Los datos faltantes son uno de los problemas mas comunes y frustrantes que enfrentaras al analizar datos de encuestas en Excel para tu tesis o disertacion. Ya sea que los encuestados omitan preguntas, abandonen la encuesta a mitad de camino o proporcionen respuestas incompletas, los datos faltantes amenazan la validez de tus hallazgos de investigacion.
Tu comite de tesis examinara como manejaste los datos faltantes. Simplemente eliminar filas o ignorar celdas vacias puede introducir sesgo y socavar meses de trabajo de investigacion. El enfoque incorrecto puede convertir resultados estadisticamente significativos en ruido sin sentido, o peor aun, llevar a conclusiones falsas que no se replican.
Esta guia te muestra exactamente como manejar datos faltantes en el analisis de encuestas en Excel usando metodos que tu comite de tesis aceptara. Aprenderas cuando usar eliminacion listwise versus imputacion por media, como diagnosticar patrones de datos faltantes y, lo mas importante, como reportar tus decisiones en formato APA para tu seccion de Metodos.
Al final, tendras un framework de decision para elegir el metodo correcto de datos faltantes para tu escenario especifico de tesis, completo con formulas de Excel y plantillas de reporte APA.
Por que los Datos Faltantes Importan para Tu Tesis
Los datos faltantes no son solo una inconveniencia tecnica. Amenazan directamente tres aspectos criticos de tu investigacion de tesis:
Poder Estadistico: Cada respuesta faltante reduce tu tamano de muestra. Si recolectaste 300 respuestas de encuesta pero el 30% tiene datos faltantes, podrias quedarte con solo 210 casos completos despues de la eliminacion listwise. Esta muestra reducida puede disminuir tu poder estadistico por debajo de niveles aceptables (tipicamente 0.80), aumentando el riesgo de errores Tipo II donde no logras detectar efectos reales.
Sesgo en Resultados: Los datos faltantes rara vez son aleatorios. Si los encuestados mas jovenes omiten sistematicamente preguntas de ingreso, o los clientes insatisfechos abandonan encuestas de satisfaccion, tus resultados ya no representan tu poblacion objetivo. Este sesgo puede invertir la direccion de las relaciones, inflar o deflactar tamanos de efecto y llevar a conclusiones que no se generalizan mas alla de tu muestra sesgada.
Validez de Conclusiones: Tu comite de tesis sabe que como manejas los datos faltantes afecta la validez de cada prueba estadistica que ejecutas. Correlaciones, pruebas t, ANOVA y analisis de regresion producen resultados diferentes dependiendo de tu enfoque de datos faltantes. Si lo manejas incorrectamente, toda tu seccion de hallazgos se vuelve cuestionable.
Considera este ejemplo real: Un estudiante analizo encuestas de satisfaccion laboral con 15% de datos faltantes en preguntas de salario. Uso imputacion por media sin verificar patrones. Su analisis mostro que no habia relacion entre salario y satisfaccion. Una revision posterior revelo que los empleados con salarios bajos omitieron sistematicamente las preguntas de salario porque les daba verguenza. Los datos faltantes estaban ocultando exactamente la relacion que la tesis buscaba estudiar.
Tu comite de tesis espera que demuestres conciencia de estos problemas y justifiques tus decisiones sobre datos faltantes con rigor metodologico, no por conveniencia.
Tipos de Datos Faltantes
Antes de elegir un metodo para manejar datos faltantes en Excel, necesitas entender que tipo de datos faltantes tienes. Este diagnostico determina que tecnicas son apropiadas y cuales introduciran sesgo en los resultados de tu tesis.
Faltantes Completamente al Azar (MCAR)
Los datos son MCAR cuando la probabilidad de estar faltantes es la misma para todas las observaciones, sin patron sistematico. Este es el "mejor escenario" para datos faltantes.
Ejemplo: Tu sistema de encuestas en linea fallo aleatoriamente para el 5% de los encuestados, cortandoles a mitad de encuesta sin importar sus respuestas o demograficos. O los encuestados accidentalmente omitieron preguntas al hacer clic en "Siguiente" demasiado rapido, sin patron sobre cuales preguntas o cuales encuestados.
Caracteristica clave: Los datos faltantes no estan relacionados con ninguna variable en tu dataset, ya sea medida o no medida. Si pudieras conocer magicamente los valores faltantes, se verian como una muestra aleatoria de los datos completos.
Por que importa: MCAR es el unico tipo donde la eliminacion listwise (simplemente remover casos incompletos) produce estimaciones sin sesgo. Pierdes poder estadistico por el tamano de muestra reducido, pero tus resultados siguen siendo validos.
Faltantes al Azar (MAR)
Los datos son MAR cuando la probabilidad de estar faltantes depende de variables observadas en tu dataset, pero no de los valores faltantes en si.
Ejemplo: Los encuestados mayores omiten sistematicamente preguntas sobre tecnologia porque estan menos familiarizados con los terminos, pero entre encuestados de la misma edad, la falta de datos es aleatoria. O las tasas de abandono de encuesta difieren por genero (las mujeres son mas propensas a completar encuestas largas que los hombres), pero dentro de cada genero, el abandono es aleatorio.
Caracteristica clave: Puedes predecir cuales respuestas es probable que falten basandote en otras variables que mediste. La falta de datos se relaciona con lo que observaste, no con los valores faltantes ocultos.
Por que importa: Los datos MAR requieren un manejo mas sofisticado que MCAR. La eliminacion simple puede introducir sesgo porque no es igualmente probable que elimines todos los tipos de encuestados. La imputacion por media se vuelve mas aceptable si consideras las relaciones entre variables.
No Faltantes al Azar (NMAR)
Los datos son NMAR cuando la probabilidad de estar faltantes depende de los valores faltantes en si, incluso despues de considerar otras variables.
Ejemplo: Los encuestados con ingresos bajos omiten preguntas de salario porque ganan menos (la falta de datos se relaciona directamente con el valor faltante). O los clientes insatisfechos abandonan encuestas de satisfaccion antes de completarlas (quienes calificarian mas bajo no proporcionan calificaciones).
Caracteristica clave: La razon de la falta de datos esta relacionada con cual habria sido la respuesta. No puedes predecir la falta de datos solo con variables observadas porque el mecanismo involucra datos no observados.
Por que importa: NMAR es el tipo mas problematico para investigacion de tesis. Ningun metodo simple en Excel puede manejarlo sin sesgo. Necesitas tecnicas avanzadas como modelos de mezcla de patrones o analisis de sensibilidad, que frecuentemente requieren software estadistico mas alla de Excel. Para fines de tesis, niveles altos de datos NMAR pueden requerir re-recoleccion o reconocimiento de limitaciones importantes.
Como Diagnosticar tu Patron de Datos Faltantes en Excel
No puedes probar definitivamente si los datos son MCAR versus MAR versus NMAR, pero puedes buscar evidencia de patrones que sugieran falta de datos sistematica.
Paso 1: Calcula el porcentaje de datos faltantes
Cuenta el total de celdas faltantes en tus variables criticas. Si tienes 300 encuestados y 50 tienen valores faltantes en al menos una variable clave, eso es 16.7% de datos faltantes.
Paso 2: Crea indicadores de datos faltantes
Agrega una nueva columna para cada variable con datos faltantes. Codifica 1 para faltante, 0 para presente. Esto transforma la falta de datos en una variable que puedes analizar.
Paso 3: Prueba relaciones con variables observadas
Ejecuta correlaciones entre tus indicadores de datos faltantes y variables demograficas (edad, genero) u otras respuestas de la encuesta. Si ciertos grupos tienen tasas de datos faltantes significativamente mas altas, tus datos no son MCAR.
Paso 4: Compara encuestados con y sin datos faltantes
Usa pruebas t para comparar medias de variables observadas entre casos completos y casos con datos faltantes. Si los casos completos difieren sistematicamente de los casos incompletos en variables clave, tienes evidencia contra MCAR.
Para fines de tesis, si no encuentras patrones significativos, puedes tratar tentativamente los datos como MCAR y justificar la eliminacion listwise. Si encuentras patrones relacionados con variables observadas, tienes datos MAR. Si sospechas patrones relacionados con factores no observados, tienes NMAR y necesitas consultar a tu asesor sobre enfoques avanzados o limitaciones.
Nota sobre Configuracion Regional: Las formulas de Excel usan diferentes separadores de argumentos dependiendo de tu configuracion regional. Excel en EE.UU./Reino Unido usa comas:
=IF(ISBLANK(A1),0,A1)mientras que Excel en Europa/Latinoamerica usa punto y coma:=IF(ISBLANK(A1);0;A1). Si una formula devuelve un error, intenta cambiar comas por punto y coma (o viceversa). Para verificar o cambiar tu configuracion:
- Windows: Archivo, Opciones, Avanzadas, Opciones de edicion, "Usar separadores del sistema"
- Mac: Preferencias del Sistema, Idioma y Region, Avanzado, Separadores de numeros
Metodo 1: Eliminacion Listwise (Analisis de Casos Completos)
La eliminacion listwise, tambien llamada analisis de casos completos, es el enfoque mas simple para manejar datos faltantes en Excel: elimina cualquier fila que tenga al menos un valor faltante en las variables que estas analizando.
Cuando Usar Eliminacion Listwise
Usa eliminacion listwise cuando se cumplan las tres condiciones:
-
Menos del 5% de datos faltantes: Tu porcentaje de datos faltantes es suficientemente pequeno para que perder esos casos no reduzca sustancialmente el poder estadistico.
-
Los datos son MCAR: Has probado patrones y no encontraste evidencia de que la falta de datos se relacione con variables observadas o no observadas.
-
Tamano de muestra adecuado despues: Despues de la eliminacion, aun tienes suficientes casos para tus analisis planeados (tipicamente n mayor o igual a 30 por grupo para pruebas t, n mayor o igual a 15 por celda para ANOVA, n mayor o igual a 10 por predictor para regresion).
NO uses eliminacion listwise si:
- Tienes mas del 10% de datos faltantes (demasiada perdida de poder)
- Los datos faltantes muestran patrones sistematicos (introduce sesgo)
- Tu tamano de muestra restante cae por debajo de los requisitos minimos
- Diferentes analisis usarian diferentes subconjuntos de casos (hace los resultados no comparables)
Paso a Paso: Eliminacion Listwise en Excel
Paso 1: Identifica filas con datos faltantes
Primero, necesitas encontrar cuales filas tienen valores faltantes en tus variables clave de analisis.

Figura 1: Dataset de encuesta con datos faltantes en Excel mostrando celdas vacias que indican respuestas faltantes
Agrega una columna auxiliar (por ejemplo, columna Z) con esta formula en la fila 2:
=COUNTBLANK(B2:Y2)

Figura 2: Formula COUNTBLANK en Excel para identificar filas con datos faltantes mediante columna auxiliar
Esto cuenta celdas vacias en tu rango de datos para esa fila. Arrastra la formula hacia abajo para todos los encuestados. Cualquier fila con un valor mayor a 0 tiene datos faltantes.
Paso 2: Filtra solo los casos completos
Aplica Autofiltro a tu dataset (Datos, Filtro). Haz clic en el menu desplegable de tu columna auxiliar y desmarca cualquier valor excepto 0. Esto muestra solo los casos completos.
Alternativamente, usa esta formula para crear un dataset filtrado en una nueva hoja:
=FILTER(A2:Y1000, Z2:Z1000=0, "No hay casos completos")

Figura 3: Formula FILTER en Excel creando un dataset con solo casos completos sin datos faltantes
Esto copia solo las filas donde la columna auxiliar es igual a 0 (datos completos).
Paso 3: Verifica tu tamano de muestra restante
Cuenta tus casos completos y calcula el porcentaje eliminado. Si comenzaste con 300 encuestados y tienes 285 casos completos, eliminaste 15 (5%). Documenta esto para tu seccion de Metodos.
Paso 4: Realiza tus analisis en casos completos
Ejecuta todas tus pruebas estadisticas (Alfa de Cronbach, estadisticas descriptivas, pruebas t, ANOVA, correlacion) en este dataset filtrado de solo casos completos.
Ventajas y Limitaciones para Investigacion de Tesis
Ventajas:
- Simple de implementar en Excel con formulas basicas
- Produce estimaciones sin sesgo si los datos son verdaderamente MCAR
- Facil de explicar y defender ante tu comite de tesis
- Enfoque estandar en la mayoria de la investigacion publicada
- Sin supuestos sobre la forma de las distribuciones
Limitaciones:
- Reduce el poder estadistico al disminuir el tamano de muestra
- Desperdicio si tienes diferentes patrones faltantes entre analisis
- Puede introducir sesgo si se viola el supuesto de MCAR
- Diferentes analisis podrian usar diferentes subconjuntos, dificultando comparaciones
- Puede descartar casos que te costaron tiempo y dinero recolectar
Como Reportar Eliminacion Listwise en Formato APA
Tu seccion de Metodos debe incluir una subseccion de datos faltantes que reporte:
El analisis de datos faltantes revelo que 47 de 312 encuestados (15.1%) tenian al menos un valor faltante en las variables de interes. La comparacion de encuestados con datos completos versus incompletos no mostro diferencias significativas en edad, t(310) equals 1.23, p equals .22, distribucion de genero, X2(1) equals 0.87, p equals .35, ni puntuaciones basales de satisfaccion, t(310) equals 0.65, p equals .52, sugiriendo que los datos faltaban completamente al azar. Se aplico eliminacion listwise, resultando en una muestra analitica final de n equals 265 para todos los analisis subsecuentes.
Elementos clave a incluir:
- Numero y porcentaje de casos con datos faltantes
- Pruebas estadisticas que no muestran diferencias sistematicas (apoyando MCAR)
- Tamano de muestra final despues de la eliminacion
- Declaracion de que todos los analisis usan el mismo dataset de casos completos
Metodo 2: Imputacion por Media/Mediana
La imputacion por media reemplaza los valores faltantes con la media (o mediana) de los valores observados para esa variable. Este es uno de los metodos mas comunes que los estudiantes usan en Excel porque es intuitivo y preserva el tamano de muestra.
Cuando Usar Imputacion por Media/Mediana
Usa imputacion por media o mediana cuando:
-
Variables de escala numerica: Estas imputando respuestas de escala Likert, mediciones continuas o datos de conteo (no variables categoricas).
-
5-10% de datos faltantes: Tienes suficientes datos faltantes para que la eliminacion perjudique el poder, pero no tantos que la imputacion distorsione las distribuciones.
-
Patrones MAR o MCAR: Los datos faltantes son aleatorios o relacionados solo con variables observadas que no estas analizando actualmente.
-
Falta de datos en una sola variable: Los encuestados tienen datos faltantes en una variable pero datos completos en las demas.
Usa mediana en lugar de media cuando:
- Tus datos tienen valores atipicos que sesgan la media
- Tu variable es ordinal (escalas Likert 1-5, 1-7)
- Quieres una imputacion mas conservadora
- Tu distribucion no es normal
NO uses imputacion por media/mediana si:
- Estas imputando variables categoricas (usa moda o creacion de categoria)
- Los datos faltantes son NMAR (dependen de los valores faltantes en si)
- Calcularas correlaciones o regresion (la imputacion reduce las correlaciones artificialmente)
- Necesitas preservar la varianza para analisis avanzados
Paso a Paso: Imputacion por Media en Excel
Supongamos que tienes una escala de satisfaccion (1-7) en la columna C con algunas respuestas faltantes.
Paso 1: Calcula la media de los valores observados
En una celda auxiliar (por ejemplo, C1), calcula la media excluyendo celdas vacias:
=AVERAGE(C2:C1000)
Si tus datos tienen texto o errores, usa:
=AVERAGEIF(C2:C1000, ">0")
Esto te da la media a imputar. Supongamos que es 4.8.
Paso 2: Crea la variable imputada con formula
En una nueva columna (por ejemplo, D2), usa esta formula:
=IF(ISBLANK(C2), $C$1, C2)
Esto dice: "Si C2 esta vacia, usa la media de C1, de lo contrario usa el valor original de C2." Los signos de dolar fijan la referencia a tu celda de media.
Arrastra esta formula hacia abajo para todos los encuestados. Ahora tienes una variable completa con valores faltantes reemplazados por la media.

Figura 4: Formula IF ISBLANK en Excel reemplazando valores faltantes con la media para imputacion
Paso 3: Verifica la imputacion
Cuenta cuantos valores fueron imputados:
=COUNTIF(C2:C1000, "")
Compara la media de tu variable imputada con la original:
Media original: =AVERAGE(C2:C1000)
Media imputada: =AVERAGE(D2:D1000)
Deben ser casi identicas (la media imputada podria ser ligeramente mayor o menor por redondeo).
Paso a Paso: Imputacion por Mediana en Excel
La imputacion por mediana sigue la misma logica pero usa la mediana en lugar de la media.
Paso 1: Calcula la mediana de los valores observados
=MEDIAN(C2:C1000)
Para escalas Likert, esto frecuentemente te da un numero entero (por ejemplo, 5 en una escala 1-7).
Paso 2: Crea la variable imputada
=IF(ISBLANK(C2), $C$1, C2)
Misma formula que la imputacion por media, pero C1 ahora contiene la mediana.
Ventajas y Limitaciones para Investigacion de Tesis
Ventajas:
- Preserva el tamano de muestra (no se eliminan casos)
- Simple de implementar en Excel con formulas basicas
- Mantiene la media general de la variable (para imputacion por media)
- Facil de explicar a miembros del comite de tesis no estadisticos
- Funciona bien para cantidades pequenas de datos faltantes en variables individuales
Limitaciones:
- Reduce la varianza artificialmente (todos los valores imputados son identicos)
- Debilita las correlaciones entre variables (pendientes de regresion sesgadas hacia cero)
- Puede distorsionar distribuciones (crea pico en la media/mediana)
- No considera relaciones entre variables
- Subestima errores estandar (lleva a valores p excesivamente optimistas)
- Inapropiada para variables categoricas
Como Reportar Imputacion por Media/Mediana en Formato APA
Tu seccion de Metodos debe justificar y describir la imputacion:
El examen de patrones de datos faltantes revelo que el 8.7% de los encuestados (n equals 27) tenian valores faltantes en la escala de satisfaccion laboral. La prueba MCAR de Little indico que los datos faltaban completamente al azar, X2(124) equals 118.34, p equals .63. Para preservar el poder estadistico mientras se mantenia la tendencia central de la variable, se aplico imputacion por media, reemplazando las puntuaciones de satisfaccion faltantes con la media muestral de M equals 4.83 (DE equals 1.24). Todas las demas variables tenian datos completos y no requirieron imputacion.
Elementos clave:
- Porcentaje y numero de casos faltantes
- Evidencia del patron MCAR o MAR
- Justificacion de la eleccion de imputacion
- Valor exacto imputado (media o mediana)
- Declaracion de que la imputacion se limito a variables especificas
Importante: Algunos revisores ven la imputacion por media con escepticismo por sus efectos de reduccion de varianza. Preparate para defender esta eleccion o senalarla como una limitacion si la usas para variables involucradas en analisis de correlacion o regresion.
Metodo 3: Llenado hacia Adelante y hacia Atras
El llenado hacia adelante y hacia atras son tecnicas de Excel que reemplazan valores faltantes con el valor no faltante mas cercano de filas previas (hacia adelante) o posteriores (hacia atras). Este metodo rara vez es apropiado para datos de encuesta transversal, pero puede funcionar en escenarios especificos de tesis.
Cuando Usar Llenado hacia Adelante/Atras
Usa llenado hacia adelante (tambien llamado "ultima observacion replicada" o LOCF) cuando:
-
Datos de medidas repetidas o series temporales: Encuestaste a los mismos participantes multiples veces y tienes valores faltantes en oleadas posteriores.
-
Supuesto logico de estabilidad: Es razonable asumir que el valor faltante seria similar a la medicion anterior (por ejemplo, caracteristicas demograficas que no cambian).
-
Estructura de datos sistematica: Tus filas de Excel estan ordenadas por participante y tiempo, haciendo que "fila anterior" tenga significado.
NO uses llenado hacia adelante/atras para:
- Encuestas transversales donde el orden de filas es arbitrario
- Variables que se espera cambien con el tiempo
- Datos faltantes aleatorios sin logica temporal
- La mayoria de escenarios de encuesta de tesis (este metodo es principalmente para datos longitudinales o de panel)
Paso a Paso: Llenado hacia Adelante en Excel
Supongamos que tienes ID del participante en la columna A, punto temporal en la columna B y una medida repetida en la columna C, con algunos valores faltantes en C.
Paso 1: Asegurate de que los datos esten ordenados correctamente
Ordena tus datos por ID del Participante, luego por Punto Temporal. El llenado hacia adelante solo tiene sentido si las filas estan ordenadas cronologicamente dentro de cada participante.
Paso 2: Crea la formula de llenado hacia adelante
En la columna D (version llenada), usa esta formula en D2:
=IF(ISBLANK(C2), D1, C2)
Esto dice: "Si C2 esta vacia, usa el valor de la fila anterior (D1), de lo contrario usa C2."
Importante: Esta formula funciona fila por fila, asi que cada valor faltante toma el ultimo valor no faltante por encima de el.
Paso 3: Maneja los limites entre participantes
Agrega una condicion para evitar trasladar valores entre diferentes participantes:
=IF(A2<>A1, C2, IF(ISBLANK(C2), D1, C2))
Esto verifica si pasaste a un nuevo participante (A2 no es igual a A1). Si es asi, usa C2 (incluso si esta vacia). Si es el mismo participante y C2 esta vacia, usa D1. De lo contrario usa C2.
Limitaciones para Investigacion de Tesis
El llenado hacia adelante y hacia atras tiene limitaciones severas para datos tipicos de encuesta de tesis:
Orden arbitrario de filas: La mayoria de las exportaciones de encuestas de Qualtrics, Google Forms o SurveyMonkey tienen orden de filas arbitrario basado en la hora de envio. "Fila anterior" no tiene significado, haciendo que el llenado hacia adelante carezca de sentido.
Asume valores estables: Este metodo asume que el valor faltante es igual al ultimo valor observado, lo cual rara vez es justificable para actitudes, comportamientos o incluso demograficos en estudios transversales.
No es adecuado para escalas psicometricas: Si alguien omitio un item Likert, llenarlo con la respuesta del item anterior asume que todos los items miden exactamente el mismo constructo, violando principios basicos de desarrollo de escalas.
Crea patrones artificiales: El llenado hacia adelante puede crear correlaciones espurias porque copia valores, reduciendo la varianza y haciendo que las variables imputadas sean mas similares a las variables fuente de lo que deberian ser.
Para la mayoria de escenarios de tesis que involucran datos de encuesta, debes usar eliminacion listwise o imputacion por media en lugar de llenado hacia adelante/atras. Reserva este metodo para disenos verdaderos de medidas repetidas donde encuestaste a las mismas personas multiples veces.
Metodo 4: Crear una Categoria "Faltante"
Para variables categoricas, puedes manejar datos faltantes creando una categoria explicita "No Reportado" o "Faltante" en lugar de eliminacion o imputacion. Esto preserva todos los casos y hace que la falta de datos sea transparente en tus analisis.
Cuando Usar la Categoria "Faltante"
Usa este metodo cuando:
-
Variables categoricas con datos faltantes: Tienes valores faltantes en genero, nivel educativo, situacion laboral u otras categorias nominales/ordinales.
-
Patrones sistematicos de falta de datos: Ciertos encuestados deliberadamente omiten preguntas sensibles (ingreso, afiliacion politica, orientacion sexual).
-
La falta de datos en si es informativa: Negarse a responder puede reflejar actitudes significativas (por ejemplo, preocupaciones de privacidad, desconfianza).
-
Preservar el tamano de muestra es critico: No puedes permitirte perder casos a traves de eliminacion listwise.
NO uses la categoria "Faltante" cuando:
- Estas ejecutando regresion o correlacion (la categoria faltante crea variables dummy que pueden no ser interpretables)
- El tamano de muestra en la categoria "Faltante" seria demasiado pequeno (n menor a 10) para comparaciones significativas
- La falta de datos es claramente aleatoria y no informativa
Paso a Paso: Crear Categoria "Faltante" en Excel
Supongamos que tienes una variable de nivel educativo en la columna E con algunas respuestas en blanco.
Paso 1: Crea la variable recodificada con categoria "Faltante"
En una nueva columna (F2), usa esta formula:
=IF(ISBLANK(E2), "No Reportado", E2)
Esto reemplaza cualquier celda vacia con "No Reportado" mientras preserva todos los demas valores.
Para una recodificacion mas sofisticada con verificacion de texto:
=IF(OR(ISBLANK(E2), E2=""), "No Reportado", E2)
Esto captura tanto celdas verdaderamente vacias como celdas que parecen vacias pero contienen cadenas vacias.
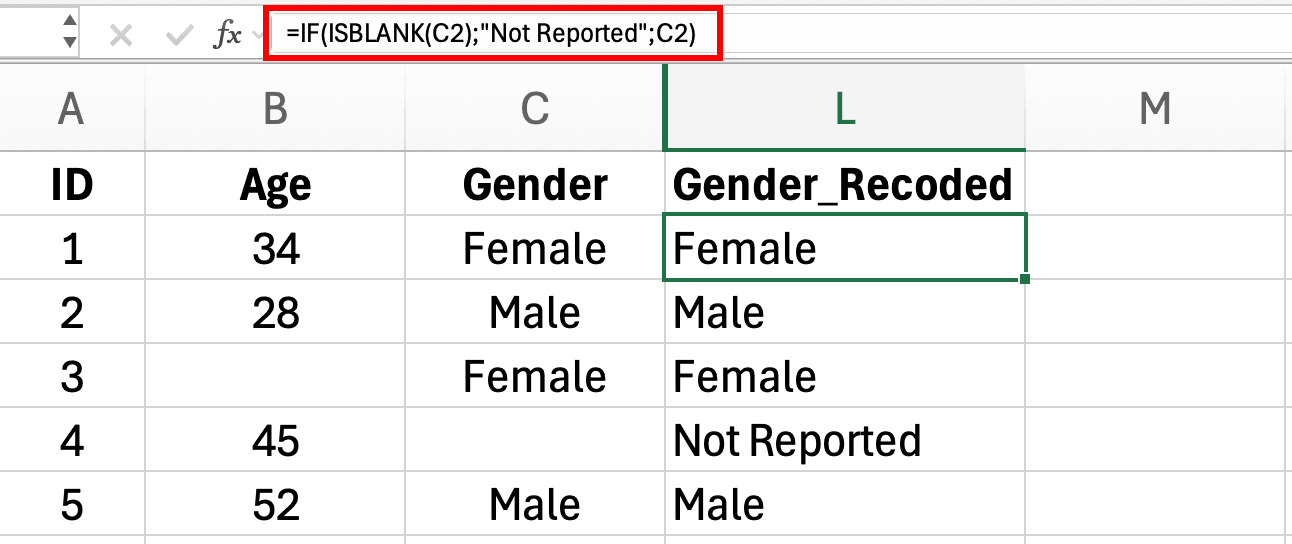
Figura 5: Formula IF ISBLANK creando categoria No Reportado para valores faltantes de Genero en Excel
Paso 2: Verifica la recodificacion
Crea una tabla de frecuencias para verificar:
- Selecciona tu columna recodificada (F2:F1000)
- Insertar, Tabla dinamica
- Arrastra tu variable a Filas
- Agrega Conteo a Valores
Debes ver tus categorias originales mas "No Reportado" con el conteo de valores previamente faltantes.
Paso 3: Usa en tus analisis
Ahora puedes incluir todos los casos en tus analisis. Por ejemplo, en una prueba chi-cuadrado examinando diferencias educativas en tasas de completamiento de encuesta, "No Reportado" se convierte en una categoria legitima que podria revelar patrones (por ejemplo, personas que no reportan educacion tambien podrian omitir sistematicamente otras preguntas).
Como Interpretar y Reportar la Categoria "Faltante"
Cuando creas una categoria "Faltante", estas tratando la negativa a responder como una respuesta significativa. Esto requiere interpretacion cuidadosa en tu seccion de Resultados:
Ejemplo de interpretacion:
La categoria "No Reportado" de educacion (n equals 34, 11.3%) mostro puntuaciones de satisfaccion significativamente mas bajas (M equals 3.2, DE equals 1.4) en comparacion con todos los demas niveles educativos (M equals 4.6, DE equals 1.2), t(298) equals 4.87, p menor a .001. Esto sugiere que los encuestados que no reportaron su nivel educativo pueden representar un subgrupo distinto con menor satisfaccion organizacional, posiblemente reflejando preocupaciones de privacidad o desapego.
Reporte APA en la seccion de Metodos:
Los datos faltantes en variables demograficas se retuvieron como categorias explicitas "No Reportado" para preservar el tamano de muestra y explorar patrones potenciales de no respuesta. Para la variable educacion, el 11.3% de los encuestados (n equals 34) no reportaron su nivel educativo y se retuvieron como una categoria separada "No Reportado" para todos los analisis que involucraran educacion.
Ventajas y Limitaciones
Ventajas:
- Preserva toda la muestra (sin eliminaciones)
- Hace que la falta de datos sea transparente en los resultados
- Puede revelar patrones significativos en quien no responde
- Apropiada para preguntas demograficas sensibles
- Evita la imputacion poco etica de datos categoricos
Limitaciones:
- Aumenta el numero de grupos para comparacion (puede reducir el poder)
- Complica la interpretacion (es "No Reportado" un grupo significativo?)
- No se puede usar en analisis que requieren variables numericas
- Puede violar supuestos de algunas pruebas estadisticas
- Requiere tamano de muestra mayor para tener poder adecuado con categoria adicional
Diagrama de Decision: Que Metodo para tus Datos de Encuesta?
Usa este diagrama de decision para elegir el metodo apropiado de datos faltantes para tu escenario especifico de tesis.

Figura 6: Diagrama de Decision de Datos Faltantes para elegir el metodo correcto en el analisis de encuestas de tu tesis
Pregunta 1: Que porcentaje de tus datos falta?
- Menos del 5% -> Continua a la Pregunta 2
- 5-10% -> Continua a la Pregunta 3
- Mas del 10% -> DETENTE. Consulta a tu asesor de tesis. La alta falta de datos requiere tecnicas avanzadas (imputacion multiple) o puede indicar problemas fundamentales en la recoleccion de datos.
Pregunta 2: Tus datos faltantes son completamente aleatorios (MCAR)?
Prueba esto comparando encuestados con datos completos vs. incompletos en demograficos clave y otras variables.
- Si, no se encontraron patrones -> Usa ELIMINACION LISTWISE
- No, existen patrones -> Continua a la Pregunta 3
Pregunta 3: Que tipo de variable tiene datos faltantes?
- Categorica (genero, educacion, Si/No) -> Usa metodo de CATEGORIA "FALTANTE"
- Numerica/Escala (Likert, continua) -> Continua a la Pregunta 4
Pregunta 4: Usaras esta variable en correlaciones o regresion?
- Si -> Usa ELIMINACION LISTWISE (la imputacion por media sesga las correlaciones hacia abajo)
- No, solo estadisticas descriptivas o comparaciones de grupos -> Usa IMPUTACION POR MEDIA o MEDIANA
Pregunta 5: Tu variable tiene valores atipicos o es ordinal?
- Si (valores atipicos presentes o escala Likert) -> Usa IMPUTACION POR MEDIANA
- No (distribucion aproximadamente normal) -> Usa IMPUTACION POR MEDIA
Caso especial: Datos longitudinales/medidas repetidas?
Si tienes datos de encuesta de series temporales donde las filas representan la misma persona en diferentes puntos temporales:
- Considera LLENADO HACIA ADELANTE o HACIA ATRAS
- Solo si el supuesto de estabilidad es razonable
- Documenta esto claramente en la seccion de Metodos
Escenarios Comunes de Tesis y Soluciones
Escenario 1: Respuestas Parciales en Escala Likert
Problema: Administraste una escala de satisfaccion de 10 items. Algunos encuestados respondieron 9 items pero omitieron 1, dejandote con datos faltantes en items individuales.
La solucion depende del proposito:
Si calculas Alfa de Cronbach o puntuaciones totales de escala:
- Usa eliminacion listwise a nivel de escala (elimina casos que falten en cualquier item)
- Justificacion: El Alfa de Cronbach requiere datos completos en todos los items
- Alternativa: Si falta menos del 20% de los items de la escala, calcula la media de los items disponibles como puntuacion de escala
Si examinas items individuales:
- Usa imputacion por mediana (las escalas Likert son ordinales)
- Imputa con la mediana de ese item especifico, no la media de la escala
- Reporta en Metodos: "Para los encuestados con items de escala faltantes (n equals 14, 4.7%), los valores faltantes se reemplazaron con la mediana especifica del item"
Escenario 2: Datos Demograficos Faltantes
Problema: El 15% de los encuestados no proporcionaron informacion de edad, genero o ingreso.
Solucion:
Para demograficos categoricos (genero, educacion):
- Crea una categoria "No Reportado"
- Nunca imputes demograficos (crea caracteristicas ficticias de la muestra)
- Ejemplo: Genero se convierte en Masculino/Femenino/No binario/No Reportado
Para demograficos continuos (edad, ingreso):
- Si los usas como variable de agrupacion: Crea la categoria "No Reportado" categorizando primero, luego agregando la categoria faltante
- Si los usas como covariable: Usa eliminacion listwise para analisis que involucren ese demografico
- Nunca imputes (tergiversa tu muestra real)
Reporta en Metodos:
Las variables demograficas con datos faltantes se retuvieron usando una categoria "No Reportado" para genero (n equals 23, 7.6%) y educacion (n equals 19, 6.3%). Los casos con datos faltantes de edad (n equals 12, 4.0%) se excluyeron de los analisis que involucraran la edad como variable a traves de eliminacion listwise.
Escenario 3: Alta Tasa de Abandono (Mas del 10% Faltante)
Problema: Enviaste una encuesta de 50 preguntas. La tasa de completamiento fue del 70%, con el 30% de los encuestados abandonando la encuesta a mitad de camino.
Senales de alerta:
- Este nivel de falta de datos probablemente indica problemas de diseno de la encuesta (demasiado larga, confusa, problemas tecnicos)
- El patron es casi seguramente NMAR (las personas que calificarian mas bajo abandonan)
- Los metodos simples de Excel introduciran sesgo sustancial
Soluciones:
Opcion 1: Analiza grupos completos vs. incompletos por separado
- Trata el abandono de la encuesta como una variable de resultado
- Compara respuestas tempranas entre completadores y no completadores. Usa pruebas t para comparar medias en variables observadas
- Reporta: "Los encuestados que completaron la encuesta (n equals 210) no difirieron de quienes la abandonaron (n equals 90) en las caracteristicas demograficas disponibles para ambos grupos, sugiriendo que el abandono no estaba sistematicamente relacionado con los perfiles de los encuestados"
Opcion 2: Analisis de datos parciales
- Usa eliminacion listwise por separado para cada analisis
- Reporta claramente tamanos de muestra variables
- Ejemplo: "Los tamanos de muestra variaron por analisis debido a la eliminacion listwise: demograficos (n equals 300), items de satisfaccion (n equals 210), respuestas abiertas (n equals 156)"
Opcion 3: Consulta a tu asesor sobre tecnicas avanzadas
- Imputacion multiple. Consulta la guia para importar un archivo CSV en R para comenzar con R
- Modelos de mezcla de patrones
- Puede necesitar reconocerse como limitacion importante
Opcion 4: Recolecta mas datos (si es posible)
- Si aun estas en fase de recoleccion de datos, redisena la encuesta para reducir la extension
- Agrega barra de progreso, funcion de guardar y continuar
- Puede ser la unica solucion para datos severamente comprometidos
Nunca procedas con datos de alto abandono usando imputacion por media simple y esperes que los revisores no lo noten. Tu comite de tesis identificara esto inmediatamente como una amenaza a la validez.
Escenario 4: Preguntas Sensibles (Ingreso, Salud, Politica)
Problema: Preguntas sobre ingreso, salud mental, afiliacion politica u otros temas sensibles tienen 20-30% de no respuesta, superando con creces otras variables.
Patron probable: NMAR (las personas que reportarian el ingreso mas bajo o las condiciones de salud mas estigmatizadas son las mas propensas a omitir)
Solucion:
Usa "Prefiero No Responder" como opcion explicita de respuesta durante el diseno de la encuesta (previene este problema).
Si ya tienes los datos con valores faltantes:
- Crea la categoria "No Reportado"
- Reconoce esto como NMAR en la seccion de Metodos
- Reporta resultados del grupo "No Reportado" por separado
- Considera que este grupo puede diferir sistematicamente de quienes respondieron
Ejemplo de analisis:
El ingreso faltaba para el 28.3% de los encuestados (n equals 85). El analisis chi-cuadrado revelo que los encuestados que no reportaron ingreso tenian significativamente mayor probabilidad de reportar insatisfaccion laboral, X2(1) equals 12.45, p menor a .001, sugiriendo diferencias sistematicas entre quienes reportaron y quienes no. Por lo tanto, los analisis de ingreso se restringen a los encuestados que proporcionaron informacion de ingreso (n equals 215), con el reconocimiento de que los hallazgos pueden no generalizarse al subgrupo que no reporto.
Este enfoque transparente reconoce la limitacion en lugar de ocultarla mediante imputacion inapropiada.
Como Reportar Datos Faltantes en Tu Tesis
Tu seccion de Metodos de tesis debe incluir una subseccion clara y detallada sobre datos faltantes. Esto demuestra rigor metodologico y previene preguntas del comite durante tu defensa. Asi es como estructurarla:
Que Incluir en tu Seccion de Metodos
1. Describe la magnitud de los datos faltantes
Reporta el porcentaje y numero de casos con valores faltantes, por separado para cada variable o conjunto de variables.
Ejemplo:
El analisis de datos faltantes revelo patrones variables entre las variables. Las variables demograficas estaban en gran parte completas, con menos del 3% de datos faltantes para edad (n equals 8) y genero (n equals 5). La variable de resultado principal, satisfaccion laboral, tenia 7.3% de datos faltantes (n equals 22), mientras que el resultado secundario de compromiso organizacional tenia 12.1% faltante (n equals 36). Todas las variables predictoras estaban completas sin valores faltantes.
2. Prueba y reporta el patron de datos faltantes
Describe si los datos parecen ser MCAR, MAR o NMAR basandote en tus pruebas diagnosticas.
Ejemplo:
Para examinar si los datos faltaban completamente al azar (MCAR), se compararon los encuestados con datos completos versus incompletos en demograficos clave y variables basales usando pruebas t independientes y pruebas chi-cuadrado. No surgieron diferencias significativas para edad, t(298) equals 0.87, p equals .39, genero, X2(2) equals 1.45, p equals .48, nivel educativo, X2(3) equals 2.31, p equals .51, ni satisfaccion basal, t(298) equals 1.22, p equals .22. La prueba MCAR de Little no fue significativa, X2(156) equals 148.73, p equals .64, proporcionando evidencia de que los datos faltaban completamente al azar.
3. Justifica tu metodo elegido
Explica por que seleccionaste tu enfoque especifico de datos faltantes, con referencia al patron diagnosticado anteriormente.
Ejemplo:
Dado el patron MCAR y el porcentaje relativamente pequeno de datos faltantes (menos del 8% para el resultado principal), se empleo eliminacion listwise para todos los analisis. Este enfoque, aunque reduce ligeramente el poder estadistico, produce estimaciones de parametros sin sesgo bajo supuestos MCAR (Schafer y Graham, 2002) y mantiene la consistencia entre todos los analisis al usar la misma muestra analitica.
4. Reporta la muestra analitica final
Indica tu tamano de muestra final despues de aplicar tu metodo de datos faltantes.
Ejemplo:
Despues de la eliminacion listwise, la muestra analitica final consistio en n equals 264 encuestados con datos completos en todas las variables incluidas en los analisis primarios. Los analisis de sensibilidad comparando los casos completos con la muestra total (N equals 300) en variables basales disponibles no mostraron diferencias sistematicas, apoyando la validez de este enfoque.
Plantillas para Diferentes Metodos
Plantilla de Eliminacion Listwise:
Los datos faltantes se presentaron en [X%] de los casos para [nombre de la variable]. El examen de patrones de datos faltantes no revelo diferencias significativas entre encuestados con datos completos versus incompletos en [enumera variables demograficas y clave], sugiriendo que los datos faltaban completamente al azar. Se aplico eliminacion listwise, resultando en una muestra analitica final de n equals [X] para todos los analisis subsecuentes.
Plantilla de Imputacion por Media/Mediana:
El analisis de datos faltantes revelo que [X%] de los encuestados (n equals [X]) tenian valores faltantes en la [nombre de la variable]. La prueba MCAR de Little indico que los datos faltaban completamente al azar, X2([gl]) equals [valor], p equals [valor]. Para preservar el poder estadistico mientras se mantenia la tendencia central de la variable, se aplico imputacion por media, reemplazando los valores faltantes con la media muestral de M equals [X] (DE equals [X]). Los analisis de sensibilidad comparando resultados con y sin imputacion mostraron patrones consistentes, apoyando este enfoque.
Plantilla de Categoria Faltante:
Las variables demograficas con datos faltantes se retuvieron usando categorias explicitas "No Reportado": [X%] para genero (n equals [X]), [X%] para educacion (n equals [X]). Este enfoque preserva la muestra completa y permite examinar patrones potenciales de no respuesta. Los encuestados que no reportaron demograficos no difirieron significativamente de quienes si lo hicieron en las variables de resultado clave, sugiriendo que la no respuesta no estaba sistematicamente relacionada con los resultados del estudio.
Preguntas Comunes del Comite (y Como Responderlas)
Pregunta: "Por que no usaste imputacion multiple?"
Respuesta: "La imputacion multiple es el estandar de oro para manejar datos faltantes, particularmente con patrones MAR o NMAR. Sin embargo, dado que nuestros datos faltaban completamente al azar, demostrado por la prueba MCAR de Little (p equals .64), y la falta de datos era menor al 8%, la eliminacion listwise proporciona estimaciones sin sesgo con mayor simplicidad y transparencia. La imputacion multiple habria requerido software mas alla de Excel y agregado complejidad sin mejorar la calidad de las estimaciones bajo condiciones MCAR."
Pregunta: "Como determinaste que los datos eran MCAR?"
Respuesta: "Realize varias pruebas diagnosticas: Primero, compare a los encuestados con y sin datos faltantes en todos los demograficos observados y variables basales usando pruebas t y pruebas chi-cuadrado. No surgieron diferencias significativas. Segundo, calcule la prueba MCAR de Little, que no fue significativa (p equals .64), sin rechazar la hipotesis nula de que los datos son MCAR. Tercero, examine los patrones de datos faltantes visualmente y no encontre clusters sistematicos. Aunque estas pruebas no pueden probar MCAR definitivamente, proporcionan evidencia solida que apoya el supuesto MCAR."
Pregunta: "No perdiste poder estadistico al eliminar casos?"
Respuesta: "Si, la eliminacion listwise redujo mi muestra de 300 a 264, una reduccion del 12%. Sin embargo, el analisis de poder post-hoc usando G*Power mostro que con n equals 264, aun alcance un poder de 0.87 para detectar tamanos de efecto medianos (d equals 0.5) con alfa equals .05. Esto supera el umbral convencional de 0.80, indicando poder adecuado para mis analisis primarios. Los enfoques alternativos (imputacion por media) habrian preservado el tamano de muestra pero introducido sesgos diferentes, particularmente para analisis de correlacion y regresion."
Preguntas Frecuentes
Proximos Pasos
Ahora tienes un framework completo para manejar datos faltantes en el analisis de encuestas en Excel. La clave para el exito de tu tesis no es evitar los datos faltantes (imposible en investigacion real), sino manejarlos de forma transparente y apropiada para tu escenario especifico.
Antes de finalizar tu enfoque:
-
Diagnostica tu patron de datos faltantes usando las pruebas descritas en esta guia. No asumas que es aleatorio.
-
Elige el metodo que coincida con tu patron y tipo de variable usando el diagrama de decision. Diferentes variables pueden requerir diferentes enfoques.
-
Documenta todo en tu seccion de Metodos. Tu comite necesita ver que tomaste decisiones informadas y defendibles.
-
Ejecuta analisis de sensibilidad comparando resultados con diferentes metodos de datos faltantes. Si las conclusiones no cambian, tienes evidencia de robustez.
-
Consulta a tu asesor si tienes mas del 10% de datos faltantes o evidencia de patrones NMAR. Algunas situaciones requieren tecnicas avanzadas mas alla de Excel.
Los datos faltantes no tienen que descarrilar tu tesis. Con el enfoque correcto, puedes producir resultados validos y defendibles incluso con datos imperfectos.
Para continuar con tu analisis de encuestas, aprende a calcular el tamano del efecto en Excel para cuantificar la magnitud de tus hallazgos, o revisa los errores comunes en analisis de encuestas para evitar otras amenazas a la validez de tu investigacion.
Referencias
American Psychological Association. (2020). Publication Manual of the American Psychological Association (7th ed.). American Psychological Association.
Schafer, J. L., & Graham, J. W. (2002). Missing data: Our view of the state of the art. Psychological Methods, 7(2), 147-177.
Little, R. J. A., & Rubin, D. B. (2019). Statistical Analysis with Missing Data (3rd ed.). Wiley.
Enders, C. K. (2010). Applied Missing Data Analysis. Guilford Press.