ผมได้ดูงานวิทยานิพนธ์และข้อมูลของนักศึกษามาหลายร้อยชุดตลอดหลายปีที่ผ่านมา และพบว่ามีข้อผิดพลาดที่เกิดซ้ำๆ เสมอ นักศึกษาใช้เวลาหลายสัปดาห์เก็บข้อมูลจากแบบสอบถาม แต่กลับทำให้ผลลัพธ์เสียหายเพราะข้อผิดพลาดใน Excel ที่สามารถหลีกเลี่ยงได้
ข้อผิดพลาดเหล่านี้เกิดขึ้นใน 4 ขั้นตอนสำคัญ: การตั้งค่าก่อนวิเคราะห์ การทำความสะอาดข้อมูล การวิเคราะห์ทางสถิติ และการนำเสนอผลลัพธ์ ข้อผิดพลาดเพียงข้อเดียวในขั้นตอนใดก็ตามอาจทำให้การวิเคราะห์ทั้งหมดของคุณไม่ถูกต้องได้
คู่มือนี้จะแสดงให้คุณเห็น 10 ข้อผิดพลาดที่พบบ่อยที่สุดที่นักศึกษามักทำเมื่อวิเคราะห์ข้อมูลแบบสอบถามใน Excel และวิธีแก้ไขก่อนที่คุณจะส่งวิทยานิพนธ์
ข้อผิดพลาดในการตั้งค่าก่อนวิเคราะห์
ข้อผิดพลาดเหล่านี้เกิดขึ้นก่อนที่คุณจะทำ statistical test เลย การจับได้ตั้งแต่เริ่มต้นจะช่วยประหยัดเวลาหลายชั่วโมงในการทำใหม่
ข้อผิดพลาด #1: ไม่ติดตั้ง Analysis ToolPak ตั้งแต่แรก
ปัญหา:
คุณเปิด Excel พร้อมที่จะทำ t-test หรือ ANOVA แต่กลับพบว่าไม่มีตัวเลือกการวิเคราะห์ทางสถิติในแท็บ Data คุณค้นหาทุกเมนูแต่ก็ไม่เจออะไรเลย
Excel ไม่ได้มี statistical test ติดมาตั้งแต่แรก ต้องติดตั้ง add-in ที่ชื่อ Analysis ToolPak ด้วยตัวเอง
วิธีแก้ไข:
สำหรับคำแนะนำการติดตั้งแบบละเอียด (Windows และ Mac) ดูคู่มือของเรา: วิธีเปิดใช้งาน Data Analysis ใน Excel
ขั้นตอนแบบรวดเร็วสำหรับ Windows:
- คลิก File ที่มุมซ้ายบน
- เลือก Options ที่ด้านล่างของเมนู
- คลิก Add-ins ที่แถบด้านซ้าย
- ที่ด้านล่าง หา dropdown "Manage:" เลือก Excel Add-ins แล้วคลิก Go
- ติ๊กช่องข้างๆ Analysis ToolPak
- คลิก OK
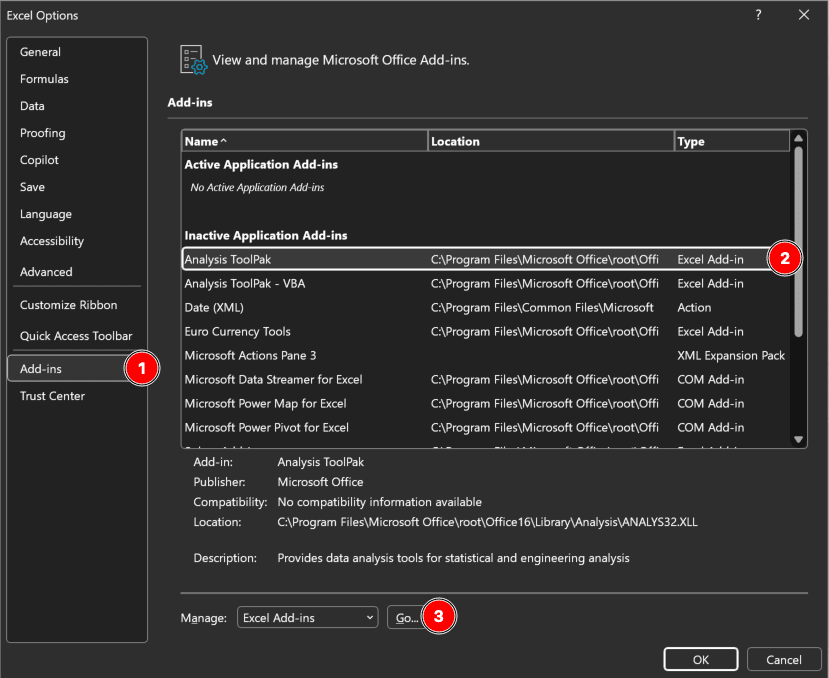 รูปที่ 1: หน้าต่าง Add-ins ของ Excel พร้อม Analysis ToolPak ที่เปิดใช้งาน (Windows)
รูปที่ 1: หน้าต่าง Add-ins ของ Excel พร้อม Analysis ToolPak ที่เปิดใช้งาน (Windows)
ผู้ใช้ Mac: ไปที่ Tools → Excel Add-ins แทนที่จะเป็น File → Options
หลังจากติดตั้งแล้ว ปุ่ม Data Analysis จะปรากฏในแท็บ Data (ทางขวาสุด) ปุ่มนี้จะให้คุณเข้าถึง t-test, ANOVA, regression, correlation และ descriptive statistics
การป้องกัน:
ติดตั้ง Analysis ToolPak ตั้งแต่ครั้งแรกที่คุณเปิด Excel สำหรับวิทยานิพนธ์ เพิ่มมันลงใน checklist การตั้งค่าการวิจัยของคุณก่อนเก็บข้อมูลใดๆ
ข้อผิดพลาด #2: ใส่ข้อความปนกับตัวเลขในคอลัมน์คำตอบ
ปัญหา:
คำตอบจากแบบสอบถามของคุณมีข้อความอย่าง "เห็นด้วยอย่างยิ่ง" "เห็นด้วย" "เฉยๆ" "ไม่เห็นด้วย" และ "ไม่เห็นด้วยอย่างยิ่ง" เมื่อคุณพยายามคำนวณค่าเฉลี่ยความพึงพอใจ Excel ก็ขึ้น error หรือได้ศูนย์
ข้อความใช้ในสูตรทางสถิติไม่ได้ ฟังก์ชัน Excel เช่น AVERAGE, STDEV และ CORREL ต้องการข้อมูลเป็นตัวเลข
วิธีแก้ไข:
เปลี่ยนคำตอบทั้งหมดเป็นตัวเลขก่อนวิเคราะห์ สร้างตารางอธิบายใน sheet แยก:
| รหัสตัวเลข | คำอธิบาย |
|---|---|
| 1 | ไม่เห็นด้วยอย่างยิ่ง |
| 2 | ไม่เห็นด้วย |
| 3 | เฉยๆ |
| 4 | เห็นด้วย |
| 5 | เห็นด้วยอย่างยิ่ง |
ตารางที่ 1: การเข้ารหัสตัวเลขสำหรับคำตอบแบบ Likert scale 5 ระดับ
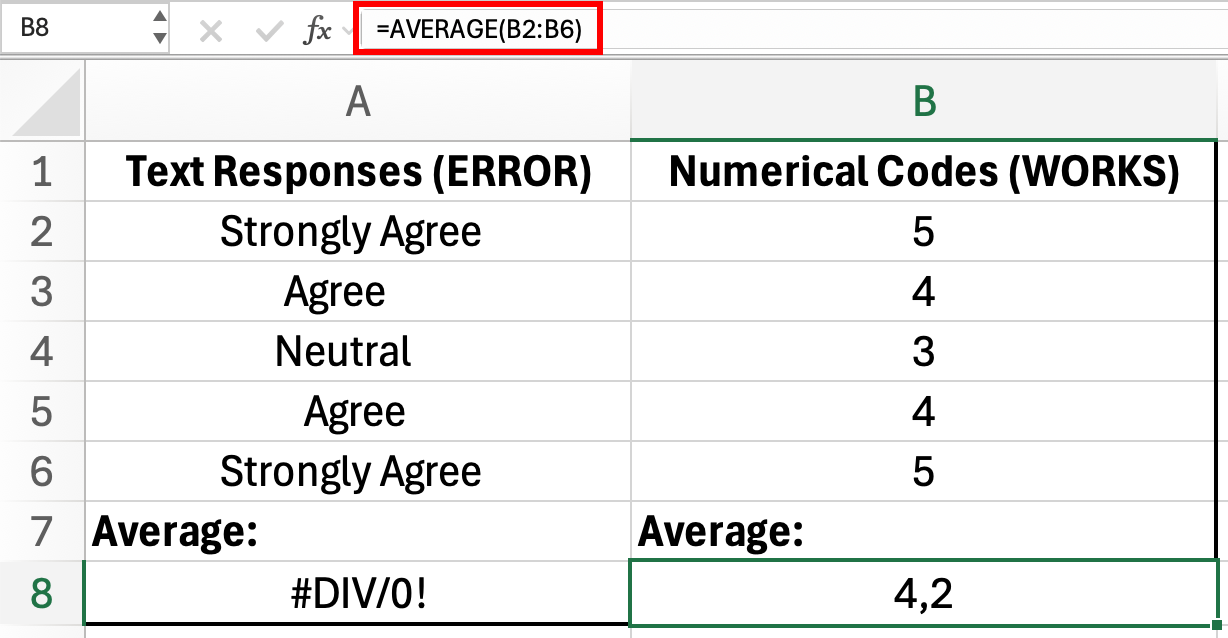 รูปที่ 2: คำตอบที่เป็นข้อความใช้ในสูตร AVERAGE ไม่ได้ (error ใน A8) แต่รหัสตัวเลขคำนวณได้ถูกต้อง (4.2 ใน B8)
รูปที่ 2: คำตอบที่เป็นข้อความใช้ในสูตร AVERAGE ไม่ได้ (error ใน A8) แต่รหัสตัวเลขคำนวณได้ถูกต้อง (4.2 ใน B8)
เมื่อ export จากเครื่องมือทำแบบสอบถาม (Google Forms, Qualtrics, SurveyMonkey) เลือกตัวเลือก numerical values แทนที่จะเป็นป้ายกำกับข้อความ
ถ้าคุณมีคำตอบเป็นข้อความอยู่แล้ว:
- สร้างคอลัมน์ใหม่
- ใช้ =IF หรือ =VLOOKUP เพื่อแปลงข้อความเป็นตัวเลข
- ลบคอลัมน์ข้อความเดิมหลังจากตรวจสอบแล้ว
การป้องกัน:
ตั้งค่าการ export แบบสอบถามให้ส่งออกรหัสตัวเลขตั้งแต่แรก แพลตฟอร์มส่วนใหญ่มีตัวเลือก "Export as numerical values (1-n)"
ข้อผิดพลาด #3: การป้อนข้อมูลที่ไม่สอดคล้องกัน
ปัญหา:
คุณป้อนคำตอบจากแบบสอบถามด้วยตัวเองและใช้รูปแบบที่ไม่สอดคล้องกัน ผู้ตอบบางคนถูกเข้ารหัสเป็น "ชาย" บางคนเป็น "ช" และบางคนเป็น "ผู้ชาย" เมื่อคุณสร้าง Pivot Table เพื่อสรุปคำตอบตามเพศ Excel ก็แสดง 3 หมวดหมู่แยกกันแทนที่จะเป็นหมวดเดียว
ปัญหานี้ยังเกิดกับการสะกดที่แตกต่างกัน: "เห็นด้วยอย่างยิ่ง" กับ "เห็นด้วยอย่างยิ่ง " (มีช่องว่างเกิน) แต่ละรูปแบบจะกลายเป็นหมวดแยกในการวิเคราะห์ของคุณ
หมายเหตุ: Pivot Tables และ COUNTIF ไม่คำนึงถึงตัวพิมพ์ใหญ่-เล็ก ดังนั้น "ช" และ "ช" จะนับรวมกัน อย่างไรก็ตาม การสะกดที่แตกต่างกันเช่น "ชาย" "ช" และ "ผู้ชาย" จะถูกนับแยกกันเสมอ
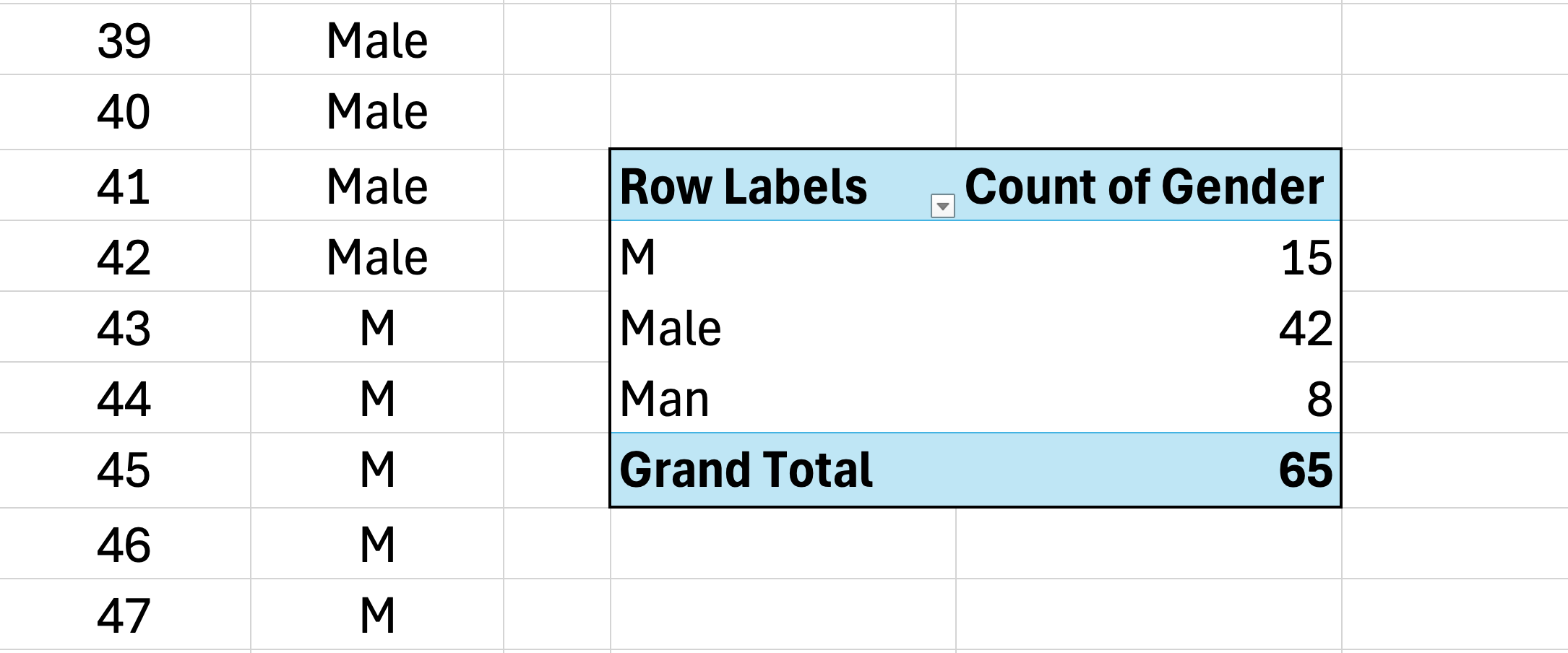 รูปที่ 3: Pivot Table ถือว่า "ชาย" "ช" และ "ผู้ชาย" เป็น 3 หมวดแยกกันเพราะการป้อนข้อมูลที่ไม่สอดคล้องกัน
รูปที่ 3: Pivot Table ถือว่า "ชาย" "ช" และ "ผู้ชาย" เป็น 3 หมวดแยกกันเพราะการป้อนข้อมูลที่ไม่สอดคล้องกัน
ตอนนี้ความถี่ของคุณถูกแบ่งไปหลายแถว ทำให้ไม่สามารถรายงานผลรวมที่ถูกต้องได้โดยไม่ต้องรวมด้วยตัวเอง
วิธีแก้ไข:
ใช้ Data Validation เพื่อจำกัดการป้อนข้อมูลก่อนเก็บข้อมูล:
- เลือกคอลัมน์ที่จะป้อนคำตอบ
- ไปที่แท็บ Data
- คลิก Data Validation
- ที่ "Allow:" เลือก List
- ใน "Source:" พิมพ์ค่าที่อนุญาต:
ชาย,หญิง,อื่นๆ(คั่นด้วยจุลภาค) - คลิก OK
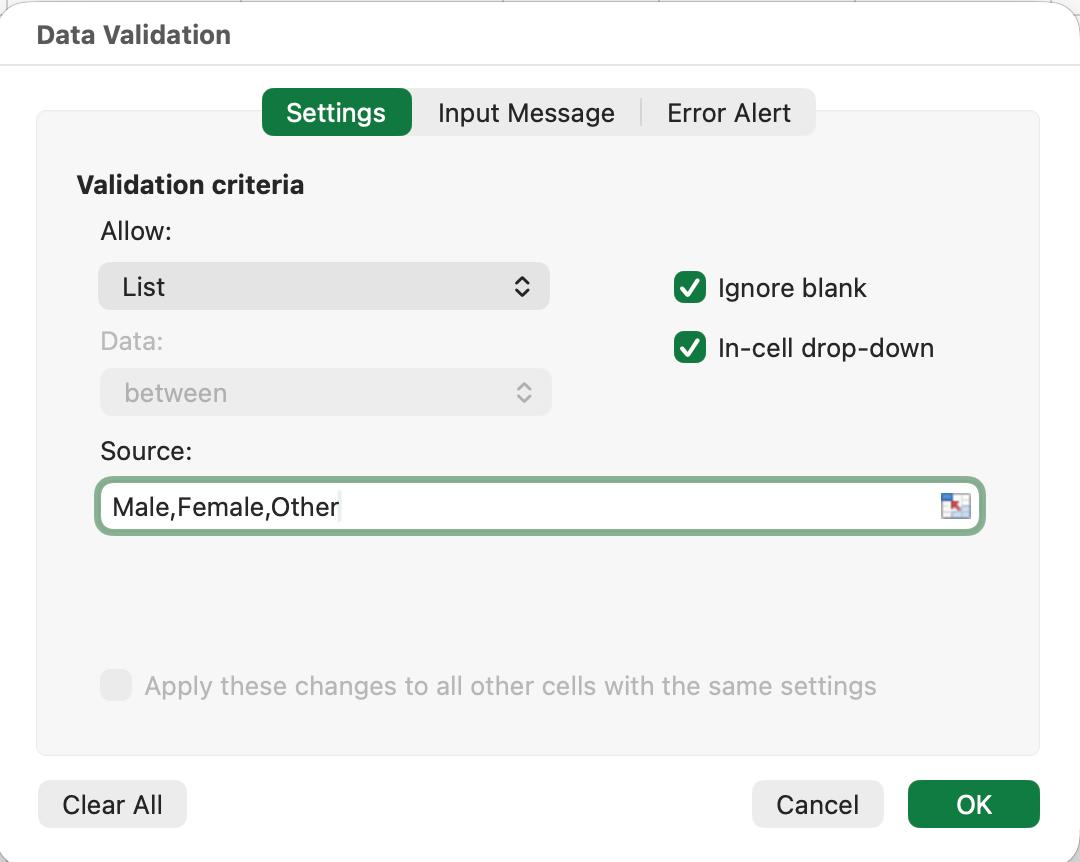 รูปที่ 4: การตั้งค่า Data Validation เพื่อจำกัดการป้อนข้อมูลให้เป็นค่าจากรายการที่กำหนดไว้
รูปที่ 4: การตั้งค่า Data Validation เพื่อจำกัดการป้อนข้อมูลให้เป็นค่าจากรายการที่กำหนดไว้
ตอนนี้ผู้ใช้สามารถเลือกจาก dropdown list เท่านั้น การพิมพ์ถูกปิดใช้งาน ช่วยขจัดความไม่สอดคล้องกัน
ถ้าข้อมูลถูกป้อนไปแล้วแบบไม่สอดคล้องกัน:
- ใช้ Find & Replace (Ctrl+H) เพื่อทำให้เป็นมาตรฐาน
- Find "ช" → Replace with "ชาย" (โดยติ๊ก "Match entire cell contents")
- Find "ผู้ชาย" → Replace with "ชาย"
- ทำซ้ำกับรูปแบบอื่นๆ ทั้งหมด
การป้องกัน:
ตั้งค่า Data Validation ก่อนเก็บข้อมูลใดๆ สำหรับแบบสอบถามออนไลน์ สิ่งนี้เกิดขึ้นโดยอัตโนมัติผ่านแพลตฟอร์มแบบสอบถามของคุณ
ข้อผิดพลาดในการทำความสะอาดข้อมูล
ข้อมูลดิบจากแบบสอบถามไม่ค่อยพร้อมสำหรับการวิเคราะห์ ข้อผิดพลาดเหล่านี้เกิดขึ้นเมื่อนักศึกษาข้ามขั้นตอนการทำความสะอาด
ข้อผิดพลาด #4: ไม่สนใจข้อมูลที่หาย
ปัญหา:
ผู้ตอบบางคนข้ามคำถาม ทำให้มีเซลล์ว่างในชุดข้อมูลของคุณ คุณใช้ AVERAGE กับคอลัมน์หนึ่งและได้ 4.2 อาจารย์ที่ปรึกษาถาม: "คุณจัดการกับข้อมูลที่หายอย่างไร" คุณถึงตระหนักว่าไม่เคยบันทึกวิธีการของคุณเลย
ฟังก์ชัน AVERAGE ของ Excel จะตัดเซลล์ว่างออกโดยอัตโนมัติทั้งจากผลรวมและการนับ พฤติกรรมนี้อาจตรงหรือไม่ตรงกับวิธีการที่คุณตั้งใจไว้:
- สิ่งที่ Excel ทำ: (ผลรวมของ 80 ค่าที่ไม่ว่าง) / 80 = 4.2
- วิธีทางเลือก: ถือว่าข้อมูลที่หายเป็นศูนย์: (ผลรวมของ 80 ค่า) / 100 = 3.36
- อีกวิธีหนึ่ง: ใส่ค่า median: (ผลรวมของ 80 ค่า + 20 × median) / 100
ปัญหาไม่ได้อยู่ที่ว่า Excel "ผิด" - แต่คือคุณได้ตัดสินใจทางวิธีการโดยไม่รู้ตัว ถ้าคุณไม่บันทึกว่าจัดการกับข้อมูลที่หายอย่างไร ผู้ประเมินจะตั้งคำถามกับผลลัพธ์ของคุณ
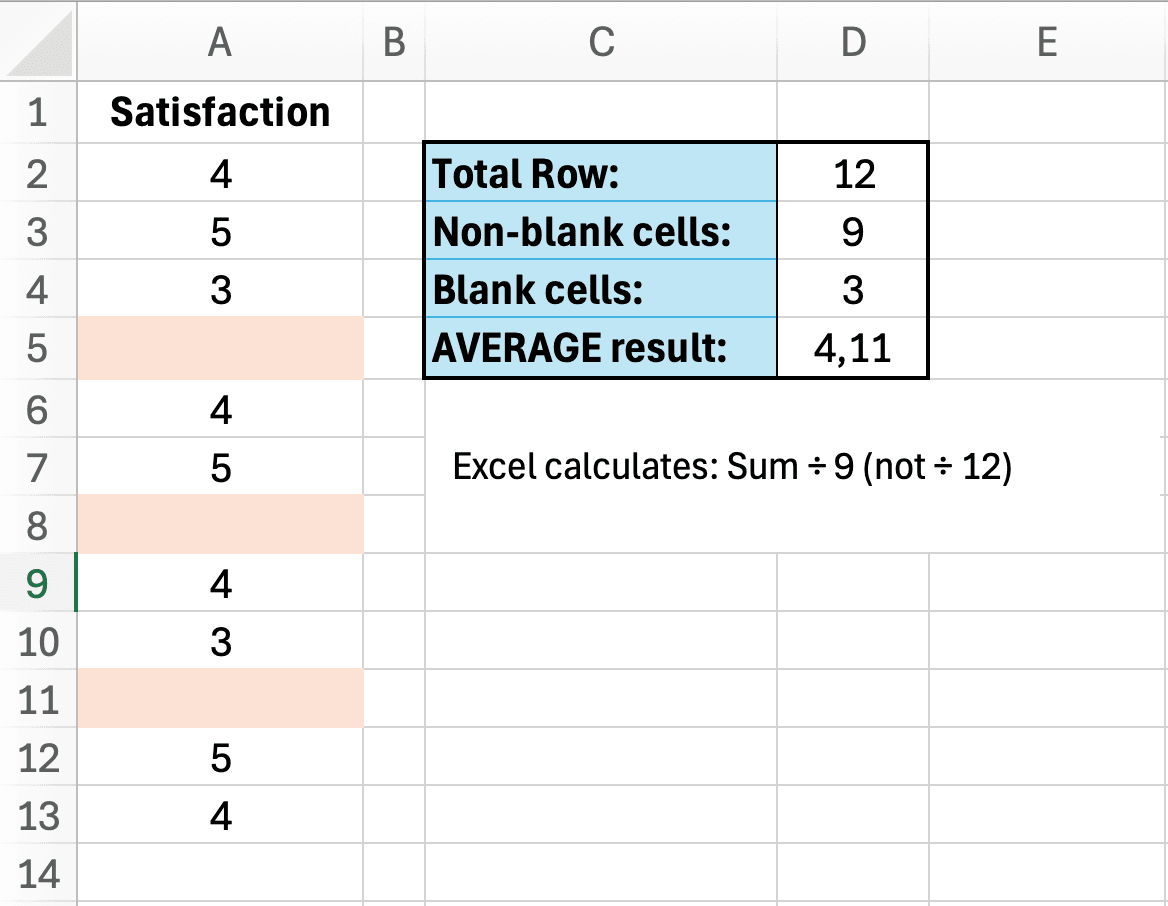 รูปที่ 5: ฟังก์ชัน AVERAGE ของ Excel ตัดเซลล์ว่างออก ซึ่งอาจตรงหรือไม่ตรงกับวิธีการที่คุณตั้งใจไว้
รูปที่ 5: ฟังก์ชัน AVERAGE ของ Excel ตัดเซลล์ว่างออก ซึ่งอาจตรงหรือไม่ตรงกับวิธีการที่คุณตั้งใจไว้
วิธีแก้ไข:
ก่อนอื่น ระบุว่ามีข้อมูลหายเท่าไหร่:
=COUNTA(B2:B101) // นับเซลล์ที่ไม่ว่าง
=ROWS(B2:B101) // จำนวนแถวทั้งหมด (ควรเป็น 100)
=ROWS(B2:B101)-COUNTA(B2:B101) // จำนวนข้อมูลที่หายจากนั้น เลือกกลยุทธ์:
กลยุทธ์ 1: ลบทั้งแถว (ถ้าข้อมูลหายแบบสุ่มสมบูรณ์)
- เลือกแถวที่มีค่าหาย
- คลิกขวา → Delete
- อัปเดตขนาดตัวอย่าง (n=80 แทน n=100)
กลยุทธ์ 2: แทนที่ด้วย median (สำหรับข้อมูลตัวเลข)
- คำนวณ median: =MEDIAN(B2:B101)
- กรอกเซลล์ว่างด้วยค่านี้
- บันทึกในวิธีการ: "ค่าที่หายถูกแทนที่ด้วย median"
กลยุทธ์ 3: เข้ารหัสเป็น "หาย" (สำหรับข้อมูลเชิงหมวดหมู่)
- แทนที่ช่องว่างด้วย 99 หรือ "หาย"
- ตัดออกจากการคำนวณทางสถิติ
- รายงานแยก: "85 คำตอบที่ถูกต้อง 15 หาย"
การป้องกัน:
ทำให้คำถามในแบบสอบถามทั้งหมดเป็น required (เว้นแต่ไม่เหมาะสมทางจริยธรรม) ถ้าข้อมูลที่หายหลีกเลี่ยงไม่ได้ วางแผนกลยุทธ์การจัดการก่อนวิเคราะห์
หมายเหตุสำคัญสำหรับวิทยานิพนธ์ของคุณ:
บันทึกกลยุทธ์ข้อมูลที่หายของคุณในส่วนวิธีการ เขียน: "ค่าที่หาย (n=15, 15%) ถูก[ลบ/แทนที่ด้วย median/เข้ารหัสแยก] เพราะ[เหตุผล]"
ผู้ประเมินจะตั้งคำถามกับการจัดการข้อมูลที่หายที่ไม่ได้บันทึก
ข้อผิดพลาด #5: ไม่เช็คคำตอบที่ซ้ำ
ปัญหา:
ผู้ตอบคนหนึ่งส่งแบบสอบถามของคุณโดยไม่ตั้งใจ 2 ครั้ง อีกคนใช้อีเมลคนละตัว ขนาดตัวอย่างของคุณถูกขยายเกินจริง และบางคำตอบถูกนับ 2 รอบในการวิเคราะห์
วิธีแก้ไข:
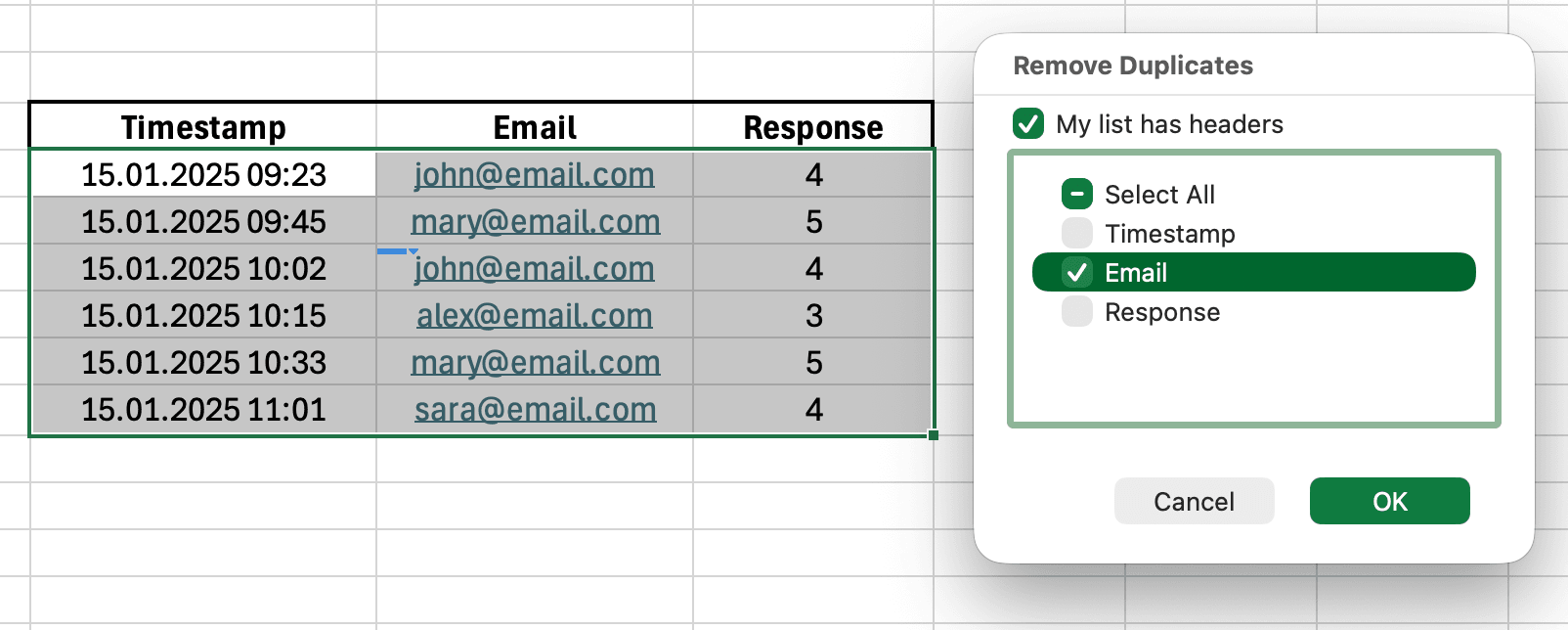 รูปที่ 6: หน้าต่าง Remove Duplicates โดยเลือก Email เพื่อหาการส่งแบบสอบถามที่ซ้ำ
รูปที่ 6: หน้าต่าง Remove Duplicates โดยเลือก Email เพื่อหาการส่งแบบสอบถามที่ซ้ำ
- เลือกชุดข้อมูลทั้งหมดของคุณ (Ctrl+A)
- ไปที่แท็บ Data
- คลิกปุ่ม Remove Duplicates
- เลือกคอลัมน์ที่จะเช็ค (มักเป็น Timestamp หรือ Email)
- คลิก OK
Excel จะแสดงว่าพบและลบข้อมูลซ้ำกี่รายการ อัปเดตขนาดตัวอย่างตามนั้น
สำหรับแบบสอบถามออนไลน์ ตรวจสอบการตั้งค่าแพลตฟอร์มของคุณ:
- Google Forms: จำกัดเป็น 1 คำตอบต่ออีเมล
- Qualtrics: เปิด "Prevent Ballot Box Stuffing"
- SurveyMonkey: ต้องการอีเมลผู้ตอบ
การป้องกัน:
เปิดการป้องกันข้อมูลซ้ำในการตั้งค่าแบบสอบถามของคุณ สำหรับแบบสอบถามกระดาษ กำหนด ID ที่ไม่ซ้ำกันให้แต่ละผู้ตอบ และเช็ค ID ซ้ำก่อนวิเคราะห์
คำนวณขนาดตัวอย่างของคุณ
ใช้เครื่องคำนวณฟรีของเราเพื่อกำหนดขนาดตัวอย่างที่ต้องการ โดยใช้ Yamane, Cochran และ Krejcie & Morgan เปรียบเทียบทั้งสามวิธีพร้อมการอ้างอิง APA
ลองใช้เครื่องคำนวณข้อผิดพลาดในการวิเคราะห์ทางสถิติ
ข้อผิดพลาดเหล่านี้เกิดขึ้นระหว่างการวิเคราะห์จริงๆ และมักนำไปสู่ข้อสรุปที่ไม่ถูกต้อง
ข้อผิดพลาด #6: ใช้ Statistical Test ผิด
ปัญหา:
คุณต้องการเปรียบเทียบคะแนนความพึงพอใจระหว่าง 3 แผนก (การตลาด ฝ่ายขาย ฝ่ายปฏิบัติการ) คุณทำ t-test แยก 3 รอบ:
- การตลาด vs ฝ่ายขาย (p=0.04)
- การตลาด vs ฝ่ายปฏิบัติการ (p=0.06)
- ฝ่ายขาย vs ฝ่ายปฏิบัติการ (p=0.03)
วิธีนี้ผิด การทำ t-test หลายครั้งเพิ่มอัตรา Type I error (false positive) ด้วยการเปรียบเทียบ 3 ครั้ง อัตรา error จริงของคุณไม่ใช่ 5% แต่ประมาณ 14%
วิธีแก้ไข:
ใช้ test ที่เหมาะสมกับคำถามวิจัยของคุณ:
| คำถามวิจัย | จำนวนกลุ่ม | Test ที่ถูกต้อง |
|---|---|---|
| เปรียบเทียบ 2 กลุ่ม | 2 | Independent t-test |
| เปรียบเทียบ 3 กลุ่มขึ้นไป | 3+ | One-Way ANOVA |
| ทดสอบกลุ่มเดียวกัน 2 ครั้ง | 2 (คู่) | Paired t-test |
| ความสัมพันธ์ระหว่างตัวแปร | 2 (ต่อเนื่อง) | Pearson correlation |
| เปรียบเทียบข้อมูลเชิงหมวดหมู่ | 2+ (เชิงหมวดหมู่) | Chi-square test |
ตารางที่ 2: คู่มือการเลือก statistical test สำหรับคำถามวิจัยทั่วไป
สำหรับตัวอย่าง 3 แผนก วิธีที่ถูกต้องคือ:
- ทำ one-way ANOVA เพื่อทดสอบว่ากลุ่มใดแตกต่างกัน
- ถ้ามีนัยสำคัญ (p < 0.05) ทำ post-hoc test เพื่อระบุว่าคู่ไหนเฉพาะแตกต่างกัน
- รายงาน: "One-way ANOVA พบความแตกต่างที่มีนัยสำคัญ F(2,297)=4.82, p=0.009"
การป้องกัน:
ก่อนเก็บข้อมูล ระบุ statistical test ของคุณ ดูคู่มือตัดสินใจ T-Test vs ANOVA ของเราสำหรับ flowchart แบบสมบูรณ์
ข้อผิดพลาด #7: คำนวณ Cronbach's Alpha โดยไม่กลับคะแนนข้อที่ถามในทางตรงกันข้าม
ปัญหา:
คุณคำนวณ Cronbach's alpha สำหรับแบบวัดความเชื่อมั่นในตนเอง 5 ข้อ และได้ α=0.45 (ความเชื่อมั่นต่ำ) คุณตรวจสอบการป้อนข้อมูลและสูตรอีกครั้ง ทุกอย่างดูถูกต้อง
ปัญหา: แบบวัดของคุณมีข้อที่ถามในทางตรงกันข้ามที่ไม่ได้ถูกกลับคะแนน
ตัวอย่างแบบวัด:
- "ฉันมั่นใจในความสามารถของตัวเอง" (บวก)
- "ฉันสามารถรับมือกับความท้าทายส่วนใหญ่ได้" (บวก)
- "ฉันมักสงสัยในทักษะของตัวเอง" (ลบ - ต้องกลับ)
- "ฉันสามารถเรียนรู้สิ่งใหม่ได้" (บวก)
- "ฉันไม่เชื่อในตัวเอง" (ลบ - ต้องกลับ)
เมื่อผู้ตอบเห็นด้วยอย่างยิ่งกับข้อ 3 (คะแนน=5) พวกเขาจริงๆ แล้วมีความเชื่อมั่นในตนเองต่ำ สิ่งนี้ต้องถูกกลับเป็น 1 ก่อนคำนวณ alpha
วิธีแก้ไข:
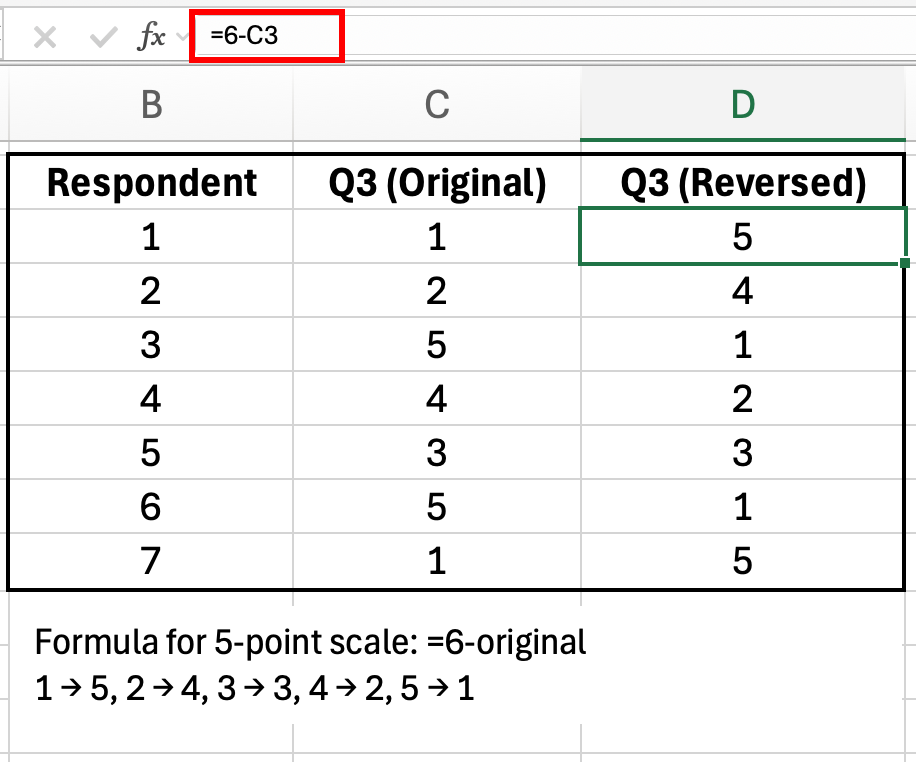 รูปที่ 7: สูตรกลับคะแนนสำหรับ scale 5 ระดับ: =6-ค่าเดิม
รูปที่ 7: สูตรกลับคะแนนสำหรับ scale 5 ระดับ: =6-ค่าเดิม
สำหรับ scale 5 ระดับ (1-5) ใช้สูตรนี้:
=6-B2สำหรับ scale 7 ระดับ (1-7):
=8-B2สูตรทั่วไป:
=(ค่า_MAX + ค่า_MIN) - ค่าเดิมหลังจากกลับคะแนนข้อที่ถามในทางตรงกันข้ามแล้ว คำนวณ Cronbach's alpha ใหม่ ความเชื่อมั่นของคุณอาจจะเพิ่มจาก 0.45 เป็น 0.80+
การป้องกัน:
เมื่อออกแบบแบบสอบถาม ทำเครื่องหมายว่าข้อไหนต้องกลับคะแนน ก่อนคำนวณสถิติความเชื่อมั่นใดๆ สร้างส่วน "ข้อที่กลับคะแนน" ในไฟล์ Excel ของคุณ และใช้สูตร
ดูคู่มือของเราเกี่ยวกับการแปลผล Cronbach's alpha สำหรับการแก้ไขปัญหาความเชื่อมั่นอื่นๆ
ข้อผิดพลาด #8: สูตรผิดสำหรับเปอร์เซ็นต์
ปัญหา:
คุณรายงาน: "50 คนเห็นด้วยกับข้อความ"
ผู้ประเมินวิทยานิพนธ์ของคุณถาม: "50 จากกี่คน? เปอร์เซ็นต์เท่าไหร่?"
คุณคำนวณเปอร์เซ็นต์ด้วยตัวเองและสับสน เปอร์เซ็นต์ของคุณรวมกันได้ 94% หรือ 107% แทนที่จะเป็น 100% ข้อผิดพลาดทั่วไป ได้แก่:
- ใช้ตัวหารผิด: หารด้วยจำนวนแถวทั้งหมด (รวม header หรือแถวว่าง) แทนที่จะเป็นคำตอบที่ถูกต้อง
- ใช้สูตรปนกัน: ใช้ COUNTA กับบางแถวและ COUNT กับแถวอื่น
- ลืมตัดข้อมูลที่หายออก: นับเซลล์ว่างในจำนวนทั้งหมด
 รูปที่ 8: ซ้ายแสดงเปอร์เซ็นต์ผิด (รวม 94% เพราะตัวหารผิด); ขวาแสดงการคำนวณที่ถูกต้อง (รวม 100%)
รูปที่ 8: ซ้ายแสดงเปอร์เซ็นต์ผิด (รวม 94% เพราะตัวหารผิด); ขวาแสดงการคำนวณที่ถูกต้อง (รวม 100%)
วิธีแก้ไข:
รายงานทั้งจำนวนและเปอร์เซ็นต์เสมอ โดยใช้สูตรที่สอดคล้องกัน:
// นับกี่คนที่พูดว่า "เห็นด้วย" (เข้ารหัสเป็น 4)
=COUNTIF(B2:B101, 4)
// จำนวนผู้ตอบทั้งหมด
=COUNTA(B2:B101)
// เปอร์เซ็นต์
=COUNTIF(B2:B101, 4) / COUNTA(B2:B101) * 100ตัวอย่างตารางความถี่พร้อมเปอร์เซ็นต์:
รูปแบบสูตรสำหรับแต่ละแถวคือ:
=COUNTIF(B:B, [ค่าคำตอบ]) / COUNTA(B:B) * 100โดยที่ [ค่าคำตอบ] คือ 1 สำหรับ "ไม่เห็นด้วยอย่างยิ่ง", 2 สำหรับ "ไม่เห็นด้วย" ฯลฯ
| คำตอบ | จำนวน | เปอร์เซ็นต์ |
|---|---|---|
| ไม่เห็นด้วยอย่างยิ่ง | 5 | 5.0% |
| ไม่เห็นด้วย | 12 | 12.0% |
| เฉยๆ | 23 | 23.0% |
| เห็นด้วย | 42 | 42.0% |
| เห็นด้วยอย่างยิ่ง | 18 | 18.0% |
| รวม | 100 | 100.0% |
ตารางที่ 3: ตารางความถี่ที่แสดงการกระจายคำตอบ (เปอร์เซ็นต์ต้องรวมเป็น 100%)
การตรวจสอบ:
รวมเปอร์เซ็นต์ทั้งหมด ต้องเท่ากับ 100% (ยอมรับ error การปัดเศษ 0.1%) ถ้าผลรวมของคุณเป็น 98% หรือ 103% คุณมี error ในสูตร
การป้องกัน:
สร้างเทมเพลตด้วยสูตรเปอร์เซ็นต์ที่สร้างไว้ล่วงหน้า ใช้เทมเพลตนี้ซ้ำสำหรับคำถามทั้งหมดในแบบสอบถาม
ข้อผิดพลาดในการนำเสนอผลลัพธ์
การวิเคราะห์ของคุณอาจถูกต้อง แต่การนำเสนอที่ไม่ดีทำลายความน่าเชื่อถือ
ข้อผิดพลาด #9: รายงานทศนิยมมากเกินไป
ปัญหา:
คุณรายงานค่าเฉลี่ยความพึงพอใจเป็น 3.8462857143 (ผลลัพธ์ดิบของ Excel)
ระดับความแม่นยำนี้เป็นเท็จ Likert scale 5 ระดับไม่สามารถวัดความพึงพอใจถึง 10 ตำแหน่งทศนิยมได้ คุณกำลังรายงานความแม่นยำในการวัดที่เครื่องมือของคุณไม่มี
วิธีแก้ไข:
ใช้ฟังก์ชัน ROUND:
=ROUND(AVERAGE(B2:B101), 2)สิ่งนี้จะให้ 3.85 แทน 3.8462857143
จำนวนทศนิยมที่แนะนำ:
| สถิติ | ทศนิยม | ตัวอย่าง |
|---|---|---|
| ค่าเฉลี่ย (M) | 2 | M = 3.85 |
| ค่าเบี่ยงเบนมาตรฐาน (SD) | 2 | SD = 0.92 |
| ค่าสหสัมพันธ์ (r) | 3 | r = 0.547 |
| ค่า P | 3 | p = 0.003 |
| ขนาดอิทธิพล (Cohen's d) | 2 | d = 0.65 |
| เปอร์เซ็นต์ | 1 | 42.0% |
ตารางที่ 4: จำนวนทศนิยมที่ APA แนะนำสำหรับสถิติทั่วไป
การป้องกัน:
ใช้ ROUND กับสถิติที่คำนวณทั้งหมดก่อนคัดลอกไปยังวิทยานิพนธ์ของคุณ ตั้งค่ารูปแบบการแสดงผลของ Excel เป็น 2 ทศนิยมสำหรับตารางผลลัพธ์ทั้งหมด
ดูคู่มือของเราเกี่ยวกับการรายงานสถิติเชิงพรรณนาในรูปแบบ APA สำหรับกฎการจัดรูปแบบแบบสมบูรณ์
ข้อผิดพลาด #10: สร้างกราฟที่ทำให้เข้าใจผิด
ปัญหา:
คุณสร้างกราฟแท่งเปรียบเทียบความพึงพอใจเฉลี่ยระหว่าง 3 กลุ่ม:
- กลุ่ม A: 3.8
- กลุ่ม B: 3.9
- กลุ่ม C: 4.0
เพื่อให้ความแตกต่างดูน่าสนใจมากขึ้น คุณตั้งค่าต่ำสุดของแกน Y เป็น 3.5 แทน 0 ตอนนี้กราฟแสดงแท่งของกลุ่ม C สูงเป็น 2 เท่าของกลุ่ม A แม้ว่าความแตกต่างจริงจะเป็นแค่ 0.2 จุด
 รูปที่ 9: ข้อมูลเดียวกัน มาตราส่วนแกน Y ต่างกัน กราฟซ้ายขยายความแตกต่าง; กราฟขวาแสดงสัดส่วนที่ถูกต้อง
รูปที่ 9: ข้อมูลเดียวกัน มาตราส่วนแกน Y ต่างกัน กราฟซ้ายขยายความแตกต่าง; กราฟขวาแสดงสัดส่วนที่ถูกต้อง
วิธีแก้ไข:
ปฏิบัติตามกฎเหล่านี้สำหรับกราฟ:
- เริ่มแกน Y ที่ศูนย์เสมอ สำหรับกราฟแท่ง (เว้นแต่มีเหตุผลที่แข็งแกร่ง)
- ใช้กราฟ 2D (หลีกเลี่ยงกราฟวงกลม 3D ซึ่งบิดเบือนการรับรู้)
- ติดป้ายกำกับแกนอย่างชัดเจน (รวมหน่วย)
- ใช้สีที่สอดคล้องกัน (อย่ากำหนดสีให้กลุ่มแบบสุ่ม)
- รวม error bar สำหรับค่าเฉลี่ย (standard error หรือ 95% CI)
สำหรับข้อมูล Likert scale (1-5) ตั้งแกน Y จาก 0 ถึง 5 แม้ว่าคำตอบทั้งหมดจะอยู่ระหว่าง 3 ถึง 4
การป้องกัน:
ใช้การตั้งค่ากราฟเริ่มต้นของ Excel เป็นจุดเริ่มต้น ปรับมาตราส่วนแกนก็ต่อเมื่อคุณสามารถอธิบายการเปลี่ยนแปลงต่อกรรมการวิทยานิพนธ์ของคุณได้
คำนวณขนาดตัวอย่างของคุณ
ใช้เครื่องคำนวณฟรีของเราเพื่อกำหนดขนาดตัวอย่างที่ต้องการ โดยใช้ Yamane, Cochran และ Krejcie & Morgan เปรียบเทียบทั้งสามวิธีพร้อมการอ้างอิง APA
ลองใช้เครื่องคำนวณChecklist การป้องกันของคุณ
ใช้ checklist นี้ก่อนเริ่มการวิเคราะห์แบบสอบถามใดๆ:
การตั้งค่าก่อนวิเคราะห์:
- ติดตั้ง Analysis ToolPak แล้วและเห็นปุ่ม Data Analysis
- คำตอบทั้งหมดเป็นตัวเลข (1-5) ไม่ใช่ข้อความ ("เห็นด้วย")
- ใช้ Data Validation เพื่อป้องกันการป้อนข้อมูลที่ไม่สอดคล้องกัน
- ตั้งค่าการ export แบบสอบถามเป็นผลลัพธ์ตัวเลข
การทำความสะอาดข้อมูล:
- ตัดสินใจและบันทึกกลยุทธ์ข้อมูลที่หาย
- เช็คและลบคำตอบที่ซ้ำ
- อัปเดตขนาดตัวอย่างหลังทำความสะอาด (n=จำนวนสุดท้าย)
- เซลล์ทั้งหมดมีข้อมูลที่ถูกต้อง (ไม่มี error ไม่มีข้อความในคอลัมน์ตัวเลข)
การวิเคราะห์ทางสถิติ:
- ระบุ statistical test ที่ถูกต้องก่อนวิเคราะห์
- กลับคะแนนข้อที่ถามในทางตรงกันข้ามก่อน reliability test
- เช็คสมมติฐาน (normalit, homogeneity of variance)
- แก้ไขการเปรียบเทียบหลายครั้ง (ถ้าทำ t-test หลายครั้ง ใช้ ANOVA แทน)
การนำเสนอผลลัพธ์:
- ปัดเศษสถิติทั้งหมดเป็นทศนิยมที่เหมาะสม
- ตรวจสอบว่าเปอร์เซ็นต์รวมเป็น 100%
- กราฟใช้แกน Y ที่เริ่มจากศูนย์ (เว้นแต่มีเหตุผล)
- รายงานขนาดตัวอย่าง (n=X) ในตารางและกราฟทั้งหมด
- ผลลัพธ์ตรงกับแนวทางการจัดรูปแบบ APA ฉบับที่ 7
ดาวน์โหลด checklist นี้และเก็บไว้ที่เห็นได้ในขณะที่ทำงานวิเคราะห์ของคุณ
คำถามที่พบบ่อย
ขั้นตอนต่อไป
ตอนนี้คุณรู้แล้วว่าต้องหลีกเลี่ยงข้อผิดพลาดอะไรบ้าง ลองตามคู่มือเหล่านี้เพื่อวิเคราะห์ข้อมูลแบบสอบถามของคุณอย่างถูกต้อง:
เริ่มที่นี่: วิธีวิเคราะห์ข้อมูลแบบสอบถามใน Excel: คู่มือฉบับสมบูรณ์
เลือก statistical test ของคุณ:
เช็คความเชื่อมั่น:
รายงานผลลัพธ์:
อ้างอิง
- American Psychological Association. (2020). Publication Manual of the American Psychological Association (7th ed.). American Psychological Association.
- Field, A. (2018). Discovering Statistics Using IBM SPSS Statistics (5th ed.). SAGE Publications.
- Pallant, J. (2020). SPSS Survival Manual: A Step by Step Guide to Data Analysis Using IBM SPSS (7th ed.). Open University Press.
- Nunnally, J. C., & Bernstein, I. H. (1994). Psychometric Theory (3rd ed.). McGraw-Hill.