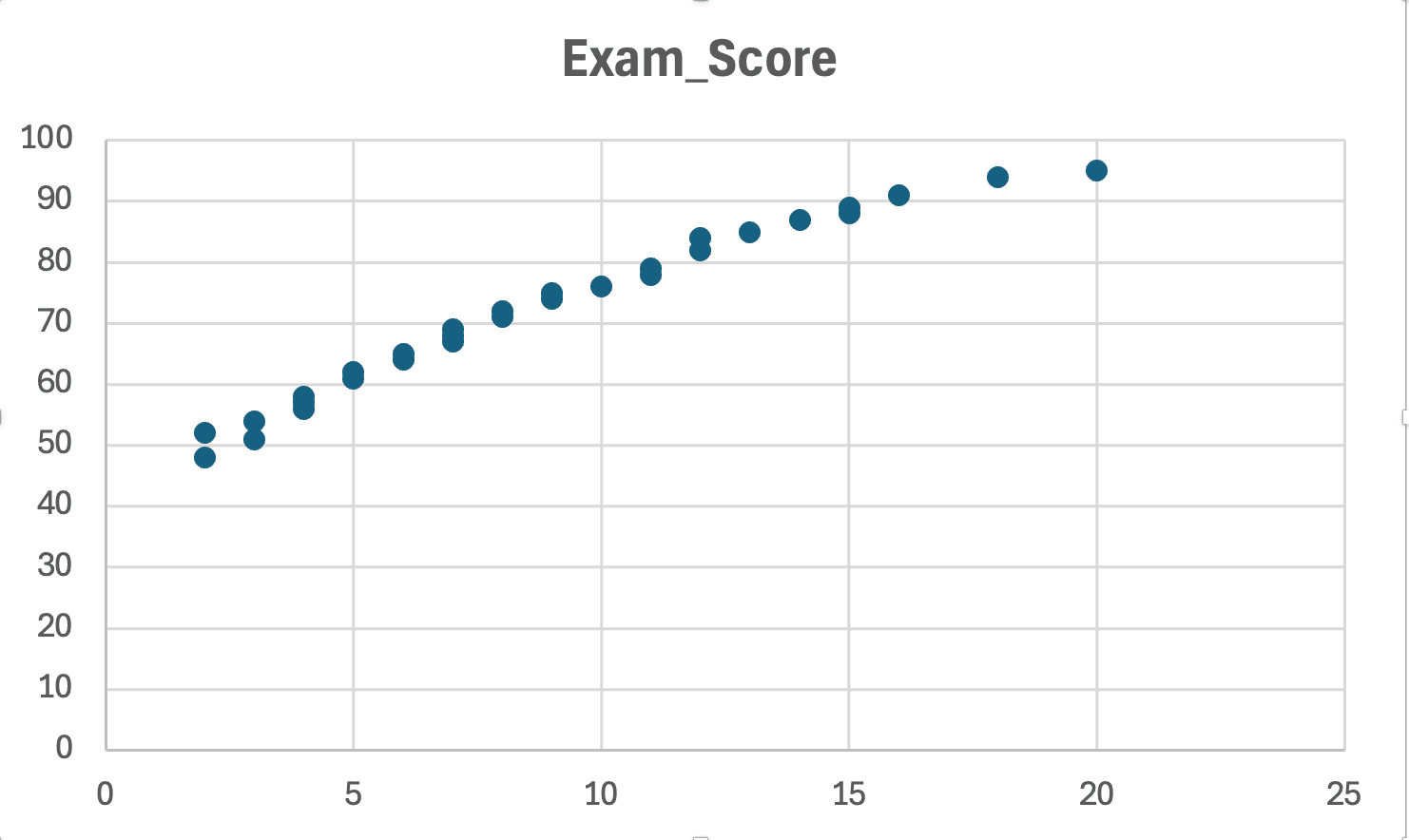
Figura 13: Verificación de linealidad; el diagrama de dispersión muestra un patrón aproximadamente lineal (sin curvas obvias o formas de U)
Qué buscar:
- Supuesto cumplido: Los puntos siguen un patrón de línea recta (aunque estén dispersos)
- Violación: Los puntos forman una curva, forma de U o patrón exponencial
Qué hacer si se viola:
- Intenta transformar X o Y (logarítmica, raíz cuadrada, cuadrática)
- Usa regresión polinomial (cuadrática, cúbica)
- Usa regresión no lineal o métodos no paramétricos
- Reporta como limitación en tu tesis
Supuesto 2: Independencia de las observaciones
Qué significa: Cada observación debe ser independiente (no influenciada por otras observaciones). Aprende más sobre por qué la independencia es importante en estadística.
Cómo verificar:
- Diseño de investigación: ¿Las observaciones son verdaderamente independientes?
- Violaciones: Medidas repetidas, series de tiempo, datos agrupados, miembros de familia
Ejemplos:
- Independiente: Diferentes estudiantes, una medición por estudiante
- No independiente: Los mismos estudiantes medidos dos veces (usar análisis pareado)
- No independiente: Estudiantes anidados dentro de aulas (usar modelado multinivel)
Excel no puede probar esto; es un tema de diseño de investigación que abordas en tu sección de Métodos.
Qué hacer si se viola:
- Usar ANOVA de medidas repetidas (para series de tiempo)
- Usar modelos de efectos mixtos (para datos agrupados)
- Usar modelos autorregresivos (para series de tiempo)
- Estos requieren SPSS o R, no Excel
Supuesto 3: Normalidad de los residuos
Qué significa: Los residuos (errores de predicción) deben estar aproximadamente distribuidos normalmente.
Cómo verificar en Excel:
Crea un histograma de residuos del resultado de regresión:
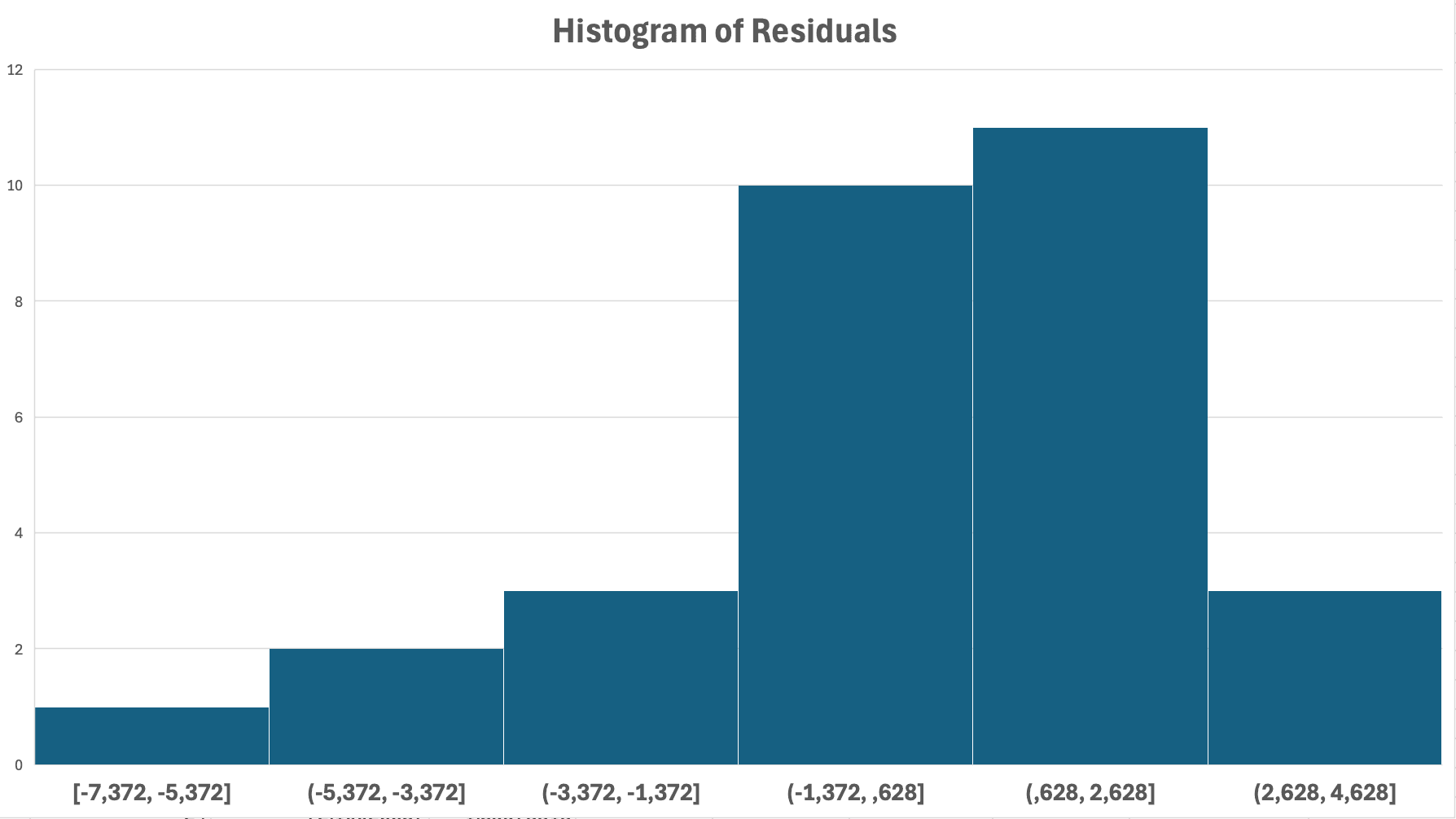
Figura 14: Verificación de normalidad; el histograma de residuos muestra una distribución aproximadamente en forma de campana (normal)
Pasos para crear un histograma de residuos:
- En el cuadro de diálogo de regresión (Método 1), marca la casilla Residuals antes de hacer clic en Aceptar
- Después de ejecutar la regresión, desplázate hacia abajo pasando las tablas principales. Excel crea una tabla separada "RESIDUAL OUTPUT" con tres columnas: Observation, Predicted [nombre variable Y] y Residuals
- Selecciona solo los valores en la columna Residuals (no el encabezado, solo los valores numéricos)
- Ve a Insertar → Gráficos → Histograma. Alternativamente, usa Análisis de datos → Histograma para mayor control sobre los tamaños de los intervalos
- El histograma resultante debe mostrar la distribución de tus errores de predicción
Qué buscar:
- Supuesto cumplido: Distribución en forma de campana, simétrica y centrada en cero
- Violación: Fuertemente sesgada (cola larga a izquierda o derecha), bimodal (dos picos)
Nota: Con n mayor a 30, la regresión es robusta a violaciones moderadas de normalidad debido al Teorema del Límite Central.
Qué hacer si se viola:
- Busca valores atípicos (residuos inusuales mayor a 3 DE de la media)
- Intenta transformar la variable Y (logarítmica, raíz cuadrada)
- Usa métodos de bootstrapping (requiere R)
- Reporta como limitación si la transformación no ayuda
Supuesto 4: Homocedasticidad (varianza constante)
Qué significa: Los residuos deben tener varianza constante en todos los niveles de X (sin patrón de embudo). Para conocer más sobre este concepto, consulta qué es la homocedasticidad en estadística.
Cómo verificar en Excel:
Crea un diagrama de dispersión de residuos vs valores ajustados (predichos):
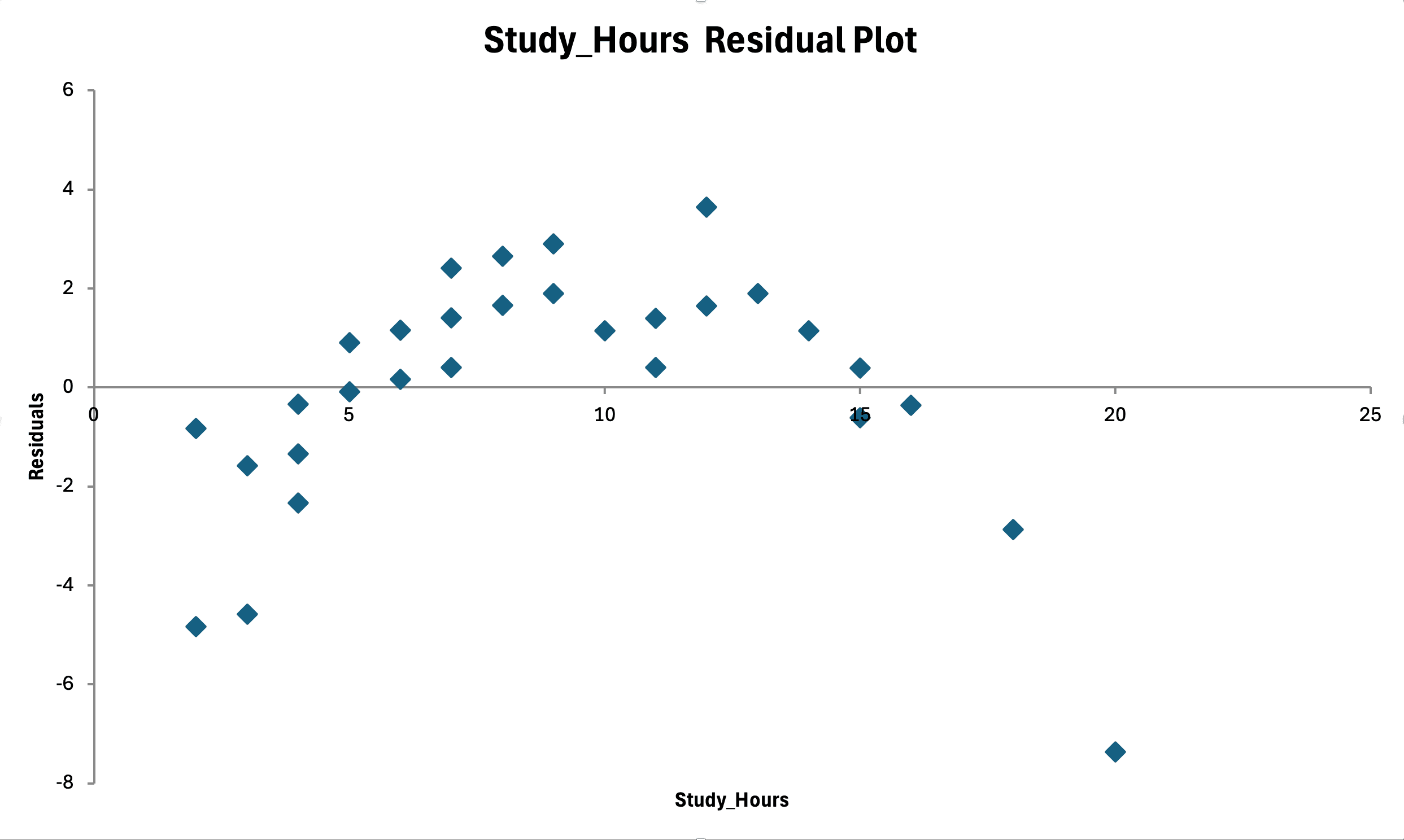
Figura 15: Verificación de homocedasticidad; residuos vs valores ajustados muestran dispersión aleatoria sin patrón de embudo (varianza constante)
Pasos para crear el gráfico de residuos:
- En los resultados de regresión, Excel proporciona "Fitted Values" (Y predicho) y "Residuals"
- Crea diagrama de dispersión: eje X = Valores ajustados, eje Y = Residuos
- Agrega una línea horizontal en Y = 0 como referencia
Qué buscar:
- Supuesto cumplido: Dispersión aleatoria alrededor de cero, dispersión aproximadamente constante en todo el rango de X
- Violación: Forma de embudo (la varianza aumenta a medida que X aumenta)
- Violación: Forma de cono (la varianza disminuye a medida que X aumenta)
Qué hacer si se viola:
- Transforma la variable Y (la transformación logarítmica frecuentemente ayuda)
- Usa regresión de mínimos cuadrados ponderados
- Usa errores estándar robustos (requiere software estadístico)
- Reporta la heterocedasticidad como limitación
Reportar la verificación de supuestos en tu tesis
En la sección de Métodos:
Previo al análisis de regresión, se examinaron diagramas de dispersión para verificar la linealidad entre las horas de estudio y las calificaciones. Se inspeccionaron gráficos de residuos e histogramas para verificar homocedasticidad y normalidad de residuos. Todos los supuestos se cumplieron, respaldando el uso de regresión lineal simple.
Si se violan los supuestos:
La inspección visual de gráficos de residuos reveló heterocedasticidad (patrón de embudo). Para abordar esta violación, se aplicó una transformación logarítmica a la variable dependiente, lo que mejoró la distribución de residuos. El análisis de regresión se realizó sobre las calificaciones transformadas logarítmicamente.
Cómo reportar regresión lineal simple en formato APA 7.ª edición
Tu comité de tesis espera que los resultados de regresión se reporten según las guías APA. Este es el formato completo para el Capítulo 4 (Resultados).
Plantilla para la sección de Resultados APA
Formato de párrafo:
Se realizó una regresión lineal simple para examinar si las horas de estudio semanales predecían las calificaciones del examen final. El supuesto de linealidad se cumplió, evaluado mediante inspección visual de un diagrama de dispersión. La inspección de gráficos de residuos indicó que los supuestos de normalidad y homocedasticidad se satisficieron.
El modelo de regresión predijo significativamente las calificaciones, F(1, 28) = 850.27, p < .001, R² = .97. Las horas de estudio explicaron el 96.8% de la varianza en las calificaciones. La ecuación de regresión fue: Calificación = 47.33 + 2.75(Horas de Estudio). Por cada hora adicional de estudio semanal, las calificaciones aumentaron en 2.75 puntos en promedio (IC 95% [2.56, 2.95]). El efecto de las horas de estudio sobre las calificaciones fue estadísticamente significativo, β = 2.75, t(28) = 29.16, p < .001.
Formato de tabla de regresión APA
| Variable | B | EE | β | t | p | IC 95% |
|---|---|---|---|---|---|---|
| Intercepto | 47.33 | 1.85 | - | 25.58 | < .001 | [43.54, 51.12] |
| Horas de Estudio | 2.75 | 0.09 | .98 | 29.16 | < .001 | [2.56, 2.95] |
Tabla 7: Regresión lineal simple prediciendo calificaciones a partir de horas de estudio
Nota. n = 30. R² = .97, F(1, 28) = 850.27, p < .001. B = coeficiente de regresión no estandarizado. EE = error estándar. β = coeficiente estandarizado. IC = intervalo de confianza.
Lista de verificación para el reporte
Al reportar regresión en tu tesis, incluye TODOS estos elementos:
En texto (párrafo de Resultados):
- Tipo de análisis ("Se realizó una regresión lineal simple...")
- Pregunta de investigación/hipótesis probada
- Declaración de verificación de supuestos
- Significancia general del modelo: F(gl_regresión, gl_residual) = valor F, valor p
- R² con interpretación ("explicó el X% de la varianza")
- Ecuación de regresión: Y = a + bX
- Interpretación del coeficiente con dirección y magnitud
- Significancia del coeficiente: β = valor, t(gl) = valor t, valor p
- Intervalo de confianza del 95% para el coeficiente
En tabla:
- Número de tabla y título en cursiva
- Coeficientes no estandarizados (B)
- Errores estándar (EE)
- Coeficientes estandarizados (β) si es relevante
- Estadísticos t y valores p
- Intervalos de confianza del 95%
- Nota de tabla con n, R², estadístico F
Errores comunes al hacer regresión en Excel
Evita estos errores frecuentes que comprometen la calidad de la investigación de tesis:
1. No verificar supuestos antes de la regresión
Error: Ejecutar regresión sin verificar linealidad, normalidad u homocedasticidad.
Por qué está mal: Los supuestos violados llevan a coeficientes sesgados y valores p incorrectos.
Cómo corregir: Siempre crea diagramas de dispersión y gráficos de residuos antes de finalizar los resultados. Reporta la verificación de supuestos en la sección de Métodos.
2. Confundir correlación con causalidad
Error: Concluir "Las horas de estudio causan calificaciones más altas" a partir de los resultados de regresión.
Por qué está mal: La regresión muestra predicción y asociación, no causalidad. La causalidad requiere diseño experimental con asignación aleatoria.
Cómo corregir: Usa lenguaje cuidadoso: "predijo," "se asoció con," "se relacionó con" en lugar de "causó," "llevó a," "resultó en."
3. Usar regresión para variables dependientes categóricas
Error: Ejecutar regresión lineal con un resultado binario (aprobado/reprobado, sí/no).
Por qué está mal: La regresión lineal asume una Y continua. Los resultados categóricos violan los supuestos y producen predicciones sin sentido (ej. probabilidad predicha de 1.3).
Cómo corregir: Usa regresión logística para resultados binarios (requiere SPSS/R). Excel no puede hacer esto.
4. Ignorar valores atípicos y puntos influyentes
Error: No verificar valores atípicos con residuos extremos que distorsionan la línea de regresión.
Por qué está mal: Un solo valor atípico puede cambiar drásticamente la pendiente y R², llevando a conclusiones engañosas.
Cómo corregir: Examina gráficos de residuos buscando valores mayores a 3 DE de la media. Investiga los valores atípicos: ¿son errores de captura de datos o casos extremos legítimos? Reporta cómo se manejaron los valores atípicos.
5. No reportar el tamaño del efecto (R²)
Error: Solo reportar "p menor a 0.05" sin R² o magnitud del coeficiente.
Por qué está mal: La significancia estadística no te dice si el efecto es lo suficientemente grande para importar prácticamente.
Cómo corregir: Siempre reporta R² como medida del tamaño del efecto, incluso si es pequeño. Discute la significancia práctica en el capítulo de Discusión.
6. Extrapolar fuera del rango de datos
Error: Usar la ecuación de regresión para predecir Y para valores de X fuera de tu rango observado.
Ejemplo: Tus datos tienen Horas de Estudio de 2-20, pero predices la calificación para 40 horas por semana.
Por qué está mal: La relación lineal podría no mantenerse fuera del rango observado (podría estabilizarse o invertirse).
Cómo corregir: Solo haz predicciones dentro del rango de tus datos. Reconoce la extrapolación como limitación si es inevitable.
7. Tratar las limitaciones de Excel como capacidades
Error: Pensar que Excel puede hacer todos los tipos de regresión (logística, jerárquica, stepwise).
Por qué está mal: Excel solo hace regresión lineal simple y múltiple. Intentar soluciones alternativas produce resultados no válidos.
Cómo corregir: Conoce las limitaciones de Excel (consulta la siguiente sección). Usa SPSS/R cuando lo requiera tu diseño de investigación.
Qué tipos de regresión Excel NO puede hacer
El Analysis ToolPak de Excel es excelente para regresión lineal simple y múltiple, pero no puede realizar muchas técnicas de regresión avanzadas requeridas para ciertos diseños de tesis. Entender estas limitaciones previene errores metodológicos y te ayuda a elegir el software correcto.
Tipos de regresión que requieren SPSS o R
| Tipo de regresión | Qué hace | Capacidad de Excel | Software alternativo |
|---|---|---|---|
| Regresión logística | Predice resultados binarios (sí/no, aprobado/reprobado, 0/1) | No | SPSS (Logística binaria), R (función glm) |
| Logística multinomial | Predice resultados categóricos (3+ categorías no ordenadas) | No | SPSS (Logística multinomial), R (multinom) |
| Regresión ordinal | Predice resultados categóricos ordenados (bajo/medio/alto) | No | SPSS (Regresión ordinal), R (polr) |
| Regresión stepwise | Selecciona predictores automáticamente según criterios | No | SPSS (Regresión lineal con Stepwise), R (función step) |
| Regresión jerárquica | Agrega predictores en bloques según la teoría | No (solución manual posible) | SPSS (bloques jerárquicos), R (comparación manual) |
| Análisis de moderación | Prueba si el efecto de X sobre Y depende del moderador M | No fácilmente | SPSS con macro PROCESS, R (interacciones) |
| Análisis de mediación | Prueba si X afecta a Y a través del mediador M | No | SPSS con macro PROCESS, R (lavaan, mediation) |
| Regresión polinomial | Ajusta curvas cuadráticas, cúbicas (términos X², X³) | Sí (agregar columna X² manualmente) | SPSS, R (sintaxis más fácil) |
| Regresión lineal simple | Predice Y a partir de un X continuo | Sí perfectamente | SPSS, R (también disponible) |
| Regresión lineal múltiple | Predice Y a partir de 2+ predictores continuos | Sí perfectamente | SPSS, R (también disponible) |
Tabla 8: Capacidades de regresión de Excel vs requisitos de software estadístico
Diagnósticos avanzados que Excel no puede proporcionar
Aunque Excel proporciona resultados básicos de regresión, carece de herramientas de diagnóstico avanzadas:
Lo que Excel NO puede calcular:
- VIF (Factor de inflación de la varianza): Detecta multicolinealidad en regresión múltiple
- Estadístico de Durbin-Watson: Prueba autocorrelación en series de tiempo
- Distancia de Cook: Identifica valores atípicos influyentes
- DFBETAS: Mide la influencia en coeficientes individuales
- Valores de leverage: Identifica puntos de alto apalancamiento
- Residuos estandarizados: Detección de valores atípicos más fácil que con residuos crudos
Cómo solucionar:
- Para regresión simple, la multicolinealidad no es un problema (solo un predictor)
- Calcula residuos estandarizados manualmente: (Residuo / Error estándar)
- Usa SPSS/R si tu asesor requiere diagnósticos avanzados
Cuándo usar Excel vs software estadístico
Usa Excel cuando:
- Tienes solo regresión lineal simple o múltiple
- Tu variable dependiente es continua (escala de intervalo/razón)
- No necesitas regresión stepwise o jerárquica
- Los diagnósticos básicos (gráficos de residuos) son suficientes
- Tu comité acepta los resultados de Excel
- Quieres aprender los fundamentos de regresión antes de SPSS/R
Usa SPSS/R cuando:
- Necesitas regresión logística, ordinal o multinomial
- Tu comité requiere VIF, Durbin-Watson o Distancia de Cook
- Estás probando hipótesis de moderación o mediación
- Necesitas selección stepwise de variables
- Tienes diseños de encuestas complejos con ponderaciones
- Publicas en revistas que requieren resultados de SPSS/R
Conclusión clave: Excel es perfecto para regresión lineal con resultados continuos. Para cualquier cosa más allá, invierte tiempo en aprender SPSS o R. La mayoría de los comités de tesis son flexibles con la elección de software para regresión simple, pero consulta con tu asesor. Si necesitas usar SPSS, consulta nuestra guía sobre cómo calcular la regresión lineal en SPSS.
Preguntas frecuentes
Próximos Pasos
Ahora tienes un marco completo para realizar regresión lineal simple en Excel, desde la preparación de datos hasta la verificación de supuestos y el reporte en formato APA. La clave del éxito en tu tesis no es solo ejecutar el análisis, sino entender cuándo usarlo, cómo interpretar los resultados correctamente y cómo comunicar los hallazgos de manera clara a tu comité.
Si necesitas analizar múltiples predictores simultáneamente, consulta cómo hacer regresión lineal múltiple en Excel. Para reportar tus estadísticas descriptivas en el formato correcto antes de la regresión, revisa cómo reportar estadísticas descriptivas en formato APA en Excel.
Referencias
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). https://doi.org/10.1037/0000165-000
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
Green, S. B. (1991). How many subjects does it take to do a regression analysis? Multivariate Behavioral Research, 26(3), 499–510. https://doi.org/10.1207/s15327906mbr2603_7