Ai terminat de colectat datele din chestionar pentru lucrarea de licență. Acum te uiți la un tabel Excel plin de numere și te întrebi ce urmează. Acesta este punctul în care majoritatea studenților se blochează.
Vestea bună este că Excel are tot ce ai nevoie pentru a analiza corect datele din chestionar. Nu ai nevoie de software scump precum SPSS. Cu metodele potrivite, poți calcula fiabilitatea, analiza statistici descriptive, testa ipoteze și formata rezultatele pentru lucrarea ta folosind instrumentele pe care le ai deja.
Acest ghid te va conduce prin întregul proces de analiză a datelor din chestionar în Excel. Vei învăța cum să pregătești datele, să verifici fiabilitatea cu Cronbach's Alpha, să calculezi statistici descriptive, să alegi testele statistice potrivite și să scrii rezultatele în format APA. La finalul acestui articol, vei avea un workflow clar de la datele brute din chestionar până la rezultate gata de inclus în lucrare.
Ce vei învăța:
- Cum să organizezi și să curăți datele din chestionar înainte de analiză
- Să calculezi Cronbach's Alpha pentru a verifica fiabilitatea scalelor
- Să calculezi statistici descriptive pentru date de tip Likert
- Să alegi și să aplici testele statistice potrivite
- Să creezi tabele de frecvență și tabele încrucișate
- Să scrii rezultatele statistice în format APA
Pentru a urma acest tutorial, descarcă Survey Analysis Excel Template din secțiunea Descărcări de pe bara laterală.
cta: sample-size
Ce este analiza datelor din chestionar?
Analiza datelor din chestionar este procesul de transformare a răspunsurilor din chestionar în informații semnificative care răspund la întrebările tale de cercetare. Pentru studenții care lucrează la licență sau disertație, acest proces include de obicei calcularea valorilor de fiabilitate, rezumarea tiparelor de răspuns și testarea ipotezelor despre relațiile dintre variabile.
Majoritatea chestionarelor academice folosesc scale Likert, unde respondenții evaluează acordul lor cu afirmații de la 1 (dezacord total) la 5 (acord total). Aceste răspunsuri necesită tratament special deoarece sunt date ordinale pe care cercetătorii le tratează adesea ca date de interval în scopuri statistice.
Abordarea ta analitică depinde de obiectivele cercetării:
| Obiectiv de cercetare | Metodă de analiză |
|---|---|
| Descrierea tiparelor de răspuns | Frecvențe, medii, abateri standard |
| Verificarea calității chestionarului | Fiabilitate Cronbach's Alpha |
| Compararea a două grupuri | Testul t pentru eșantioane independente |
| Compararea mai multor grupuri | ANOVA unifactorial |
| Examinarea relațiilor | Corelație Pearson |
| Predicția rezultatelor | Analiza de regresie |
Tabelul 1: Obiective comune de cercetare și metodele lor statistice corespunzătoare
Înainte de a începe calculele, ai nevoie de date structurate corespunzător. Secțiunea următoare explică cum să pregătești datele din chestionar pentru analiză.
cta: sample-size
Pregătirea datelor din chestionar pentru analiză
Datele brute din chestionar nu sunt de obicei gata pentru analiză imediat. Studenții fac adesea greșeli în această etapă care cauzează probleme mai târziu. Timpul investit în organizarea și curățarea corectă a datelor previne probleme viitoare.
Structurarea datelor
Tabelul tău Excel ar trebui să urmeze o structură simplă: fiecare rând reprezintă un respondent, și fiecare coloană reprezintă o întrebare sau variabilă. Primul rând conține anteturile coloanelor cu etichete scurte și clare.
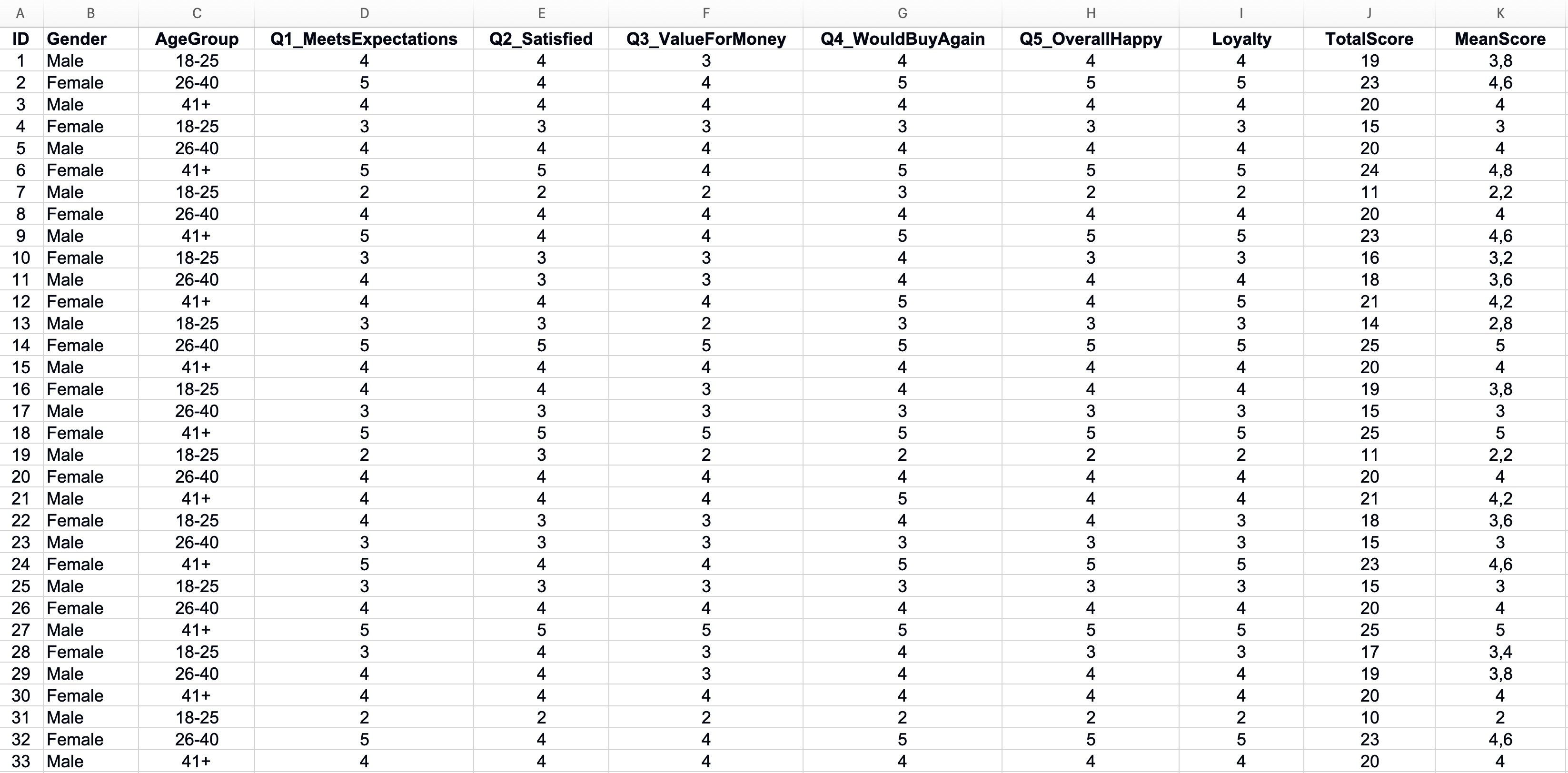 Figura 1: Structura datelor de chestionar organizate corespunzător în Excel
Figura 1: Structura datelor de chestionar organizate corespunzător în Excel
Notă: Setul de date de practică și toate exemplele din acest ghid folosesc nume de coloane în engleză (de exemplu, Gender, AgeGroup, Q1_MeetsExpectations, Loyalty) pentru a urmări standardele internaționale de cercetare și pentru compatibilitate cu software-ul statistic. Aceste nume de variabile vor fi indicate între paranteze de-a lungul ghidului.
Câteva reguli care fac datele gata pentru analiză:
- Folosește coduri numerice pentru răspunsuri (1-5 pentru scale Likert, 1 pentru da și 0 pentru nu)
- Păstrează o singură variabilă per coloană
- Nu îmbina celule și nu adăuga rânduri goale între date
- Folosește codificări consistente (nu amesteca scale 1-5 cu scale 0-4)
Notă pentru utilizatorii Excel din afara SUA: Separatorii din formulele Excel depind de setările regionale ale sistemului. Dacă sistemul tău folosește virgula ca separator zecimal (de exemplu, 3,14 în loc de 3.14), va trebui să folosești punct și virgulă în loc de virgulă în formule. De exemplu, folosește
=COUNTIF(B2:B101;1)în loc de=COUNTIF(B2:B101,1). Toate formulele din acest ghid folosesc formatul american (virgulă). Ajustează conform setărilor tale regionale.
Codificarea variabilelor categoriale
Răspunsurile din chestionar includ adesea date categoriale precum gen (Gender), grup de vârstă (AgeGroup), nivel de educație sau departament. Convertește răspunsurile text în coduri numerice înainte de analiză.
| Răspuns original | Cod numeric |
|---|---|
| Masculin | 1 |
| Feminin | 2 |
| Nespecificat | 3 |
Tabelul 2: Exemplu de codificare a variabilei categoriale pentru răspunsurile de gen
Creează o foaie separată pentru coduri în fișierul tău Excel care documentează ce înseamnă fiecare număr. Această documentație va fi crucială când interpretezi rezultatele și scrii capitolul de metodologie.
Gestionarea itemilor cu scorare inversă
Unele chestionare includ întrebări formulate negativ pentru a detecta respondenții neatenți. Înainte de a calcula scorurile totale ale scalei, trebuie să inversezi codificarea acestor itemi pentru ca toate răspunsurile să indice aceeași direcție.
Pentru o scală Likert de 5 puncte, formula de inversare este:
În Excel, dacă valoarea maximă a scalei este 5 și răspunsul original este în celula B2:
=6-B2Un răspuns de 1 devine 5, un răspuns de 2 devine 4, și așa mai departe. Creează o coloană nouă pentru itemii inversați în loc să suprascrii datele originale.
Identificarea datelor lipsă
Răspunsurile lipsă creează probleme pentru analiza statistică. Înainte de a continua, identifică unde există lacune în setul tău de date.
Folosește funcția COUNTBLANK din Excel pentru a număra celulele goale din fiecare coloană:
=COUNTBLANK(B2:B101)Aceasta îți spune câți respondenți au sărit peste fiecare întrebare. Un număr mic de valori lipsă este normal. Dacă o întrebare are mult mai multe răspunsuri lipsă decât altele, investighează de ce. Întrebarea ar putea fi confuză sau sensibilă.
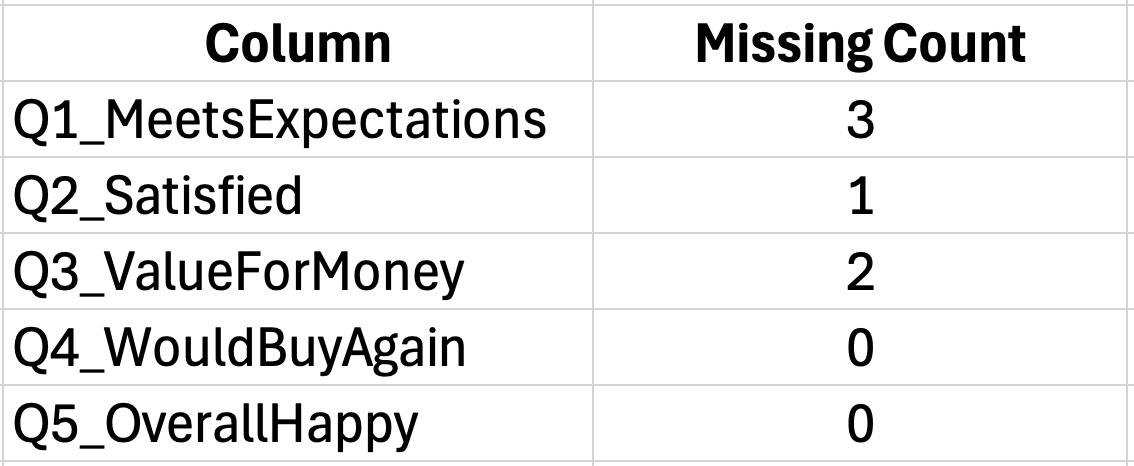 Figura 2: Identificarea datelor lipsă cu funcția COUNTBLANK
Figura 2: Identificarea datelor lipsă cu funcția COUNTBLANK
Pentru cantități mici de date lipsă, ai câteva opțiuni:
- Șterge cazurile cu valori lipsă (listwise deletion)
- Înlocuiește valorile lipsă cu media itemului (mean imputation)
- Lasă-le așa și permite Excel-ului să ignore celulele goale în calcule
Majoritatea îndrumătorilor de lucrări acceptă listwise deletion când răspunsurile lipsă sunt sub 5%. Documentează metoda ta în capitolul de metodologie. Pentru un ghid complet despre gestionarea datelor lipsă cu metode Excel pas cu pas, consultă: Cum să gestionezi datele lipsă în Excel
Calcularea scorurilor totale și pe subscale
Instrumentele din chestionar constau adesea din mai multe subscale care măsoară constructe diferite. Înainte de analiză, calculează scorurile totale pentru fiecare subscală prin însumarea (sau calcularea mediei) itemilor relevanți.
Pentru o scală de „Satisfacție a clienților" cu 5 itemi:
=SUM(B2:F2)Aceasta calculează scorul total pentru respondentul 1 din itemii din coloanele B până la F. Copiază această formulă în jos pentru toți respondenții.
Folosirea AVERAGE în loc de SUM păstrează scorul pe scala originală 1-5, ceea ce face interpretarea mai ușoară:
=AVERAGE(B2:F2) Figura 3: Calcularea scorurilor totale și medii pentru subscale
Figura 3: Calcularea scorurilor totale și medii pentru subscale
Odată ce datele tale sunt pregătite, poți verifica dacă scalele tale măsoară în mod fiabil ceea ce pretind că măsoară.
cta: sample-size
Calculează Mărimea Eșantionului
Folosește calculatorul nostru gratuit pentru a determina mărimea eșantionului necesar folosind Yamane, Cochran și Krejcie & Morgan. Compară cele trei metode și obține o citare APA.
Încearcă CalculatorulVerificarea fiabilității: Cronbach's Alpha în Excel
Înainte de a analiza rezultatele chestionarului, trebuie să confirmi că chestionarul tău funcționează corect. Cronbach's Alpha îți spune dacă itemii din scala ta măsoară în mod consistent același construct. O scală cu fiabilitate scăzută va produce rezultate în care nu poți avea încredere.
Gândește-te astfel: dacă ai măsura aceeași persoană de două ori cu o scală fiabilă, ai obține scoruri similare. O scală nefiabilă ar da rezultate diferite de fiecare dată, făcând imposibilă tragerea concluziilor corecte.
Când să calculezi Cronbach's Alpha
Calculează fiabilitatea pentru scalele multi-item din chestionarul tău. Dacă folosești un instrument deja dezvoltat precum Job Satisfaction Scale sau Customer Loyalty Index, cercetătorii anteriori au stabilit deja fiabilitatea. Totuși, ar trebui să calculezi Alpha pentru eșantionul tău pentru a confirma că scala funcționează în contextul tău.
Ai nevoie de Cronbach's Alpha când:
- Chestionarul tău are mai mulți itemi care măsoară un singur construct
- Plănuiești să însumezi sau să calculezi media itemilor într-un scor de scală
- Trebuie să demonstrezi că instrumentul tău este de încredere
Nu ai nevoie de el pentru:
- Scale cu un singur item (o întrebare per construct)
- Întrebări demografice
- Întrebări factuale cu răspunsuri concrete
Formula Cronbach's Alpha
Cronbach's Alpha variază de la 0 la 1. Valorile mai mari indică o consistență internă mai puternică între itemii scalei. Formula este:
Unde:
- K este egal cu numărul de itemi din scală
- σ²ᵢ este egal cu varianța fiecărui item
- σ²ₜ este egal cu varianța scorului total
Pare complicat, dar Excel face calculul simplu.
Calcul pas cu pas în Excel
Să parcurgem un exemplu cu o scală de satisfacție a clienților de 5 itemi folosind răspunsuri de la 30 de respondenți.
Pasul 1: Calculează varianța fiecărui item
Folosește funcția VAR.S pentru varianța eșantionului. Dacă răspunsurile primului item sunt în coloana B (rândurile 2-31):
=VAR.S(B2:B31)Repetă pentru fiecare coloană de item. Plasează aceste calcule de varianță într-o zonă de sumar sub datele tale.
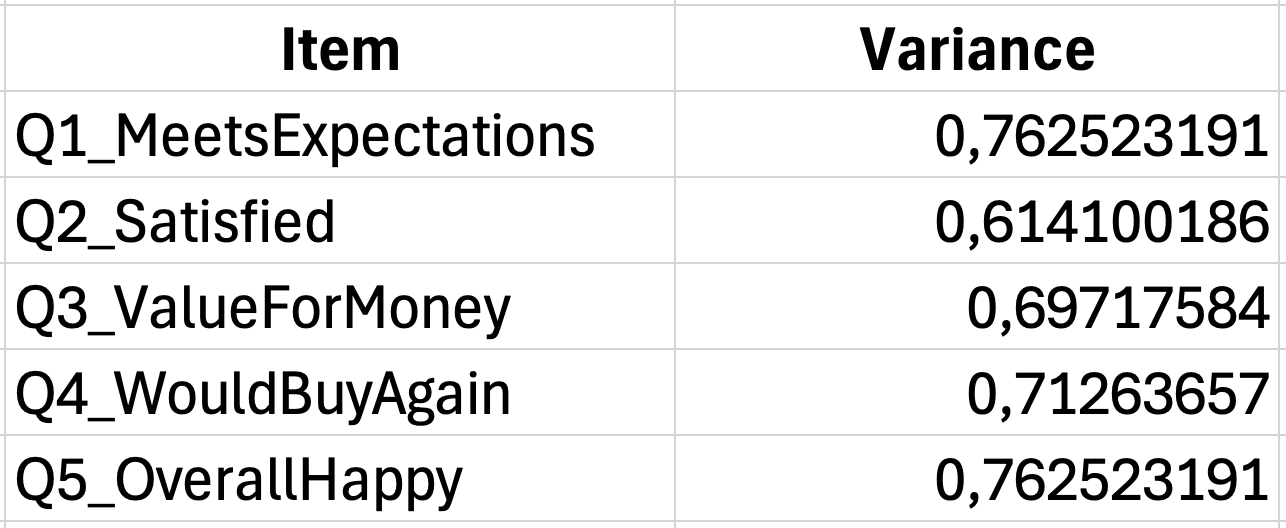 Figura 4: Calcularea varianțelor individuale ale itemilor
Figura 4: Calcularea varianțelor individuale ale itemilor
Pasul 2: Însumează toate varianțele itemilor
Adună toate varianțele individuale ale itemilor:
=SUM(G35:G39)Dacă varianțele itemilor sunt în celulele G35 până la G39, aceasta îți dă suma varianțelor itemilor.
Pasul 3: Calculează varianța scorului total
Mai întâi, calculează scorul total pentru fiecare respondent prin însumarea itemilor:
=SUM(B2:F2)Apoi calculează varianța acestor scoruri totale:
=VAR.S(G2:G31)Pasul 4: Aplică formula Cronbach's Alpha
Cu K egal cu 5 itemi, suma varianțelor itemilor în celula G40, și varianța totală în celula G42:
=(5/4)*(1-(G40/G42))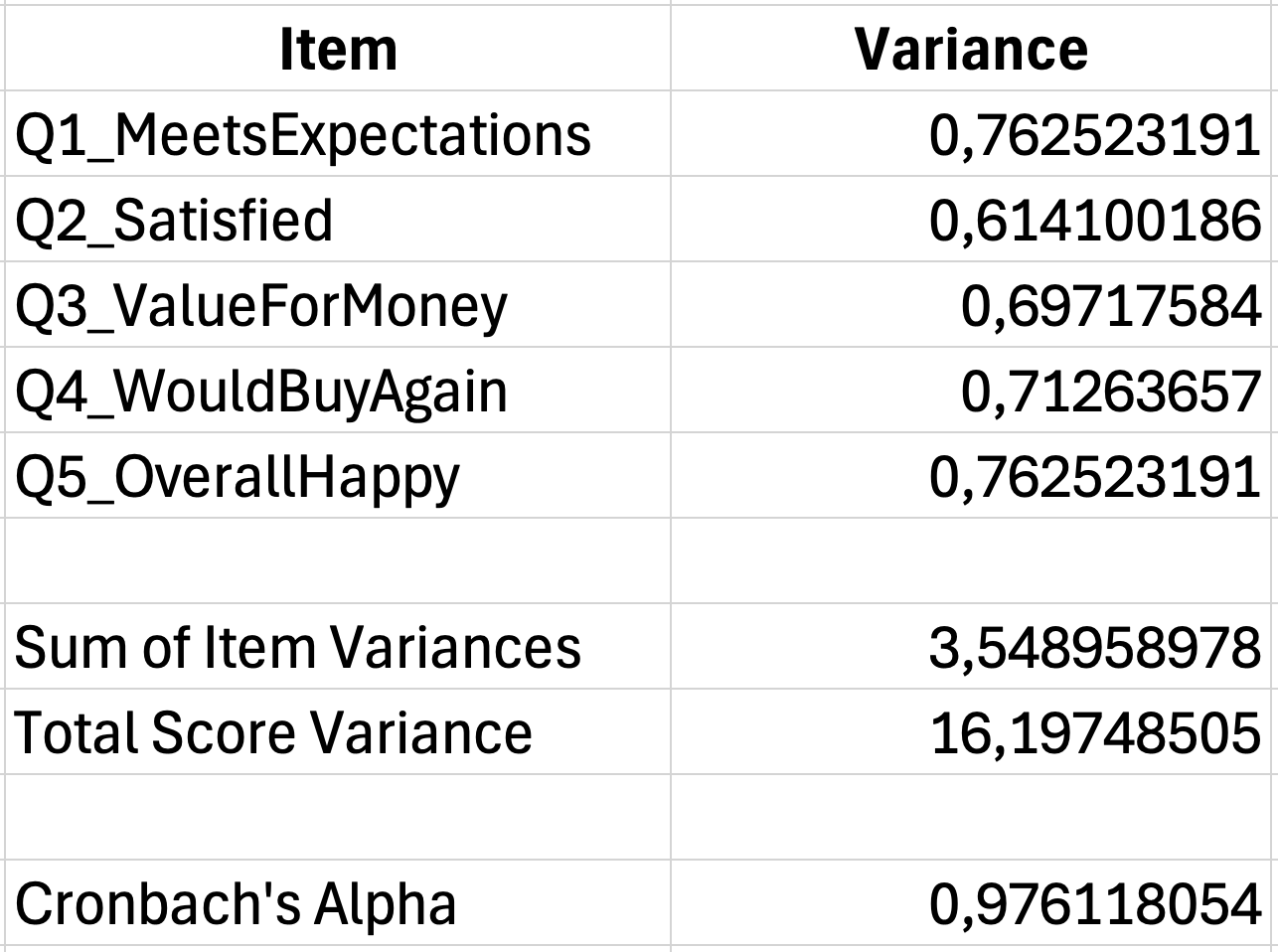 Figura 5: Calculul complet al Cronbach's Alpha (α = 0.78)
Figura 5: Calculul complet al Cronbach's Alpha (α = 0.78)
Interpretarea valorilor Alpha
Odată ce ai coeficientul, folosește acest tabel pentru a interpreta rezultatele:
| Valoare Alpha | Interpretare |
|---|---|
| 0.90 și peste | Excelent |
| 0.80 până la 0.89 | Bun |
| 0.70 până la 0.79 | Acceptabil |
| 0.60 până la 0.69 | Discutabil |
| 0.50 până la 0.59 | Slab |
| Sub 0.50 | Inacceptabil |
Tabelul 3: Linii directoare pentru interpretarea Cronbach's Alpha
Pentru cercetarea de licență/disertație, majoritatea îndrumătorilor se așteaptă la Alpha de 0.70 sau mai mare. Valori între 0.60 și 0.70 pot fi acceptabile pentru cercetare exploratorie sau scale cu mai puțin de 10 itemi (Pallant, 2016).
Pentru un ghid complet cu exemple reale, pași de depanare pentru valori Alpha mici sau mari și șabloane de raportare APA, consultă articolul nostru detaliat despre cum să interpretezi rezultatele Cronbach's Alpha. Când ești gata să redactezi rezultatele, consultă Cum să raportezi Cronbach's Alpha în format APA pentru formatare corectă.
Dacă Alpha ta este sub nivelul acceptabil, ia în considerare:
- Eliminarea itemilor care nu corelează cu ceilalți
- Verificarea itemilor cu scorare inversă pe care e posibil să fi uitat să-i recodifici
- Examinarea dacă constructul este cu adevărat multidimensional
Raportarea fiabilității în lucrare
Include rezultatele testării fiabilității în capitolul de metodologie sau rezultate. Formatul standard APA:
„Scala de satisfacție a clienților a demonstrat consistență internă acceptabilă (Cronbach's α este egal cu 0.78, 5 itemi)."
Pentru scale multiple, prezintă fiabilitatea în format de tabel:
| Scală | Număr de itemi | Cronbach's Alpha |
|---|---|---|
| Satisfacția clienților | 5 | 0.78 |
| Intenția de cumpărare | 4 | 0.84 |
| Loialitatea față de brand | 6 | 0.91 |
Tabelul 4: Exemple de raportare a fiabilității pentru scale multiple
Pentru îndrumări detaliate privind calculul Cronbach's Alpha cu template descărcabil, vezi ghidul nostru complet: Cum să calculezi Cronbach's Alpha în Excel
cta: sample-size
Statistici descriptive pentru datele din chestionar
Odată ce fiabilitatea este confirmată, poți descrie ce arată datele tale. Statisticile descriptive rezumă tiparele de răspuns și ajută cititorii să înțeleagă eșantionul tău înainte de a prezenta statisticile inferențiale.
Pentru datele din chestionar, vei raporta de obicei frecvențe, măsuri ale tendinței centrale (medie, mediană, mod) și măsuri ale dispersiei (abatere standard, interval). Statisticile specifice depind de nivelul de măsurare și de întrebările tale de cercetare.
Crearea tabelelor de frecvență
Tabelele de frecvență arată cum sunt distribuite răspunsurile în categorii. Ele răspund la întrebări precum „Câți respondenți au fost de acord cu această afirmație?" sau „Ce procentaj de participanți a ales fiecare opțiune?"
Folosește funcția COUNTIF pentru a număra răspunsurile pentru fiecare categorie:
=COUNTIF(B2:B101,1)Aceasta numără câți respondenți au selectat „1" (dezacord total) în intervalul B2:B101.
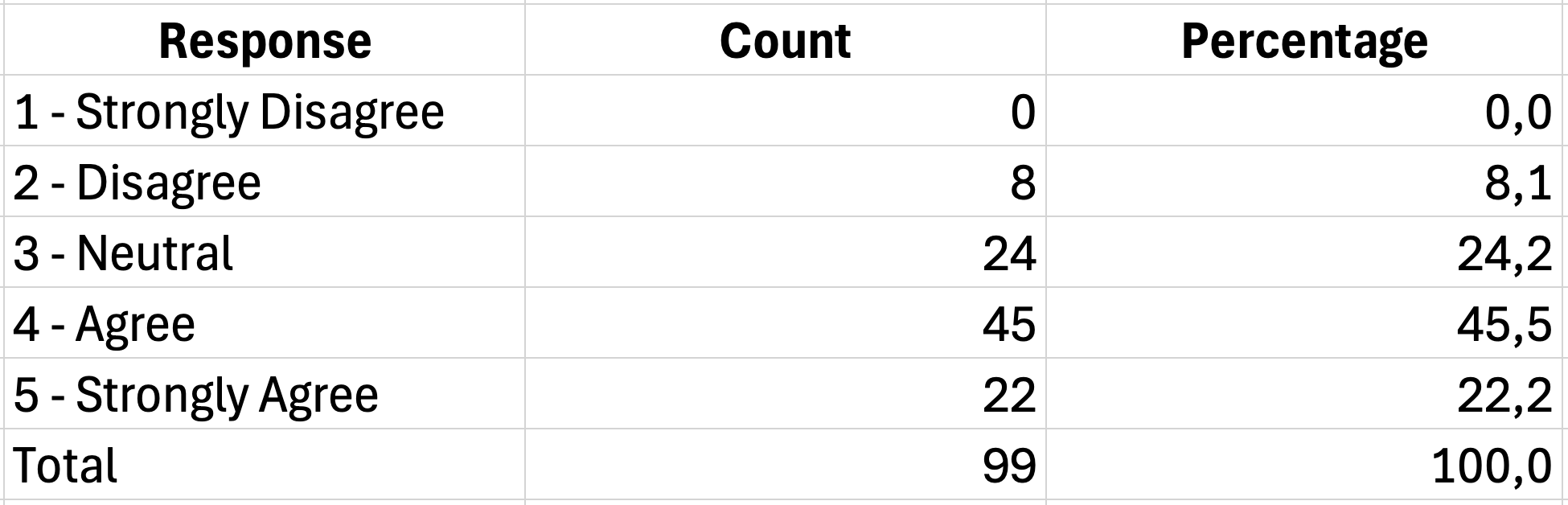 Figura 6: Crearea tabelelor de frecvență cu COUNTIF
Figura 6: Crearea tabelelor de frecvență cu COUNTIF
Pentru a calcula procentajele, împarte fiecare numărătoare la numărul total de răspunsuri:
=D2/SUM($D$2:$D$6)*100Semnele dolar blochează intervalul total astfel încât să poți copia formula în jos fără ca aceasta să se schimbe.
Pentru un tutorial complet despre crearea tabelelor de frecvență, inclusiv frecvențe grupate, procente cumulative și tabelări încrucișate, consultă: Cum să creezi tabele de frecvență în Excel pentru date din chestionar
Un tabel de frecvență complet pentru un item Likert arată astfel:
| Răspuns | Frecvență | Procent |
|---|---|---|
| 1 - Dezacord total | 5 | 5.0% |
| 2 - Dezacord | 12 | 12.0% |
| 3 - Neutru | 28 | 28.0% |
| 4 - Acord | 35 | 35.0% |
| 5 - Acord total | 20 | 20.0% |
| Total | 100 | 100.0% |
Tabelul 5: Tabel de frecvență pentru un item cu scală Likert de 5 puncte
Calcularea mediei și abaterii standard
Pentru datele de tip Likert, cercetătorii raportează de obicei media și abaterea standard. Aceste statistici rezumă tendința centrală și dispersia răspunsurilor.
Media îți spune care a fost răspunsul mediu al tuturor participanților:
=AVERAGE(B2:B101)Abaterea standard indică cât de mult variază răspunsurile față de medie:
=STDEV.S(B2:B101)Folosește STDEV.S (abaterea standard a eșantionului) în loc de STDEV.P pentru că respondenții tăi reprezintă un eșantion dintr-o populație mai mare.
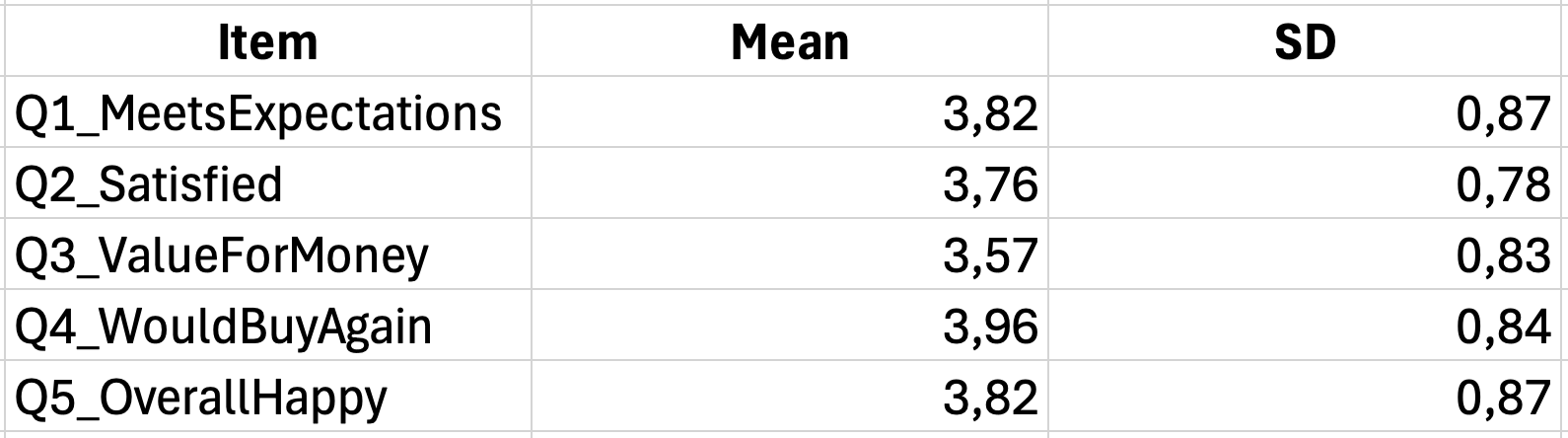 Figura 7: Rezumatul mediilor și deviațiilor standard
Figura 7: Rezumatul mediilor și deviațiilor standard
Rezumarea scorurilor de scală
Odată ce ai calculat scorurile totale sau medii pentru scalele tale, raportează statistici descriptive și pentru aceste scoruri agregate.
Pentru o scală de satisfacție în care ai calculat media itemilor 1-5:
| Măsură | Valoare |
|---|---|
| Medie | 3.67 |
| Abatere standard | 0.82 |
| Minim | 1.40 |
| Maxim | 5.00 |
| Interval | 3.60 |
Tabelul 6: Statistici descriptive sumare pentru scorurile compozite ale scalei
Calculează folosind:
Medie: =AVERAGE(G2:G101)
AS: =STDEV.S(G2:G101)
Min: =MIN(G2:G101)
Max: =MAX(G2:G101)
Interval: =MAX(G2:G101)-MIN(G2:G101)Interpretarea mediilor pe scale Likert
O întrebare frecventă este „Ce înseamnă o medie de 3.67?" Interpretarea depinde de ancorele scalei.
Pentru o scală Likert standard de 5 puncte privind acordul:
| Interval medie | Interpretare |
|---|---|
| 1.00 până la 1.80 | Dezacord total |
| 1.81 până la 2.60 | Dezacord |
| 2.61 până la 3.40 | Neutru |
| 3.41 până la 4.20 | Acord |
| 4.21 până la 5.00 | Acord total |
Tabelul 7: Linii directoare pentru interpretarea mediilor pe scală Likert de 5 puncte
O medie a satisfacției de 3.67 se încadrează în intervalul „Acord", sugerând că respondenții în general au exprimat niveluri pozitive de satisfacție.
Fii prudent să nu interpretezi excesiv diferențe mici. O medie de 3.52 versus 3.48 ar putea să nu reprezinte o diferență semnificativă. Uită-te la abaterile standard și efectuează teste statistice înainte de a pretinde că diferențele sunt semnificative.
Statistici descriptive pe grupuri
Adesea trebuie să compari statisticile descriptive între grupuri, cum ar fi bărbați versus femei sau diferite grupe de vârstă. Creează calcule separate pentru fiecare subgrup.
Funcția AVERAGEIF calculează media pentru un grup specific:
=AVERAGEIF(A2:A101,"Masculin",G2:G101)Aceasta calculează scorul mediu de satisfacție doar pentru respondenții codificați ca „Male" în coloana Gen (Gender).
 Figura 8: Statistici descriptive pe grupuri folosind AVERAGEIF
Figura 8: Statistici descriptive pe grupuri folosind AVERAGEIF
Pentru abaterea standard pe grupuri, va trebui să folosești DSTDEV cu un interval de criterii, sau să filtrezi datele și să calculezi separat.
Formatarea statisticilor descriptive pentru lucrare
Prezintă statisticile descriptive în tabele clare. Formatul APA necesită formatare specifică:
Tabelul 1 Statistici descriptive pentru itemii scalei de satisfacție a clienților
| Item | M | AS |
|---|---|---|
| Produsul a îndeplinit așteptările mele | 3.82 | 0.98 |
| Sunt mulțumit de această achiziție | 3.67 | 1.05 |
| Calitatea corespunde prețului | 3.54 | 1.12 |
| Aș cumpăra din nou acest produs | 3.91 | 0.89 |
| Per total, sunt fericit cu produsul | 3.78 | 0.94 |
| Scor total scală | 3.74 | 0.82 |
Tabelul 8: Statistici descriptive pentru itemii scalei de satisfacție
Notă. N este egal cu 100. Răspunsurile au fost măsurate pe o scală Likert de 5 puncte (1 pentru dezacord total, 5 pentru acord total).
Puncte cheie de formatare:
- Folosește M pentru medie și AS pentru abatere standard
- Raportează două zecimale pentru medii și abateri standard
- Include dimensiunea eșantionului și descrierea scalei în notă
- Scrie titlul tabelului cu italic
Pentru ghiduri complete de formatare APA 7th edition cu șabloane gata de copiat, consultă: Cum să raportezi statisticile descriptive în format APA (Excel)
cta: sample-size
Analiza datelor de tip Likert
Scalele Likert necesită atenție specială deoarece se află într-o zonă gri între date ordinale și de interval. Înțelegerea modului de analiză corectă a acestor răspunsuri previne erori care ar putea invalida rezultatele tale.
Dezbaterea ordinal versus interval
Tehnic, răspunsurile Likert sunt date ordinale. Diferența dintre „acord" și „acord total" ar putea să nu fie egală cu diferența dintre „dezacord" și „neutru". Cu toate acestea, cercetătorii tratează în mod obișnuit scalele Likert de 5 și 7 puncte ca date de interval în scopuri practice.
Această practică este general acceptată când:
- Scala ta are cel puțin 5 puncte
- Opțiunile de răspuns sunt spațiate uniform (1, 2, 3, 4, 5)
- Analizezi scoruri agregate de scală mai degrabă decât itemi individuali
Când însumezi sau calculezi media mai multor itemi Likert într-un scor de scală, rezultatul aproximează mai bine date de interval și poate fi analizat cu statistici parametrice.
Calcularea mediilor de construct
Când chestionarul tău măsoară un construct teoretic cu mai mulți itemi, calculează un scor mediu din acești itemi pentru fiecare respondent. Aceasta creează o singură variabilă reprezentând acel construct.
Dacă itemii Q1 până la Q5 (Q1_MeetsExpectations, Q2_Satisfied, Q3_ValueForMoney, Q4_WouldBuyAgain, Q5_OverallHappy) măsoară „Satisfacția în muncă":
=AVERAGE(B2:F2)Copiază în jos pentru toți respondenții. Coloana rezultată conține scorul de satisfacție al fiecărei persoane pe scala originală 1-5.
 Figura 9: Calcularea scorurilor medii de construct din mai multe itemi
Figura 9: Calcularea scorurilor medii de construct din mai multe itemi
Gestionarea răspunsurilor neutre
Punctul de mijloc al scalei Likert (de obicei „neutru" sau „nici acord nici dezacord") primește adesea cele mai multe răspunsuri. Răspunsurile neutre excesive ar putea indica:
- Respondenții sunt cu adevărat ambivalenți
- Întrebarea este confuză sau irelevantă
- Respondenții fac „satisficing" (aleg opțiunea de mijloc ușoară)
Verifică frecvența răspunsurilor neutre pentru fiecare item. Dacă o întrebare are semnificativ mai multe răspunsuri neutre decât altele, investighează formularea.
Crearea variabilelor grupate
Uneori trebuie să restrângi răspunsurile Likert în mai puține categorii pentru analiză sau raportare. De exemplu, combinarea „acord" și „acord total" într-o singură categorie „acord".
Folosește funcții IF imbricate:
=IF(B2<=2,"Dezacord",IF(B2=3,"Neutru","Acord"))Aceasta recodifică răspunsurile 1-2 ca „Dezacord", 3 ca „Neutru", și 4-5 ca „Acord".
| Scală originală | Categorie grupată |
|---|---|
| 1 - Dezacord total | Dezacord |
| 2 - Dezacord | Dezacord |
| 3 - Neutru | Neutru |
| 4 - Acord | Acord |
| 5 - Acord total | Acord |
Tabelul 9: Exemplu de grupare a răspunsurilor Likert în trei categorii
Variabilele grupate funcționează bine pentru prezentarea rezultatelor către audiențe non-tehnice. În loc să spui „media a fost 3.67," poți raporta „55% dintre respondenți au fost de acord sau total de acord."
Greșeli comune cu datele Likert
Mai multe greșeli apar frecvent în lucrările care implică scale Likert:
Greșeala 1: Analizarea itemilor individuali cu statistici parametrice
Efectuarea unui test t pe un singur item Likert încalcă presupunerile despre măsurarea la nivel de interval. Folosește în schimb statistici non-parametrice (Mann-Whitney U) sau analizează scoruri agregate de scală.
Greșeala 2: Uitarea de a inversa scorarea itemilor negativi
Dacă scala ta include itemi formulați negativ, neaplicarea scorării inverse înainte de agregare va corupe scorurile de scală. Verifică întotdeauna chestionarul original pentru itemii care necesită scorare inversă.
Greșeala 3: Tratarea punctului neutru ca „date lipsă"
Unii studenți exclud răspunsurile neutre din analiză, presupunând că acești respondenți nu au avut o opinie. Aceasta creează bias. Neutru este un răspuns valid care ar trebui inclus.
Greșeala 4: Supra-interpretarea diferențelor zecimale
O medie de 3.65 nu este semnificativ diferită de 3.58 fără un test statistic care să confirme semnificația. Raportează mărimea efectului alături de valorile p pentru a determina semnificația practică.
Pentru îndrumări detaliate privind dezvoltarea și analiza scalelor, vezi articolul nostru despre Cum să calculezi Cronbach's Alpha în Excel care acoperă analiza itemilor și testarea fiabilității.
cta: sample-size
Testarea ipotezelor în Excel
Statisticile descriptive îți spun ce s-a întâmplat în eșantionul tău. Testarea ipotezelor îți spune dacă acele descoperiri se generalizează la o populație mai largă. Alegerea testului statistic potrivit depinde de întrebarea ta de cercetare, numărul de grupuri pe care le compari și tipul de date pe care le-ai colectat.
Alegerea testului statistic potrivit
Folosește acest cadru de decizie pentru a selecta testul tău statistic:
Figura 10: Diagrama de decizie pentru selectarea testelor statistice adecvate
| Întrebare de cercetare | Număr de grupuri | Test statistic |
|---|---|---|
| Există diferență între mediile a două grupuri? | 2 grupuri independente | Testul t independent |
| Se schimbă scorurile de la pre-test la post-test? | 2 măsurători pereche | Testul t pentru perechi |
| Există diferență între mai multe grupuri? | 3 sau mai multe grupuri | ANOVA unifactorial |
| Există relație între două variabile? | Nu se aplică | Corelație Pearson |
| O variabilă poate prezice alta? | Nu se aplică | Regresie liniară |
Tabelul 10: Ghid de selecție a testelor statistice pentru diferite tipuri de cercetare
Înainte de a efectua orice test, confirmă că datele tale îndeplinesc presupunerile necesare. Majoritatea statisticilor parametrice presupun distribuție normală și varianțe egale. Pentru eșantioane mici sau date non-normale, ia în considerare alternative non-parametrice.
Pentru o comparație detaliată a momentului când să folosești fiecare test, inclusiv un diagrama de decizie vizuală, consultă ghidul nostru: Test t vs ANOVA în Excel: Ce test să folosești?
Efectuarea testului t în Excel
Testul t compară mediile între două grupuri. Excel oferă aceasta prin Data Analysis Toolpak.
Activarea Data Analysis Toolpak:
- Click pe File apoi Options
- Selectează Add-ins din meniul din stânga
- În partea de jos, selectează Excel Add-ins și click Go
- Bifează Analysis ToolPak și click OK
Opțiunea Data Analysis va apărea în tab-ul Data. Pentru instrucțiuni detaliate cu capturi de ecran, vezi ghidul nostru: Cum să activezi Data Analysis în Excel.
Efectuarea testului t pentru eșantioane independente:
Să presupunem că vrei să compari scorurile de satisfacție între respondenți masculini și feminini.
- Click pe Data apoi Data Analysis
- Selectează t-Test: Two-Sample Assuming Equal Variances
- Pentru Variable 1 Range, selectează scorurile de satisfacție masculine
- Pentru Variable 2 Range, selectează scorurile de satisfacție feminine
- Setează Alpha la 0.05
- Alege o locație pentru output și click OK
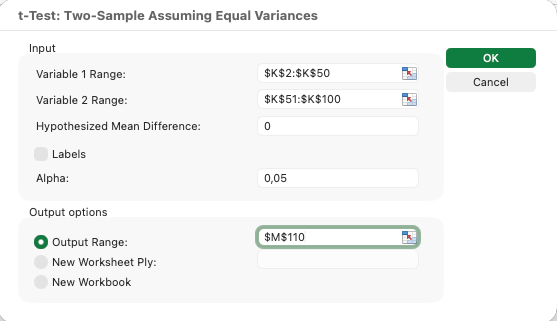 Figura 11: Configurarea testului t pentru eșantioane independente
Figura 11: Configurarea testului t pentru eșantioane independente
Interpretarea rezultatelor testului t:
Excel va genera un tabel cu mai multe statistici. Concentrează-te pe aceste valori cheie:
| Valoare Output | Semnificație |
|---|---|
| Mean | Scorul mediu pentru fiecare grup |
| Variance | Răspândirea scorurilor în cadrul fiecărui grup |
| t Stat | Valoarea t calculată |
| P(T mai mic sau egal cu t) two-tail | Valoarea p pentru test bilateral |
| t Critical two-tail | Valoarea t prag pentru semnificație |
Tabelul 11: Valori cheie din output-ul testului t în Excel
Dacă valoarea p este mai mică de 0.05, diferența dintre grupuri este semnificativă statistic. Dacă valoarea p depășește 0.05, nu poți concluziona că grupurile diferă. Pentru a determina semnificația practică, calculează mărimea efectului folosind Cohen's d sau eta-squared. Consultă ghidul nostru: Cum să calculezi mărimea efectului în Excel
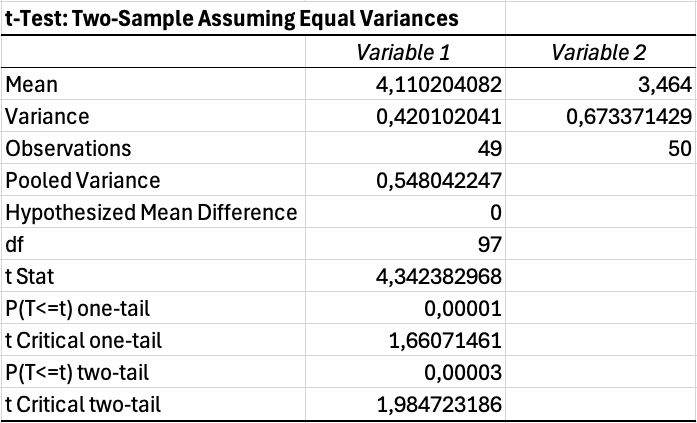 Figura 12: Rezultatul testului t arătând o diferență semnificativă (p = 0.035)
Figura 12: Rezultatul testului t arătând o diferență semnificativă (p = 0.035)
Pentru un tutorial complet despre testul t cu instrucțiuni pas cu pas, vezi ghidul nostru: Testul t în Excel: Ghid complet
Efectuarea ANOVA unifactorial
Când compari trei sau mai multe grupuri, folosește ANOVA în loc de teste t multiple. Efectuarea mai multor teste t crește rata de eroare de tip I, făcând rezultatele fals pozitive mai probabile.
Exemplu: Compararea scorurilor de satisfacție între trei grupe de vârstă (18-25, 26-40, 41+)
- Aranjează datele cu fiecare grup într-o coloană separată
- Click pe Data apoi Data Analysis
- Selectează Anova: Single Factor
- Selectează intervalul de input care acoperă toate coloanele de grupuri
- Selectează Labels dacă primul rând conține anteturi
- Setează Alpha la 0.05
- Click OK
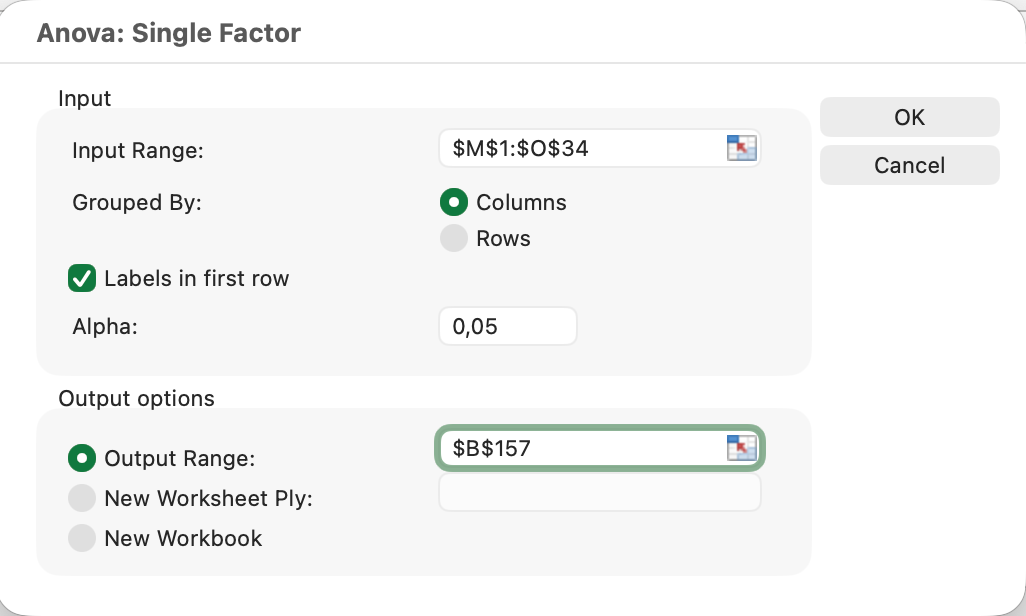 Figura 13: Configurarea ANOVA unifactorial pentru trei grupuri de vârstă
Figura 13: Configurarea ANOVA unifactorial pentru trei grupuri de vârstă
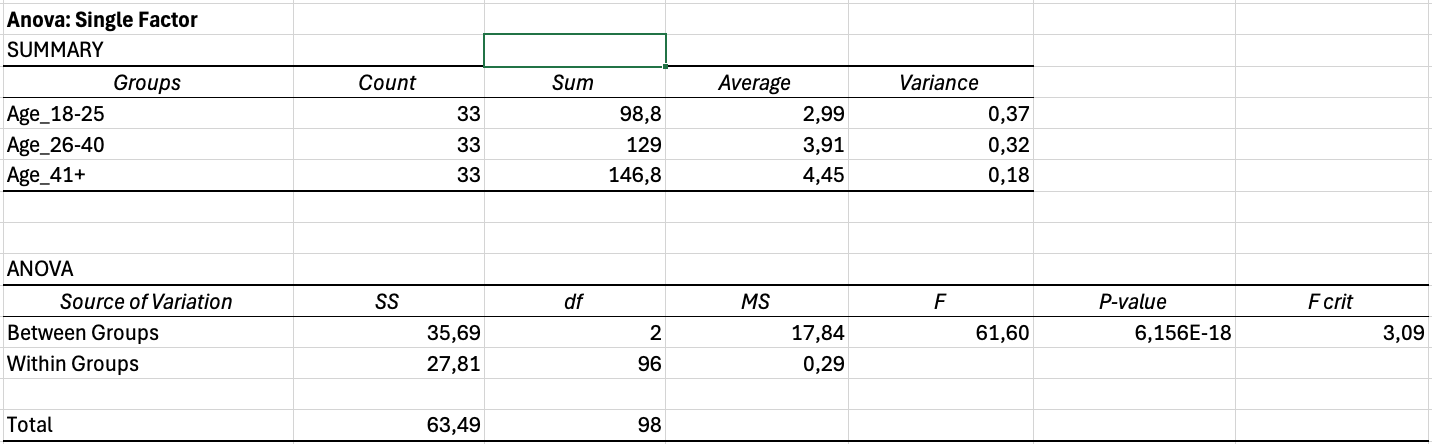 Figura 14: Rezultatul ANOVA arătând diferențe extrem de semnificative
Figura 14: Rezultatul ANOVA arătând diferențe extrem de semnificative
Interpretarea rezultatelor ANOVA:
Output-ul include două tabele. Tabelul Summary arată statistici descriptive pentru fiecare grup. Tabelul ANOVA arată rezultatele testului.
Valori cheie de raportat:
| Sursă | SS | df | MS | F | P-value |
|---|---|---|---|---|---|
| Between Groups | 12.45 | 2 | 6.22 | 4.18 | 0.018 |
| Within Groups | 144.32 | 97 | 1.49 | ||
| Total | 156.77 | 99 |
Tabelul 12: Exemplu de output ANOVA din Excel
Dacă valoarea p este mai mică de 0.05, cel puțin un grup diferă semnificativ de celelalte. ANOVA nu îți spune care grupuri diferă specific. Pentru aceasta, trebuie să efectuezi teste post-hoc (care necesită calcule suplimentare sau alt software).
Pentru instrucțiuni detaliate pas cu pas despre efectuarea ANOVA cu calculul mărimii efectului și raportare APA, consultă ghidul nostru complet: Cum să calculezi ANOVA în Excel
Calcularea corelației în Excel
Corelația măsoară puterea și direcția relației dintre două variabile continue. Folosește-o când vrei să știi dacă valorile mai mari pe o variabilă se asociază cu valori mai mari (sau mai mici) pe alta.
Folosind funcția CORREL:
De exemplu, pentru a corela Satisfacția (Satisfaction_Mean) cu Loialitatea (Loyalty):
=CORREL(B2:B101,C2:C101)Aceasta calculează coeficientul de corelație Pearson între datele din coloanele B și C.
Interpretarea coeficienților de corelație:
Coeficientul variază de la -1 la +1:
| Coeficient | Interpretare |
|---|---|
| 0.90 până la 1.00 | Corelație pozitivă foarte puternică |
| 0.70 până la 0.89 | Corelație pozitivă puternică |
| 0.40 până la 0.69 | Corelație pozitivă moderată |
| 0.10 până la 0.39 | Corelație pozitivă slabă |
| 0.00 până la 0.09 | Nesemnificativă |
| -0.10 până la -0.39 | Corelație negativă slabă |
| -0.40 până la -0.69 | Corelație negativă moderată |
| -0.70 până la -0.89 | Corelație negativă puternică |
| -0.90 până la -1.00 | Corelație negativă foarte puternică |
Tabelul 13: Linii directoare pentru interpretarea coeficienților de corelație Pearson
Un coeficient pozitiv înseamnă că variabilele se mișcă împreună. Un coeficient negativ înseamnă că se mișcă în direcții opuse. Cu cât este mai aproape de 1 sau -1, cu atât relația este mai puternică.
 Figura 15: Corelația Pearson arătând o relație pozitivă puternică (r = 0.67)
Figura 15: Corelația Pearson arătând o relație pozitivă puternică (r = 0.67)
Testarea semnificației statistice:
Funcția CORREL nu oferă o valoare p. Pentru a determina dacă corelația ta este semnificativă, compară cu valori critice sau folosește Data Analysis Toolpak:
- Click pe Data apoi Data Analysis
- Selectează Correlation
- Selectează intervalul de date
- Click OK
Aceasta generează o matrice de corelație dar tot îi lipsesc valorile p. Pentru lucrări, ar putea fi nevoie să calculezi manual valoarea p sau să folosești formula pentru statistica t din corelație:
Unde r este coeficientul de corelație și n este dimensiunea eșantionului. Compară această valoare t cu valoarea critică pentru gradele tale de libertate (n-2).
Pentru un ghid detaliat incluzând testarea semnificației, vezi: Cum să calculezi corelația Pearson în Excel
cta: sample-size
Tabele încrucișate și analiza Chi-Square
Tabularea încrucișată examinează relațiile dintre două variabile categoriale. Răspunde la întrebări precum „Există o relație între gen și preferința de produs?" sau „Diferite grupe de vârstă aleg niveluri de satisfacție diferite?"
Crearea tabelelor încrucișate cu PivotTables
PivotTables sunt cea mai ușoară metodă de a crea tabele încrucișate în Excel.
- Selectează-ți datele incluzând anteturile
- Click pe Insert apoi PivotTable
- Alege unde să plasezi PivotTable-ul
- Trage o variabilă în Rows
- Trage cealaltă variabilă în Columns
- Trage oricare variabilă în Values (setează la Count)
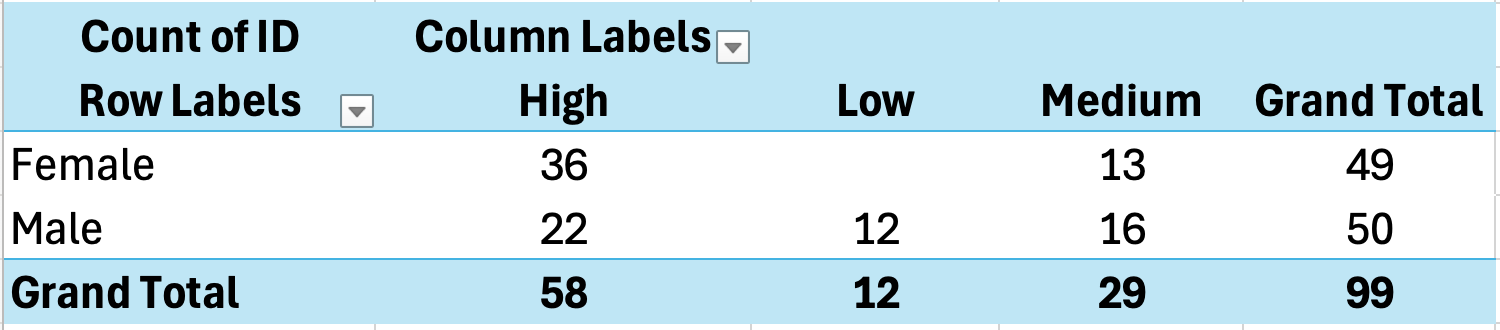 Figura 16: Crearea tabelului încrucișat cu PivotTable
Figura 16: Crearea tabelului încrucișat cu PivotTable
Exemplu de output tabel încrucișat:
| Nemulțumit | Neutru | Mulțumit | Total | |
|---|---|---|---|---|
| Masculin | 8 | 15 | 22 | 45 |
| Feminin | 5 | 18 | 32 | 55 |
| Total | 13 | 33 | 54 | 100 |
Tabelul 14: Tabel încrucișat arătând relația dintre gen și nivelul de satisfacție
Pentru a afișa procentaje în loc de numărători:
- Click pe orice număr din zona Values
- Click dreapta și selectează Show Values As
- Alege % of Row Total sau % of Column Total
Interpretarea rezultatelor tabelului încrucișat
Tabularea încrucișată relevă tipare în modul în care categoriile se raportează una la alta. În exemplul de mai sus:
- 49% dintre bărbați sunt mulțumiți comparativ cu 58% dintre femei
- Bărbații au o rată mai mare de nemulțumire (18%) versus femei (9%)
Totuși, aceste diferențe descriptive nu confirmă o relație semnificativă statistic. Pentru aceasta, ai nevoie de testul Chi-Square.
Testul Chi-Square pentru independență
Testul Chi-Square determină dacă relația dintre două variabile categoriale este semnificativă statistic sau probabil datorată întâmplării.
Excel nu are un test Chi-Square încorporat, dar îl poți calcula folosind formule.
Pasul 1: Calculează frecvențele așteptate
Pentru fiecare celulă, frecvența așteptată este:
Pentru celula Masculin/Nemulțumit: (45 × 13) / 100 este egal cu 5.85
Pasul 2: Calculează Chi-Square
Unde O este frecvența observată și E este frecvența așteptată.
Creează un tabel de valori așteptate, apoi calculează contribuția chi-square pentru fiecare celulă și însumează-le.
Pasul 3: Determină semnificația
Folosește funcția CHISQ.TEST din Excel:
=CHISQ.TEST(IntervalObservat, IntervalAșteptat)Aceasta returnează valoarea p. Dacă este mai mică de 0.05, relația este semnificativă.
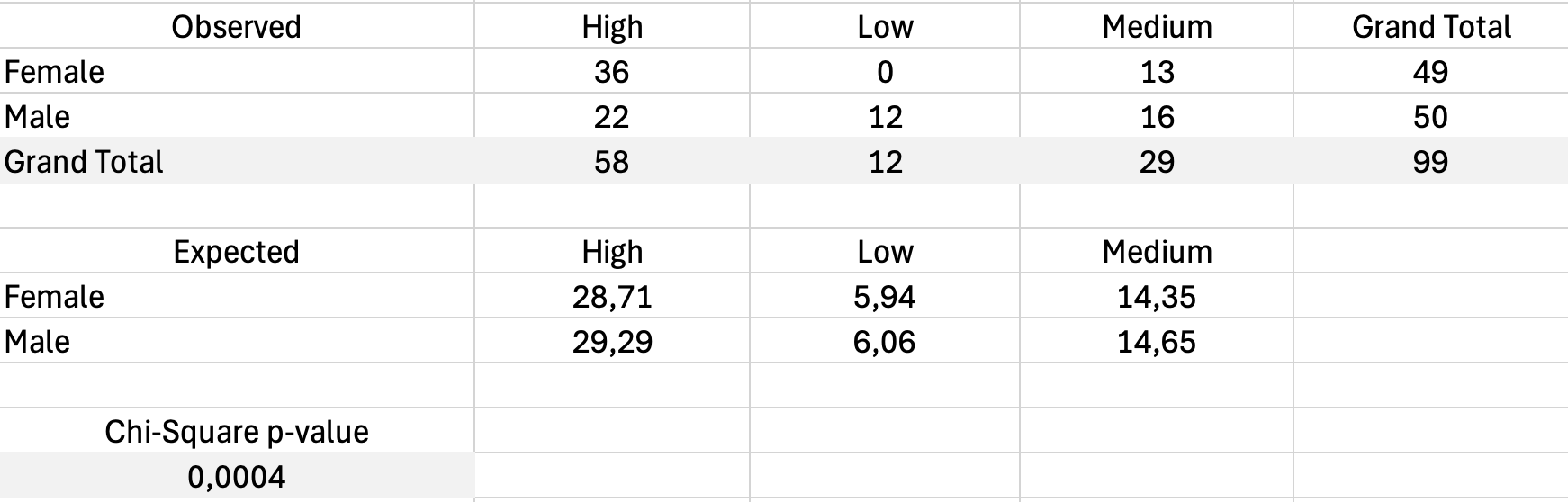 Figura 17: Calculul testului Chi-Square cu frecvențele observate și așteptate
Figura 17: Calculul testului Chi-Square cu frecvențele observate și așteptate
cta: sample-size
Calculează Mărimea Eșantionului
Folosește calculatorul nostru gratuit pentru a determina mărimea eșantionului necesar folosind Yamane, Cochran și Krejcie & Morgan. Compară cele trei metode și obține o citare APA.
Încearcă CalculatorulVizualizarea rezultatelor din chestionar
Graficele traduc numerele în formate pe care cititorii le pot înțelege imediat. Pentru datele din chestionar, anumite tipuri de grafice comunică descoperirile mai eficient decât altele.
Grafice cu bare pentru frecvențe
Graficele cu bare funcționează cel mai bine pentru a arăta cum sunt distribuite răspunsurile în categorii. Folosește-le pentru:
- Distribuții de răspunsuri Likert
- Comparații între grupuri
- Defalcări demografice
Creează un grafic cu bare din tabelul tău de frecvență:
- Selectează etichetele categoriilor și valorile de frecvență
- Click pe Insert și alege Bar Chart sau Column Chart
- Formatează cu etichete clare și culori potrivite
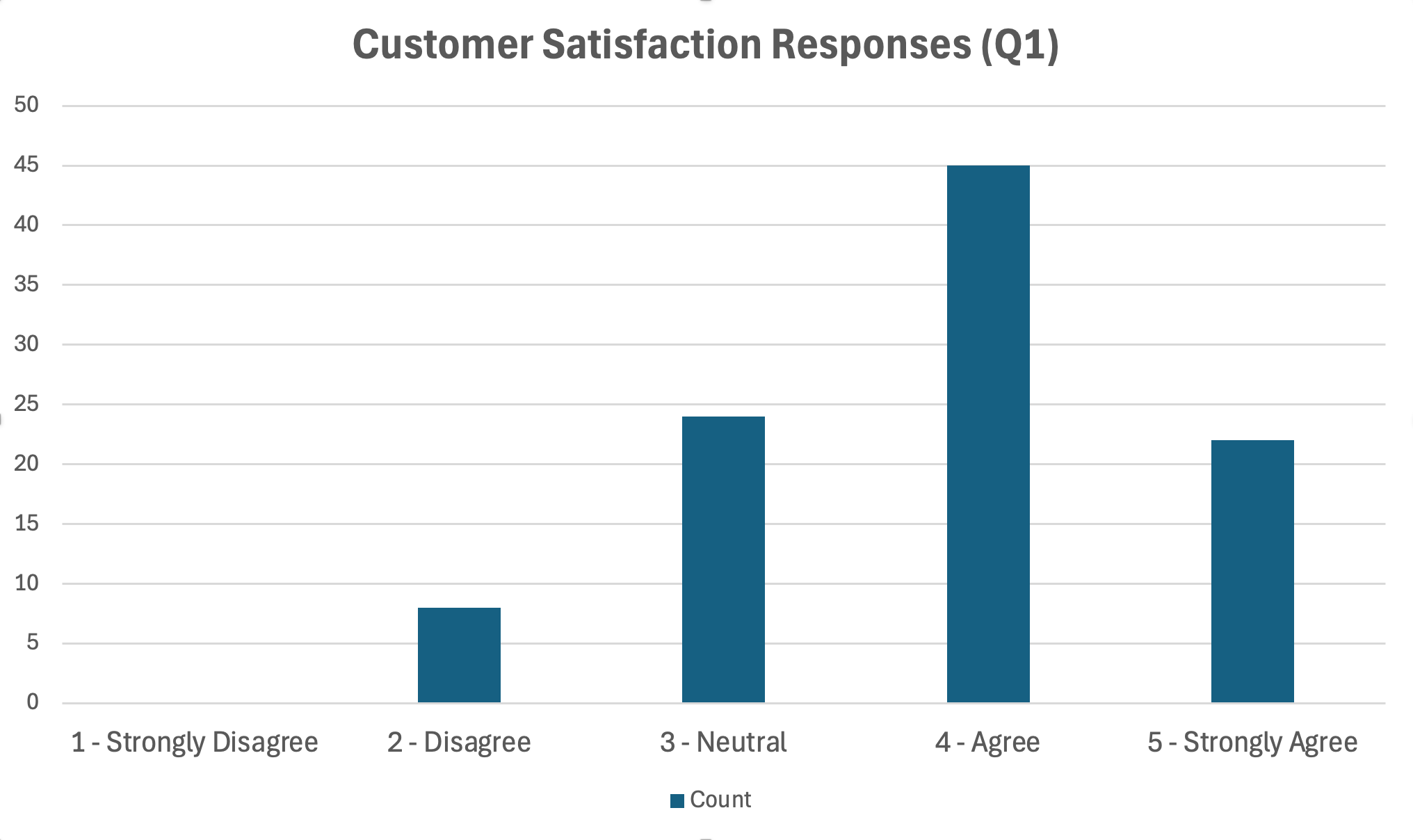 Figura 18: Diagramă cu bare afișând distribuția răspunsurilor pe scala Likert
Figura 18: Diagramă cu bare afișând distribuția răspunsurilor pe scala Likert
Sfaturi de formatare:
- Folosește o singură culoare sau un gradient (evită culorile curcubeu)
- Ordonează barele logic (pentru Likert, păstrează ordinea 1-5)
- Include etichete de date sau o axă clară cu valori
- Adaugă dimensiunea eșantionului în titlu sau notă
Comparații între grupuri cu grafice cu bare grupate
Când compari răspunsuri între grupuri, graficele cu bare grupate plasează barele una lângă alta pentru comparare ușoară.
- Creează un tabel sumar cu grupurile pe rânduri și categoriile de răspuns pe coloane
- Selectează datele și inserează un Clustered Bar Chart
- Fiecare cluster reprezintă o categorie de răspuns cu bare pentru fiecare grup
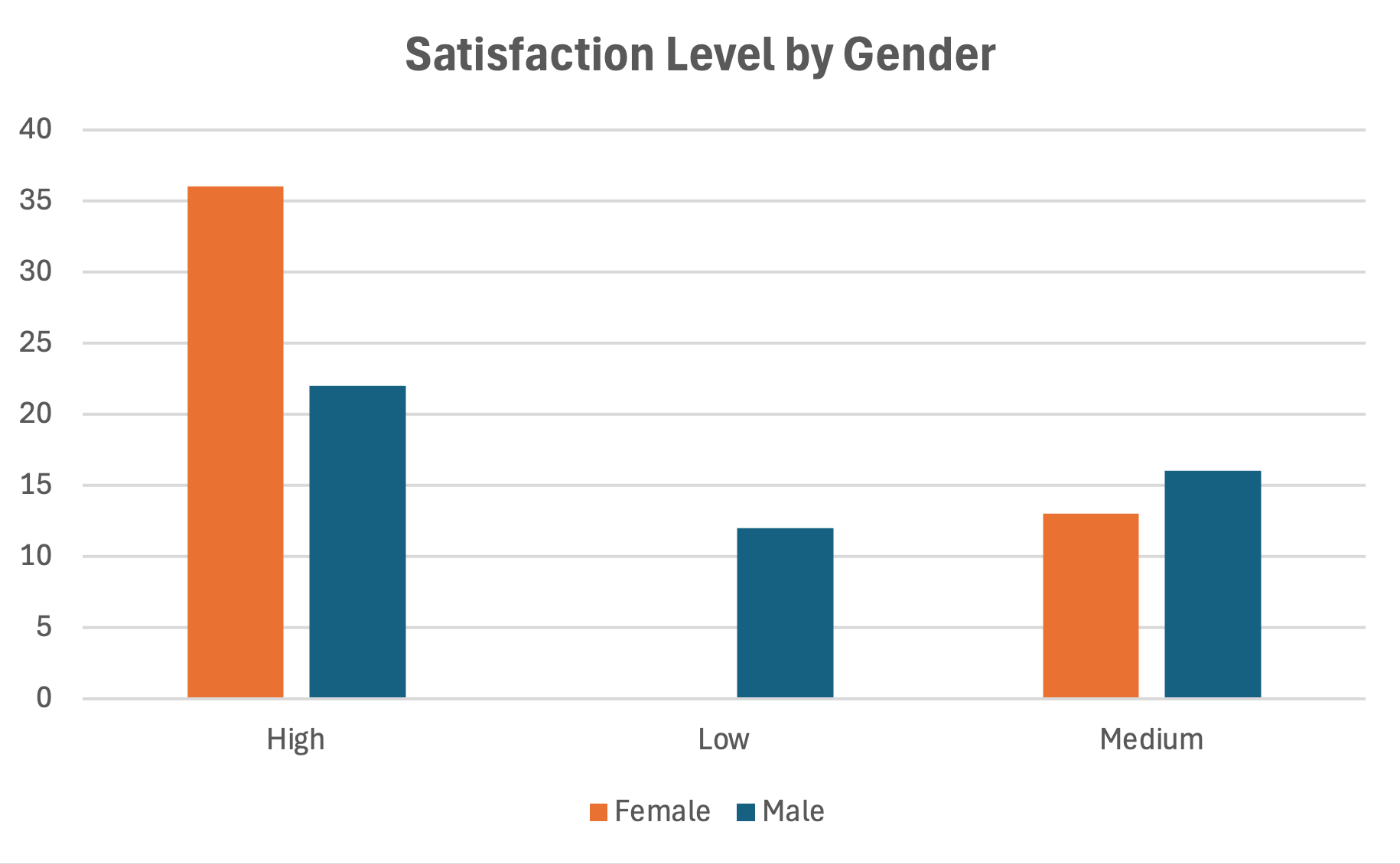 Figura 19: Diagramă cu bare grupate pentru compararea grupurilor
Figura 19: Diagramă cu bare grupate pentru compararea grupurilor
Histograme pentru variabile continue
Pentru scorurile agregate de scală care aproximează date continue, histogramele arată forma distribuției.
- Folosește Data Analysis Toolpak
- Selectează Histogram
- Specifică intervalul de input și intervalul de bin
- Selectează Chart Output
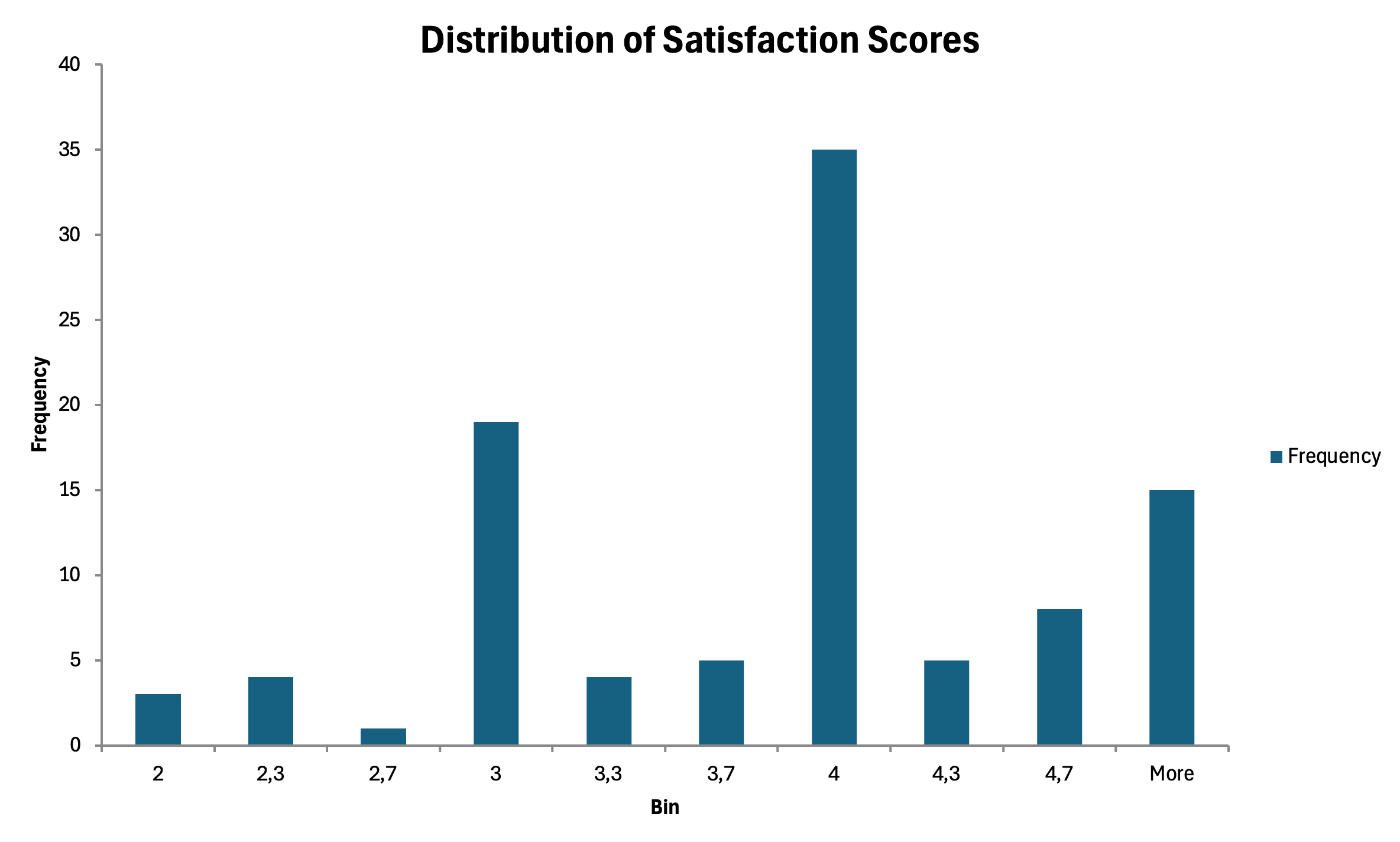 Figura 20: Histogramă arătând distribuția scorurilor pe scală compozită
Figura 20: Histogramă arătând distribuția scorurilor pe scală compozită
Formatarea graficelor pentru lucrare
Graficele academice necesită formatare specifică:
- Elimină elementele decorative (linii de grilă, chenare, efecte 3D)
- Folosește nuanțe de gri sau pattern-uri dacă se printează alb-negru
- Numerotează figurile secvențial (Figura 1, Figura 2)
- Plasează titlul sub figură în format APA
- Include note care explică abrevierile sau dimensiunea eșantionului
cta: sample-size
Cum să scrii rezultatele pentru lucrare
Calcularea statisticilor este doar jumătate din muncă. Comunicarea clară a rezultatelor determină dacă comisia de evaluare va înțelege descoperirile tale. Această secțiune oferă șabloane pe care le poți adapta pentru propriile rezultate.
Bazele formatului APA
Majoritatea disciplinelor academice folosesc formatul APA pentru raportarea statisticilor. Convenții cheie:
- Scrie simbolurile statistice cu italic: M, SD, t, F, r, p
- Raportează valorile p exacte cu trei zecimale (p este egal cu .034)
- Folosește zero înainte de punct pentru statistici care pot depăși 1 (M este egal cu 0.75)
- Fără zero înainte de punct pentru statistici cuprinse între 1 (r este egal cu .67, p este egal cu .034)
- Rotunjește la două zecimale dacă nu este necesară mai multă precizie
Raportarea statisticilor descriptive
Pentru o singură variabilă:
Participanții au raportat niveluri moderat-ridicate de satisfacție față de serviciu (M este egal cu 3.67, SD este egal cu 0.82).
Pentru variabile pe grupuri:
Participanții de sex masculin (M este egal cu 3.52, SD este egal cu 0.79) au raportat satisfacție mai scăzută decât participanții de sex feminin (M este egal cu 3.78, SD este egal cu 0.84).
În tabele:
Tabelul 2 prezintă statisticile descriptive pentru toate variabilele din studiu.
Raportarea rezultatelor testului t
Rezultat semnificativ:
Testul t pentru eșantioane independente a relevat o diferență semnificativă în satisfacție între bărbați (M este egal cu 3.52, SD este egal cu 0.79) și femei (M este egal cu 3.78, SD este egal cu 0.84), t(98) este egal cu -2.14, p este egal cu .035.
Rezultat nesemnificativ:
Diferența în satisfacție între bărbați (M este egal cu 3.52, SD este egal cu 0.79) și femei (M este egal cu 3.58, SD este egal cu 0.81) nu a fost semnificativă statistic, t(98) este egal cu -0.42, p este egal cu .677.
Formatul este: t(grade de libertate) este egal cu valoarea t, p este egal cu valoarea p
Raportarea rezultatelor ANOVA
Rezultat semnificativ:
ANOVA unifactorial a indicat o diferență semnificativă în satisfacție între grupele de vârstă, F(2, 97) este egal cu 4.18, p este egal cu .018.
Cu analize post-hoc:
Comparațiile post-hoc folosind testul Tukey au relevat că participanții de 41+ ani (M este egal cu 4.02, SD este egal cu 0.72) au raportat satisfacție semnificativ mai mare decât cei din grupa 18-25 (M este egal cu 3.45, SD este egal cu 0.89), p este egal cu .014. Grupa 26-40 (M este egal cu 3.68, SD este egal cu 0.78) nu a diferit semnificativ de niciun grup.
Raportarea rezultatelor corelației
Corelație semnificativă:
A existat o corelație pozitivă puternică între satisfacția clienților și loialitatea față de brand, r(98) este egal cu .67, p mai mic decât .001. Satisfacția mai mare a fost asociată cu loialitate mai mare.
Corelație nesemnificativă:
Relația dintre satisfacție și vârstă nu a fost semnificativă statistic, r(98) este egal cu .12, p este egal cu .231.
Raportarea fiabilității
Scală unică:
Scala de satisfacție a clienților a demonstrat consistență internă bună (Cronbach's α este egal cu .84).
Scale multiple:
Consistența internă a fost acceptabilă pentru toate scalele: satisfacția clienților (α este egal cu .84), intenția de cumpărare (α este egal cu .78), și loialitatea față de brand (α este egal cu .91).
Șabloane gata de folosit
Iată șabloane de completat pentru analize comune:
Șablon statistici descriptive:
Participanții au avut scoruri [ridicate/moderate/scăzute] pe [numele variabilei] (M este egal cu [medie], SD este egal cu [SD]).
Șablon test t:
Testul t pentru eșantioane independente [a relevat/nu a relevat] o diferență semnificativă în [VD] între [grupul 1] (M este egal cu [medie], SD este egal cu [SD]) și [grupul 2] (M este egal cu [medie], SD este egal cu [SD]), t([gl]) este egal cu [valoare t], p este egal cu [valoare p].
Șablon ANOVA:
ANOVA unifactorial [a indicat/nu a indicat] o diferență semnificativă în [VD] între [variabila de grupare], F([gl1], [gl2]) este egal cu [valoare F], p este egal cu [valoare p].
Șablon corelație:
A existat o corelație [puternică/moderată/slabă] [pozitivă/negativă] între [variabila 1] și [variabila 2], r([gl]) este egal cu [valoare r], p este egal cu [valoare p].
cta: sample-size
Greșeli de evitat
Chiar și cercetătorii experimentați fac greșeli când analizează date din chestionar. Învățarea din greșelile comune te ajută să produci rezultate mai credibile. Pentru un ghid detaliat despre cele 10 cele mai comune greșeli și cum să le corectezi, consultă: Greșeli comune în analiza chestionarelor (Excel) și cum să le corectezi
Greșeala 1: Folosirea testului statistic greșit
Alegerea unui test statistic bazat pe ce vrei să găsești în loc de ce susțin datele duce la concluzii invalide. Lasă întotdeauna întrebarea de cercetare și tipul de date să ghideze selecția testului. Testele t necesită o variabilă dependentă continuă. Chi-square necesită variabile categoriale. Amestecarea acestora produce rezultate fără sens.
Greșeala 2: Ignorarea presupunerilor
Statisticile parametrice presupun distribuție normală și varianțe egale. Sărirea verificărilor presupunerilor nu face încălcările să dispară. Verifică normalitatea folosind histograme sau testul Shapiro-Wilk. Verifică omogenitatea varianțelor folosind testul Levene. Când presupunerile sunt încălcate, folosește alternative non-parametrice sau transformă datele.
Greșeala 3: P-Hacking
Efectuarea mai multor teste până când găsești semnificație, apoi raportarea doar a acelor rezultate, umflă rata de fals pozitiv. Dacă testezi 20 de relații la α egal cu .05, te aștepți la un rezultat semnificativ întâmplător. Raportează toate analizele efectuate, chiar și cele nesemnificative. Ia în considerare ajustarea pentru comparații multiple folosind corecția Bonferroni.
Greșeala 4: Confundarea corelației cu cauzalitatea
O corelație semnificativă între satisfacție și loialitate nu dovedește că satisfacția cauzează loialitate. Relația ar putea fi inversă (loialitatea cauzează satisfacție) sau ambele ar putea fi cauzate de o a treia variabilă. Doar designurile experimentale cu randomizare pot stabili cauzalitatea.
Greșeala 5: Supra-interpretarea rezultatelor pe eșantioane mici
Testele statistice cu eșantioane mici (sub 30) au putere scăzută, însemnând că ar putea rata efecte reale. De asemenea, produc estimări instabile care s-ar putea să nu se replice. Fii prudent în generalizarea din eșantioane mici. Raportează limitările privind dimensiunea eșantionului în capitolul de discuții.
Greșeala 6: Uitarea de a verifica fiabilitatea înainte de analiză
Folosirea scalelor nefiabile invalidează toate analizele ulterioare. O scală cu α egal cu .55 introduce atât de multă eroare de măsurare încât orice relații pe care le găsești sunt suspecte. Verifică și raportează întotdeauna Cronbach's Alpha înainte de a efectua teste de ipoteze.
Greșeala 7: Negestionarea datelor lipsă
Ignorarea valorilor lipsă sau gestionarea lor inconsecventă creează bias. Documentează câte cazuri au date lipsă, ce variabile sunt afectate și cum ai abordat problema. Metodele comune includ listwise deletion, pairwise deletion și mean imputation. Fiecare are compromisuri pe care ar trebui să le recunoști.
cta: sample-size
Template Excel: Kit de analiză pentru chestionar
Pentru a te ajuta să implementezi aceste tehnici, am creat un template Excel cu formule pre-construite pentru analize comune de chestionar.
Ce include template-ul:
- Foaie de introducere a datelor cu structură adecvată
- Calcul automat Cronbach's Alpha
- Rezumat statistici descriptive
- Generator de tabele de frecvență
- Calculator pentru testul t
- Matrice de corelație
- Template-uri de grafice
Cum să folosești:
- Descarcă template-ul din bara laterală
- Introdu răspunsurile din chestionar în foaia Data
- Foaia Summary va calcula automat statisticile cheie
- Folosește foaia Analysis pentru testarea ipotezelor
- Copiază template-urile de grafice și actualizează-le cu datele tale
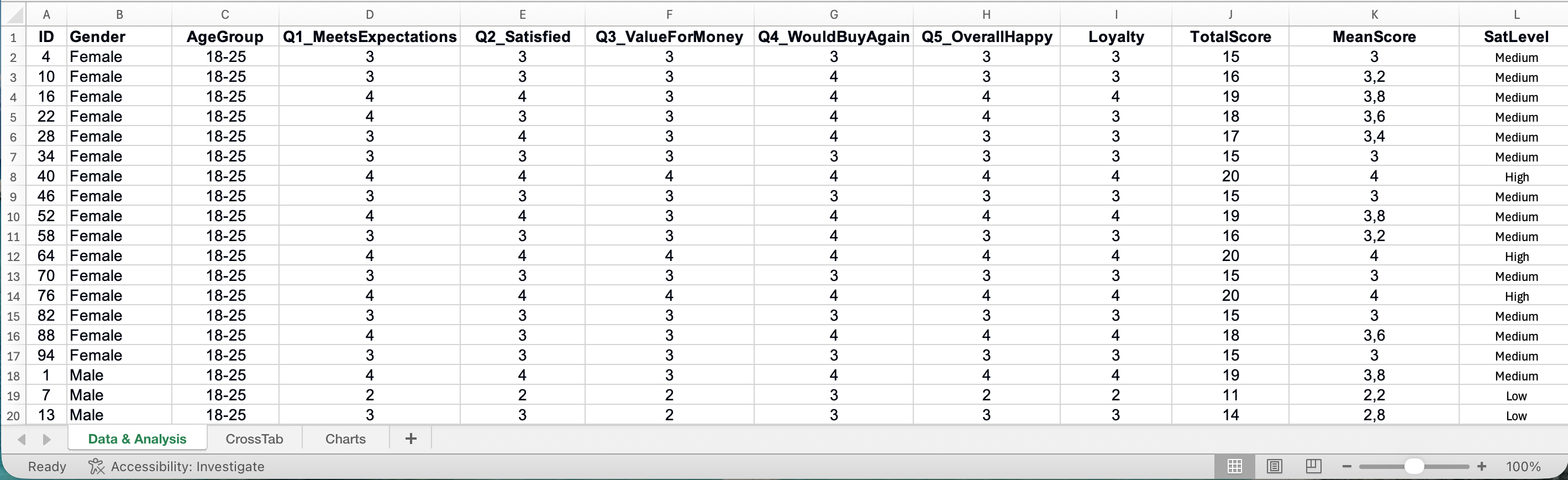 Figura 21: Survey Analysis Excel Template cu calcule automate
Figura 21: Survey Analysis Excel Template cu calcule automate
Descarcă Survey Analysis Excel Template
cta: sample-size
Întrebări frecvente
cta: sample-size
Pași următori
Acum ai un workflow complet pentru analiza datelor din chestionar în Excel, de la pregătirea datelor la raportarea rezultatelor. Fiecare pas contribuie la o lucrare credibilă.
Seria completă Statistică în Excel:
Fiabilitate și Interpretare:
- Cum să calculezi Cronbach's Alpha în Excel - Calculul fiabilității pas cu pas
- Cum să interpretezi rezultatele Cronbach's Alpha - Înțelegerea valorilor de fiabilitate
- Cum să raportezi Cronbach's Alpha în format APA - Ghid de formatare pentru lucrări
Testarea Ipotezelor:
- Testul t în Excel: Ghid complet - Teste t independente și pentru perechi
- Test t vs ANOVA: Ce test să folosești? - Cadru de decizie
- Cum să calculezi ANOVA în Excel - Compararea a 3+ grupuri
- Cum să calculezi mărimea efectului în Excel - Cohen's d și eta-squared
Statistici Descriptive și Corelație:
- Statistici descriptive în Excel: Ghidul complet - Medie, mediană, mod și altele
- Cum să raportezi statisticile descriptive în format APA - Tabele pentru lucrări
- Cum să creezi tabele de frecvență în Excel - Analiza distribuției
- Cum să calculezi corelația Pearson în Excel - Analiza relațiilor
Analiză de Regresie:
- Cum să calculezi regresia liniară simplă în Excel - Modele cu un singur predictor
- Cum să calculezi regresia liniară multiplă în Excel - Modele cu mai mulți predictori
Calitatea Datelor și Depanare:
- Cum să gestionezi datele lipsă în Excel - Strategii de curățare a datelor
- Greșeli comune în analiza chestionarelor (Excel) - Evită erorile costisitoare
Pregătit pentru SPSS?
Dacă analizele tale necesită funcții dincolo de capacitățile Excel, explorează tutorialele noastre SPSS:
- Cum să calculezi Cronbach's Alpha în SPSS
- Cum să faci analiză de mediere în SPSS
- Cum să faci analiză de moderare în SPSS
cta: sample-size
Referințe
Pallant, J. (2016). SPSS Survival Manual (6th ed.). McGraw-Hill Education.