Cum să Calculezi Regresia Liniară Simplă în Excel (Ghid pentru Teză)
•By Leonard Cucos•ro
StatisticăMetode de CercetareExcel
Regresia liniară simplă este una dintre cele mai puternice și totuși accesibile tehnici statistice pentru cercetarea de teză și disertație. Fie că prezici performanța studenților pe baza orelor de studiu, veniturile din vânzări pe baza cheltuielilor de publicitate sau rezultatele pacienților pe baza duratei tratamentului, regresia liniară simplă te ajută să cuantifici relațiile și să faci predicții bazate pe evidențe folosind Analysis ToolPak integrat în Excel.
Spre deosebire de analiza de corelație care îți spune doar dacă variabilele sunt legate, regresia îți permite să prezici valori specifice, să înțelegi direcția influenței și să cuantifici exact cât se schimbă variabila ta de rezultat pentru fiecare unitate de creștere a predictorului. Acest lucru face regresia esențială pentru Capitolul 4 (Rezultate) în disertațiile din psihologie, educație, business, științele sănătății și științele sociale.
Acest ghid cuprinzător îți arată cum să calculezi regresia liniară simplă în Excel folosind trei metode, să verifici toate cele patru asumpții ale regresiei, să interpretezi corect rezultatele și să raportezi concluziile în format APA ediția a 7-a. Vei învăța și limitările critice ale regresiei în Excel și când trebuie să folosești SPSS sau R în schimb.
Vei învăța:
Ce este regresia liniară simplă și când să o folosești pentru cercetarea de teză
Cum să calculezi regresia folosind Analysis ToolPak (recomandat), trendline-uri în grafice scatter și funcția LINEST
Cum să interpretezi R-squared, valorile p, coeficienții și erorile standard
Cum să verifici asumpțiile (linearitate, normalitate, homoscedasticitate) în Excel
Cum să raportezi rezultatele în format APA ediția a 7-a pentru disertația ta
Limitările Excel și ce tipuri de regresie necesită SPSS/R
Aceste tehnici se aplică fie că analizezi date experimentale, răspunsuri la chestionare sau studii observaționale cu variabile continue.
Regresia liniară simplă este o metodă statistică care modelează relația dintre o variabilă dependentă (Y, rezultat) și o variabilă independentă (X, predictor) folosind o ecuație liniară. Linia de regresie reprezintă cea mai bună predicție a lui Y bazată pe X, minimizând suma diferențelor pătrate între valorile observate și cele prevăzute - aceasta se numește metoda celor mai mici pătrate.
Ecuația Regresiei
Ecuația regresiei liniare simple este:
Y=a+bX+ε
Unde:
Y = Variabila dependentă (rezultatul pe care vrei să-l prezici)
X = Variabila independentă (predictorul)
a = Interceptarea (valoarea lui Y când X = 0)
b = Panta (schimbarea în Y pentru fiecare creștere de o unitate în X)
ε = Termenul de eroare (variația neexplicată)
Exemplu de cercetare: Un student de master investighează dacă orele săptămânale de studiu (X) prezic scorurile finale la examen (Y). Analiza de regresie produce ecuația:
Scor examen=47.33+2.75×Ore studiu
Aceasta înseamnă că pentru fiecare oră suplimentară de studiu pe săptămână, scorul la examen crește în medie cu 2.75 puncte.
Când să Folosești Regresia Liniară Simplă pentru Teză
Folosește regresia liniară simplă când cercetarea ta îndeplinește aceste criterii:
1. Cerințe pentru Întrebarea de Cercetare:
Vrei să prezici valori ale lui Y pe baza lui X
Vrei să cuantifici cât se schimbă Y când X crește
Vrei să testezi dacă X este un predictor semnificativ al lui Y
2. Cerințe pentru Variabile:
Un singur predictor continuu (X): Scală intervală sau de raport (de exemplu, vârstă, venit, scoruri la teste, timp)
Un singur rezultat continuu (Y): Scală intervală sau de raport
Ambele variabile ar trebui să aibă cel puțin 30 de puncte de date
3. Exemple de Cercetare pe Discipline:
Psihologie: Numărul de ședințe de terapie prezice reducerea simptomelor de depresie?
Educație: Prezența la cursuri prezice scorurile la examenul final?
Business: Bugetul de publicitate prezice veniturile lunare din vânzări?
Științele Sănătății: Minutele de exercițiu pe săptămână prezic pierderea în greutate?
Științe Sociale: Nivelul veniturilor prezice scorurile de satisfacție a vieții?
Regresia Liniară Simplă vs. Corelație
Multi studenți confundă regresia cu corelația. Iată diferența critică:
Aspect
Corelație
Regresie Liniară Simplă
Scop
Măsoară intensitatea și direcția relației
Prezice Y din X și cuantifică efectul
Output
Coeficient de corelație (r) de la -1 la +1
Ecuație de regresie (Y = a + bX)
Variabile
Tratează X și Y în mod egal (simetrică)
Face distincție între predictor (X) și rezultat (Y)
Interpretare
"X și Y sunt legate"
"Fiecare creștere de o unitate în X schimbă Y cu b unități"
Utilizare în Teză
Analiză preliminară, explorarea relațiilor
Analiză primară pentru predicție și cuantificarea efectului
Exemplu
Orele de studiu și scorurile la examen sunt corelate pozitiv (r = 0.98)
Fiecare oră suplimentară de studiu crește scorul la examen cu 2.75 puncte
Raportare APA
"Orele de studiu și scorurile la examen au fost corelate pozitiv, r = .98, p < .001"
"Regresia liniară simplă a arătat că orele de studiu au prezis semnificativ scorurile la examen, β = 2.75, t(28) = 29.16, p < .001"
Tabelul 1: Comparație Corelație vs. Regresie
Când să folosești corelația: Analiza exploratorie, verificarea dacă variabilele sunt legate înainte de regresie, raportarea relațiilor bivariate în secțiunea de statistică descriptivă.
Când să folosești regresia: Testarea ipotezelor despre predicție, cuantificarea efectelor pentru discuție, raportarea rezultatelor primare pentru întrebări de cercetare concentrate pe predicție.
Regresia Simplă vs. Multiplă: Ce Îți Trebuie?
Înainte de a continua, determină dacă ai nevoie de regresia liniară simplă sau multiplă pentru teza ta:
Figura 1: Diagramă de decizie pentru selectarea regresiei liniare simple (un predictor) sau regresiei liniare multiple (doi sau mai mulți predictori) pe baza întrebării tale de cercetare și variabilelor
Folosește Regresia Liniară Simplă când:
Ai un singur predictor de interes
Întrebarea ta de cercetare se concentrează pe o singură relație specifică
Vrei să izolezi efectul unei singure variabile
Faci analiză preliminară înainte de a adăuga covariate
Exemplu: "Timpul de studiu prezice scorurile la examen?"
Folosește Regresia Liniară Multiplă când:
Ai doi sau mai mulți predictori
Vrei să controlezi variabilele confuzive
Întrebarea ta de cercetare include factori multipli
Vrei să compari importanța relativă a predictorilor
Exemplu: "Timpul de studiu, orele de somn ȘI prezența la curs prezic scorurile la examen?"
Gândește-te la asta ca la gătit: regresia simplă testează dacă adăugarea mai multului usturoi îmbunătățește sosul de paste, în timp ce regresia multiplă testează dacă usturoiul, uleiul de măsline ȘI roșiile proaspete împreună îl fac mai bun - și care ingredient contează cel mai mult.
Caracteristică
Regresia Liniară Simplă
Regresia Liniară Multiplă
Număr de predictori
1 variabilă independentă
2 sau mai multe variabile independente
Ecuație
Y = a + bX
Y = a + b₁X₁ + b₂X₂ + ...
Întrebare de cercetare
"Orele de studiu prezic scorurile la examen?"
"Orele de studiu ȘI participarea la curs prezic scorurile la examen?"
Când să o folosești
Când ai un singur predictor de interes
Când ai predictori multipli sau variabile de control
Complexitatea analizei
Mai simplu - mai ușor de interpretat
Mai complex - necesită verificări suplimentare (multicolinearitate)
Software necesar
Excel Analysis ToolPak (suficient)
Excel pentru bază, SPSS/R pentru analiză avansată
Tabelul 2: Comparație Regresie Simplă vs. Multiplă
Set de Date Exemplu pentru Acest Tutorial
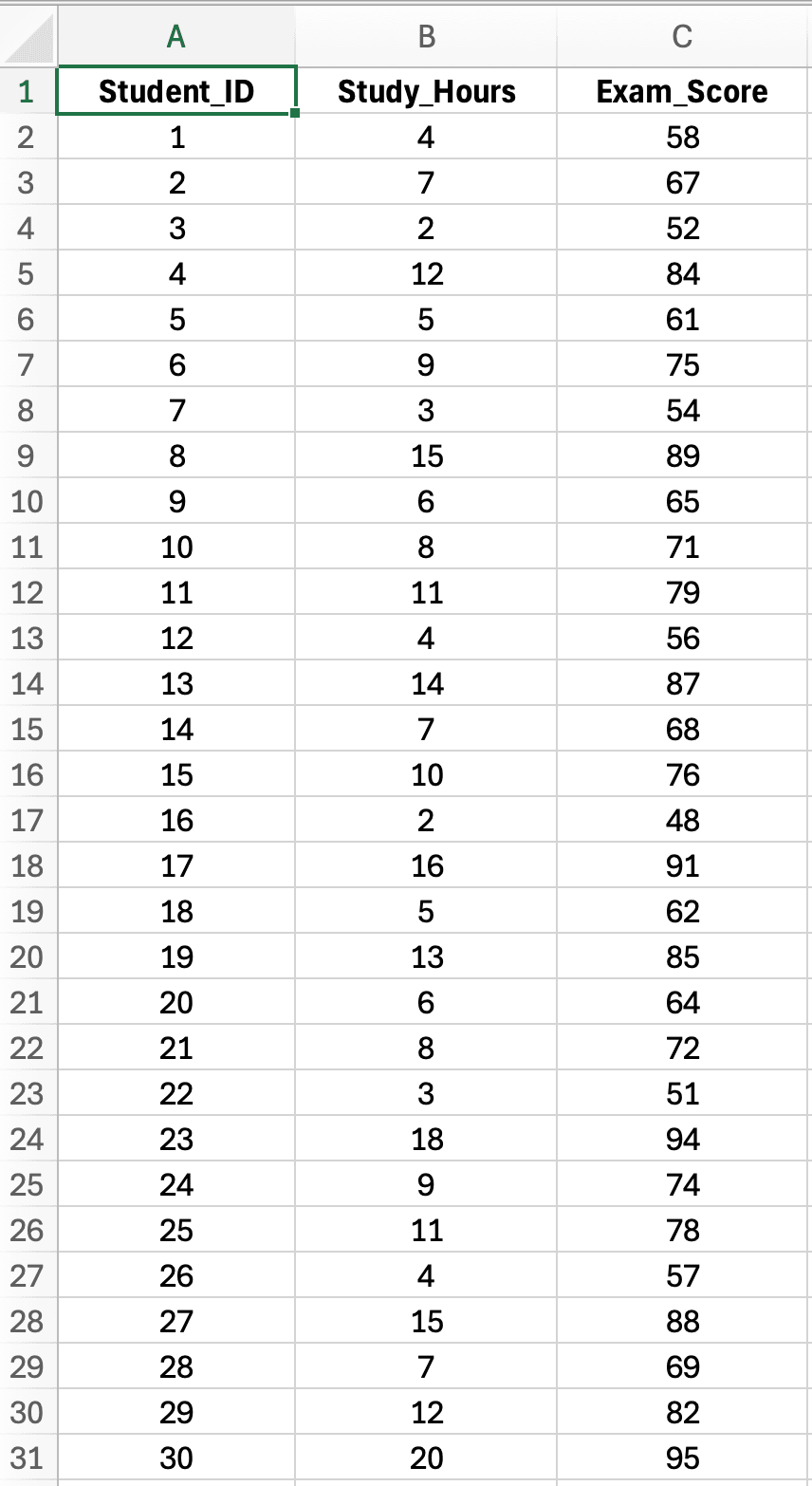
Pe parcursul acestui ghid, vom folosi un set de date realist de teză care examinează relația dintre orele de studiu și scorurile la examen pentru 30 de studenți universitari. Acest set de date demonstrează o întrebare de cercetare tipică de predicție: "Timpul de studiu prezice performanța academică?"
Figura 2: Set de date exemplu cu 30 de studenți arătând Ore de studiu (Study_Hours - variabila X, predictor) și Scor examen (Exam_Score - variabila Y, rezultat) pentru analiza regresiei liniare simple
Caracteristicile setului de date:
Dimensiunea eșantionului: n = 30 studenți (adecvat pentru regresia simplă)
Variabila independentă (X): Ore de studiu (Study_Hours) pe săptămână (interval: 2-20 ore)
Întrebarea de cercetare: Timpul săptămânal de studiu prezice performanța la examenul final?
Creează propriul set de date:
Introdu datele tale în două coloane (X în coloana A, Y în coloana B)
Include anteturi (rândul 1): "Study_Hours" și "Exam_Score"
Minim 30 de observații recomandate pentru cercetarea de teză
Asigură-te că datele sunt continue (fără variabile categorice)
Notă privind mărimea efectului: Acest set de date didactic arată intenționat o relație foarte puternică (R² = .97) astfel încât tiparele să fie clare și ușor de interpretat. În cercetarea reală din științele comportamentale, valorile R² între .10 și .40 sunt mult mai comune și reprezintă în continuare descoperiri semnificative și publicabile. Nu te descuraja dacă datele din teza ta arată relații mai slabe. Este normal și de așteptat în științele sociale.
Cum să Calculezi Regresia Liniară Simplă în Excel (Pas cu Pas)
Excel oferă trei metode pentru calcularea regresiei liniare simple. Vom acoperi toate cele trei, începând cu abordarea cea mai cuprinzătoare pentru cercetarea de teză.
Metoda 1: Analysis ToolPak (Recomandat pentru Teză)
Analysis ToolPak oferă cel mai complet rezultat al regresiei, incluzând R-squared, valorile p, coeficienții, erorile standard și reziduurile. Această metodă este necesară pentru lucrarea de teză deoarece îți oferă toate statisticile necesare pentru raportarea APA.
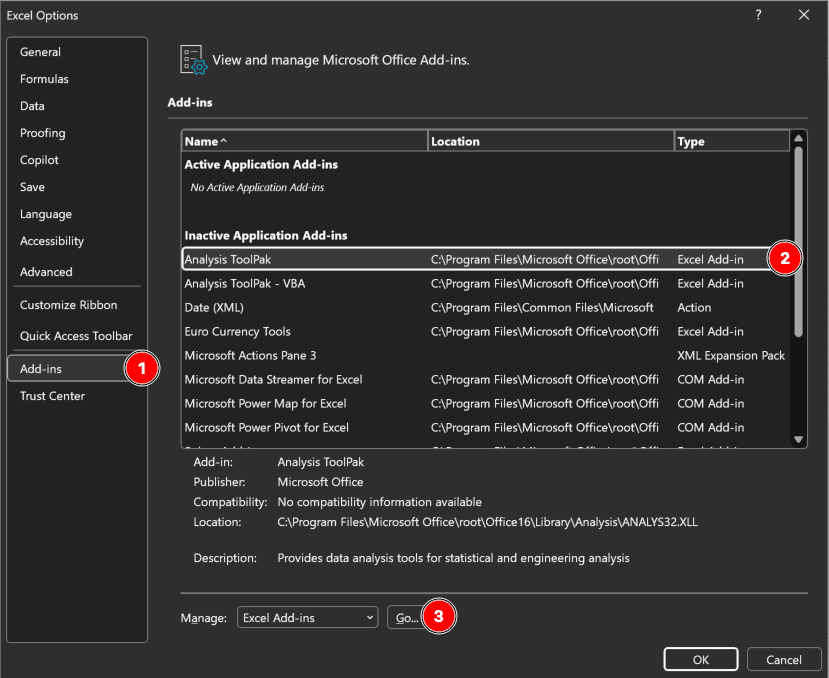
Pasul 1: Activează Analysis ToolPak (Configurare O Singură Dată)
Dacă nu ai folosit Analysis ToolPak înainte, activează-l:
Figura 3: Activarea Analysis ToolPak în Excel prin File → Options → Add-ins → Analysis ToolPak
Click pe File → Options
Selectează Add-ins (bara laterală din stânga)
La bază, selectează Excel Add-ins din meniul dropdown "Manage"
Click pe Go
Bifează caseta pentru Analysis ToolPak
Click pe OK
Odată activat, vei vedea "Data Analysis" în fila Data din ribbon.
Ai nevoie de ajutor mai detaliat pentru instalare? Pentru instrucțiuni pas cu pas cu capturi de ecran pentru Windows, Mac și rezolvarea problemelor comune, consultă ghidul nostru complet: Cum să Activezi Data Analysis în Excel.
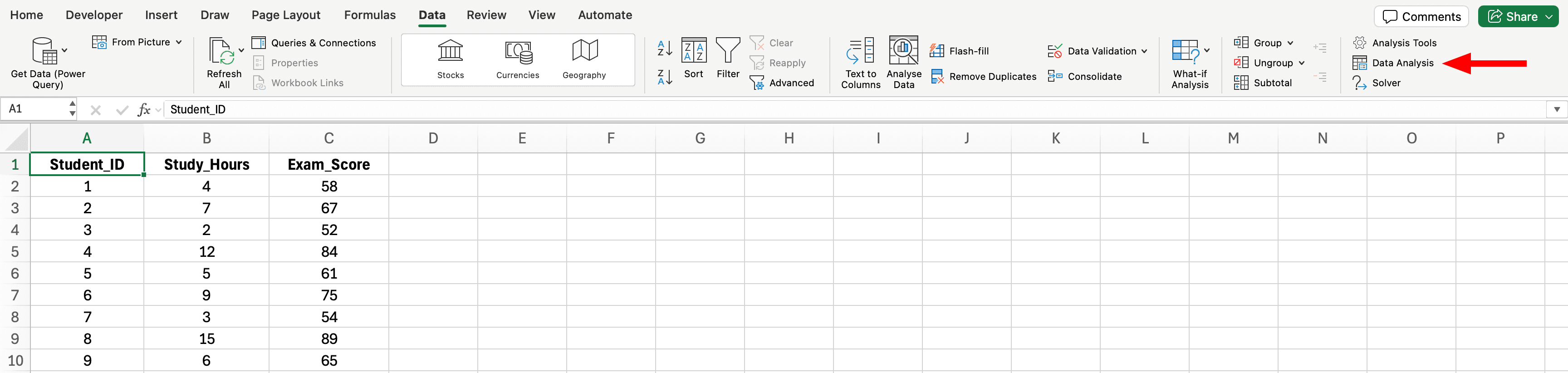
Pasul 2: Accesează Instrumentul Data Analysis
Figura 4: Locația butonului Data Analysis în fila Data Excel (partea dreaptă a ribbon-ului)
Click pe fila Data (în ribbon)
Click pe Data Analysis (grupul Analysis, partea dreaptă)
Dacă nu vezi acest buton, revino la Pasul 1 pentru a activa ToolPak-ul
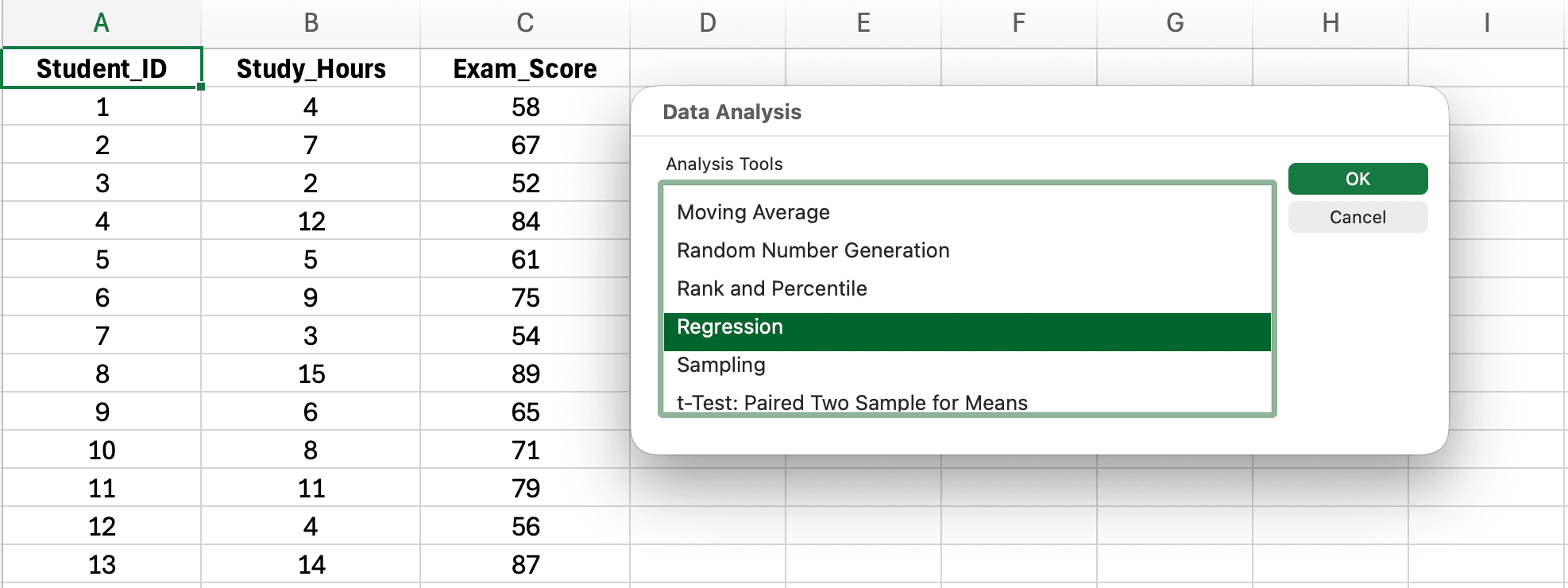
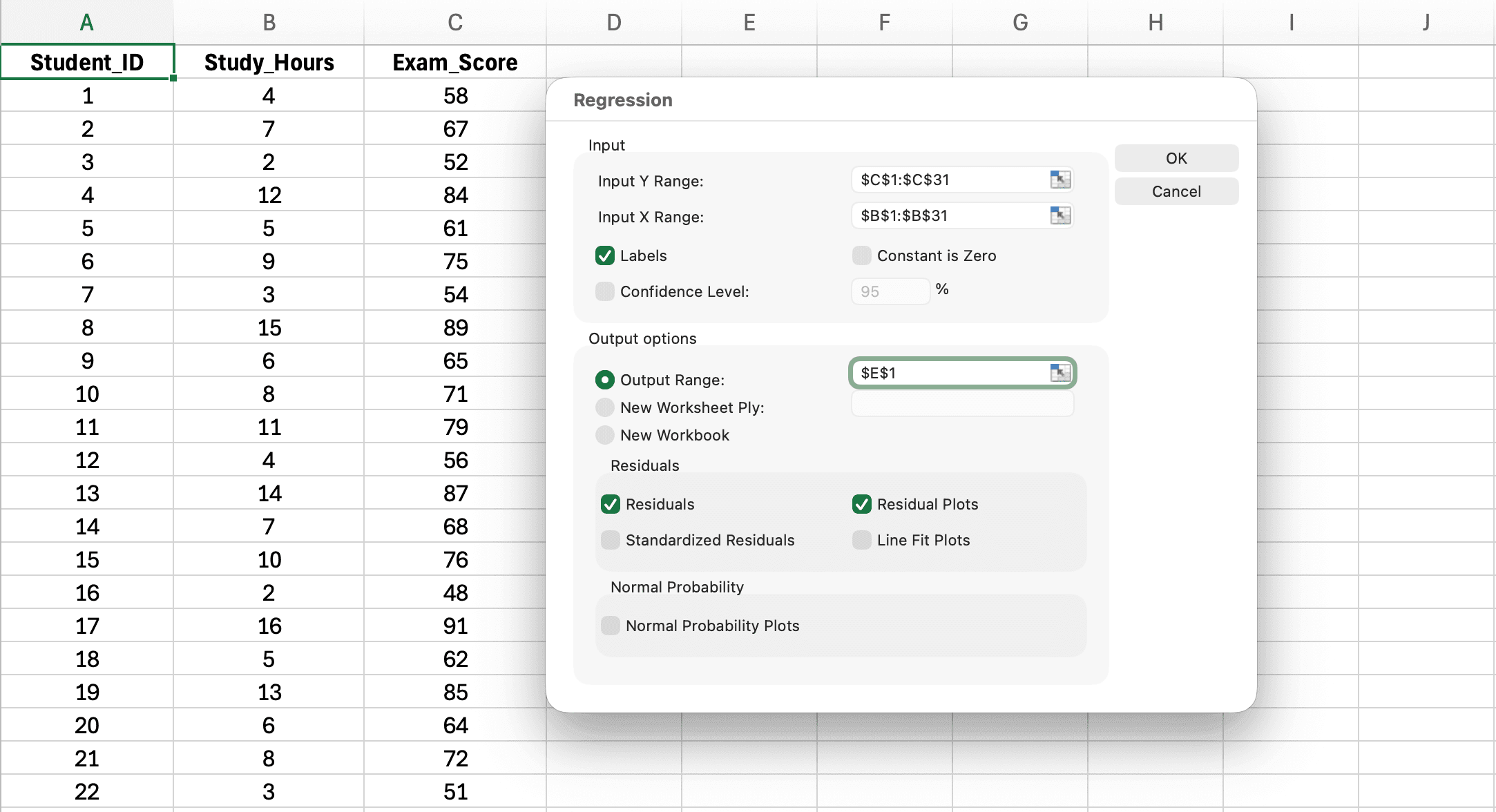
Pasul 3: Selectează Regression și Configurează Setările
Figura 5: Selectarea Regression din lista de instrumente Data Analysis
În caseta de dialog Data Analysis, derulează în jos și selectează Regression
Click pe OK
Figura 6: Caseta de dialog Regression cu Input Y Range (Exam_Score), Input X Range (Study_Hours), caseta Labels și Output Range configurate
Input Y Range: Click în caseta și selectează coloana ta de Scor examen (Exam_Score) (inclusiv antetul)
Exemplu: $B$1:$B$31 (antetul + 30 de studenți)
Input X Range: Click în caseta și selectează coloana ta de Ore studiu (Study_Hours) (inclusiv antetul)
Exemplu: $A$1:$A$31
Labels: Bifează această casetă (pentru că am inclus anteturile)
Output Range: Specifică unde vrei rezultatele (ex: $D$1)
SAU selectează "New Worksheet Ply" pentru rezultate într-o foaie nouă
Click pe OK
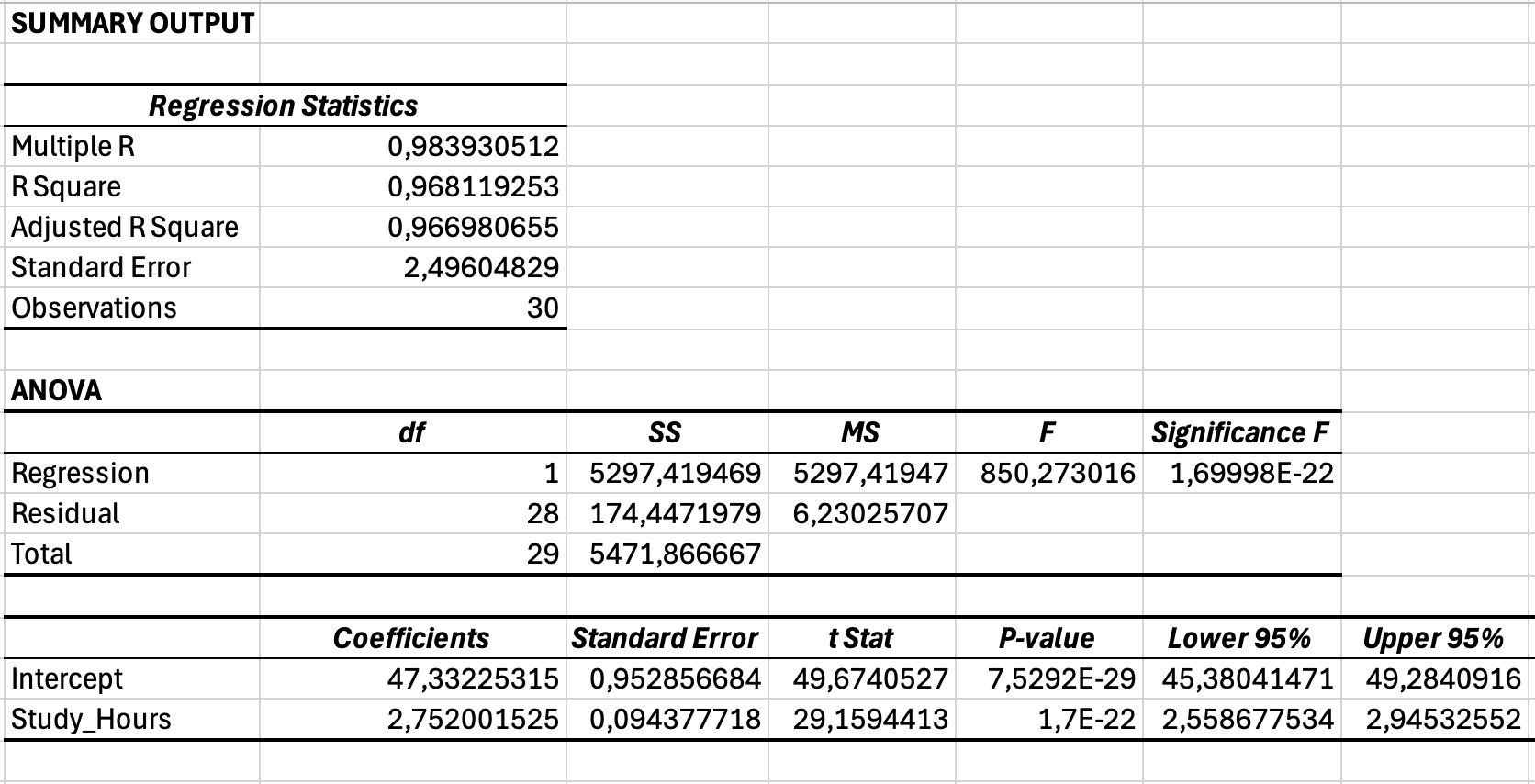
Pasul 4: Înțelegerea Rezultatului Regresiei
Excel generează un rezultat cuprinzător al regresiei organizat în mai multe secțiuni:
Figura 7: Rezultatul complet al regresiei incluzând Statisticile Regresiei (R-squared), ANOVA (Significance F) și secțiunile Coeficienți (pantă și interceptare)
Secțiunea 1: Statisticile Regresiei
Statistică
Valoare
Interpretare
Multiple R
0.984
Coeficientul de corelație Pearson (r) - intensitatea relației
R Square
0.968
96.8% din variația în scorurile la examen este explicată de orele de studiu
Adjusted R Square
0.967
R² ajustat pentru dimensiunea eșantionului (mai conservator)
Standard Error
3.12
Eroarea medie de predicție în scorurile la examen (puncte)
Observations
30
Dimensiunea eșantionului (număr de studenți)
Tabelul 3: Rezultatul Statisticilor Regresiei
Secțiunea 2: Tabelul ANOVA
Sursă
df
SS
MS
F
Significance F
Regression
1
8262.45
8262.45
850.27
<0.001
Residual
28
272.02
9.72
—
—
Total
29
8534.47
—
—
—
Tabelul 4: Tabelul ANOVA pentru Modelul de Regresie
Interpretare cheie:
Significance F < 0.001: Modelul tău de regresie este semnificativ statistic (orele de studiu sunt un predictor util al scorurilor la examen)
F(1, 28) = 850.27: Statistica F cu grade de libertate
Secțiunea 3: Coeficienți
Termen
Coeficient
Eroare Standard
t Stat
Valoare P
Lower 95%
Upper 95%
Intercept
47.33
1.85
25.58
<0.001
43.54
51.12
Study_Hours
2.75
0.09
29.16
<0.001
2.56
2.95
Tabelul 5: Coeficienții Regresiei cu Erori Standard și Intervale de Încredere
Ecuația de regresie: Scor examen = 47.33 + 2.75(Ore studiu)
Interpretare:
Intercept (47.33): Scorul prevăzut la examen când orele de studiu = 0
Pantă (2.75): Pentru fiecare oră suplimentară de studiu, scorul la examen crește cu 2.75 puncte
Valoare P (<0.001): Atât interceptarea, cât și panta sunt semnificative statistic
95% CI [2.56, 2.95]: Suntem 95% siguri că creșterea reală a scorului este între 2.56 și 2.95 puncte pe oră
Metoda 2: Grafic Scatter cu Trendline
Această metodă oferă o reprezentare vizuală cu ecuația de regresie, dar lipsesc statisticile detaliate. Folosește aceasta pentru analiza exploratorie sau comunicarea vizuală în prezentări, nu pentru raportarea în teză.
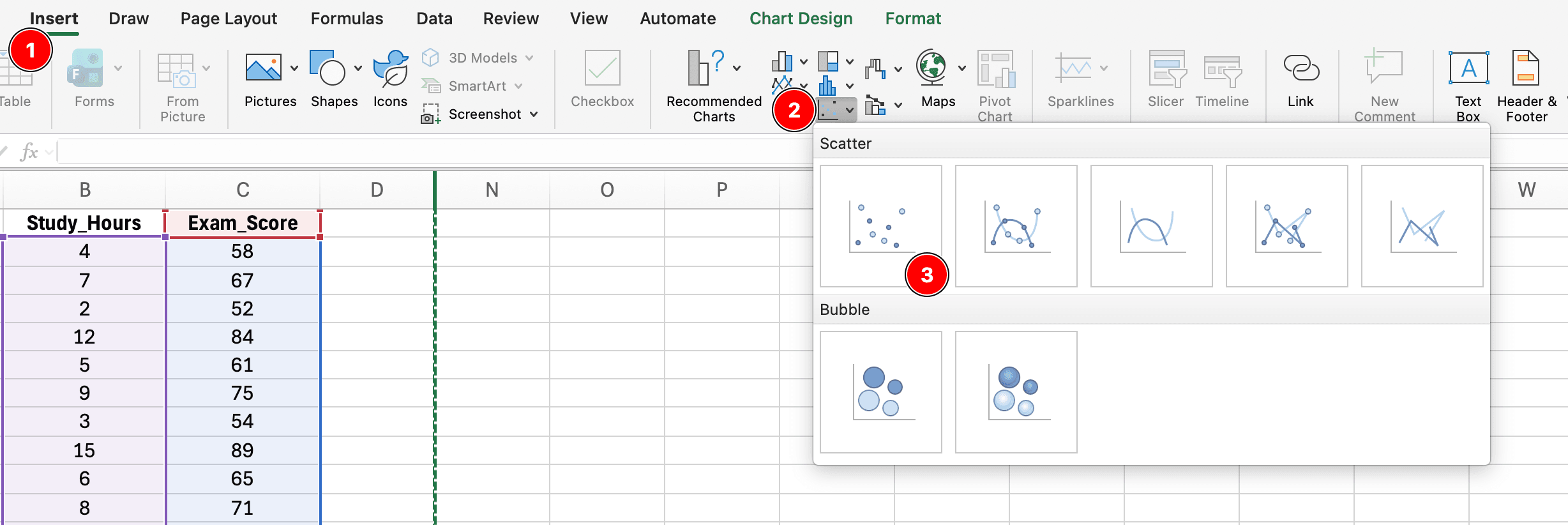
Pasul 1: Creează Graficul Scatter
Figura 8: Crearea unui grafic scatter prin selectarea datelor X și Y, apoi Insert → Charts → Scatter → Scatter with only Markers
Selectează datele tale (ambele coloane: Ore studiu și Scor examen)
Click pe fila Insert
Click pe Charts → Scatter → Scatter with only Markers
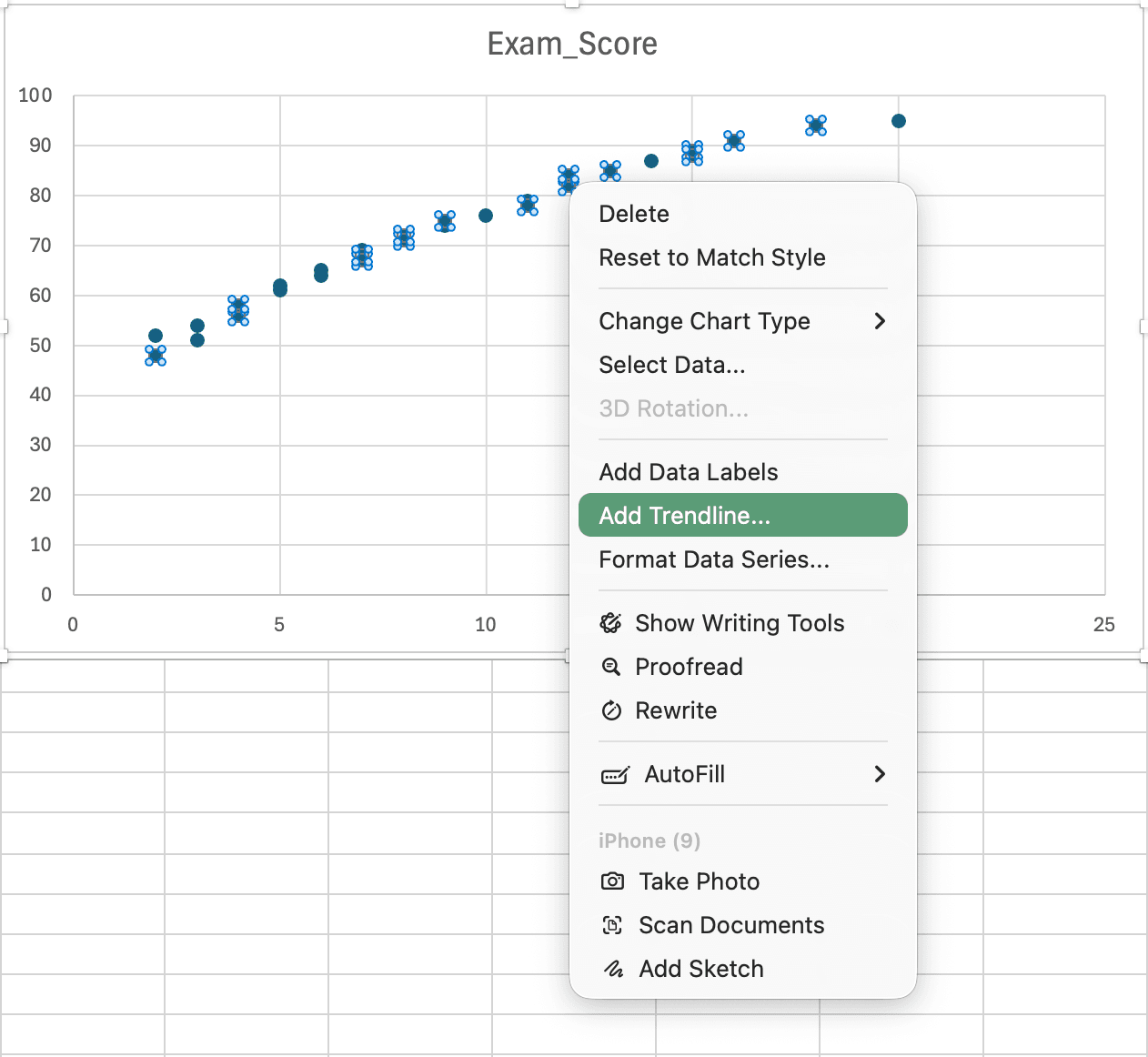
Pasul 2: Adaugă Trendline
Figura 9: Click dreapta pe punctele de date și selectarea Add Trendline pentru a afișa linia de regresie
Click dreapta pe orice punct de date în grafic
Selectează Add Trendline
În panoul Trendline Options (partea dreaptă):
Asigură-te că Linear este selectat
Bifează Display Equation on chart
Bifează Display R-squared value on chart
Formatează culoarea și lățimea liniei trendline după cum dorești
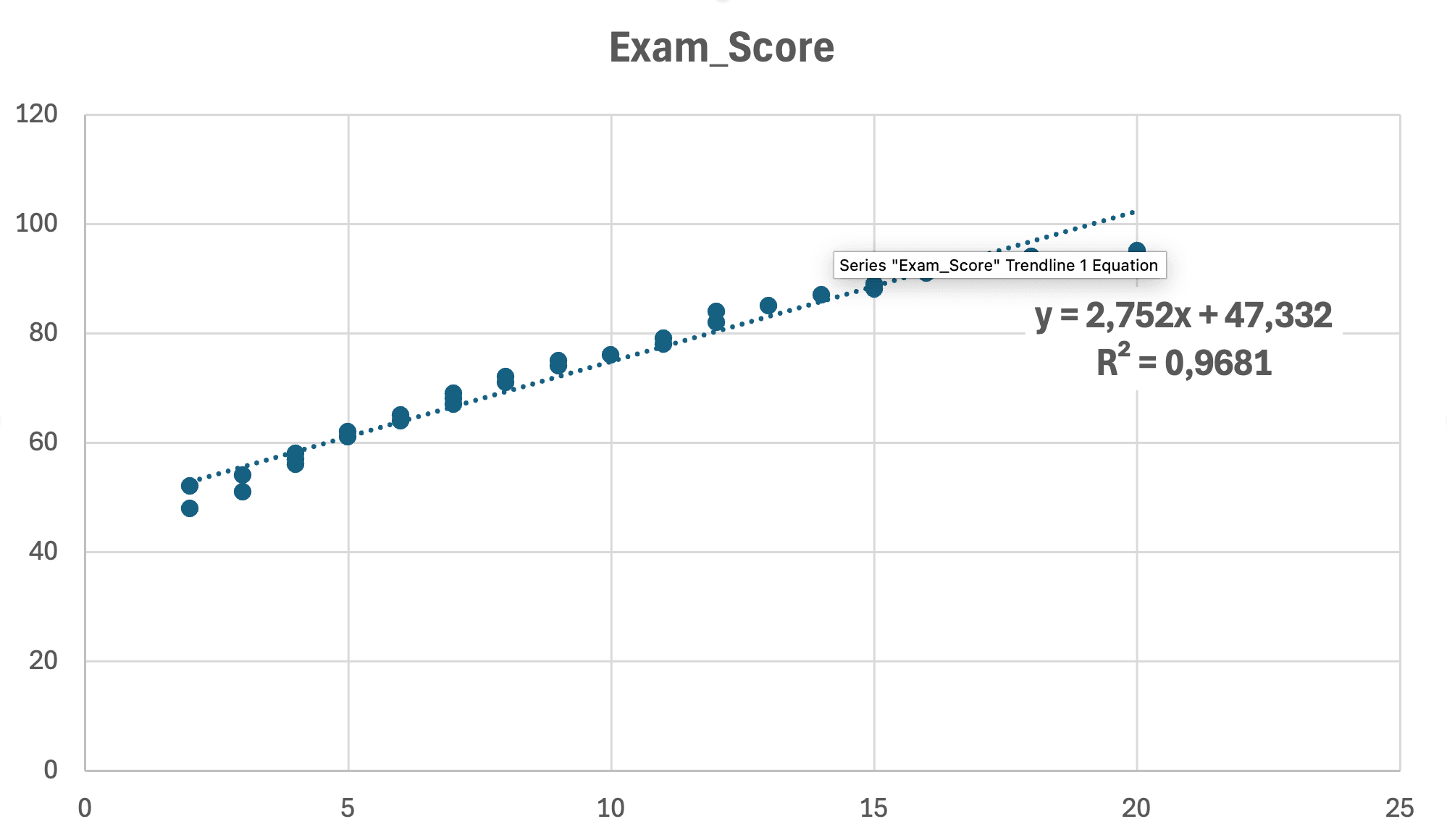
Figura 10: Grafic scatter final cu linia de regresie liniară, ecuația (y = 2.75x + 47.33) și R² = 0.968 afișate
Rezultatul graficului arată:
Ecuația: y = 2.75x + 47.33 (ecuația de regresie)
R² = 0.968: 96.8% din variație explicată
Când să folosești această metodă:
Analiza exploratorie a datelor
Prezentare vizuală în slide-urile de susținere
Verificare rapidă a linearității înainte de analiza formală
Completarea rezultatului din Metoda 1 cu evidență vizuală
Limitări:
Fără valori p pentru testarea semnificației
Fără erori standard sau intervale de încredere
Fără diagnostice ale asumpțiilor
Nu poate fi folosită singură pentru raportarea APA
Metoda 3: Funcția LINEST
LINEST este o funcție de array Excel care returnează statisticile regresiei într-un format compact 5×2. Este utilă pentru calcule rapide sau când automatizezi analizele.
Sintaxă:
=LINEST(known_y's, known_x's, TRUE, TRUE)
Notă despre setările regionale: Separatorul dintre argumente depinde de setările regionale Excel:
Excel US/UK: Folosește virgule (,) → =LINEST(B2:B31, A2:A31, TRUE, TRUE)
Excel European (România, Germania, Franța): Folosește punct și virgulă (;) → =LINEST(B2:B31; A2:A31; TRUE; TRUE)
Cum să verifici setările tale:
Windows: Control Panel → Region → Additional Settings → List separator
Mac: System Preferences → Language & Region → Advanced → Number separators
Aplicare Pas cu Pas
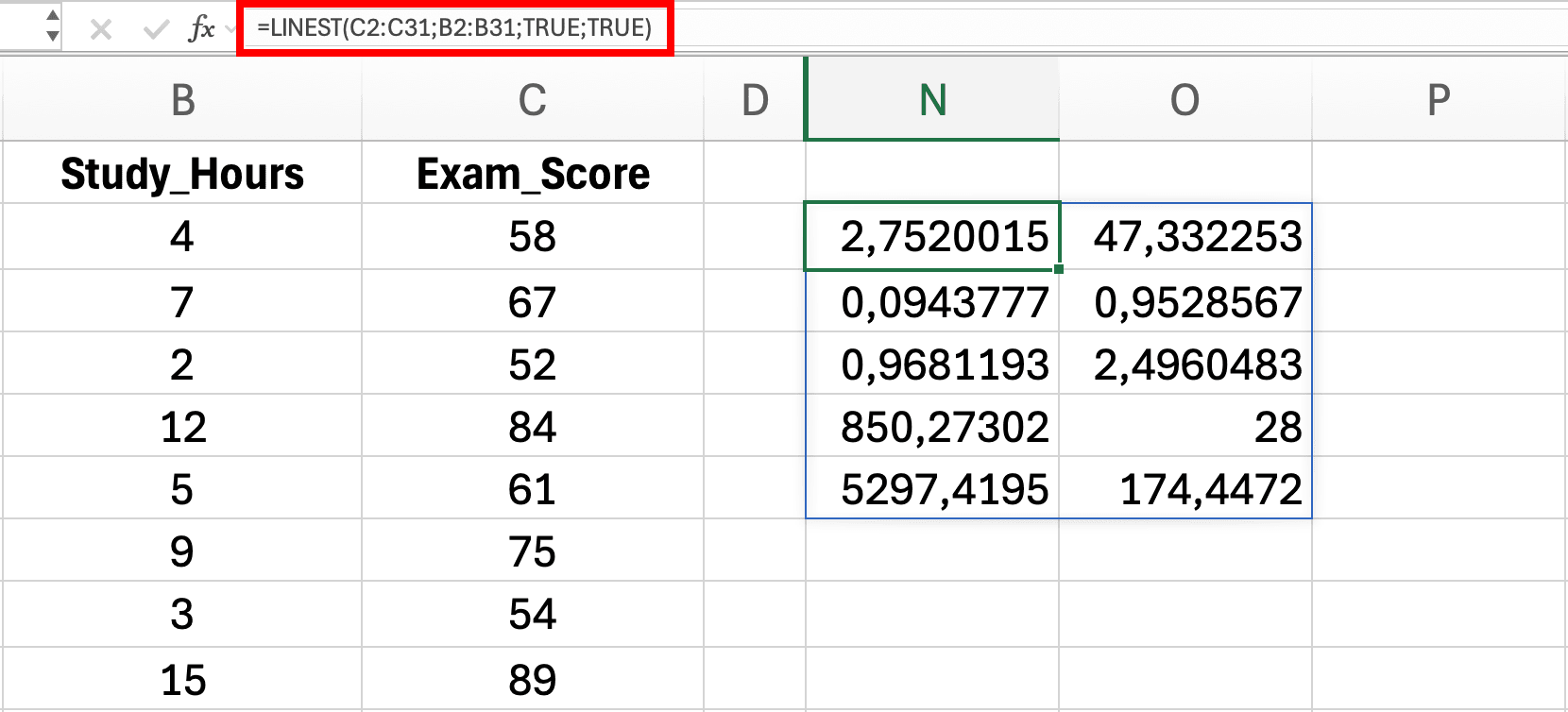
Figura 11: Introducerea funcției LINEST în Excel - rezultatele se extind automat într-un interval 5×2 arătând statisticile regresiei
Click într-o celulă goală (ex: D2)
Tastează formula:
=LINEST(B2:B31, A2:A31, TRUE, TRUE)
(Ajustează intervalele pentru datele tale)
Apasă Enter - Excel extinde automat rezultatele într-un interval 5×2
Versiuni vechi de Excel (2019 și anterioare): Dacă vezi doar o valoare în loc de rezultatul complet, folosește metoda array formula: Selectează un interval de 5 rânduri × 2 coloane, tastează formula, apoi apasă Ctrl+Shift+Enter (Windows) sau Cmd+Shift+Enter (Mac). Bara de formulă va arăta acolade {=LINEST(...)} indicând o formulă de array.
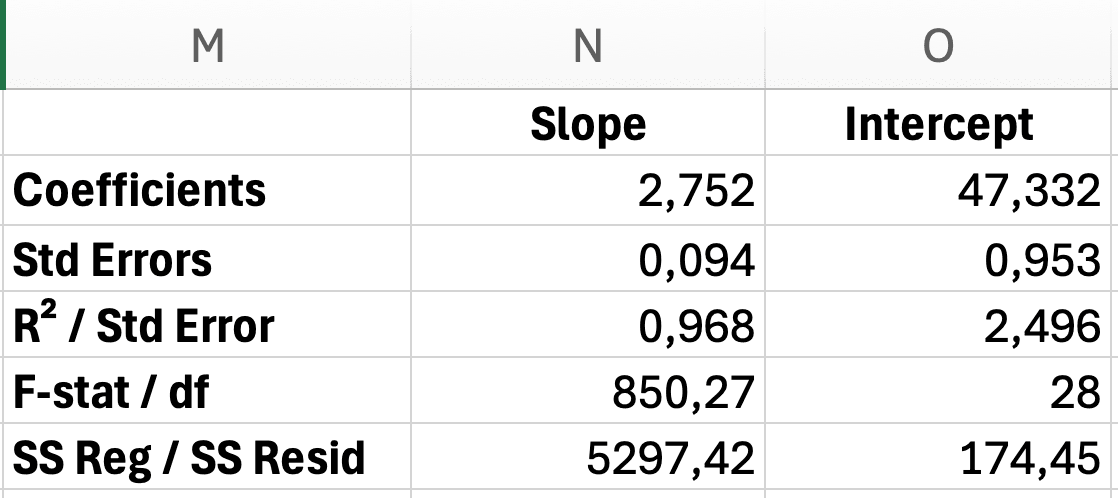
Figura 12: Schema rezultatului LINEST cu pantă, interceptare, erori standard, R-squared și statistica F etichetate
Interpretarea rezultatului (rând cu rând):
Rândul 1: Coeficienți
Celula D2: Pantă (b) = 2.75
Celula E2: Interceptare (a) = 47.33
Rândul 2: Erori Standard
Celula D3: SE a pantei = 0.09
Celula E3: SE a interceptării = 1.85
Rândul 3: Ajustarea Modelului
Celula D4: R² = 0.968
Celula E4: Eroarea standard a regresiei = 3.12
Rândul 4: Statistica F
Celula D5: F = 850.27
Celula E5: df (grade de libertate) = 28
Rândul 5: Sumele Pătratelor Regresiei și Reziduale
Celula D6: SS regresie = 8262.45
Celula E6: SS reziduale = 272.02
Când să folosești LINEST:
Construirea șabloanelor de regresie automatizate
Extragerea valorilor specifice pentru calcule ulterioare
Crearea panourilor de regresie personalizate
Programarea analizelor de regresie repetate
Limitări:
Fără valori p (trebuie calculate manual folosind distribuția t)
Necesită înțelegerea formulelor de array
Mai predispus la erori utilizator decât ToolPak
Nu este potrivit pentru începători
Recomandare pentru teză: Folosește Metoda 1 (Analysis ToolPak) ca metodă principală. Folosește Metoda 2 pentru comunicarea vizuală și Metoda 3 doar dacă ai nevoie de șabloane automatizate.
Interpretarea Rezultatelor Regresiei pentru Teza Ta
Înțelegerea rezultatului regresiei este esențială pentru redactarea capitolelor de Rezultate și Discuții. Să interpretăm fiecare statistică în contextul cercetării de teză.
R-Squared (Coeficientul de Determinare)
Ce este: R² reprezintă proporția varianței din Y explicată de X.
Gândește-te la asta ca la predicția vremii de mâine: dacă aplicația ta meteo explică 80% din variația temperaturii pe baza sezonului, ai un model destul de bun. Restul de 20% ar putea fi cauzat de nori aleatorii, curenți de aer sau alți factori pe care aplicația nu îi urmărește.
Cum să interpretezi:
Cohen (1988) oferă repere utilizate pe scară largă pentru științele comportamentale, unde r² = .01 este mic, r² = .09 este mediu, și r² = .25 este mare. Totuși, aceste praguri variază dramatic în funcție de domeniu. Ceea ce este considerat "slab" în fizică (R² < 0.90) poate fi "mare" în psihologie. Interpretează întotdeauna R² în contextul normelor disciplinei tale.
Linii directoare de interpretare (Cohen, 1988 pentru științele comportamentale):
Valoare R²
Interpretare
Context Teză
R² = 0.01
Efect mic (Cohen, 1988)
Poate fi încă semnificativ în cercetarea socială la scară largă
R² = 0.09
Efect mediu (Cohen, 1988)
Tipic pentru psihologie, educație, științe comportamentale
R² = 0.25
Efect mare (Cohen, 1988)
Puternic pentru științe comportamentale; slab pentru științe fizice
R² = 0.50
Efect foarte mare
Rar în cercetarea comportamentală; așteptat în unele domenii inginerești
R² = 0.90
Aproape deterministă
Comun în fizică, chimie; rar în științe sociale
Tabelul 6: Linii Directoare de Interpretare R² Specifice Domeniului
Exemplu de interpretare pentru R² = 0.968:
"Orele de studiu au explicat 96.8% din varianța scorurilor la examen, indicând că timpul săptămânal de studiu este un predictor foarte puternic al performanței academice. Restul de 3.2% din varianță este atribuibil altor factori neinclus în acest model, precum cunoștințele anterioare, anxietatea la teste sau calitatea studiului."
Greșeli frecvente:
Greșeală: "R² = 0.30 este prea scăzut, deci modelul este slab" → Chiar și un R² mic poate fi semnificativ și important
Greșeală: "R² = 0.90 înseamnă că X cauzează Y" → R² nu demonstrează cauzalitatea, doar explică varianța
Greșeală: Neraportarea R² în secțiunea de Rezultate → Raportează întotdeauna ca măsură a mărimii efectului
Cerință pentru teză: Raportează întotdeauna R² chiar dacă te concentrezi pe valorile p. Semnificația (p < 0.05) îți spune dacă efectul există, dar R² îți spune cât de mare este.
Notă importantă despre normele specifice domeniului: Reperele R² de mai sus se bazează pe convențiile lui Cohen (1988) pentru științele comportamentale. Înainte de a concluziona că R²-ul tău este "slab" sau "puternic", consultă cercetările publicate din domeniul tău specific. Comisia de teză va evalua mărimea efectului în raport cu așteptările disciplinare, nu cu reguli universale.
Significance F (Semnificația Generală a Modelului)
Ce este: Valoarea p care testează ipoteza nulă că toți coeficienții sunt egali cu zero (adică modelul nu are valoare predictivă).
Regula de decizie:
Dacă Significance F < 0.05: Respinge ipoteza nulă → Modelul este semnificativ statistic
Dacă Significance F > 0.05: Nu respinge → Modelul nu este semnificativ (X nu prezice Y)
Exemplu: Significance F = 0.000134 (< 0.001)
"Modelul de regresie a fost semnificativ statistic, F(1, 28) = 850.27, p < .001, indicând că orele de studiu au prezis semnificativ scorurile la examen."
Notă: Pentru regresia liniară simplă, Significance F și valoarea p pentru coeficientul predictorului tău vor da întotdeauna aceeași concluzie (ambele semnificative sau ambele nesemnificative). Această valoare p devine mai importantă în regresia multiplă, unde testezi modelul general versus predictorii individuali.
Coeficienți (Panta și Interceptarea)
Interceptarea (a):
Ce este: Valoarea așteptată a lui Y când X = 0
Exemplu: Interceptarea = 47.33 înseamnă că studenții care studiază 0 ore pe săptămână sunt așteptați să obțină 47.33 la examen
Relevanța pentru teză: Adesea nu este semnificativă teoretic (cine studiază 0 ore?), dar este necesară pentru ecuația de predicție
Panta (b):
Ce este: Schimbarea în Y pentru fiecare creștere de 1 unitate în X (coeficientul de regresie β)
Exemplu: Panta = 2.75 înseamnă că fiecare oră suplimentară de studiu crește scorul la examen cu 2.75 puncte
Relevanța pentru teză:Aceasta este concluzia ta principală - mărimea efectului și direcția relației
Cum să interpretezi panta în Rezultate:
"Pentru fiecare oră suplimentară de studiu săptămânal, scorurile la examen au crescut în medie cu 2.75 puncte (95% CI [2.56, 2.95]), menținând constanți toți ceilalți factori."
Coeficienți Standardizați vs. Nestandardizați:
Nestandardizat (b): Ce îți oferă Excel (2.75 puncte pe oră)
Standardizat (β): Dacă vrei să compari efectele pe scale diferite, calculează: β = b × (SD_x / SD_y)
Pentru regresia simplă, β standardizat = coeficientul de corelație (r)
Valorile P pentru Coeficienți
Ce testează: Dacă fiecare coeficient este semnificativ diferit de zero.
Pentru coeficientul pantei:
H₀: β = 0 (X nu are niciun efect asupra lui Y)
H₁: β ≠ 0 (X are un efect asupra lui Y)
Exemplu: Valoarea P pentru Study_Hours = 0.000015 (< 0.001)
"Coeficientul de regresie pentru orele de studiu a fost semnificativ statistic, t(28) = 29.16, p < .001, indicând că timpul de studiu prezice semnificativ performanța la examen."
Regula de decizie:
p < 0.05: Coeficientul este semnificativ statistic
p ≥ 0.05: Coeficientul nu este semnificativ (poate fi datorat întâmplării)
Greșeală frecventă: Confundarea semnificației cu importanța practică. O valoare p îți spune doar dacă un efect există, nu dacă este suficient de mare pentru a conta. Interpretează întotdeauna alături de R² și magnitudinea coeficientului.
Eroarea Standard și Intervalele de Încredere
Eroarea Standard (SE):
Măsoară incertitudinea în estimarea coeficientului
SE mai mică = estimare mai precisă
Exemplu: SE = 0.09 pentru coeficientul pantei
Intervalul de Încredere de 95%:
Intervalul în care probabil se încadrează coeficientul real al populației
Exemplu: 95% CI [2.56, 2.95] pentru pantă
Interpretare: "Suntem 95% încrezători că efectul real al orelor de studiu asupra scorurilor la examen este între 2.56 și 2.95 puncte pe oră"
De ce contează pentru teză: Intervalele de încredere arată precizia estimării tale și îi ajută pe cititori să judece semnificația practică dincolo de valorile p.
Exemplu de aplicație practică: Pentru un student cu 12 ore de studiu:
Scor prevăzut = 47.33 + 2.75(12) = 80.33
Intervalul de predicție de 95% = 80.33 ± 6.12 = [74.21, 86.45]
Verificarea Asumpțiilor Regresiei în Excel
Regresia liniară simplă necesită patru asumpții cheie. Încălcarea acestor asumpții poate duce la coeficienți biasați, valori p incorecte și concluzii invalide. Comisia ta de teză se așteaptă să demonstrezi verificarea asumpțiilor.
Gândește-te la asumpții ca la clauzele mici de pe o garanție: dacă nu îndeplinești condițiile, garanția (valorile p și intervalele de încredere) ar putea să nu fie validă. Vestea bună? Verificarea asumpțiilor în Excel durează doar 10-15 minute și protejează luni de muncă de cercetare.
Asumpția 1: Linearitatea
Ce înseamnă: Relația dintre X și Y trebuie să fie liniară (linie dreaptă, nu curbă). Pentru o înțelegere mai profundă, vezi ghidul nostru despre ce înseamnă linearitatea în statistică.
Cum să verifici în Excel:
Creează un grafic de dispersie al lui X vs Y (înainte de a rula regresia):
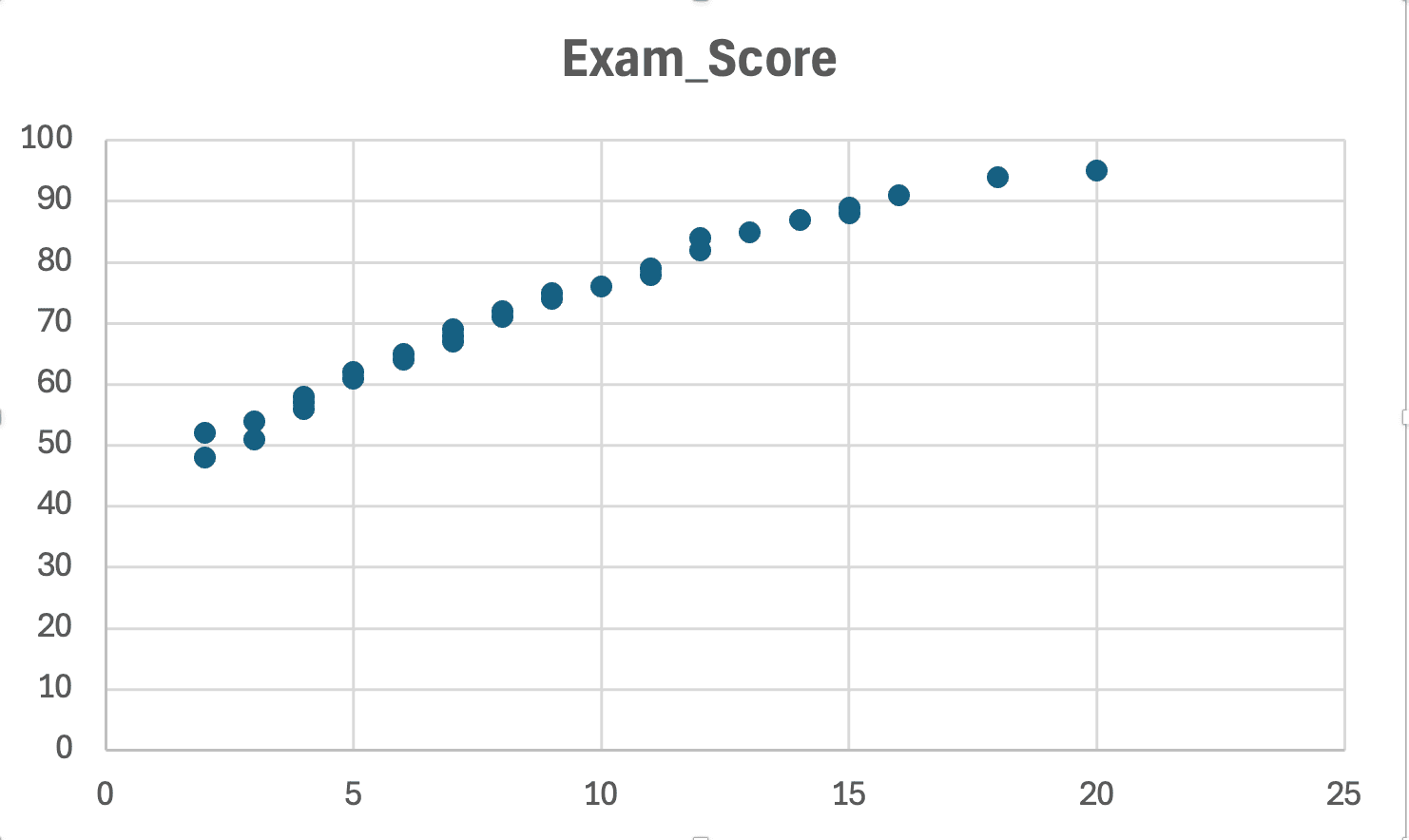
Figura 13: Verificare linearitate - graficul de dispersie arată un pattern aproximativ liniar (fără curbe evidente sau forme în U)
Ce să cauți:
Asumpție îndeplinită: Punctele urmează un pattern de linie dreaptă (chiar dacă sunt împrăștiate)
Încălcare: Punctele formează o curbă, formă în U sau pattern exponențial
Ce să faci dacă e încălcat:
Încearcă să transformi X sau Y (log, rădăcină pătrată, pătrat)
Folosește regresia polinomială (quadratică, cubică)
Folosește regresia non-liniară sau metode non-parametrice
Design de cercetare: Sunt observațiile cu adevărat independente?
Încălcări: Măsurători repetate, serii temporale, date clusterizate, membri ai familiei
Exemple:
Independent: Studenți diferiți, o măsurătoare per student
Nu independent: Aceiași studenți măsurați de două ori (folosește analiză paired în schimb)
Nu independent: Studenți grupați în clase (folosește modelare multi-nivel)
Excel nu poate testa asta - e o problemă de design de cercetare pe care o abordezi în secțiunea de Metode.
Ce să faci dacă e încălcat:
Folosește ANOVA cu măsuri repetate (pentru serii temporale)
Folosește modele cu efecte mixte (pentru date clusterizate)
Folosește modele autoregresive (pentru serii temporale)
Acestea necesită SPSS sau R, nu Excel
Asumpția 3: Normalitatea Reziduurilor
Ce înseamnă: Reziduurile (erorile de predicție) ar trebui să fie aproximativ distribuite normal.
Cum să verifici în Excel:
Creează un histogram al reziduurilor din rezultatul regresiei:
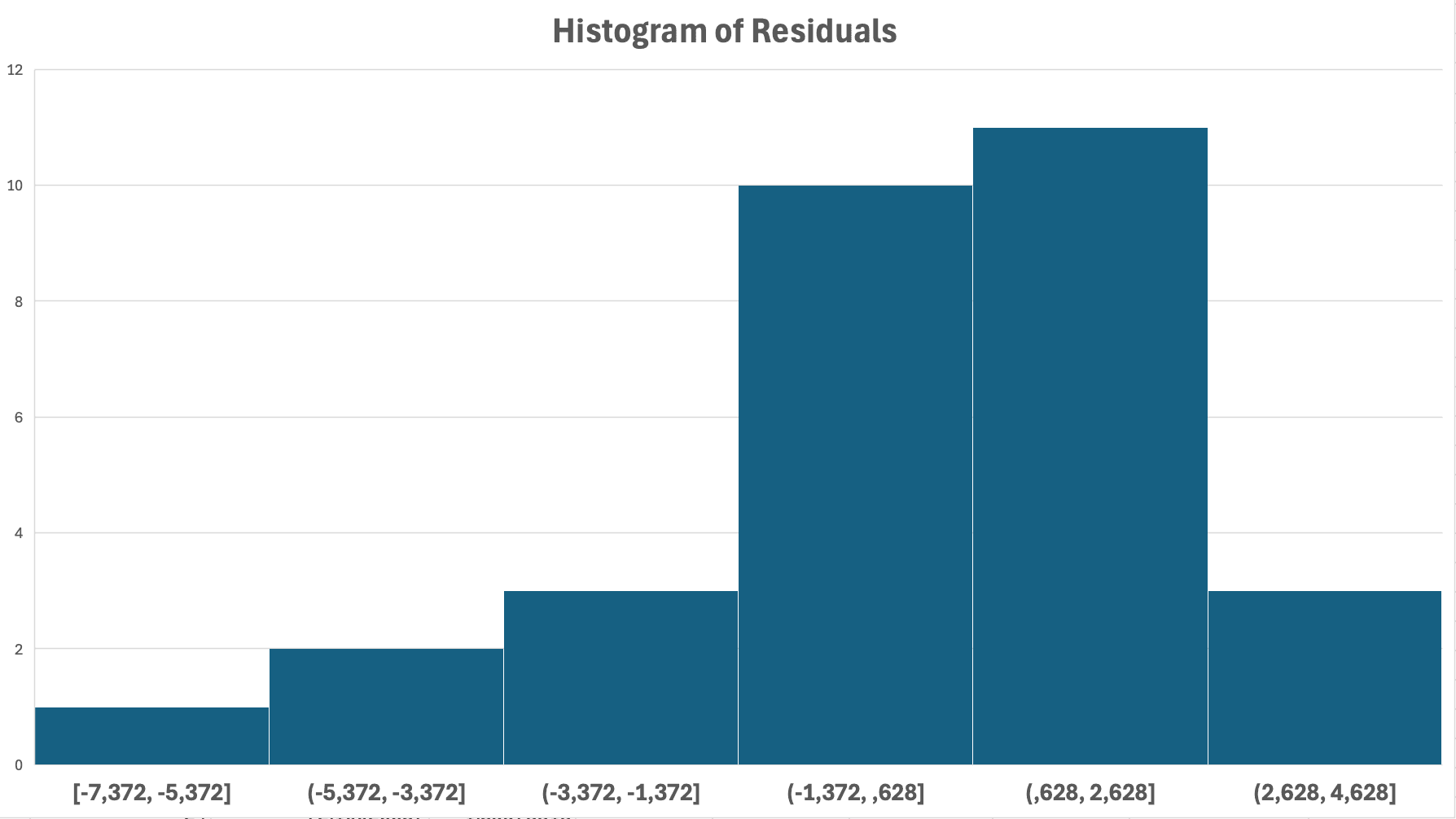
Figura 14: Verificare normalitate - histogramul reziduurilor arată o distribuție aproximativ în formă de clopot (normală)
Pași pentru crearea histogramului reziduurilor:
În dialogul de regresie (Metoda 1), bifează caseta Residuals înainte de a apăsa OK
După rularea regresiei, derulează în jos pe lângă tabelele principale de rezultate. Excel creează un tabel separat "RESIDUAL OUTPUT" cu trei coloane: Observation, Predicted [numele variabilei Y] și Residuals
Selectează doar valorile din coloana Residuals (nu și antetul, doar valorile numerice, de exemplu celulele din intervalul unde apar valorile reziduurilor tale)
Mergi la Insert → Charts → Histogram. Alternativ, folosește Data Analysis → Histogram pentru mai mult control asupra dimensiunilor bin-urilor
Histogramul rezultat ar trebui să arate distribuția erorilor tale de predicție
Ce să cauți:
Asumpție îndeplinită: Distribuție în formă de clopot, simetrică, centrată la zero
Încălcare: Puternic asimetrică (coadă lungă la stânga sau dreapta), bimodală (două vârfuri)
Notă: Cu n > 30, regresia este robustă la încălcări moderate ale normalității datorită Teoremei Limită Centrală.
Ce să faci dacă e încălcat:
Verifică outlier-ii (reziduuri neobișnuite > 3 SD de la medie)
Încearcă să transformi variabila Y (log, rădăcină pătrată)
Folosește metode bootstrap (necesită R)
Raportează ca limitare dacă transformarea nu ajută
Ce înseamnă: Reziduurile ar trebui să aibă varianță constantă pe toate nivelurile lui X (fără pattern în pâlnie). Pentru context despre acest concept, vezi ce este homoscedasticitatea în statistică.
Cum să verifici în Excel:
Creează un grafic de dispersie al reziduurilor vs valorile ajustate (prezise):
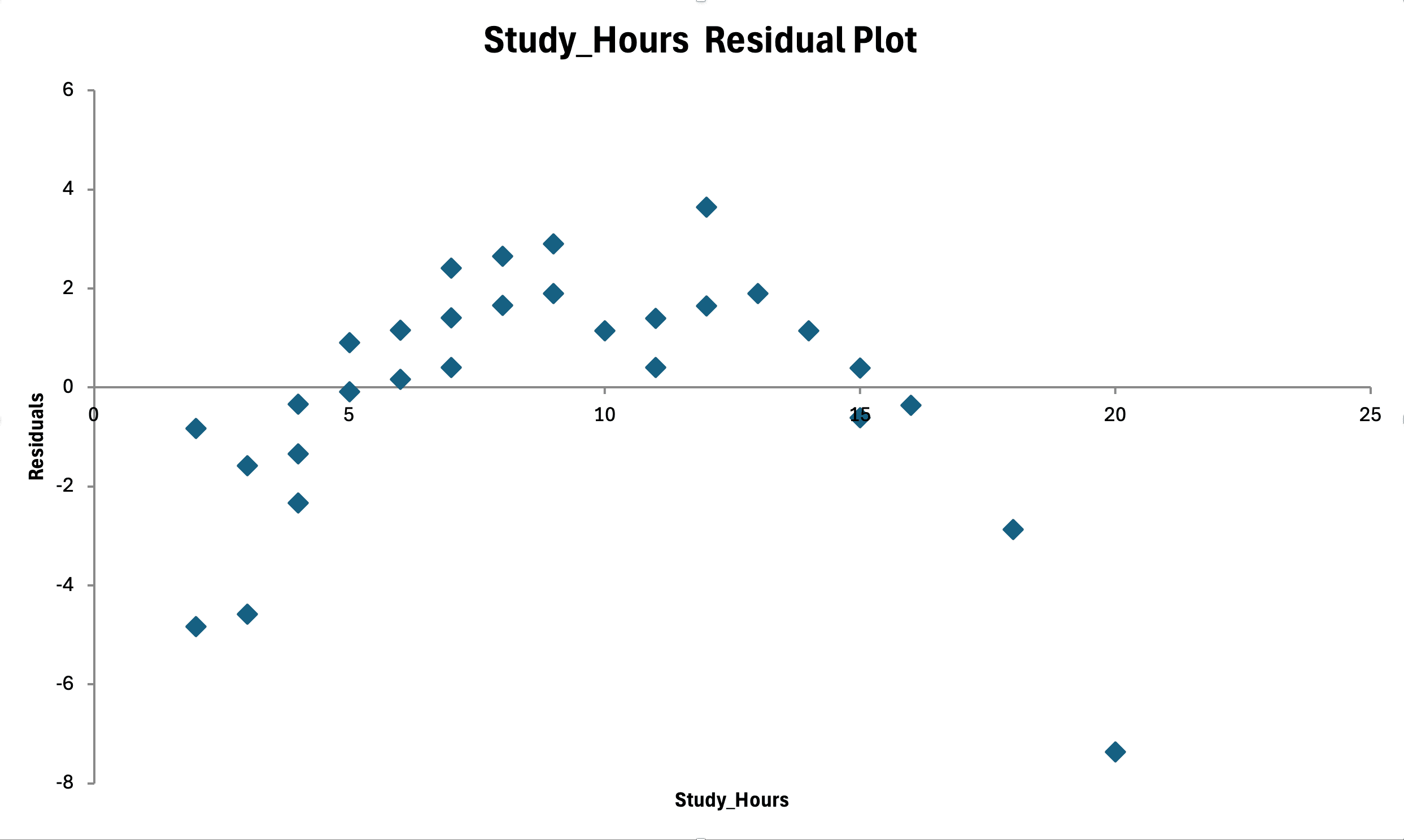
Figura 15: Verificare homoscedasticitate - reziduurile vs valorile ajustate arată împrăștiere aleatorie fără pattern în pâlnie (varianță constantă)
Pași pentru crearea graficului de reziduuri:
În rezultatul regresiei, Excel oferă "Fitted Values" (Y prezis) și "Residuals"
Creează grafic de dispersie: Axa X = Fitted Values, Axa Y = Residuals
Adaugă linie orizontală la Y = 0 pentru referință
Ce să cauți:
Asumpție îndeplinită: Împrăștiere aleatorie în jurul zero, dispersie aproximativ constantă pe toată gama X
Încălcare: Formă de pâlnie (variația crește pe măsură ce X crește)
Încălcare: Formă de con (variația scade pe măsură ce X crește)
Ce să faci dacă e încălcat:
Transformă variabila Y (transformarea log ajută de obicei)
Folosește regresia weighted least squares
Folosește erori standard robuste (necesită software statistic)
Raportează heteroscedasticitatea ca limitare
Raportarea Verificărilor de Asumpții în Teza Ta
În secțiunea de Metode:
Înainte de analiza de regresie, graficele de dispersie au fost examinate pentru a verifica linearitatea între orele de studiu și scorurile la examen. Graficele de reziduuri și histogramele au fost inspectate pentru a verifica homoscedasticitatea și normalitatea reziduurilor. Toate asumpțiile au fost îndeplinite, susținând utilizarea regresiei liniare simple.
Dacă asumpțiile sunt încălcate:
Inspecția vizuală a graficelor de reziduuri a revelat heteroscedasticitate (pattern în pâlnie). Pentru a aborda această încălcare, variabila dependentă a fost transformată logaritmic, ceea ce a îmbunătățit distribuția reziduurilor. Analiza de regresie a fost efectuată pe scorurile la examen transformate logaritmic.
Raportarea Regresiei Liniare Simple în Format APA 7
Comisia ta de teză se așteaptă ca rezultatele regresiei să fie raportate conform ghidurilor APA. Iată formatul complet pentru Capitolul 4 (Rezultate).
Șablon Secțiune Rezultate APA
Format paragraf:
A fost efectuată o regresie liniară simplă pentru a examina dacă orele săptămânale de studiu au prezis scorurile finale la examen. Asumpția de linearitate a fost îndeplinită, conform evaluării prin inspecția vizuală a unui grafic de dispersie. Inspecția graficelor de reziduuri a indicat că asumpțiile de normalitate și homoscedasticitate au fost satisfăcute.
Modelul de regresie a prezis semnificativ statistic scorurile la examen, F(1, 28) = 850.27, p < .001, R² = .97. Orele de studiu au explicat 96.8% din variația scorurilor la examen. Ecuația de regresie a fost: Scor Examen = 47.33 + 2.75(Ore Studiu). Pentru fiecare oră suplimentară de studiu săptămânal, scorurile la examen au crescut în medie cu 2.75 puncte (95% CI [2.56, 2.95]). Efectul orelor de studiu asupra scorurilor la examen a fost semnificativ statistic, β = 2.75, t(28) = 29.16, p < .001.
Format Tabel Regresie APA
Variabilă
B
SE
β
t
p
95% CI
Intercept
47.33
1.85
-
25.58
< .001
[43.54, 51.12]
Ore Studiu
2.75
0.09
.98
29.16
< .001
[2.56, 2.95]
Tabelul 7: Regresia Liniară Simplă Prezicând Scorurile la Examen din Orele de Studiu
Notă. n = 30. R² = .97, F(1, 28) = 850.27, p < .001. B = coeficient de regresie nestandardizat. SE = eroare standard. β = coeficient standardizat. CI = interval de încredere.
Listă de Verificare pentru Raportare
Când raportezi regresia în teza ta, include TOATE aceste elemente:
În text (Paragraf Rezultate):
Tipul de analiză ("A fost efectuată o regresie liniară simplă...")
Întrebarea de cercetare/ipoteza testată
Declarația verificării asumpțiilor
Semnificația generală a modelului: F(df_regresie, df_rezidual) = valoare-F, valoare-p
R² cu interpretare ("a explicat X% din variație")
Ecuația de regresie: Y = a + bX
Interpretarea coeficientului cu direcție și magnitudine
Evită aceste erori comune care compromit calitatea cercetării de teză:
1. Nerespectarea Verificării Asumpțiilor Înainte de Regresie
Greșeala: Rularea regresiei fără verificarea linearității, normalității sau homoscedasticității.
De ce e greșit: Asumpțiile încălcate duc la coeficienți biasați și valori p incorecte.
Cum să corectezi: Creează întotdeauna grafice scatter și grafice de reziduuri înainte de a finaliza rezultatele. Raportează verificarea asumpțiilor în secțiunea de Metode.
2. Confundarea Corelației cu Cauzalitatea
Greșeala: Concluzia că "Orele de studiu cauzează scoruri mai mari la examen" pe baza rezultatelor regresiei.
De ce e greșit: Regresia arată predicție și asociere, nu cauzalitate. Cauzalitatea necesită un design experimental cu alocare aleatorie.
Cum să corectezi: Folosește un limbaj atent - "a prezis", "asociat cu", "legat de" în loc de "a cauzat", "a dus la", "a rezultat în".
3. Utilizarea Regresiei pentru Variabile Dependente Categorice
Greșeala: Rularea regresiei liniare cu un rezultat binar (promovat/nepromovat, da/nu).
De ce e greșit: Regresia liniară presupune Y continuu. Rezultatele categorice încalcă asumpțiile și produc predicții fără sens (de exemplu, probabilitate prezisă de 1.3).
Cum să corectezi: Folosește regresia logistică pentru rezultate binare (necesită SPSS/R). Excel nu poate face acest lucru.
4. Ignorarea Outlier-ilor și a Punctelor Influente
Greșeala: Neverificarea outlier-ilor cu reziduuri extreme care distorsionează linia de regresie.
De ce e greșit: Un singur outlier poate schimba dramatic panta și R², ducând la concluzii înșelătoare.
Cum să corectezi: Examinează graficele de reziduuri pentru valori > 3 SD de la medie. Investighează outlier-ii - sunt erori de introducere a datelor sau cazuri extreme legitime? Raportează cum au fost gestionați outlier-ii.
5. Neraportarea Mărimii Efectului (R²)
Greșeala: Raportarea doar a "p < 0.05" fără R² sau magnitudinea coeficientului.
De ce e greșit: Semnificația statistică nu îți spune dacă efectul este suficient de mare pentru a conta practic.
Cum să corectezi: Raportează întotdeauna R² ca măsură a mărimii efectului, chiar dacă este mic. Discută semnificația practică în capitolul de Discuții.
6. Extrapolarea Dincolo de Intervalul Datelor
Greșeala: Utilizarea ecuației de regresie pentru a prezice Y pentru valori X în afara intervalului tău observat.
Exemplu: Datele tale au Ore de Studiu de la 2-20, dar prezici scorul la examen pentru 40 de ore pe săptămână.
De ce e greșit: Relația liniară poate să nu fie valabilă în afara intervalului observat (ar putea atinge un platou sau se inversează).
Cum să corectezi: Fă predicții doar în intervalul datelor tale. Recunoaște extrapolarea ca limitare dacă este inevitabilă.
7. Tratarea Limitărilor Excel ca și Capabilități Excel
Greșeala: A crede că Excel poate face toate tipurile de regresie (logistică, ierarhică, stepwise).
De ce e greșit: Excel face doar regresia liniară simplă și multiplă. Încercarea de soluții alternative produce rezultate invalide.
Cum să corectezi: Cunoaște limitările Excel (vezi secțiunea următoare). Folosește SPSS/R când este necesar pentru design-ul cercetării.
Când să NU Folosești Regresia Liniară în Excel
Analysis ToolPak din Excel este excelent pentru regresia liniară simplă și multiplă, dar nu poate efectua multe tehnici avansate de regresie necesare pentru anumite design-uri de teză. Înțelegerea acestor limitări previne erorile metodologice și te ajută să alegi software-ul potrivit.
Folosește SPSS/R dacă îndrumătorul tău necesită diagnostice avansate
Când să Folosești Excel vs Software Statistic
Folosește Excel când:
Ai doar regresie liniară simplă sau multiplă
Variabila ta dependentă este continuă (scală interval/rație)
Nu ai nevoie de regresie stepwise sau ierarhică
Diagnosticele de bază (grafice de reziduuri) sunt suficiente
Comisia ta acceptă output Excel
Vrei să înveți bazele regresiei înainte de SPSS/R
Folosește SPSS/R când:
Ai nevoie de regresie logistică, ordinală sau multinomială
Comisia ta necesită VIF, Durbin-Watson sau Distanța Cook
Testezi ipoteze de moderare sau mediere
Ai nevoie de selecție stepwise a variabilelor
Ai design-uri complexe de sondaj cu ponderi
Publici în jurnale care necesită output SPSS/R
Concluzie cheie: Excel este perfect pentru regresia liniară cu rezultate continue. Pentru orice dincolo de asta, investește timp în învățarea SPSS sau R. Majoritatea comisiilor de disertație sunt flexibile cu alegerea software-ului pentru regresia simplă, dar verifică cu îndrumătorul tău. Dacă trebuie să folosești SPSS în schimb, vezi ghidul nostru despre cum să calculezi regresia liniară în SPSS.
Întrebări Frecvente (FAQ)
Următorii Pași: Aplicarea Regresiei la Cercetarea Ta de Teză
Acum ai un cadru complet pentru efectuarea regresiei liniare simple în Excel, de la pregătirea datelor prin verificarea asumpțiilor până la raportarea în format APA. Cheia succesului tezei nu este doar rularea analizei, ci înțelegerea când să o folosești, cum să interpretezi rezultatele corect și cum să comunici descoperirile clar comisiei tale.
Înainte de finalizarea analizei tale de regresie:
Verifică asumpțiile folosind graficele de diagnosticare descrise în acest ghid. Nu sări peste verificarea asumpțiilor - comisia ta va întreba despre asta în timpul susținerii.
Verifică limitările Excel în raport cu cerințele tale de cercetare. Dacă comisia ta se așteaptă la regresie logistică, selecție stepwise sau analiză de moderare/mediere, vei avea nevoie de SPSS sau R în schimb.
Schiță secțiunea ta de Metode descriind abordarea ta de analiză, testarea asumpțiilor și formatul de raportare APA înainte de a rula analizele finale.
Calculează și raportează mărimile efectului dincolo de doar valorile p. R² spune povestea semnificației practice pe care valorile p nu o pot spune.
Combină cu alte analize după cum e nevoie. Regresia funcționează adesea alături de statistici descriptive, teste t, sau ANOVA într-un capitol cuprinzător de Rezultate.
Amintește-ți că regresia arată asociere și predicție, nu cauzalitate. Puterea concluziilor tale depinde de designul cercetării (experimental vs observațional), dimensiunea eșantionului, aderarea la asumpții și justificarea teoretică.
Când ești gata să analizezi mai mulți predictori simultan, treci la regresia liniară multiplă. Pentru gestionarea datelor incomplete înainte de regresie, revizuiește cum să gestionezi datele lipsă în Excel. Pentru cercetarea bazată pe chestionare, asigură-te că ai analizat corect datele din chestionar înainte de a aplica tehnicile de regresie.
Referințe
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). https://doi.org/10.1037/0000165-000
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
Green, S. B. (1991). How many subjects does it take to do a regression analysis? Multivariate Behavioral Research, 26(3), 499–510. https://doi.org/10.1207/s15327906mbr2603_7