He revisado cientos de conjuntos de datos de tesis a lo largo de los años, y los mismos errores aparecen repetidamente. Los estudiantes pasan semanas recolectando datos de encuestas, solo para comprometer sus resultados con errores prevenibles en Excel.
Estos errores se dividen en cuatro etapas críticas: configuración previa al análisis, limpieza de datos, análisis estadístico y presentación de resultados. Un solo error en cualquier etapa puede invalidar todo tu análisis.
Esta guía te muestra los 10 errores más comunes que cometen los estudiantes al analizar datos de encuestas en Excel y cómo corregirlos antes de entregar tu tesis.
Errores en la Configuración Previa al Análisis
Estos errores ocurren antes de ejecutar una sola prueba estadística. Detectarlos temprano te ahorra horas de retrabajo.
Error #1: No Instalar Analysis ToolPak
El Problema:
Abres Excel, listo para ejecutar una prueba t o un ANOVA, y descubres que no hay ninguna opción de análisis estadístico en la pestaña Datos. Buscas en todos los menús sin encontrar nada.
Excel no incluye pruebas estadísticas por defecto. El complemento Analysis ToolPak debe instalarse manualmente.
Cómo Solucionarlo:
Para instrucciones completas de instalación (Windows y Mac), consulta nuestra guía: Cómo agregar Data Analysis en Excel.
Pasos rápidos para Windows:
- Haz clic en Archivo en la esquina superior izquierda
- Selecciona Opciones en la parte inferior del menú
- Haz clic en Complementos en la barra lateral izquierda
- En la parte inferior, busca el menú desplegable "Administrar:", selecciona Complementos de Excel, haz clic en Ir
- Marca la casilla junto a Analysis ToolPak
- Haz clic en Aceptar
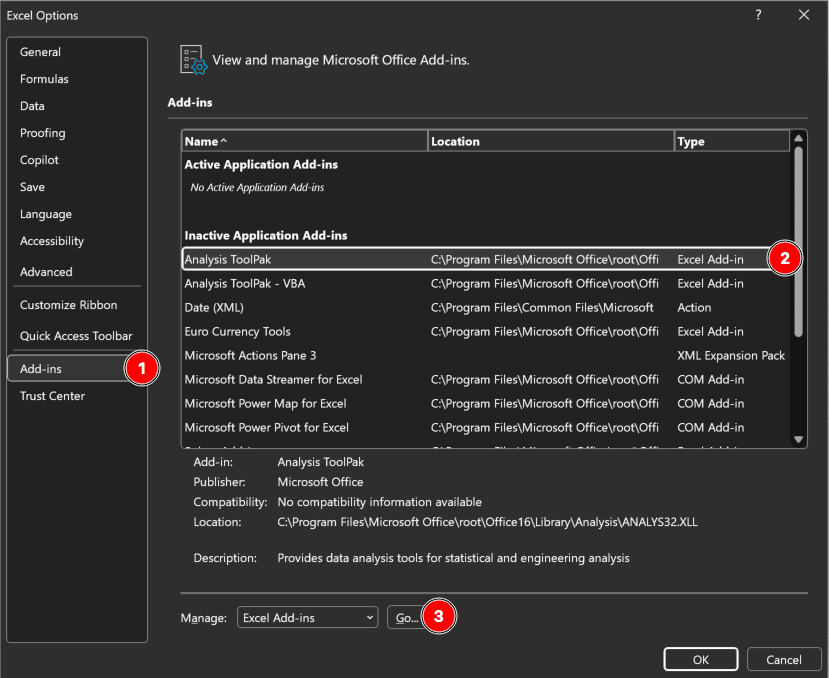 Figura 1: Cuadro de diálogo de Complementos de Excel con Analysis ToolPak habilitado (Windows)
Figura 1: Cuadro de diálogo de Complementos de Excel con Analysis ToolPak habilitado (Windows)
Usuarios de Mac: Ve a Herramientas → Complementos de Excel en lugar de Archivo → Opciones.
Después de la instalación, el botón Data Analysis aparece en la pestaña Datos (extremo derecho). Este botón te da acceso a pruebas t, ANOVA, regresión, correlación y estadísticas descriptivas.
Prevención:
Instala Analysis ToolPak la primera vez que abras Excel para tu tesis. Agrégalo a tu lista de verificación de configuración de investigación antes de recolectar cualquier dato.
Error #2: Mezclar Texto y Números en las Columnas de Respuestas
El Problema:
Tus respuestas de encuesta contienen texto como "Totalmente de acuerdo", "De acuerdo", "Neutral", "En desacuerdo" y "Totalmente en desacuerdo". Cuando intentas calcular el promedio de satisfacción, Excel devuelve un error o cero.
El texto no puede usarse en fórmulas estadísticas. Las funciones de Excel como AVERAGE, STDEV y CORREL requieren entrada numérica.
Cómo Solucionarlo:
Codifica todas las respuestas numéricamente antes del análisis. Crea una leyenda en una hoja separada:
| Código Numérico | Etiqueta de Texto |
|---|---|
| 1 | Totalmente en desacuerdo |
| 2 | En desacuerdo |
| 3 | Neutral |
| 4 | De acuerdo |
| 5 | Totalmente de acuerdo |
Tabla 1: Codificación numérica para respuestas en escala Likert de 5 puntos
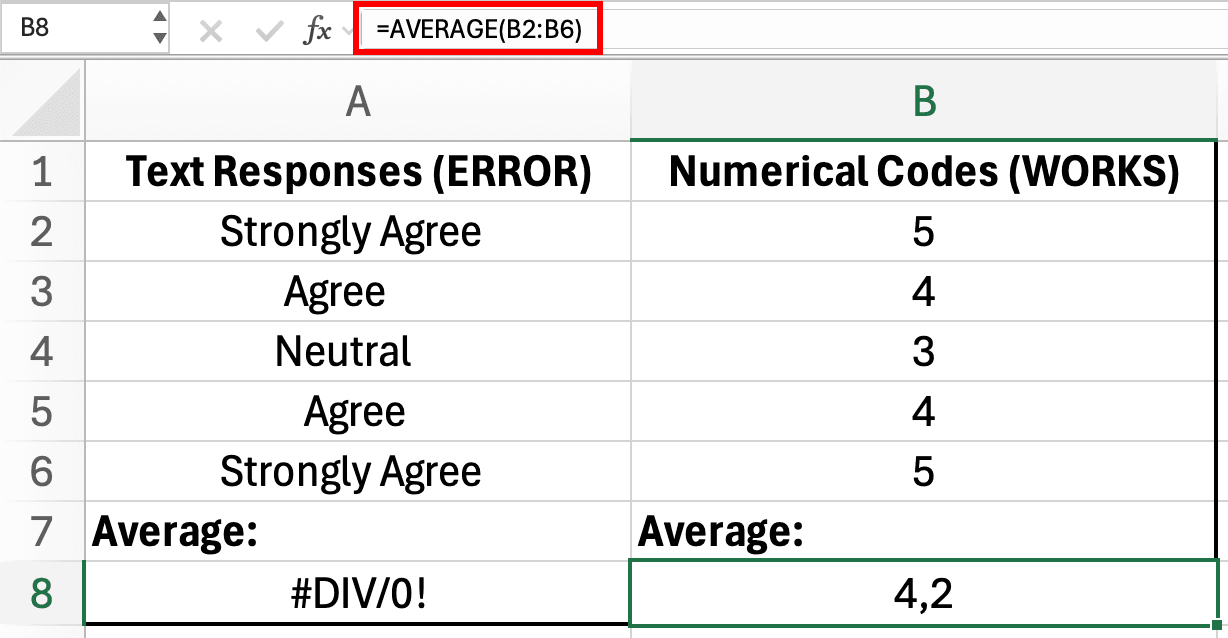 Figura 2: Las respuestas de texto no pueden usarse en la fórmula AVERAGE (error en A8), pero los códigos numéricos funcionan correctamente (4.2 en B8)
Figura 2: Las respuestas de texto no pueden usarse en la fórmula AVERAGE (error en A8), pero los códigos numéricos funcionan correctamente (4.2 en B8)
Al exportar desde herramientas de encuestas (Google Forms, Qualtrics, SurveyMonkey), selecciona la opción de valores numéricos en lugar de etiquetas de texto.
Si ya tienes respuestas de texto:
- Crea una nueva columna
- Usa =IF o =VLOOKUP para convertir texto a números
- Elimina la columna de texto original después de verificar
Prevención:
Configura los ajustes de exportación de tu encuesta para generar códigos numéricos desde el inicio. La mayoría de las plataformas tienen una opción "Exportar como valores numéricos (1-n)".
Error #3: Entrada de Datos Inconsistente
El Problema:
Ingresaste manualmente las respuestas de la encuesta y usaste formatos inconsistentes. Algunos encuestados están codificados como "Masculino", otros como "M" y algunos como "Hombre". Cuando creas una Tabla Dinámica para resumir respuestas por género, Excel muestra tres categorías separadas en lugar de una.
Este problema también aparece con variaciones ortográficas: "Totalmente de acuerdo" vs "TotalmenteDeAcuerdo" vs "Totalmente de acuerdo" (espacio extra). Cada variación se convierte en una categoría separada en tu análisis.
Nota: Las Tablas Dinámicas y COUNTIF no distinguen entre mayúsculas y minúsculas, así que "M" y "m" se contarían juntos. Sin embargo, diferentes grafías como "Masculino", "M" y "Hombre" siempre se tratan como valores separados.
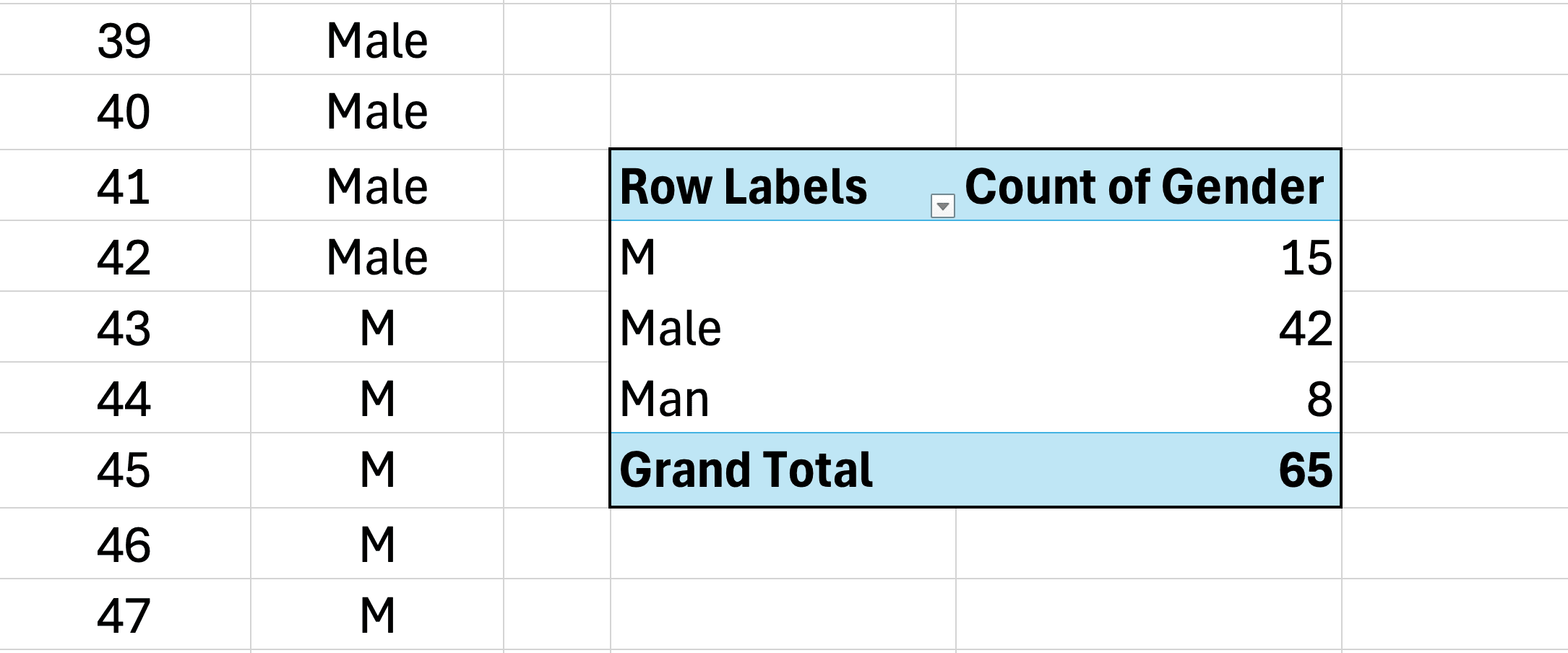 Figura 3: La Tabla Dinámica trata "Masculino", "M" y "Hombre" como tres categorías separadas debido a la entrada de datos inconsistente
Figura 3: La Tabla Dinámica trata "Masculino", "M" y "Hombre" como tres categorías separadas debido a la entrada de datos inconsistente
Tus conteos de frecuencia ahora están divididos en múltiples filas, lo que hace imposible reportar totales precisos sin consolidación manual.
Cómo Solucionarlo:
Usa Validación de Datos para restringir las entradas antes de la recolección:
- Selecciona la columna donde se ingresarán las respuestas
- Ve a la pestaña Datos
- Haz clic en Validación de datos
- En "Permitir:", selecciona Lista
- En "Origen:", escribe tus valores permitidos:
Masculino,Femenino,Otro(separados por comas) - Haz clic en Aceptar
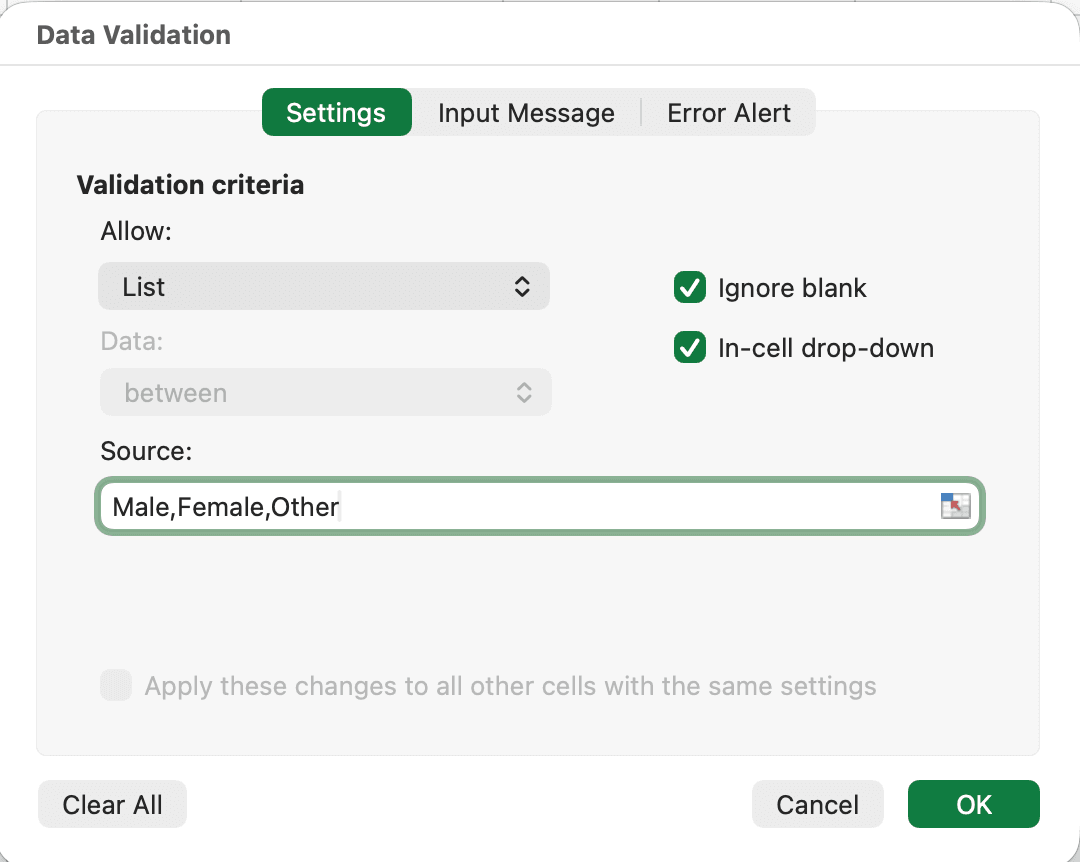 Figura 4: Configuración de Validación de Datos para restringir entradas a valores de lista predefinidos
Figura 4: Configuración de Validación de Datos para restringir entradas a valores de lista predefinidos
Ahora, los usuarios solo pueden seleccionar de la lista desplegable. La escritura directa queda deshabilitada, eliminando las inconsistencias.
Si los datos ya se ingresaron de forma inconsistente:
- Usa Buscar y Reemplazar (Ctrl+H) para estandarizar
- Busca "M" → Reemplazar con "Masculino" (con "Coincidir con el contenido completo de la celda" marcado)
- Busca "Hombre" → Reemplazar con "Masculino"
- Repite para todas las variaciones
Prevención:
Configura la Validación de Datos antes de recolectar cualquier dato. Para encuestas en línea, esto ocurre automáticamente a través de tu plataforma de encuestas.
Errores en la Limpieza de Datos
Los datos crudos de encuestas rara vez están listos para el análisis. Estos errores ocurren cuando los estudiantes omiten la fase de limpieza.
Error #4: Ignorar los Datos Faltantes
El Problema:
Algunos encuestados omitieron preguntas, dejando celdas vacías en tu conjunto de datos. Ejecutas AVERAGE en una columna y obtienes 4.2. Tu asesor pregunta: "¿Cómo manejaste los datos faltantes?" Te das cuenta de que nunca documentaste tu enfoque.
La función AVERAGE de Excel excluye automáticamente las celdas vacías tanto de la suma como del conteo. Este comportamiento puede o no coincidir con tu metodología prevista:
- Lo que hace Excel: (suma de 80 valores no vacíos) / 80 = 4.2
- Enfoque alternativo: Tratar faltantes como cero: (suma de 80 valores) / 100 = 3.36
- Otro enfoque: Imputar con mediana: (suma de 80 valores + 20 × mediana) / 100
El problema no es que Excel esté "mal"; es que tomaste una decisión metodológica sin darte cuenta. Si no documentas cómo se manejaron los datos faltantes, los revisores cuestionarán tus resultados.
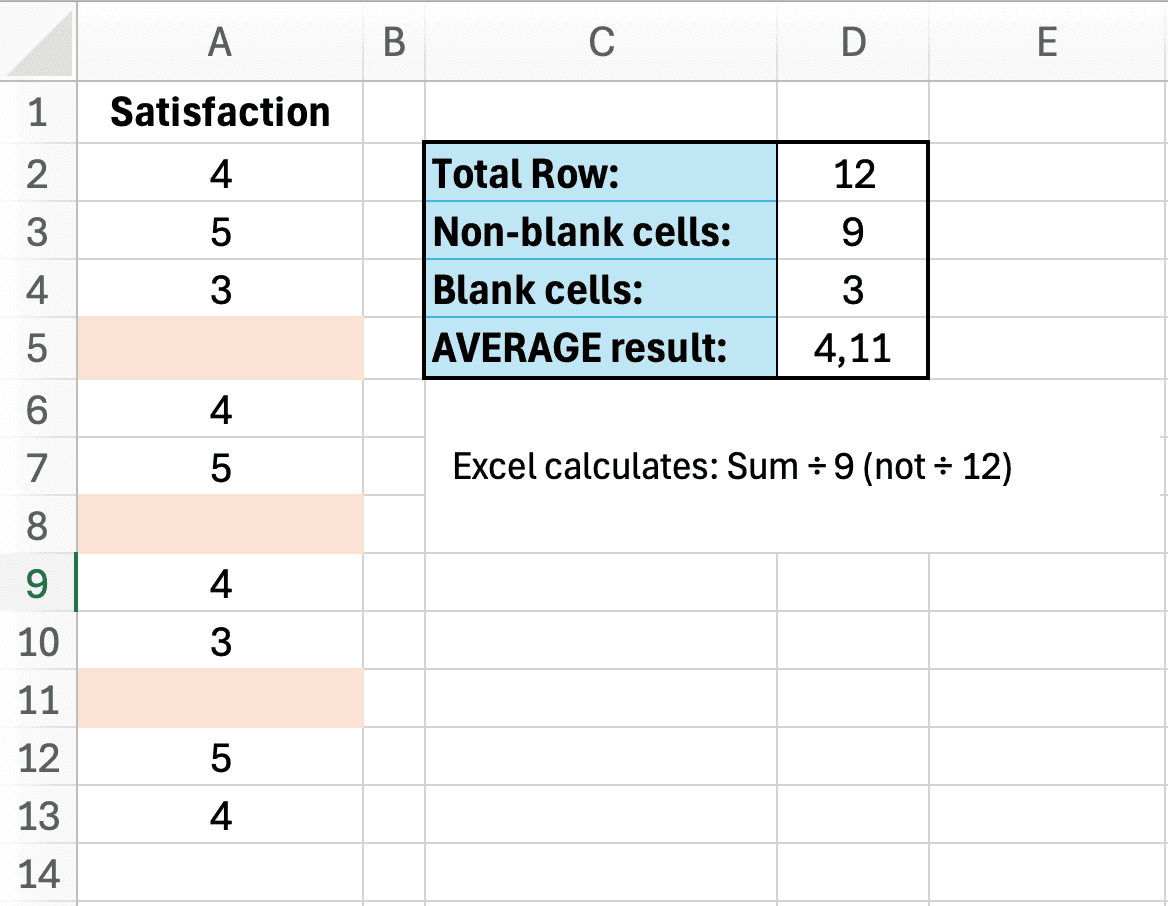 Figura 5: La función AVERAGE de Excel excluye las celdas vacías; esto puede o no coincidir con tu metodología prevista
Figura 5: La función AVERAGE de Excel excluye las celdas vacías; esto puede o no coincidir con tu metodología prevista
Cómo Solucionarlo:
Primero, identifica cuántos datos faltan:
=COUNTA(B2:B101) // Cuenta celdas no vacías
=ROWS(B2:B101) // Total de filas (debería ser 100)
=ROWS(B2:B101)-COUNTA(B2:B101) // Conteo de datos faltantesLuego, elige una estrategia:
Estrategia 1: Eliminar la fila completa (si los datos faltan de forma completamente aleatoria)
- Selecciona las filas con valores faltantes
- Clic derecho → Eliminar
- Actualiza tu tamaño de muestra (n=80 en lugar de n=100)
Estrategia 2: Reemplazar con la mediana (para datos numéricos)
- Calcula la mediana: =MEDIAN(B2:B101)
- Rellena las celdas vacías con este valor
- Anota en tu metodología: "Valores faltantes reemplazados con la mediana"
Estrategia 3: Codificar como "Faltante" (para datos categóricos)
- Reemplaza los espacios en blanco con 99 o "Faltante"
- Excluye de los cálculos estadísticos
- Reporta por separado: "85 respuestas válidas, 15 faltantes"
Prevención:
Haz que todas las preguntas de la encuesta sean obligatorias (a menos que sea éticamente inapropiado). Si los datos faltantes son inevitables, planifica tu estrategia de manejo antes del análisis.
Nota importante para tu tesis:
Documenta tu estrategia de datos faltantes en la sección de metodología. Escribe: "Los valores faltantes (n=15, 15%) fueron [eliminados/reemplazados con la mediana/codificados por separado] porque [justificación]."
Los revisores cuestionarán el manejo no documentado de datos faltantes.
Error #5: No Verificar Respuestas Duplicadas
El Problema:
Un encuestado envió tu encuesta dos veces por accidente. Otro usó dos direcciones de correo electrónico diferentes. Tu tamaño de muestra está inflado y algunas respuestas tienen doble peso en tu análisis.
Cómo Solucionarlo:
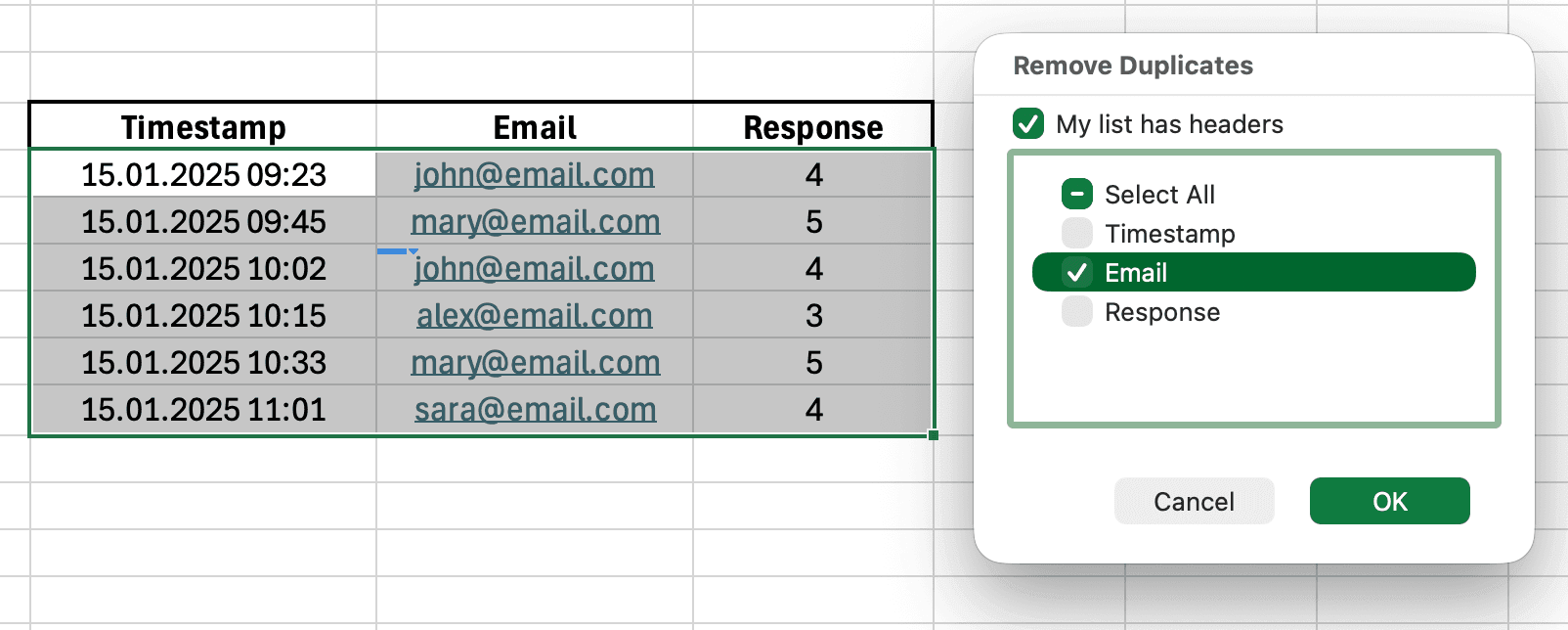 Figura 6: Cuadro de diálogo Quitar duplicados con Correo electrónico seleccionado para encontrar envíos duplicados de encuesta
Figura 6: Cuadro de diálogo Quitar duplicados con Correo electrónico seleccionado para encontrar envíos duplicados de encuesta
- Selecciona todo tu conjunto de datos (Ctrl+A)
- Ve a la pestaña Datos
- Haz clic en el botón Quitar duplicados
- Elige las columnas a verificar (generalmente Marca de tiempo o Correo electrónico)
- Haz clic en Aceptar
Excel muestra cuántos duplicados se encontraron y eliminaron. Actualiza tu tamaño de muestra en consecuencia.
Para encuestas en línea, revisa la configuración de tu plataforma:
- Google Forms: Limitar a 1 respuesta por correo electrónico
- Qualtrics: Habilitar "Prevenir envíos múltiples"
- SurveyMonkey: Requerir correo electrónico del encuestado
Prevención:
Habilita la prevención de duplicados en la configuración de tu encuesta. Para encuestas en papel, asigna a cada encuestado un ID único y verifica IDs duplicados antes del análisis.
Calcula tu Tamaño de Muestra
Usa nuestra calculadora gratuita para determinar el tamaño de muestra requerido con Yamane, Cochran y Krejcie & Morgan. Compara los tres métodos y obtén una cita lista para APA.
Probar CalculadoraErrores en el Análisis Estadístico
Estos errores ocurren durante el análisis propiamente dicho y suelen llevar a conclusiones incorrectas.
Error #6: Usar la Prueba Estadística Incorrecta
El Problema:
Quieres comparar las puntuaciones de satisfacción entre tres departamentos (Marketing, Ventas, Operaciones). Ejecutas tres pruebas t separadas:
- Marketing vs. Ventas (p=0.04)
- Marketing vs. Operaciones (p=0.06)
- Ventas vs. Operaciones (p=0.03)
Este enfoque es incorrecto. Múltiples pruebas t inflan tu tasa de error Tipo I (falsos positivos). Con tres comparaciones, tu tasa de error real no es 5% sino aproximadamente 14%.
Cómo Solucionarlo:
Usa la prueba apropiada para tu pregunta de investigación:
| Pregunta de Investigación | Número de Grupos | Prueba Correcta |
|---|---|---|
| Comparar dos grupos | 2 | Prueba t independiente |
| Comparar tres o más grupos | 3+ | ANOVA de una vía |
| Evaluar el mismo grupo dos veces | 2 (pareados) | Prueba t pareada |
| Relación entre variables | 2 (continuas) | Correlación de Pearson |
| Comparar datos categóricos | 2+ (categóricos) | Prueba chi-cuadrado |
Tabla 2: Guía de selección de pruebas estadísticas para preguntas de investigación comunes
Para el ejemplo de los tres departamentos, el enfoque correcto es:
- Ejecutar un ANOVA de una vía para probar si algún grupo difiere
- Si es significativo (p menor a 0.05), ejecutar pruebas post-hoc para identificar qué pares específicos difieren
- Reportar: "El ANOVA de una vía reveló diferencias significativas, F(2,297)=4.82, p=0.009"
Prevención:
Antes de recolectar datos, identifica tu prueba estadística. Consulta nuestra guía T-Test vs ANOVA: ¿cuál usar? para un diagrama de decisión completo.
Error #7: Calcular el Alfa de Cronbach en Ítems con Codificación Inversa
El Problema:
Calculas el alfa de Cronbach para una escala de autoeficacia de 5 ítems y obtienes α=0.45 (confiabilidad pobre). Revisas tu entrada de datos y fórmulas. Todo parece correcto.
El problema: tu escala incluye ítems formulados negativamente que no fueron invertidos.
Ejemplo de escala:
- "Me siento seguro de mis habilidades" (positivo)
- "Puedo manejar la mayoría de los desafíos" (positivo)
- "Frecuentemente dudo de mis habilidades" (negativo, necesita inversión)
- "Soy capaz de aprender cosas nuevas" (positivo)
- "NO creo en mí mismo" (negativo, necesita inversión)
Cuando los encuestados están totalmente de acuerdo con el ítem 3 (puntuación=5), en realidad tienen BAJA autoeficacia. Esto debe invertirse a 1 antes de calcular el alfa.
Cómo Solucionarlo:
 Figura 7: Fórmula de codificación inversa para una escala de 5 puntos: =6-valor_original
Figura 7: Fórmula de codificación inversa para una escala de 5 puntos: =6-valor_original
Para una escala de 5 puntos (1-5), usa esta fórmula:
=6-B2Para una escala de 7 puntos (1-7):
=8-B2Fórmula general:
=(valor_MAX + valor_MIN) - valor_originalDespués de invertir los ítems formulados negativamente, recalcula el alfa de Cronbach. Tu confiabilidad probablemente saltará de 0.45 a 0.80+.
Prevención:
Al diseñar tu encuesta, marca qué ítems necesitan codificación inversa. Antes de calcular cualquier estadístico de confiabilidad, crea una sección de "Ítems Invertidos" en tu archivo de Excel y aplica la fórmula.
Consulta nuestra guía sobre interpretar los resultados del alfa de Cronbach para solucionar otros problemas de confiabilidad.
Error #8: Fórmula Incorrecta para Porcentajes
El Problema:
Reportas: "50 encuestados estuvieron de acuerdo con la afirmación."
Tu revisor de tesis pregunta: "¿50 de cuántos? ¿Qué porcentaje?"
Calculas porcentajes manualmente y te confundes. Tus porcentajes suman 94% o 107% en lugar de 100%. Los errores comunes incluyen:
- Usar el denominador incorrecto: Dividir entre el total de filas (incluyendo encabezados o filas vacías) en lugar de respuestas válidas
- Mezclar fórmulas: Usar COUNTA para algunas filas y COUNT para otras
- Olvidar excluir datos faltantes: Incluir celdas vacías en tu conteo total
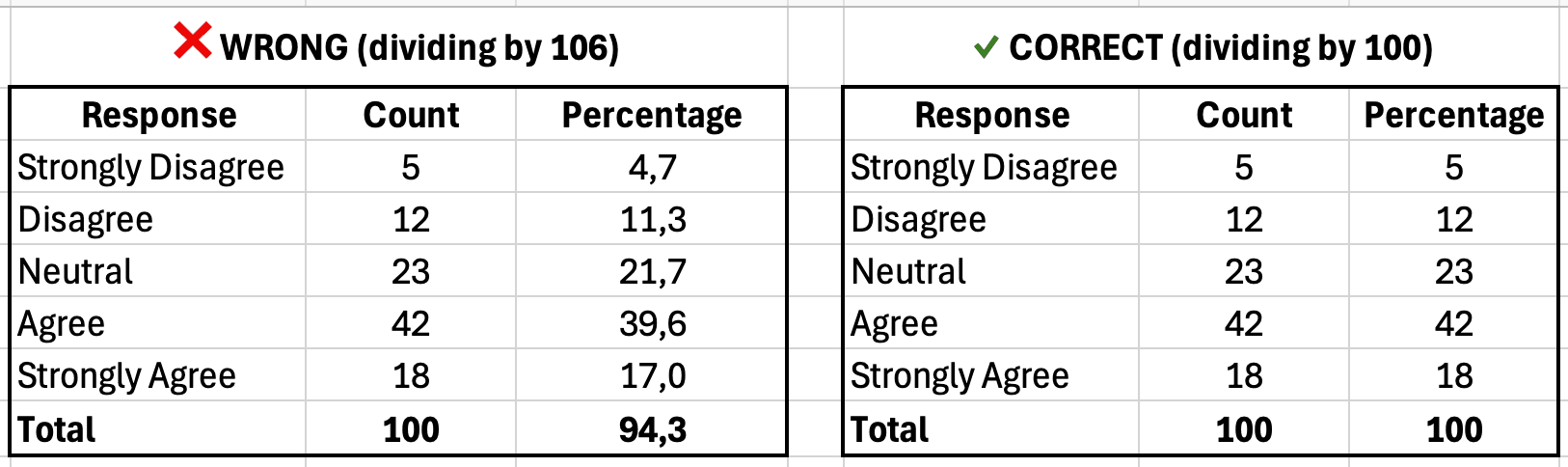 Figura 8: La izquierda muestra porcentajes incorrectos (94% total por denominador incorrecto); la derecha muestra el cálculo correcto (100% total)
Figura 8: La izquierda muestra porcentajes incorrectos (94% total por denominador incorrecto); la derecha muestra el cálculo correcto (100% total)
Cómo Solucionarlo:
Reporta siempre tanto el conteo como el porcentaje, usando fórmulas consistentes:
// Contar cuántos dijeron "De acuerdo" (codificado como 4)
=COUNTIF(B2:B101, 4)
// Total de encuestados
=COUNTA(B2:B101)
// Porcentaje
=COUNTIF(B2:B101, 4) / COUNTA(B2:B101) * 100Ejemplo de tabla de frecuencias con porcentajes:
El patrón de fórmula para cada fila es:
=COUNTIF(B:B, [valor_respuesta]) / COUNTA(B:B) * 100Donde [valor_respuesta] es 1 para "Totalmente en desacuerdo", 2 para "En desacuerdo", etc.
| Respuesta | Conteo | Porcentaje |
|---|---|---|
| Totalmente en desacuerdo | 5 | 5.0% |
| En desacuerdo | 12 | 12.0% |
| Neutral | 23 | 23.0% |
| De acuerdo | 42 | 42.0% |
| Totalmente de acuerdo | 18 | 18.0% |
| Total | 100 | 100.0% |
Tabla 3: Tabla de frecuencias mostrando la distribución de respuestas (los porcentajes deben sumar 100%)
Verificación:
Suma todos los porcentajes. Deben sumar 100% (permitiendo 0.1% de error por redondeo). Si tu total es 98% o 103%, tienes un error de fórmula.
Prevención:
Crea una plantilla con fórmulas de porcentaje preconstruidas. Reutiliza esta plantilla para todas las preguntas de la encuesta.
Errores en la Presentación de Resultados
Tu análisis puede ser correcto, pero una presentación deficiente socava la credibilidad.
Error #9: Reportar Demasiados Decimales
El Problema:
Reportas la satisfacción media como 3.8462857143 (la salida sin procesar de Excel).
Este nivel de precisión es falso. Una escala Likert de 5 puntos no puede medir la satisfacción con 10 decimales. Estás reportando una precisión de medición que tu instrumento no tiene.
Cómo Solucionarlo:
Usa la función ROUND:
=ROUND(AVERAGE(B2:B101), 2)Esto devuelve 3.85 en lugar de 3.8462857143.
Decimales recomendados:
| Estadístico | Decimales | Ejemplo |
|---|---|---|
| Media (M) | 2 | M = 3.85 |
| Desviación estándar (DE) | 2 | DE = 0.92 |
| Correlación (r) | 3 | r = 0.547 |
| Valor p | 3 | p = 0.003 |
| Tamaño del efecto (d de Cohen) | 2 | d = 0.65 |
| Porcentaje | 1 | 42.0% |
Tabla 4: Decimales recomendados por APA para estadísticos comunes
Prevención:
Aplica ROUND a todos los estadísticos calculados antes de copiarlos en tu tesis. Configura el formato de visualización de Excel a 2 decimales para toda tu tabla de resultados.
Consulta nuestra guía sobre estadísticas descriptivas en Excel para reglas completas de formato.
Error #10: Crear Gráficos Engañosos
El Problema:
Creas un gráfico de barras comparando la satisfacción media entre tres grupos:
- Grupo A: 3.8
- Grupo B: 3.9
- Grupo C: 4.0
Para hacer que las diferencias parezcan más impresionantes, estableces el mínimo del eje Y en 3.5 en lugar de 0. El gráfico ahora muestra la barra del Grupo C con el doble de altura que la del Grupo A, aunque la diferencia real es solo 0.2 puntos.
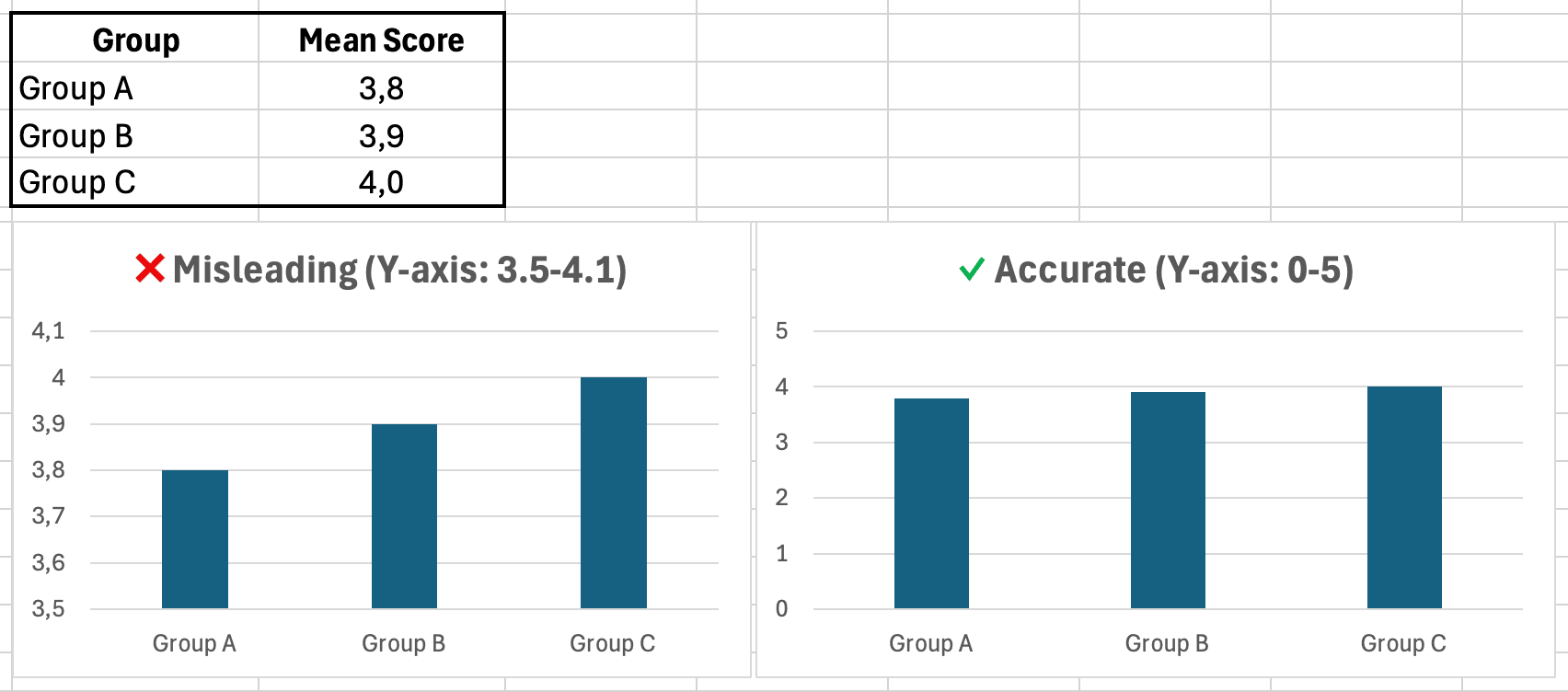 Figura 9: Mismos datos, diferentes escalas de eje Y. El gráfico izquierdo exagera las diferencias; el gráfico derecho muestra proporciones precisas
Figura 9: Mismos datos, diferentes escalas de eje Y. El gráfico izquierdo exagera las diferencias; el gráfico derecho muestra proporciones precisas
Cómo Solucionarlo:
Sigue estas reglas para gráficos:
- Siempre inicia el eje Y en cero para gráficos de barras (a menos que haya una justificación sólida)
- Usa gráficos 2D (evita los gráficos circulares 3D, que distorsionan la percepción)
- Etiqueta los ejes claramente (incluye unidades)
- Usa colores consistentes (no asignes colores al azar a los grupos)
- Incluye barras de error para las medias (error estándar o IC del 95%)
Para datos de escala Likert (1-5), establece el eje Y de 0 a 5, incluso si todas las respuestas caen entre 3 y 4.
Prevención:
Usa la configuración predeterminada de gráficos de Excel como punto de partida. Solo ajusta las escalas de los ejes si puedes justificar el cambio ante tu comité de tesis.
Calcula tu Tamaño de Muestra
Usa nuestra calculadora gratuita para determinar el tamaño de muestra requerido con Yamane, Cochran y Krejcie & Morgan. Compara los tres métodos y obtén una cita lista para APA.
Probar CalculadoraTu Lista de Verificación de Prevención
Usa esta lista de verificación antes de iniciar cualquier análisis de encuestas:
Configuración previa al análisis:
- Analysis ToolPak instalado y botón Data Analysis visible
- Todas las respuestas codificadas numéricamente (1-5), no texto ("De acuerdo")
- Validación de Datos aplicada para prevenir entradas inconsistentes
- Configuración de exportación de encuesta ajustada para salida numérica
Limpieza de datos:
- Estrategia de datos faltantes decidida y documentada
- Respuestas duplicadas verificadas y eliminadas
- Tamaño de muestra actualizado después de la limpieza (n=conteo final)
- Todas las celdas contienen datos válidos (sin errores, sin texto en columnas numéricas)
Análisis estadístico:
- Prueba estadística correcta identificada antes del análisis
- Ítems formulados negativamente invertidos antes de las pruebas de confiabilidad
- Supuestos verificados (normalidad, homogeneidad de varianzas)
- Comparaciones múltiples corregidas (si ejecutas múltiples pruebas t, usa ANOVA)
Presentación de resultados:
- Todos los estadísticos redondeados al número apropiado de decimales
- Porcentajes verificados para sumar 100%
- Gráficos usan eje Y basado en cero (a menos que se justifique)
- Tamaños de muestra reportados (n=X) en todas las tablas y gráficos
- Resultados siguen las pautas de formato APA 7.ª edición
Descarga esta lista de verificación y mantenla visible mientras trabajas en tu análisis.
Preguntas Frecuentes
Próximos Pasos
Ahora que conoces los errores que debes evitar, puedes avanzar con confianza en tu análisis de datos.
Para aprender a reportar correctamente los resultados de tu análisis descriptivo, consulta cómo reportar estadísticas descriptivas en formato APA con Excel. Si necesitas realizar una prueba t paso a paso, nuestra guía de la prueba t en Excel te lleva por todo el proceso.
Referencias
- American Psychological Association. (2020). Publication Manual of the American Psychological Association (7th ed.). American Psychological Association.
- Field, A. (2018). Discovering Statistics Using IBM SPSS Statistics (5th ed.). SAGE Publications.
- Pallant, J. (2020). SPSS Survival Manual: A Step by Step Guide to Data Analysis Using IBM SPSS (7th ed.). Open University Press.
- Nunnally, J. C., & Bernstein, I. H. (1994). Psychometric Theory (3rd ed.). McGraw-Hill.