คุณเก็บข้อมูลจากแบบสอบถามสำหรับวิทยานิพนธ์เสร็จแล้ว แต่พอเปิดดูก็พบว่าบางคนข้ามคำถามไป หรือบางคนก็ทิ้งแบบสอบถามไปเลย ไม่ต้องกังวลนะ เพราะนักศึกษาเกือบทุกคนเจอปัญหานี้เมื่อวิเคราะห์ข้อมูลแบบสอบถามใน Excel คำถามไม่ใช่ว่าคุณจะมีข้อมูลหายหรือเปล่า แต่คือคุณจะจัดการมันยังไงให้ถูกต้องสำหรับวิทยานิพนธ์
ข้อมูลหายทำให้:
- ผลการทดสอบเชื่อถือได้น้อยลง เพราะข้อมูลน้อยลง
- ผลวิจัยอาจบิดเบือน ถ้าบางกลุ่มมีข้อมูลหายเยอะกว่ากลุ่มอื่น
- อาจารย์ที่ปรึกษาจะถามแน่ คุณต้องอธิบายได้ว่าจัดการยังไง
ความถูกต้องของผลการวิจัย: อาจารย์ที่ปรึกษารู้ดีว่าการจัดการข้อมูลหายส่งผลต่อความถูกต้องของการทดสอบทางสถิติทุกตัว ไม่ว่าจะเป็นค่าสหสัมพันธ์ t-test ANOVA หรือการวิเคราะห์ถดถอย ล้วนให้ผลต่างกันไปตามวิธีที่คุณจัดการข้อมูลหาย ถ้าคุณจัดการผิด ผลการวิจัยทั้งหมดจะถูกตั้งคำถาม
ข่าวดีก็คือ Excel มีเครื่องมือที่ใช้จัดการข้อมูลหายได้ดี คู่มือนี้จะสอนให้คุณใช้มันสำหรับวิทยานิพนธ์ได้
คุณจะได้เรียนรู้:
- วิธีเช็คว่าข้อมูลหายเป็นแบบไหน (MCAR, MAR, NMAR) ใน Excel
- 4 วิธีจัดการข้อมูลหายพร้อมสูตร Excel ทีละขั้นตอน
- วิธีเลือกว่าควรใช้วิธีไหนสำหรับวิทยานิพนธ์ของคุณ
- วิธีรายงานข้อมูลหายในรูปแบบ APA สำหรับบทที่ 3
- ตัวอย่างสถานการณ์จริงจากวิทยานิพนธ์และวิธีแก้
มาดูกันว่าจะจัดการข้อมูลหายยังไงให้ไม่ทำลายความถูกต้องของวิทยานิพนธ์
ทำความเข้าใจประเภทของข้อมูลหาย (MCAR, MAR, NMAR)
ก่อนจะเลือกวิธีจัดการ คุณต้องเข้าใจก่อนว่าทำไมข้อมูลถึงหาย เพราะมันจะบอกว่าควรใช้วิธีไหน
1. MCAR: Missing Completely at Random (หายแบบสุ่มจริงๆ)
ข้อมูลหายไปไม่เกี่ยวกับอะไรเลย สุ่มจริงๆ
ตัวอย่าง: คนตอบแบบสอบถามออนไลน์อยู่ แล้ว WiFi หลุด การหลุดนี้ไม่เกี่ยวกับคำตอบเรื่องความพึงพอใจในการทำงานของเขาเลย
วิธีเช็ค MCAR ใน Excel:
- สร้างคอลัมน์ "Missing_Flag" สำหรับแต่ละตัวแปร:
=IF(ISBLANK(C2), 1, 0)- รัน t-test เปรียบเทียบคนที่ตอบครบกับคนที่ไม่ครบ:
- ถ้าคนที่ข้ามคำถาม 5 มีคำตอบคำถาม 1-4 คล้ายกับคนที่ตอบครบ ก็น่าจะเป็น MCAR
- ถ้าสองกลุ่มต่างกันมาก ไม่ใช่ MCAR
การทดสอบทางสถิติ: Little's MCAR Test (ต้องใช้ SPSS หรือ R นะ Excel ไม่มี)
สำหรับวิทยานิพนธ์: ข้อมูล MCAR จัดการง่ายที่สุด วิธีส่วนใหญ่ใช้ได้หมดโดยไม่ทำให้เกิดอคติ
2. MAR: Missing at Random (หายแบบสุ่ม แต่เกี่ยวกับตัวแปรอื่น)
ข้อมูลหายเกี่ยวกับตัวแปรอื่นที่เราเห็น แต่ไม่เกี่ยวกับค่าที่หายเอง
ตัวอย่าง: ผู้ชายมักข้ามคำถามเรื่องสุขภาพจิตเพราะรู้สึกอาย ไม่ใช่เพราะสุขภาพจิตแย่กว่า การหายเกี่ยวกับเพศ (ที่เราเห็น) ไม่เกี่ยวกับคะแนนสุขภาพจิต (ที่หาย)
วิธีเช็ค MAR ใน Excel:
- สร้าง Pivot Table เปรียบเทียบอัตราข้อมูลหายระหว่างกลุ่ม:
- เลือกข้อมูล → Insert → PivotTable
- Rows: เพศ (หรือตัวแปรประชากรอื่น)
- Values: Count of Missing_Flag
- ถ้าบางกลุ่มมีข้อมูลหายเยอะกว่า ก็น่าจะเป็น MAR
สำหรับวิทยานิพนธ์: ข้อมูล MAR จัดการได้ด้วย imputation หรือ listwise deletion แต่ต้องรายงานรูปแบบการหายด้วย
3. NMAR: Not Missing at Random (ไม่หายแบบสุ่ม)
ข้อมูลหายเกี่ยวกับค่าที่หายเอง
ตัวอย่าง: คนที่วิตกกังวลสูงมักข้ามแบบวัดความวิตกกังวล เพราะคิดเรื่องนี้แล้วไม่สบายใจ การหายเกี่ยวกับระดับความวิตกกังวลโดยตรง (ค่าที่หาย)
วิธีสังเกต NMAR ใน Excel:
ยากที่จะเช็คได้ชัดเจน แต่ให้สงสัยเมื่อ:
- คำถามละเอียดอ่อน (รายได้ สุขภาพจิต พฤติกรรมเบี่ยงเบน) มีข้อมูลหายเยอะ
- ข้อท้ายๆ ในแบบสอบถามหายเยอะ (เพราะเหนื่อย)
- คนที่มีคะแนนสุดโต่งในตัวแปรคล้ายกันมีข้อมูลหายเยอะ
สำหรับวิทยานิพนธ์: ข้อมูล NMAR ค่อนข้างยุ่งยาก อาจต้องใช้เทคนิคขั้นสูง เช่น multiple imputation หรือต้องทำ sensitivity analysis
หมายเหตุเรื่องการตั้งค่าภูมิภาค: สูตร Excel ใช้ตัวคั่นที่แตกต่างกันขึ้นอยู่กับการตั้งค่าภูมิภาค Excel ในสหรัฐ/UK ใช้เครื่องหมายจุลภาค:
=IF(ISBLANK(A1),0,A1)ในขณะที่ Excel ในยุโรปใช้เครื่องหมายอัฒภาค:=IF(ISBLANK(A1);0;A1)ถ้าสูตรแสดงข้อผิดพลาด ลองเปลี่ยนเครื่องหมายจุลภาคเป็นอัฒภาค (หรือกลับกัน) วิธีตรวจสอบหรือเปลี่ยนการตั้งค่า:
- Windows: File → Options → Advanced → Editing options → "Use system separators"
- Mac: System Preferences → Language & Region → Advanced → Number separators
วิธีที่ 1: Listwise Deletion (ลบคนที่ตอบไม่ครบออก)
ใช้เมื่อ:
- ข้อมูลหาย น้อยกว่า 5%
- ข้อมูลเป็น MCAR (เช็คแล้วจากข้างบน)
- กลุ่มตัวอย่างใหญ่พอ ที่จะลบบางคนออกได้
ไม่ควรใช้เมื่อ:
- ข้อมูลหายเกิน 10% (เสียอำนาจทางสถิติเยอะ)
- ข้อมูลเป็น MAR หรือ NMAR (จะเกิดอคติ)
- กลุ่มตัวอย่างเล็ก (ทุกคนมีค่า)
ขั้นตอน Excel สำหรับ Listwise Deletion
ขั้นตอนที่ 1: หาว่าแถวไหนมีข้อมูลหาย
ก่อนอื่น ต้องหาว่าแถวไหนมีค่าหายในตัวแปรสำคัญที่จะวิเคราะห์

รูปที่ 1: ชุดข้อมูลแบบสำรวจที่มีข้อมูลหายใน Excel - ช่องว่างที่บ่งบอกคำตอบที่หาย
สร้างคอลัมน์ช่วยเพื่อนับช่องว่างในแต่ละแถว:
=COUNTBLANK(B2:Y2)
รูปที่ 2: สูตร COUNTBLANK ใน Excel เพื่อหาแถวที่มีข้อมูลหาย - คอลัมน์ช่วยแสดงจำนวนช่องว่าง
โดย B2:Y2 คือคอลัมน์ตัวแปรของคุณ ลากสูตรลงสำหรับทุกแถว
ขั้นตอนที่ 2: กรองเอาเฉพาะคนที่ตอบครบ
ใช้ฟังก์ชัน FILTER สร้างชุดข้อมูลที่สะอาด:
=FILTER(A2:Y1000, Z2:Z1000=0, "ไม่มีคนตอบครบ")
รูปที่ 3: สูตร FILTER ใน Excel สร้างชุดข้อมูลที่มีเฉพาะคนที่ตอบครบ - ไม่มีข้อมูลหาย
โดย:
- A2:Y1000 = ข้อมูลทั้งหมดของคุณ
- Z2:Z1000 = คอลัมน์ COUNTBLANK
- 0 = เก็บเฉพาะแถวที่ไม่มีช่องว่าง
ขั้นตอนที่ 3: คัดลอกข้อมูลที่กรองแล้วไปชีตใหม่
- เลือกผลลัพธ์ FILTER
- Copy → Paste Special → Values
- ตั้งชื่อชีตว่า "Complete_Cases"
ขั้นตอนที่ 4: วิเคราะห์ข้อมูลที่สมบูรณ์
รันการทดสอบทางสถิติทั้งหมด (Cronbach's Alpha, สถิติเชิงพรรณนา, t-test, ANOVA, correlation) กับชุดข้อมูลที่กรองแล้วนี้เท่านั้น
การรายงาน APA สำหรับ Listwise Deletion
ในบทที่ 3 (Methods) ให้เขียนแบบนี้:
การวิเคราะห์ข้อมูลหายพบว่า 8.2% (n = 37) มีคำตอบหายอย่างน้อย 1 ข้อ Little's MCAR test บ่งชี้ว่าข้อมูลหายแบบสุ่ม χ²(84) = 92.14, p = .26 ใช้ listwise deletion ทำให้กลุ่มตัวอย่างสุดท้ายเป็น n = 413 (91.8% ของกลุ่มตัวอย่างเดิม) Sensitivity analysis เปรียบเทียบลักษณะประชากรของคนที่ตอบครบกับไม่ครบ ไม่พบความแตกต่างที่มีนัยสำคัญ (ทุก p > .05) สนับสนุนข้อสมมติ MCAR
สิ่งสำคัญที่ต้องรายงาน:
- เปอร์เซ็นต์และจำนวนคนที่มีข้อมูลหาย
- ผลการทดสอบ MCAR (ถ้ามี)
- จำนวนกลุ่มตัวอย่างสุดท้ายหลังลบ
- การเปรียบเทียบคนที่ตอบครบกับไม่ครบ - ใช้ t-test เปรียบเทียบค่าเฉลี่ยของตัวแปรที่สังเกตได้
วิธีที่ 2: Mean/Median Imputation (เติมด้วยค่าเฉลี่ย/มัธยฐาน)
ใช้เมื่อ:
- ข้อมูลหาย 5-10% (เยอะไปสำหรับลบ แต่น้อยพอสำหรับเติม)
- ข้อมูลเป็น MCAR หรือ MAR
- เป็นตัวแปร Likert หรือตัวแปรต่อเนื่อง (ไม่ใช่หมวดหมู่)
- ต้องการรักษาจำนวนกลุ่มตัวอย่าง
ไม่ควรใช้เมื่อ:
- ข้อมูลหายเกิน 10% (ทำให้ความแปรปรวนลดลงเยอะ)
- เป็นข้อมูลหมวดหมู่ (เพศ อาชีพ หาค่าเฉลี่ยไม่ได้)
- เป็นตัวแปรหลักในการวิเคราะห์ (ทำให้ความสัมพันธ์อ่อนลง)
ขั้นตอน Excel สำหรับ Mean Imputation
ขั้นตอนที่ 1: คำนวณค่าเฉลี่ยสำหรับแต่ละตัวแปร
ในเซลล์ด้านบน (เช่น แถว 1):
=AVERAGE(C2:C1000)สูตรนี้คำนวณค่าเฉลี่ยของค่าที่ไม่ว่างในคอลัมน์ C (เช่น คำถามที่ 1)
ขั้นตอนที่ 2: แทนที่ช่องว่างด้วยค่าเฉลี่ย
สร้างคอลัมน์ใหม่โดยใช้ IF + ISBLANK:
=IF(ISBLANK(C2), $C$1, C2)
รูปที่ 4: สูตร IF ISBLANK ใน Excel แทนที่ค่าหายด้วยค่าเฉลี่ยสำหรับ imputation
โดย:
- C2 = เซลล์เดิม
- 1 = เซลล์ค่าเฉลี่ย (ใส่ $ เพื่อล็อคตำแหน่ง)
- ถ้า C2 ว่าง ใช้ค่าเฉลี่ย ถ้าไม่ว่าง ใช้ค่าเดิม
ขั้นตอนที่ 3: ลากสูตรลง
คัดลอกสูตรสำหรับทุกแถวและคอลัมน์
Median Imputation (สำหรับข้อมูลที่เบ้)
ถ้าข้อมูลมีค่าสุดโต่ง (outliers) มัธยฐานจะดีกว่าค่าเฉลี่ย
สูตร:
=MEDIAN(C2:C1000)แล้วใช้ IF เหมือนเดิม:
=IF(ISBLANK(C2), $C$1, C2)โดย 1 ตอนนี้เป็นมัธยฐาน
ใช้มัธยฐานเมื่อ:
- ระดับ Likert ที่มีค่าสุดโต่ง (ส่วนใหญ่ตอบ 4-5 แต่บางคนตอบ 1)
- ข้อมูลรายได้หรืออายุ (มักเบ้)
- ตัวแปรใดๆ ที่ outliers จะทำให้ค่าเฉลี่ยผิดเพี้ยน
การรายงาน APA สำหรับ Mean Imputation
ข้อมูลหายอยู่ระหว่าง 2.3% (ตัวแปร X) ถึง 9.1% (ตัวแปร Y) Little's MCAR test บ่งชี้ว่าข้อมูลหายแบบสุ่ม χ²(112) = 118.45, p = .32 ใช้ mean imputation สำหรับข้อ Likert โดยใช้ค่าเฉลี่ยเฉพาะตัวแปรที่คำนวณจากคนที่ตอบ Sensitivity analysis เปรียบเทียบผลลัพธ์ระหว่าง listwise deletion กับ mean imputation ไม่พบความแตกต่างสำคัญในผลการถดถอย (ความแตกต่าง β < .03, ทุก p > .05) สนับสนุนความแข็งแกร่งของข้อสรุป
สิ่งสำคัญที่ต้องรายงาน:
- ช่วงของข้อมูลหายในแต่ละตัวแปร
- เหตุผลที่เลือก mean imputation
- Sensitivity analysis เปรียบเทียบผลลัพธ์แบบเติมกับไม่เติม
- ผลกระทบต่อความแปรปรวน (เช่น "SD ลดลงน้อยกว่า 5%")
วิธีที่ 3: Forward/Backward Fill (สำหรับข้อมูลระยะยาว)
ใช้เมื่อ:
- เป็นข้อมูลระยะยาว (วัดซ้ำหลายครั้ง)
- คาดว่าค่าจะคงที่ในตัวแปรนั้น (เช่น ประชากร กลุ่มการรักษา)
- คนทิ้งแบบสอบถามตอนท้ายๆ (หายตรงการติดตามครั้งสุดท้าย)
ไม่ควรใช้เมื่อ:
- เป็นข้อมูล cross-sectional (วัดครั้งเดียว)
- ตัวแปรที่เปลี่ยนเร็ว (อารมณ์ อาการ)
- ข้อมูลหายตอนต้น (ไม่มีค่าก่อนหน้าให้คัดลอก)
ขั้นตอน Excel สำหรับ Forward Fill (LOCF)
สถานการณ์: คุณมีข้อมูลรายเดือนตั้งแต่มกราคมถึงมิถุนายน บางคนทิ้งไปในเดือนพฤษภาคม คุณต้องการ "คัดลอกไปข้างหน้า" ค่าล่าสุดของเขา
ขั้นตอนที่ 1: ตั้งค่าข้อมูล
| ID | ม.ค. | ก.พ. | มี.ค. | เม.ย. | พ.ค. | มิ.ย. |
|---|---|---|---|---|---|---|
| 001 | 25 | 27 | 26 | 28 | ||
| 002 | 30 | 29 | 31 | 30 | 32 | 31 |
ตารางที่ 1: ข้อมูลรายเดือนที่มีค่าขาดหายของผู้เข้าร่วมการศึกษา
ขั้นตอนที่ 2: สูตร Forward Fill
ในคอลัมน์พฤษภาคม (E2):
=IF(ISBLANK(E2), D2, E2)หมายความว่า: ถ้าพฤษภาคมว่าง ใช้ค่าจากเมษายน (D2) ถ้าไม่ว่าง ใช้ค่าพฤษภาคม
ขั้นตอนที่ 3: ขยายไปหลายเดือน
สำหรับมิถุนายน (F2):
=IF(ISBLANK(F2), E2, F2)สูตรนี้ต่อจากการเติมก่อนหน้า ถ้าพฤษภาคมก็ว่าง ก็คัดลอกจากเมษายน
สูตร Backward Fill
ใช้เมื่อต้องการ "คัดลอกย้อนกลับ" จากค่าที่มีทีหลัง
=IF(ISBLANK(C2), D2, C2)หมายความว่า: ถ้ามีนาคมว่าง ใช้เมษายน ถ้าไม่ว่าง ใช้มีนาคม
ใช้ในวิทยานิพนธ์เมื่อ: คนหายตรงจุดเวลาต้นๆ แต่มีข้อมูลตอนหลัง
สูตรขั้นสูง: Forward Fill พร้อมเช็ค ID
ถ้ามีหลายคนในชีตเดียว ต้องเช็คไม่ให้คัดลอกข้ามคน:
=IF(A2<>A1, C2, IF(ISBLANK(C2), D1, C2))หมายความว่า:
- ถ้า ID เปลี่ยน (A2 ไม่เท่ากับ A1) ไม่เติม เริ่มใหม่
- ถ้า ID เดิมและว่าง ใช้ค่าก่อนหน้า
การรายงาน APA สำหรับ Forward/Backward Fill
สำหรับข้อมูลระยะยาวที่หาย ใช้วิธี Last Observation Carried Forward (LOCF) สำหรับคนที่ทิ้งก่อนการประเมินสุดท้าย (n = 23, 5.1%) LOCF สมมติว่าค่าคงที่หลังทิ้ง ซึ่งสมเหตุสมผลสำหรับลักษณะประชากรและตัวแปรกลุ่ม Sensitivity analysis เปรียบเทียบการวิเคราะห์แบบ intention-to-treat (LOCF) กับการวิเคราะห์เฉพาะคนที่ตอบครบ (n = 427) แสดงผลลัพธ์ที่สอดคล้องกัน (ความแตกต่าง OR < 1.15, ทุก p > .05) สนับสนุนความถูกต้องของข้อสมมติ LOCF
สิ่งสำคัญที่ต้องรายงาน:
- จำนวนและเปอร์เซ็นต์คนที่ใช้ forward/backward fill
- เหตุผลที่สมมติว่าค่าคงที่
- Sensitivity analysis (LOCF vs. คนที่ตอบครบ)
- ข้อจำกัด (เช่น "LOCF อาจประมาณการปรับปรุงต่ำไป")
วิธีที่ 4: สร้างหมวดหมู่ "หาย" (สำหรับตัวแปรหมวดหมู่)
ใช้เมื่อ:
- เป็นตัวแปรหมวดหมู่ (เพศ อาชีพ ระดับการศึกษา)
- สงสัยว่าการไม่ตอบมีความหมาย (เช่น ไม่ยอมบอกรายได้)
- ต้องการรักษาทุกคนไว้ในการวิเคราะห์
ไม่ควรใช้เมื่อ:
- เป็นตัวแปรต่อเนื่อง (ไม่มี "อายุ = หาย")
- การไม่ตอบเป็นสุ่มจริงๆ (เพิ่มความซับซ้อนโดยไม่จำเป็น)
ขั้นตอน Excel สำหรับหมวดหมู่ "หาย"
สถานการณ์: คุณมีคอลัมน์ "ระดับการศึกษา" ที่มีบางช่องว่าง
ขั้นตอนที่ 1: สูตรสร้างหมวดหมู่ "หาย"
=IF(ISBLANK(E2), "ไม่รายงาน", E2)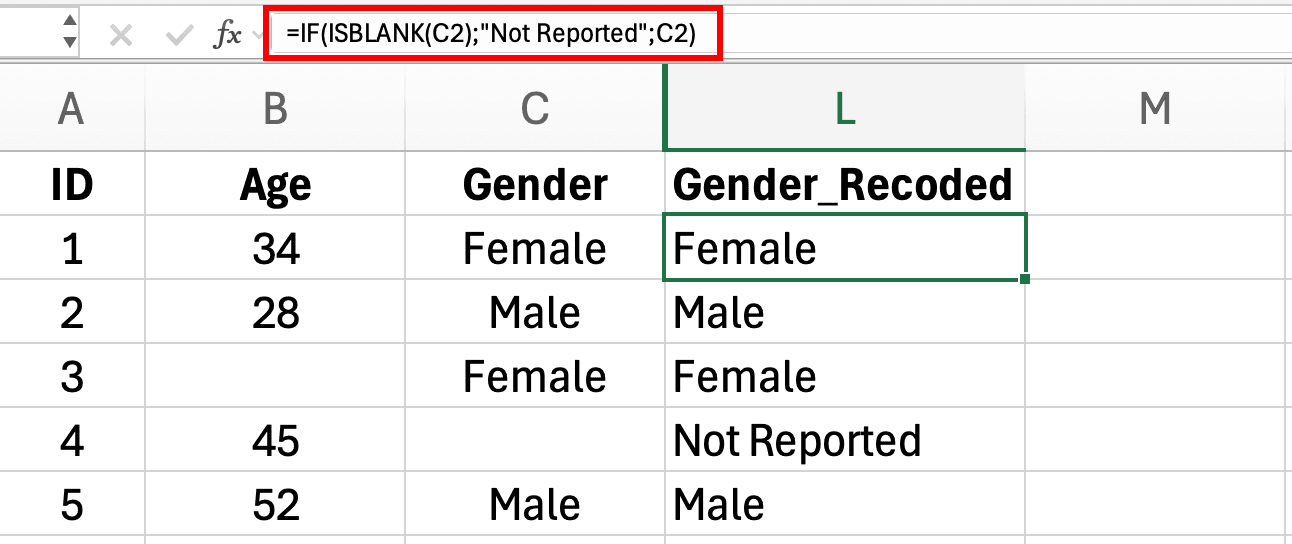
รูปที่ 5: สูตร IF ISBLANK สร้างหมวดหมู่ไม่รายงานสำหรับค่าเพศที่หายใน Excel
สูตรนี้สร้างหมวดหมู่ใหม่ชื่อ "ไม่รายงาน" สำหรับช่องว่าง
ขั้นตอนที่ 2: เช็คการกระจาย
สร้าง Pivot Table:
- Rows: ระดับการศึกษา (รวม "ไม่รายงาน")
- Values: Count
ขั้นตอนที่ 3: รันการวิเคราะห์โดยมี "ไม่รายงาน" เป็นกลุ่มหนึ่ง
เช่น ANOVA หรือ Chi-Square เปรียบเทียบ:
- มัธยมศึกษา
- ปริญญาตรี
- ปริญญาโท
- ไม่รายงาน ← เป็นกลุ่มแยก
การตีความผลลัพธ์กับหมวดหมู่ "หาย"
ถ้ากลุ่ม "ไม่รายงาน" ต่างจากกลุ่มอื่นอย่างมีนัยสำคัญ:
- รายงานรูปแบบนี้ (เช่น "คนที่ไม่รายงานการศึกษามีคะแนนความพึงพอใจต่ำกว่า F(3, 446) = 4.23, p = .006")
- อภิปรายว่าทำไมการหายอาจมีความหมาย (เช่น การศึกษาต่ำ → ลังเลที่จะบอก)
ถ้ากลุ่ม "ไม่รายงาน" ไม่ต่างจากกลุ่มอื่น:
- รายงานว่าไม่มีผลของการไม่ตอบ (สนับสนุน MCAR)
- พิจารณารวมกับกลุ่มอื่นหรือใช้ listwise deletion
การรายงาน APA สำหรับหมวดหมู่ "หาย"
สำหรับตัวแปรประชากรหมวดหมู่ สร้างหมวดหมู่แยก 'ไม่รายงาน' เพื่อรักษาทุกกรณี (ระดับการศึกษา: n = 34 ไม่รายงาน, 7.6%) ANOVA เปรียบเทียบกลุ่มการศึกษาพบว่ากลุ่ม 'ไม่รายงาน' ไม่ต่างจากกลุ่มมัธยมศึกษาในตัวแปรตามอย่างมีนัยสำคัญ F(4, 445) = 2.18, p = .07, η² = .019 Sensitivity analysis ที่ไม่รวมกลุ่ม 'ไม่รายงาน' ได้ผลลัพธ์คล้ายกัน (ความแตกต่าง F < 0.30) บ่งชี้ว่าการรวมไม่ได้ทำให้ข้อสรุปบิดเบือน
สิ่งสำคัญที่ต้องรายงาน:
- จำนวนและเปอร์เซ็นต์ในหมวดหมู่ "ไม่รายงาน"
- การเปรียบเทียบทางสถิติกับกลุ่มอื่น
- Sensitivity analysis (รวม vs. ไม่รวม "ไม่รายงาน")
- การตีความ (ทำไมการหายอาจมีความหมาย)
แผนผังตัดสินใจ: ควรใช้วิธีไหน?
ใช้แผนผังตัดสินใจนี้เพื่อเลือกวิธีจัดการข้อมูลหายที่เหมาะสมสำหรับสถานการณ์เฉพาะของวิทยานิพนธ์ของคุณ

รูปที่ 6: แผนผังตัดสินใจจัดการข้อมูลหาย - เลือกวิธีที่เหมาะสมสำหรับการจัดการข้อมูลหายในการวิเคราะห์แบบสอบถามวิทยานิพนธ์
ทำตามคำถามเหล่านี้เพื่อเลือกวิธีที่เหมาะกับวิทยานิพนธ์ของคุณ:
คำถามที่ 1: ข้อมูลหายกี่เปอร์เซ็นต์?
- น้อยกว่า 5% → ไปคำถามที่ 2
- 5-10% → ไปคำถามที่ 3
- เกิน 10% → ไปคำถามที่ 4
คำถามที่ 2: ข้อมูลเป็น MCAR ไหม? (เช็คด้วยการเปรียบเทียบกลุ่ม)
- ใช่ (MCAR) → ใช้ Listwise Deletion
- ง่าย อาจารย์ยอมรับ อคติน้อย
- ไม่ใช่ (MAR/NMAR) → ไปคำถามที่ 3
คำถามที่ 3: ตัวแปรเป็นตัวเลขต่อเนื่องหรือหมวดหมู่?
- ต่อเนื่อง (Likert อายุ คะแนน) → ไปคำถามที่ 5
- หมวดหมู่ (เพศ อาชีพ) → ใช้หมวดหมู่ "หาย"
- รักษาข้อมูลทั้งหมด ดูรูปแบบการหายได้
คำถามที่ 4: เป็นข้อมูลระยะยาว (วัดซ้ำ) ไหม?
- ใช่ → ใช้ Forward/Backward Fill
- สมมติว่าค่าคงที่ในช่วงเวลา
- ต้องรายงาน sensitivity analysis
- ไม่ใช่ → ไปคำถามที่ 5
คำถามที่ 5: ยอมรับได้ไหมถ้าความแปรปรวนลดลง?
- ยอมรับได้ (ไม่ใช่ตัวแปรหลัก) → ใช้ Mean/Median Imputation
- รักษาจำนวนกลุ่มตัวอย่าง
- ต้องรายงานผลกระทบต่อ SD
- ยอมรับไม่ได้ (ตัวแปรผลลัพธ์หลัก) → พิจารณา Multiple Imputation (ต้องใช้ SPSS/R)
- เกินความสามารถของ Excel ดูคู่มือ วิธีรัน Multiple Imputation ใน R
ตัวอย่างสถานการณ์จริงจากวิทยานิพนธ์
สถานการณ์ที่ 1: คำตอบไม่ครบในระดับ Likert
ปัญหา: คนตอบได้ 8 จาก 10 ข้อในแบบวัดความพึงพอใจในการทำงาน
วิธีแก้:
- ถ้าหายน้อยกว่า 20% ของข้อในแบบวัด: ใช้ค่าเฉลี่ยของคนนั้นเอง
- สูตร:
=IF(ISBLANK(C2), AVERAGE($C2:$L2), C2) - เติมจากคำตอบของคนนั้นในข้ออื่นๆ
- สูตร:
- ถ้าหาย ≥20% ของข้อ: ลบคนนั้นออกจากการคำนวณคะแนนแบบวัด
- คะแนนแบบวัดที่เติมเยอะเกินไปไม่น่าเชื่อถือ
การรายงาน APA:
คนที่มีข้อหายน้อยกว่า 20% ในแบบวัด (n = 47) ถูกเติมด้วยค่าเฉลี่ยของข้อที่คนนั้นตอบ คนที่มีข้อหาย ≥20% (n = 12) ถูกลบออกจากการคำนวณคะแนนแบบวัดเพื่อรักษาความน่าเชื่อถือ (Cronbach's α = .89 สำหรับคนที่ตอบครบ)
สถานการณ์ที่ 2: ข้อมูลประชากรหาย (อายุ เพศ การศึกษา)
ปัญหา: 15 คนไม่บอกอายุ 22 คนไม่บอกการศึกษา
วิธีแก้:
-
สำหรับตัวแปรต่อเนื่อง (อายุ):
- ถ้าอายุไม่ใช่ตัวแปรหลัก → ใช้ mean imputation
- ถ้าอายุเป็นตัวแปรหลัก → รายงาน sensitivity analysis (รวม vs. ไม่รวมอายุหาย)
-
สำหรับตัวแปรหมวดหมู่ (การศึกษา):
- สร้างหมวดหมู่ "ไม่รายงาน" (ดูวิธีที่ 4)
- เช็คว่า "ไม่รายงาน" ต่างจากกลุ่มอื่นไหม
การรายงาน APA:
อายุที่หาย (n = 15, 3.3%) ถูกเติมด้วยอายุเฉลี่ยของกลุ่มตัวอย่าง (M = 34.2) การศึกษาที่หาย (n = 22, 4.9%) ถูกเข้ารหัสเป็น 'ไม่รายงาน' และรวมเป็นกลุ่มแยกในการวิเคราะห์ กลุ่ม 'ไม่รายงาน' ไม่ต่างจากกลุ่มมัธยมศึกษาในตัวแปรตามอย่างมีนัยสำคัญ t(418) = 0.87, p = .39
สถานการณ์ที่ 3: คนทิ้งเยอะตอนท้ายแบบสอบถาม
ปัญหา: คำถาม 30 ข้อแรกหาย 5% คำถาม 10 ข้อสุดท้ายหาย 25%
วิธีแก้:
- หาสาเหตุ: เหนื่อย? คำถามละเอียดอ่อน? ปัญหาเทคนิค?
- ตัวเลือกในการวิเคราะห์:
- ตัวเลือก A: วิเคราะห์คำถามต้นๆ แยกจากคำถามท้ายๆ
- ตัวเลือก B: ใช้ listwise deletion เฉพาะการวิเคราะห์ที่ต้องใช้คำถามท้ายๆ
- ตัวเลือก C: รายงานว่าคำถามท้ายๆ มีอำนาจทางสถิติต่ำ และตีความด้วยความระมัดระวัง
การรายงาน APA:
อัตราการตอบลดลงจาก 95% (คำถาม 1-30) เป็น 75% (คำถาม 31-40) บ่งบอกถึงความเหนื่อยล้าของผู้ตอบ การวิเคราะห์หลักใช้ข้อมูลที่มีครบ (คำถาม 1-30, n = 427) การวิเคราะห์รองที่รวมคำถาม 31-40 ใช้ listwise deletion (n = 337, 75% ของกลุ่มตัวอย่างเดิม) การเปรียบเทียบประชากรระหว่างคนที่ตอบครบกับไม่ครบ ไม่พบความแตกต่างที่มีนัยสำคัญ (ทุก p > .05) สนับสนุนความสามารถในการสรุปทั่วไป
สถานการณ์ที่ 4: ข้อมูลหายสำหรับคำถามละเอียดอ่อน (รายได้ สุขภาพจิต)
ปัญหา: 30% ของคนข้ามคำถามเรื่องรายได้ประจำปี
วิธีแก้:
- ยอมรับว่าข้อมูลน่าจะเป็น NMAR (คนรายได้สูงหรือต่ำมากอาจไม่อยากบอก)
- อย่าใช้ mean imputation จะทำให้เกิดอคติมาก
- ตัวเลือก:
- ตัวเลือก A: รายงานเฉพาะคนที่ตอบ (n = 315) และยอมรับข้อจำกัด
- ตัวเลือก B: สร้างหมวดหมู่รายได้ (ต่ำ/กลาง/สูง/ไม่รายงาน) และวิเคราะห์รูปแบบ
- ตัวเลือก C: ใช้ multiple imputation กับตัวแปรทำนาย (ต้องใช้ SPSS/R)
การรายงาน APA:
รายได้ประจำปีมีอัตราไม่ตอบสูง (30.2%, n = 136) น่าจะเพราะความละเอียดอ่อนของคำถาม เนื่องจากข้อมูลน่าจะเป็น NMAR (คนรายได้สุดโต่งอาจไม่ยอมบอก) จึงไม่ใช้ imputation การวิเคราะห์ที่เกี่ยวกับรายได้รายงานเฉพาะคนที่ตอบ (n = 314) และควรตีความด้วยความระมัดระวังเพราะอาจมีอคติจากการเลือก การเปรียบเทียบคนที่ตอบกับไม่ตอบในตัวแปรอื่น (อายุ เพศ การศึกษา) พบว่าคนไม่ตอบมีแนวโน้มอายุมากกว่า (M = 42.3 vs. 36.1, p = .002) บ่งบอกว่าไม่ใช่การหายแบบสุ่ม
วิธีรายงานข้อมูลหายในวิทยานิพนธ์ (บทที่ 3 Methods APA)
อาจารย์ที่ปรึกษาจะมองหาสิ่งเหล่านี้ในบทที่ 3 ของคุณ:
1. ปริมาณข้อมูลหาย
รายงาน:
- เปอร์เซ็นต์รวมของข้อมูลหาย
- ข้อมูลหายในแต่ละตัวแปร (โดยเฉพาะตัวแปรสำคัญ)
- จำนวนคนที่ได้รับผลกระทบ
ตัวอย่าง:
ข้อมูลหายมีน้อย อยู่ระหว่าง 1.2% (เพศ) ถึง 8.7% (คะแนนความพึงพอใจในการทำงาน) รวมแล้ว 67 จาก 450 คน (14.9%) มีคำตอบหายอย่างน้อย 1 ข้อ
2. รูปแบบข้อมูลหาย (วิเคราะห์ MCAR/MAR/NMAR)
รายงาน:
- ผล Little's MCAR test (ถ้ามี)
- การเปรียบเทียบคนที่ตอบครบกับไม่ครบ
- รูปแบบที่พบ (เช่น บางกลุ่มประชากรมีข้อมูลหายเยอะกว่า)
ตัวอย่าง:
Little's MCAR test บ่งชี้ว่าข้อมูลหายแบบสุ่ม χ²(124) = 132.18, p = .29 การเปรียบเทียบเพิ่มเติมระหว่างคนที่มีข้อมูลครบกับไม่ครบ ไม่พบความแตกต่างที่มีนัยสำคัญในอายุ t(448) = 1.23, p = .22, เพศ χ²(1) = 0.87, p = .35, หรือระดับการศึกษา χ²(3) = 2.45, p = .48
3. วิธีการจัดการที่เลือก
รายงาน:
- วิธีที่ใช้ (listwise deletion, mean imputation ฯลฯ)
- ทำไมถึงเลือกวิธีนั้น (เหตุผล)
- ข้อสมมติที่ใช้
ตัวอย่าง:
เนื่องจากข้อมูลหายน้อย (8.7%) และยืนยันว่าเป็น MCAR จึงใช้ listwise deletion สำหรับการวิเคราะห์หลัก ทำให้กลุ่มตัวอย่างสุดท้ายเป็น n = 383 (85.1% ของกลุ่มตัวอย่างเดิม) รักษาอำนาจทางสถิติที่เพียงพอสำหรับการวิเคราะห์ที่วางแผนไว้ (power = .89 สำหรับการตรวจจับ effect size ขนาดกลางที่ α = .05)
4. Sensitivity Analyses
รายงาน:
- การเปรียบเทียบผลลัพธ์ระหว่างวิธีต่างๆ (เช่น listwise deletion vs. mean imputation)
- ผลลัพธ์เปลี่ยนไปมากไหม
- เหตุผลที่เลือกวิธีสุดท้าย
ตัวอย่าง:
Sensitivity analysis เปรียบเทียบ listwise deletion (n = 383) กับ mean imputation (n = 450) ผลการถดถอยแสดงรูปแบบที่สอดคล้องกัน: listwise deletion β = .34, p < .001; mean imputation β = .32, p < .001 เนื่องจากความแตกต่างน้อย (Δβ = .02) และความแข็งแกร่งของ listwise deletion ภายใต้ MCAR จึงเลือก listwise deletion สำหรับการวิเคราะห์ที่รายงาน
5. ผลกระทบต่อขนาดกลุ่มตัวอย่างและอำนาจทางสถิติ
รายงาน:
- ขนาดกลุ่มตัวอย่างก่อนและหลังจัดการข้อมูลหาย
- อำนาจทางสถิติยังเพียงพอไหม
- การปรับเปลี่ยนการวิเคราะห์ที่วางแผนไว้
ตัวอย่าง:
กลุ่มตัวอย่างสุดท้าย (n = 383) เกินขนาดเป้าหมายจากการวิเคราะห์อำนาจก่อนหน้า (n = 350 สำหรับการตรวจจับ effect size ขนาดกลางที่ power = .80, α = .05) ดังนั้นการจัดการข้อมูลหายไม่ได้ทำให้อำนาจทางสถิติลดลงสำหรับการทดสอบสมมติฐานที่วางแผนไว้
ตัวอย่างย่อหน้าบทที่ 3 (การจัดการข้อมูลหาย)
นี่คือย่อหน้าตัวอย่างที่คุณปรับใช้ได้:
การจัดการข้อมูลหาย. การวิเคราะห์ข้อมูลเบื้องต้นพบ 14.9% (n = 67) มีคำตอบหายอย่างน้อย 1 ข้อ อยู่ระหว่าง 1.2% (เพศ) ถึง 8.7% (คะแนนความพึงพอใจในการทำงาน) Little's MCAR test บ่งชี้ว่าข้อมูลหายแบบสุ่ม χ²(124) = 132.18, p = .29 การเปรียบเทียบลักษณะประชากรเพิ่มเติมระหว่างคนที่มีข้อมูลครบ (n = 383) กับไม่ครบ (n = 67) ไม่พบความแตกต่างที่มีนัยสำคัญในอายุ t(448) = 1.23, p = .22, เพศ χ²(1) = 0.87, p = .35, หรือระดับการศึกษา χ²(3) = 2.45, p = .48 สนับสนุนข้อสมมติ MCAR
เนื่องจากข้อมูลหายน้อยและยืนยัน MCAR จึงใช้ listwise deletion สำหรับการวิเคราะห์หลัก ทำให้ n = 383 (85.1% ของกลุ่มตัวอย่างเดิม) ขนาดนี้เกินเป้าหมายจากการวิเคราะห์อำนาจก่อนหน้า (n = 350) รับประกันอำนาจทางสถิติที่เพียงพอ (power ที่สังเกตได้ = .89 สำหรับการตรวจจับ effect size ขนาดกลางที่ α = .05)
Sensitivity analysis เปรียบเทียบ listwise deletion กับ mean imputation (n = 450) ผลการถดถอยแสดงรูปแบบที่สอดคล้องกัน (listwise deletion β = .34, p < .001; mean imputation β = .32, p < .001) ความแตกต่างน้อย (Δβ = .02) เนื่องจากความแข็งแกร่งของ listwise deletion ภายใต้ข้อสมมติ MCAR และการป้องกันการลดความแปรปรวนเทียมที่เกี่ยวกับ mean imputation จึงเลือก listwise deletion สำหรับการวิเคราะห์ที่รายงานทั้งหมด
คำถามที่พบบ่อย (FAQ)
ขั้นตอนต่อไป
ตอนนี้คุณรู้วิธีจัดการข้อมูลหายใน Excel สำหรับวิทยานิพนธ์แล้ว ทำตามขั้นตอนนี้ต่อได้เลย:
1. วินิจฉัยข้อมูลหายของคุณ
- คำนวณเปอร์เซ็นต์ข้อมูลหายในแต่ละตัวแปร
- เช็ค MCAR ด้วยการเปรียบเทียบกลุ่ม
- ดูรูปแบบ (บางกลุ่มประชากรหายเยอะกว่าไหม?)
2. เลือกวิธีที่เหมาะสม
- ใช้แผนผังตัดสินใจจากคู่มือนี้
- จดเหตุผลที่เลือก
- เตรียม sensitivity analysis
3. ทำใน Excel
- ใช้สูตรทีละขั้นตอนจากคู่มือนี้
- สร้างชีตแยกสำหรับข้อมูลเดิมกับข้อมูลที่จัดการแล้ว
- เก็บบันทึกสิ่งที่เปลี่ยน (audit trail)
4. รายงานในวิทยานิพนธ์
- เขียนบทที่ 3 ตามแม่แบบ APA จากคู่มือนี้
- รวม sensitivity analysis ในผลลัพธ์
- อภิปรายข้อจำกัดในบทอภิปราย
5. เรียนรู้เพิ่มเติม
สำหรับขั้นตอนถัดไปในการวิเคราะห์แบบสอบถาม เรียนรู้วิธีรายงานสถิติเชิงพรรณนาในรูปแบบ APA หรือดูข้อผิดพลาดทั่วไปในการวิเคราะห์แบบสอบถาม เพื่อหลีกเลี่ยงปัญหาความถูกต้องอื่นๆ
ถ้าต้องใช้เทคนิคที่เกิน Excel:
- วิธีนำเข้าไฟล์ CSV ใน R - เริ่มต้นกับ R สำหรับ multiple imputation
- วิธีติดตั้ง PROCESS Macro ใน SPSS - จัดการข้อมูลหายในโมเดล mediation/moderation
มีคำถามเกี่ยวกับการจัดการข้อมูลหายสำหรับวิทยานิพนธ์ของคุณไหม? ทิ้งความคิดเห็นด้านล่าง แล้วฉันจะตอบด้วยคำแนะนำที่เหมาะกับสถานการณ์ของคุณ!
อ้างอิง
American Psychological Association. (2020). Publication Manual of the American Psychological Association (7th ed.). American Psychological Association.
Schafer, J. L., & Graham, J. W. (2002). Missing data: Our view of the state of the art. Psychological Methods, 7(2), 147-177.
Little, R. J. A., & Rubin, D. B. (2019). Statistical Analysis with Missing Data (3rd ed.). Wiley.
Enders, C. K. (2010). Applied Missing Data Analysis. Guilford Press.