En la lección anterior, aprendimos cómo calcular la desviación estándar con Excel. Esta vez aprenderemos cómo calcular la desviación estándar en R paso a paso con ejemplos claros.
Aunque R ofrece diversos tipos y estructuras de datos, en este tutorial nos enfocaremos en cómo calcular la desviación estándar en RStudio para los tipos más utilizados: data frames, vectores y arrays.
Suponiendo que ya tienes R y RStudio instalados en tu computadora, abre RStudio. Mientras tanto, repasemos algunos conceptos importantes sobre la desviación estándar.
Referencia Rápida: Desviación Estándar en R
| Función | Uso | Sintaxis | Ejemplo |
|---|---|---|---|
| sd() | Desviación estándar muestral | sd(x) | sd(df$column) |
| sd() | Desviación estándar poblacional | sd(x) * sqrt((n-1)/n) | sd(data) * sqrt(24/25) |
| var() | Varianza (para cálculo manual) | var(x) | sqrt(var(data)) |
Tabla 1: Funciones principales de R para calcular la desviación estándar
¿Qué es la Desviación Estándar?
En términos simples, la desviación estándar nos indica qué tan disperso está un conjunto de datos respecto a su promedio (media). Una desviación estándar baja es preferible porque indica que los datos son más confiables al estar agrupados cerca de la media. En contraste, una desviación estándar alta indica que los datos están dispersos sobre un rango más amplio de valores.
La notación general para la desviación estándar es sd. Sin embargo, la desviación estándar tiene dos fórmulas (y dos notaciones), dependiendo de si se calcula para toda la población o para una muestra.
El símbolo para la desviación estándar poblacional es la letra griega minúscula Sigma σ, mientras que la notación para la desviación estándar muestral es la letra s.
Fórmula de Desviación Estándar Poblacional
Donde:
- σ = desviación estándar poblacional
- μ = media poblacional
- N = tamaño de la población
Fórmula de Desviación Estándar Muestral
Donde:
- s = desviación estándar muestral
- x̄ = media muestral
- n = tamaño de la muestra
- n-1 = corrección de Bessel (grados de libertad)
Existe bastante confusión sobre la desviación estándar, su notación, cálculo y uso correcto en investigación estadística. Tómate unos minutos y revisa la lección Desviación Estándar Poblacional vs. Muestral primero para tener claridad antes de continuar con R.
Calcular la Desviación Estándar en R
En R, la función dedicada para la desviación estándar es sd() y calcula la raíz cuadrada de la varianza del objeto de entrada. El objeto y los valores que contiene se definen primero y luego se insertan como objetos de entrada en la función sd() para el cálculo.
Importante: La función sd() de R calcula la desviación estándar muestral (usando n-1 en el denominador). Si necesitas la desviación estándar poblacional, deberás aplicar un factor de corrección.
Veamos cómo calcular la desviación estándar en R usando la función sd() con ejemplos paso a paso.
Usando un Dataset de Excel
Comencemos calculando la desviación estándar de la edad en R para un grupo de encuestados en un dataset de Excel.
Puedes seguir el tutorial descargando el archivo Standard-Deviation-on-R.xlsx desde la barra lateral. Una vez descargado, importa el dataset de Excel en RStudio navegando a File → Import Dataset → From Excel y seleccionando el archivo descargado.
Nuestro dataset de ejemplo contiene dos columnas: age (edad) y weight (peso), como se muestra en la siguiente imagen.
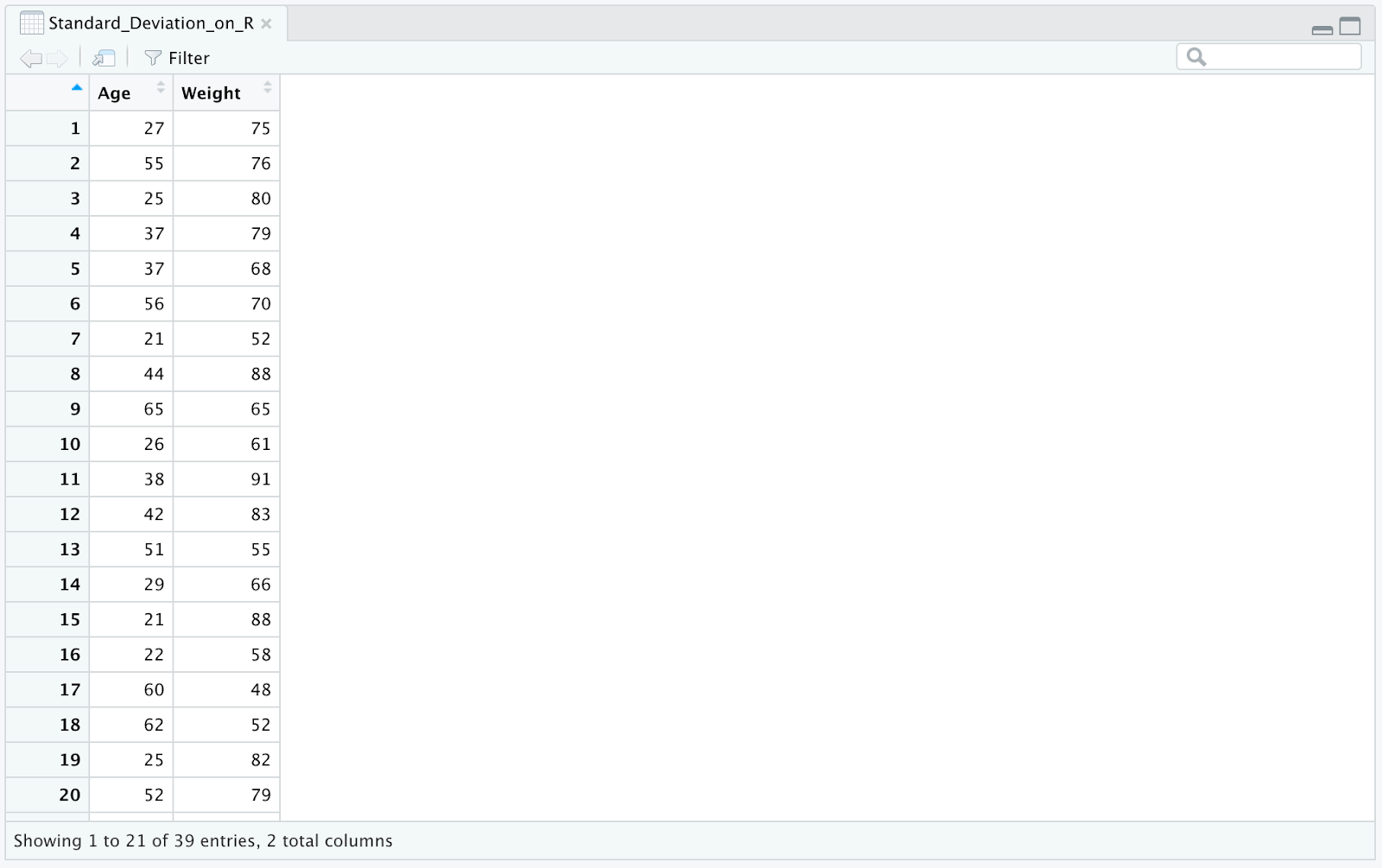
Figura 1: Dataset de ejemplo en Excel con columnas Age y Weight para el análisis de desviación estándar en R
Paso 1: Importar el archivo Excel
En RStudio, navega a:
- File → Import Dataset → From Excel
- Selecciona el archivo Standard-Deviation-on-R.xlsx
Paso 2: Calcular la desviación estándar para la columna age
Para encontrar la desviación estándar en R para el subconjunto age en el dataset de Excel importado, escribe en la consola de RStudio:
sd(Standard_Deviation_on_R$Age)Donde:
- sd() = función de desviación estándar en R
- Standard_Deviation_on_R = objeto del dataset de Excel
- $ = operador usado para extraer una parte específica de un objeto, por ejemplo, la columna age
La desviación estándar para age es 14.46402. Ahora, calcula la desviación estándar para el subconjunto weight en el mismo archivo Excel.

Figura 2: Salida de la consola RStudio mostrando la desviación estándar de 14.46402 para la columna Age
Paso 3: Calcular la desviación estándar para la columna weight
sd(Standard_Deviation_on_R$Weight)Usando Data Frames
En R, los data frames constan de tres componentes: filas, columnas y datos. En resumen, los data frames son todo lo que puede almacenar datos tabulares.
Podemos importar un data frame en R desde un archivo de texto o Excel (como hicimos anteriormente) o crear un data frame manual y extraer la desviación estándar de una columna numérica usando la función sd() en R.
Primero, creemos un data frame en R con cinco compañías tecnológicas principales y su precio por acción (NASDAQ) al momento de escribir este artículo:
| APPL | MSFT | AMZN | GOOGL | TSLA |
|---|---|---|---|---|
| 174.24 | 308.31 | 3259.95 | 2781.35 | 1078 |
Tabla 2: Precios por acción de las cinco principales compañías tecnológicas (NASDAQ)
Paso 1: Crear el data frame
Usaremos la función data.frame() para crear el objeto df en R. Este data frame tendrá cinco columnas y dos filas, similar a la tabla anterior, con el ID de la compañía (1 a 5), el nombre de la compañía y el precio de la acción.
Así creamos este data frame en R con un solo comando:
df <- data.frame(company_id = c(1:5),
company_name = c("APPL", "MSFT", "AMZN", "GOOGL", "TSLA"),
share_price = c(174.24, 308.31, 3259.95, 2781.35, 1078),
stringsAsFactors = FALSE)Donde:
- df = objeto data frame que contiene el ID, nombre y precio de acción de las cinco principales compañías tecnológicas de EE.UU.
- stringsAsFactors = argumento para la función data.frame() que determina si las cadenas de texto deben tratarse como factores o como cadenas ordinarias. En este caso, queremos tratar los datos como cadenas de caracteres, por lo que agregamos la bandera FALSE al argumento stringsAsFactors
Paso 2: Calcular la desviación estándar para la columna share_price
Finalmente, calculemos la desviación estándar en R para el precio de acción de las cinco principales compañías tecnológicas usando la función sd() de R:
sd(df$share_price)
Figura 3: Desviación estándar de 1422.415 para los precios de acción en el data frame de R
Como puedes ver, la desviación estándar calculada para el precio de acción es 1422.415.
Por supuesto, podemos agregar filas y columnas adicionales al data frame y expandir nuestro análisis de estadísticas descriptivas en R más allá del precio de acción.
Usando Vectores
Un vector es la estructura de datos más básica en R y consiste en una colección de componentes de datos del mismo tipo.
Por ejemplo, en R el vector 1:10 contendrá los valores del 1 al 10, respectivamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10.
Además, un vector puede contener valores específicos. Por ejemplo, el vector c(2,4,6) contendrá los valores 2, 4 y 6.
Paso 1: Crear un vector
Comencemos creando un vector vc usando el operador (:) y componentes de vector con valores del 1 al 10.
vc <- 1:10Paso 2: Visualizar el vector (opcional)
Puedes visualizar los componentes del vector vc usando el comando concatenate cat de la siguiente manera:
cat(vc)Paso 3: Calcular la desviación estándar
A continuación, calcula la desviación estándar en R para el objeto vc usando el comando:
sd(vc)Aquí está la salida completa. Como podemos ver, la desviación estándar en R para el vector vc es 3.02765

Figura 4: Desviación estándar de 3.02765 calculada para el vector con valores del 1 al 10 en RStudio
Usando Arrays
En R, un array es una colección de objetos que puede contener dos o más dimensiones de datos (multidimensional) y almacenar valores del mismo tipo de datos. Los arrays no deben confundirse con los vectores, que son unidimensionales por naturaleza.
Para encontrar la desviación estándar de un array en R, necesitamos crear el array usando la función incorporada array(). Para ello, tomaremos dos vectores como argumentos (por ejemplo, vc1 y vc2) y luego estableceremos las dimensiones de la matriz usando la función dim.
Paso 1: Crear el primer vector
Primero, definamos el vector vc1 con los elementos 12 y 8 usando el comando:
vc1 <- c(12,8)Paso 2: Crear el segundo vector
Y configuremos el vector vc2 con los elementos 39 y 17:
vc2 <- c(39,17)Paso 3: Crear un array a partir de los vectores
A continuación, creamos un array usando los vectores vc1 y vc2 y usamos la función dim para establecer las dimensiones de la matriz (columnas por filas):
arr <- array(c(vc1, vc2), dim = c(2, 2))Paso 4: Calcular la desviación estándar del array
Finalmente, usamos la función sd() para calcular la desviación estándar en R del array recién creado:
sd(arr)A continuación se muestra la salida completa en R. Como puedes ver, la desviación estándar del array arr es 13.832
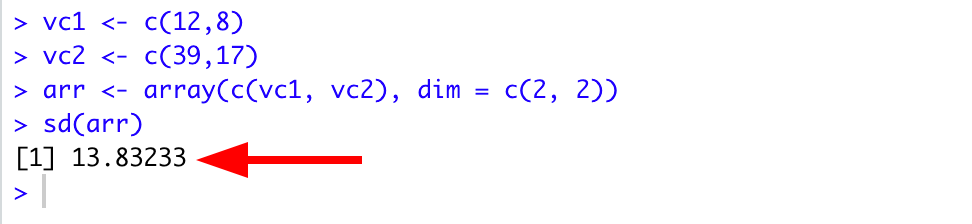
Figura 5: Desviación estándar de 13.832 calculada para el array 2x2 creado a partir de vectores en RStudio
Desviación Estándar Poblacional vs. Muestral en R
Como mencionamos anteriormente, la función sd() de R calcula la desviación estándar muestral por defecto (usando la corrección de Bessel con n-1).
Si necesitas calcular la desviación estándar poblacional en R, debes aplicar un factor de corrección:
# Desviación estándar muestral (por defecto)
sample_sd <- sd(data)
# Desviación estándar poblacional
n <- length(data)
population_sd <- sd(data) * sqrt((n-1)/n)Ejemplo: Desviación Estándar Poblacional
Calculemos la desviación estándar poblacional para nuestro ejemplo con vectores:
# Crear vector
vc <- 1:10
# Desviación estándar muestral
sd(vc) # Devuelve 3.02765
# Desviación estándar poblacional
n <- length(vc)
sd(vc) * sqrt((n-1)/n) # Devuelve 2.872281Preguntas Frecuentes
Próximos Pasos
Ahora que sabes cómo calcular la desviación estándar en R para datasets de Excel, data frames, vectores y arrays, puedes continuar fortaleciendo tus habilidades estadísticas:
-
Aprende los fundamentos de media, mediana y moda para complementar tu comprensión de las medidas de dispersión con las medidas de tendencia central.
-
Descubre cómo realizar la prueba de normalidad en R, un paso esencial antes de aplicar pruebas estadísticas paramétricas como la prueba t o ANOVA.
Referencias
Field, A., Miles, J., & Field, Z. (2012). Discovering statistics using R. SAGE Publications.