Am revizuit sute de seturi de date pentru lucrări de licență și disertație de-a lungul anilor, iar aceleași greșeli apar în mod repetat. Studenții petrec săptămâni colectând date din chestionare, doar pentru a-și compromite rezultatele cu erori Excel care puteau fi prevenite.
Aceste greșeli se încadrează în patru etape critice: configurarea pre-analiză, curățarea datelor, analiza statistică și prezentarea rezultatelor. O singură eroare în oricare etapă poate invalida întreaga ta analiză.
Acest ghid îți arată cele 10 greșeli frecvente pe care le fac studenții când analizează datele din chestionare în Excel și cum să le corectezi înainte de a depune lucrarea.
Greșeli în Configurarea Pre-Analiză
Aceste greșeli se întâmplă înainte să rulezi vreun test statistic. Identificarea lor din timp economisește ore de muncă refăcută.
Greșeala #1: Neinstalarea Analysis ToolPak de la Început
Problema:
Deschizi Excel, pregătit să rulezi un test t sau ANOVA, și descoperi că nu există opțiunea de analiză statistică în fila Data. Cauți prin toate meniurile și nu găsești nimic.
Excel nu include teste statistice implicit. Add-in-ul Analysis ToolPak trebuie instalat manual.
Cum să Corectezi:
Pentru instrucțiuni complete de instalare (Windows și Mac), consultă ghidul nostru: Cum să Activezi Data Analysis în Excel.
Pași rapizi pentru Windows:
- Dă clic pe File în colțul din stânga sus
- Selectează Options în partea de jos a meniului
- Dă clic pe Add-ins în bara laterală din stânga
- În partea de jos, găsește dropdown-ul "Manage:", selectează Excel Add-ins, dă clic pe Go
- Bifează caseta de lângă Analysis ToolPak
- Dă clic pe OK
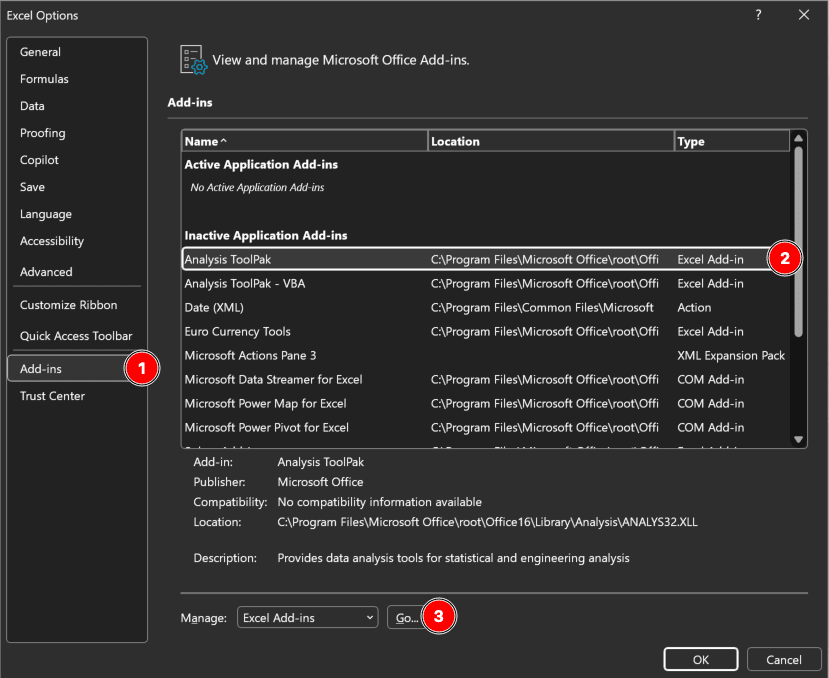 Figura 1: Dialogul Add-ins din Excel cu Analysis ToolPak activat (Windows)
Figura 1: Dialogul Add-ins din Excel cu Analysis ToolPak activat (Windows)
Utilizatori Mac: Mergi la Tools → Excel Add-ins în loc de File → Options.
După instalare, butonul Data Analysis apare în fila Data (în partea dreaptă). Acest buton îți oferă acces la teste t, ANOVA, regresie, corelație și statistici descriptive.
Prevenire:
Instalează Analysis ToolPak prima dată când deschizi Excel pentru lucrarea ta. Adaugă-l pe lista de verificare pentru configurarea cercetării înainte de a colecta orice date.
Greșeala #2: Amestecarea Textului cu Numerele în Coloanele de Răspunsuri
Problema:
Răspunsurile din chestionarul tău conțin text precum "Total de acord", "De acord", "Neutru", "Dezacord" și "Total dezacord". Când încerci să calculezi scorul mediu de satisfacție, Excel returnează o eroare sau zero.
Textul nu poate fi folosit în formule statistice. Funcțiile Excel precum AVERAGE, STDEV și CORREL necesită input numeric.
Cum să Corectezi:
Codifică toate răspunsurile numeric înainte de analiză. Creează o legendă într-o foaie separată:
| Cod Numeric | Etichetă Text |
|---|---|
| 1 | Total dezacord |
| 2 | Dezacord |
| 3 | Neutru |
| 4 | De acord |
| 5 | Total de acord |
Tabelul 1: Codificare numerică pentru răspunsurile pe scala Likert în 5 puncte
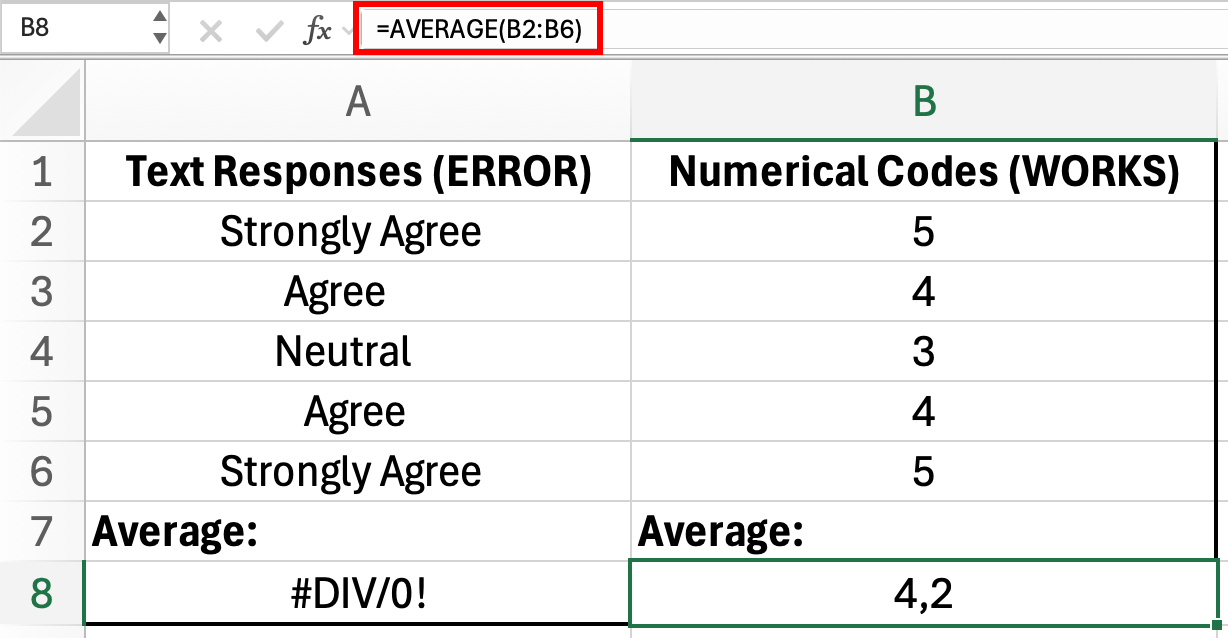 Figura 2: Răspunsurile text nu pot fi folosite în formula AVERAGE (eroare în A8), dar codurile numerice funcționează corect (4.2 în B8)
Figura 2: Răspunsurile text nu pot fi folosite în formula AVERAGE (eroare în A8), dar codurile numerice funcționează corect (4.2 în B8)
Când exporti din instrumente de sondaj (Google Forms, Qualtrics, SurveyMonkey), selectează opțiunea pentru valori numerice în loc de etichete text.
Dacă ai deja răspunsuri text:
- Creează o coloană nouă
- Folosește =IF sau =VLOOKUP pentru a converti textul în numere
- Șterge coloana text originală după verificare
Prevenire:
Configurează setările de export ale chestionarului pentru a genera coduri numerice de la început. Majoritatea platformelor au opțiunea "Export as numerical values (1-n)".
Greșeala #3: Introducerea Inconsistentă a Datelor
Problema:
Ai introdus manual răspunsurile din chestionar și ai folosit formate inconsistente. Unii respondenți sunt codificați ca "Masculin", alții ca "M", și câțiva ca "Bărbat". Când creezi un Pivot Table pentru a rezuma răspunsurile pe gen, Excel arată trei categorii separate în loc de una.
Această problemă apare și cu variații de scriere: "Total de acord" vs "Totaldeacord" vs "Total de acord" (spațiu extra). Fiecare variație devine o categorie separată în analiza ta.
Notă: Pivot Tables și COUNTIF nu sunt sensibile la majuscule, deci "M" și "m" vor fi numărate împreună. Totuși, scrieri diferite precum "Masculin", "M" și "Bărbat" sunt întotdeauna tratate ca valori separate.
 Figura 3: Pivot Table tratează "Masculin", "M" și "Bărbat" ca trei categorii separate din cauza introducerii inconsistente a datelor
Figura 3: Pivot Table tratează "Masculin", "M" și "Bărbat" ca trei categorii separate din cauza introducerii inconsistente a datelor
Frecvențele tale sunt acum împărțite pe mai multe rânduri, făcând imposibilă raportarea totalurilor corecte fără consolidare manuală.
Cum să Corectezi:
Folosește Data Validation pentru a restricționa introducerile înainte de colectarea datelor:
- Selectează coloana unde vor fi introduse răspunsurile
- Mergi la fila Data
- Dă clic pe Data Validation
- Sub "Allow:", selectează List
- În "Source:", tastează valorile permise:
Masculin,Feminin,Altul(separate prin virgulă) - Dă clic pe OK
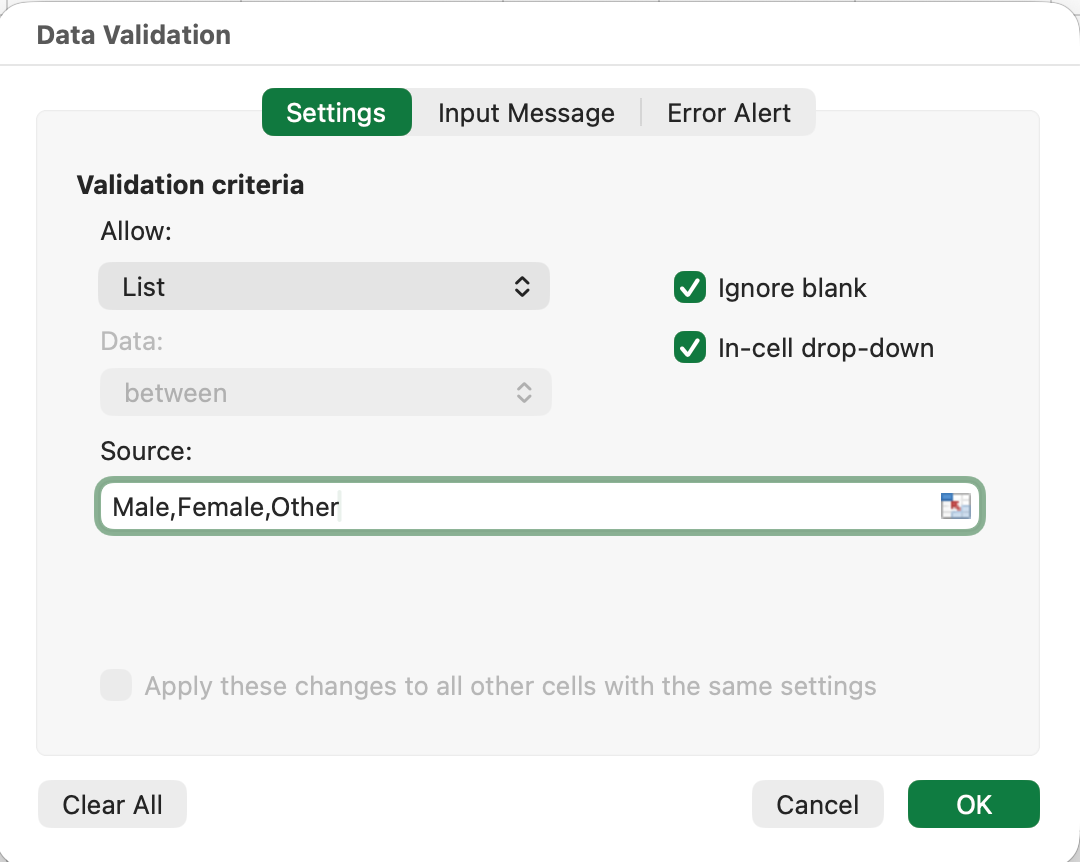 Figura 4: Configurarea Data Validation pentru a restricționa introducerile la valorile din lista predefinită
Figura 4: Configurarea Data Validation pentru a restricționa introducerile la valorile din lista predefinită
Acum, utilizatorii pot selecta doar din lista dropdown. Tastarea este dezactivată, eliminând inconsistențele.
Dacă datele sunt deja introduse inconsistent:
- Folosește Find & Replace (Ctrl+H) pentru a standardiza
- Găsește "M" → Înlocuiește cu "Masculin" (cu "Match entire cell contents" bifat)
- Găsește "Bărbat" → Înlocuiește cu "Masculin"
- Repetă pentru toate variațiile
Prevenire:
Configurează Data Validation înainte de a colecta orice date. Pentru chestionarele online, asta se întâmplă automat prin platforma de sondaj.
Greșeli în Curățarea Datelor
Datele brute din chestionare sunt rareori pregătite pentru analiză. Aceste greșeli apar când studenții sar peste faza de curățare.
Greșeala #4: Ignorarea Datelor Lipsă
Problema:
Unii respondenți au sărit întrebări, lăsând celule goale în setul tău de date. Rulezi AVERAGE pe o coloană și obții 4.2. Coordonatorul tău întreabă: "Cum ai gestionat datele lipsă?" Realizezi că nu ai documentat niciodată abordarea ta.
Funcția AVERAGE din Excel exclude automat celulele goale atât din sumă, cât și din numărare. Acest comportament poate sau nu să corespundă metodologiei tale intenționate:
- Ce face Excel: (suma celor 80 de valori non-goale) / 80 = 4.2
- Abordare alternativă: Tratează lipsa ca zero: (suma celor 80 de valori) / 100 = 3.36
- Altă abordare: Imputare cu mediana: (suma celor 80 de valori + 20 × mediană) / 100
Problema nu este că Excel "greșește" - este că ai luat o decizie metodologică fără să realizezi. Dacă nu documentezi cum au fost gestionate datele lipsă, evaluatorii vor pune sub semnul întrebării rezultatele tale.
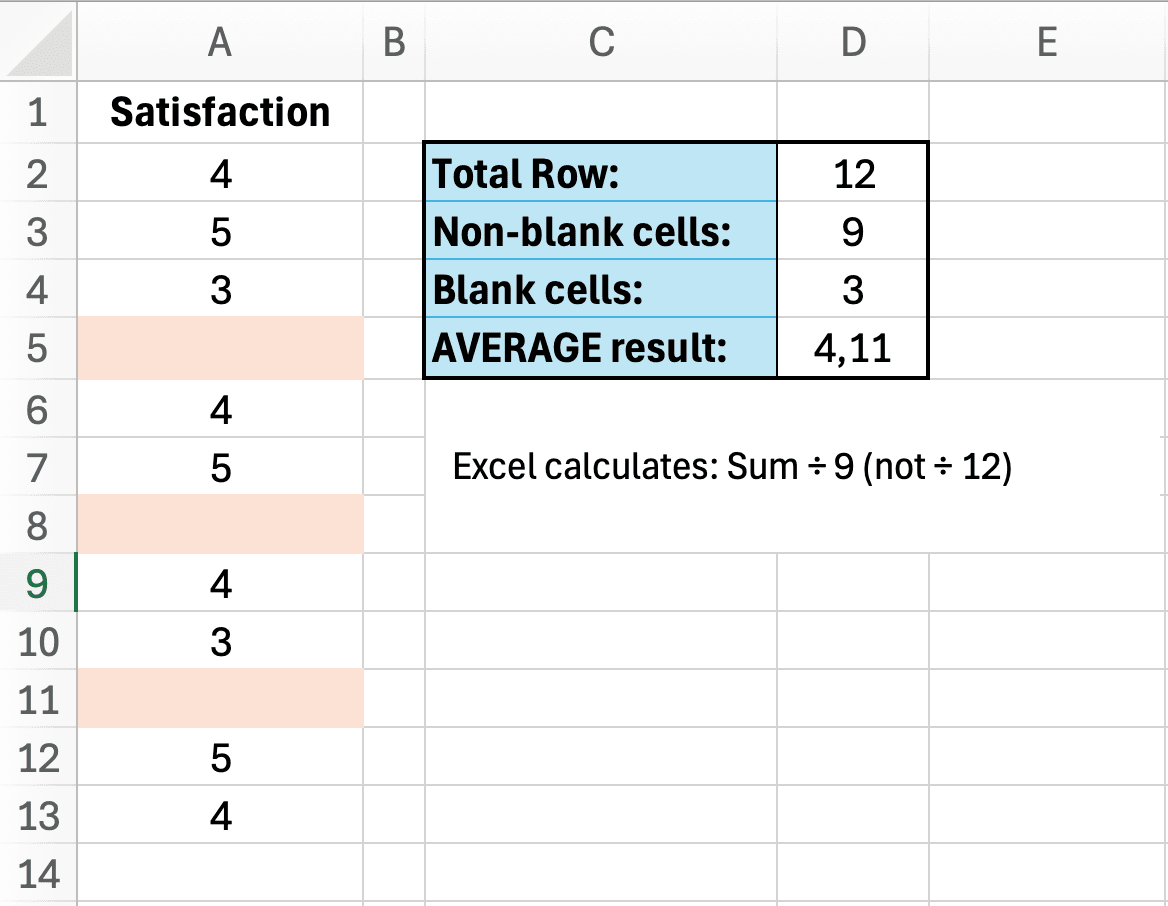 Figura 5: Funcția AVERAGE din Excel exclude celulele goale, ceea ce poate sau nu să corespundă metodologiei tale intenționate
Figura 5: Funcția AVERAGE din Excel exclude celulele goale, ceea ce poate sau nu să corespundă metodologiei tale intenționate
Cum să Corectezi:
Mai întâi, identifică cât de multe date lipsesc:
=COUNTA(B2:B101) // Numără celulele non-goale
=ROWS(B2:B101) // Total rânduri (ar trebui să fie 100)
=ROWS(B2:B101)-COUNTA(B2:B101) // Număr date lipsăApoi, alege o strategie:
Strategia 1: Șterge întregul rând (dacă datele lipsesc complet aleatoriu)
- Selectează rândurile cu valori lipsă
- Clic dreapta → Delete
- Actualizează dimensiunea eșantionului (n=80 în loc de n=100)
Strategia 2: Înlocuiește cu mediana (pentru date numerice)
- Calculează mediana: =MEDIAN(B2:B101)
- Completează celulele goale cu această valoare
- Notează în metodologie: "Valorile lipsă au fost înlocuite cu mediana"
Strategia 3: Codifică ca "Lipsă" (pentru date categorice)
- Înlocuiește celulele goale cu 99 sau "Lipsă"
- Exclude din calculele statistice
- Raportează separat: "85 răspunsuri valide, 15 lipsă"
Prevenire:
Fă toate întrebările din chestionar obligatorii (cu excepția cazurilor în care este inadecvat din punct de vedere etic). Dacă datele lipsă sunt inevitabile, planifică strategia de gestionare înainte de analiză.
Notă importantă pentru lucrarea ta:
Documentează strategia ta pentru datele lipsă în secțiunea de metodologie. Scrie: "Valorile lipsă (n=15, 15%) au fost [șterse/înlocuite cu mediana/codificate separat] deoarece [justificare]."
Evaluatorii vor pune sub semnul întrebării gestionarea nedocumentată a datelor lipsă.
Greșeala #5: Neverificarea Răspunsurilor Duplicate
Problema:
Un respondent a trimis accidental chestionarul de două ori. Altul a folosit două adrese de email diferite. Dimensiunea eșantionului tău este umflată, iar unele răspunsuri sunt ponderate de două ori în analiza ta.
Cum să Corectezi:
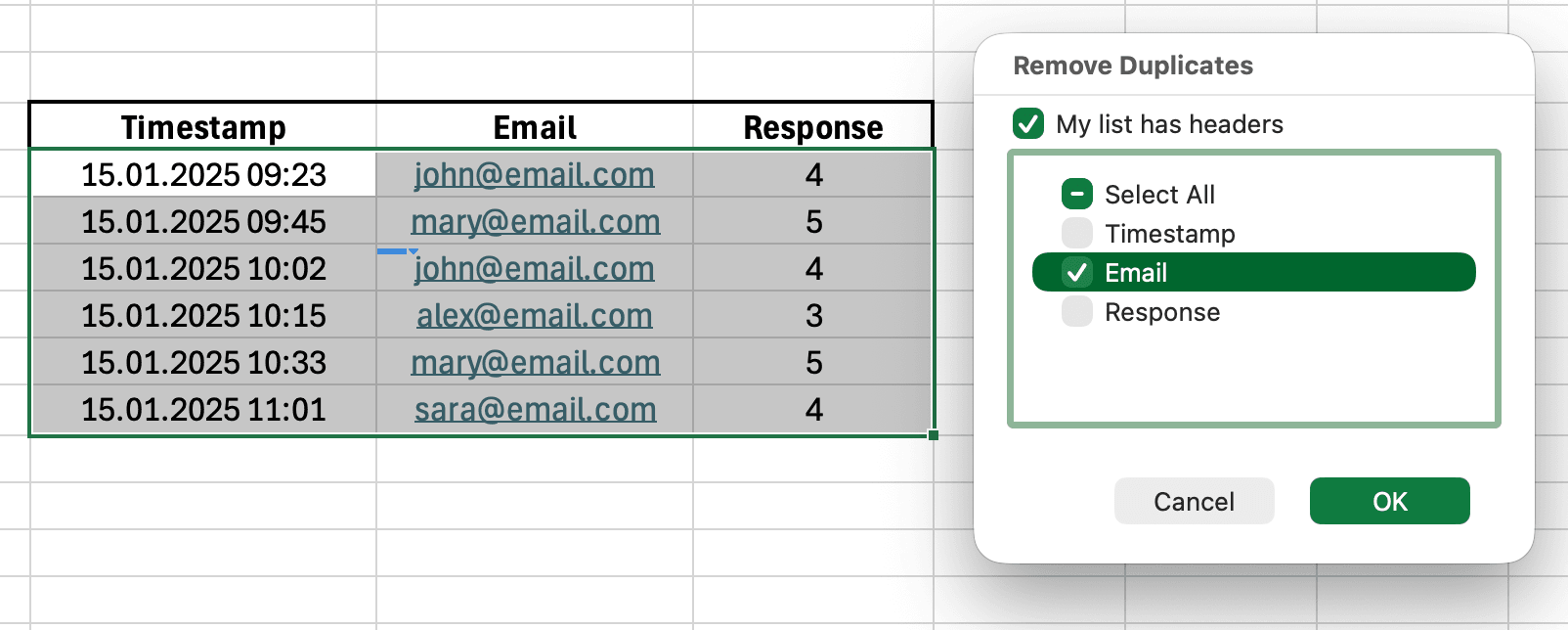 Figura 6: Dialogul Remove Duplicates cu Email selectat pentru a găsi trimiterile duplicate de chestionar
Figura 6: Dialogul Remove Duplicates cu Email selectat pentru a găsi trimiterile duplicate de chestionar
- Selectează întregul set de date (Ctrl+A)
- Mergi la fila Data
- Dă clic pe butonul Remove Duplicates
- Alege coloanele de verificat (de obicei Timestamp sau Email)
- Dă clic pe OK
Excel arată câte duplicate au fost găsite și eliminate. Actualizează dimensiunea eșantionului corespunzător.
Pentru chestionarele online, verifică setările platformei tale:
- Google Forms: Limitează la 1 răspuns per email
- Qualtrics: Activează "Prevent Ballot Box Stuffing"
- SurveyMonkey: Solicită email-ul respondentului
Prevenire:
Activează prevenirea duplicatelor în setările chestionarului tău. Pentru chestionarele pe hârtie, atribuie fiecărui respondent un ID unic și verifică ID-urile duplicate înainte de analiză.
Calculează Mărimea Eșantionului
Folosește calculatorul nostru gratuit pentru a determina mărimea eșantionului necesar folosind Yamane, Cochran și Krejcie & Morgan. Compară cele trei metode și obține o citare APA.
Încearcă CalculatorulGreșeli în Analiza Statistică
Aceste greșeli se întâmplă în timpul analizei propriu-zise și duc adesea la concluzii incorecte.
Greșeala #6: Folosirea Testului Statistic Greșit
Problema:
Vrei să compari scorurile de satisfacție între trei departamente (Marketing, Vânzări, Operațiuni). Rulezi trei teste t separate:
- Marketing vs. Vânzări (p=0.04)
- Marketing vs. Operațiuni (p=0.06)
- Vânzări vs. Operațiuni (p=0.03)
Această abordare este greșită. Testele t multiple cresc rata erorilor de tip I (fals pozitive). Cu trei comparații, rata ta reală de eroare nu este 5% ci aproximativ 14%.
Cum să Corectezi:
Folosește testul potrivit pentru întrebarea ta de cercetare:
| Întrebare de Cercetare | Număr de Grupuri | Test Corect |
|---|---|---|
| Compară două grupuri | 2 | Test t independent |
| Compară trei sau mai multe grupuri | 3+ | ANOVA unifactorial |
| Testează același grup de două ori | 2 (perechi) | Test t pereche |
| Relație între variabile | 2 (continue) | Corelație Pearson |
| Compară date categorice | 2+ (categorice) | Test chi-pătrat |
Tabelul 2: Ghid de selecție a testului statistic pentru întrebări de cercetare comune
Pentru exemplul cu cele trei departamente, abordarea corectă este:
- Rulează ANOVA unifactorial pentru a testa dacă vreun grup diferă
- Dacă este semnificativ (p < 0.05), rulează teste post-hoc pentru a identifica care perechi specifice diferă
- Raportează: "ANOVA unifactorial a relevat diferențe semnificative, F(2,297)=4.82, p=0.009"
Prevenire:
Înainte de a colecta date, identifică testul tău statistic. Consultă ghidul nostru de decizie T-Test vs ANOVA pentru o diagramă completă.
Greșeala #7: Calcularea Cronbach's Alpha pe Itemi cu Codificare Inversă
Problema:
Calculezi Cronbach's alpha pentru o scală de auto-eficacitate cu 5 itemi și obții α=0.45 (fiabilitate slabă). Verifici din nou introducerea datelor și formulele. Totul pare corect.
Problema: Scala ta include itemi formulați negativ care nu au fost codificați invers.
Exemplu de scală:
- "Mă simt încrezător în abilitățile mele" (pozitiv)
- "Pot face față majorității provocărilor" (pozitiv)
- "Mă îndoiesc adesea de competențele mele" (negativ - necesită inversare)
- "Sunt capabil să învăț lucruri noi" (pozitiv)
- "NU cred în mine" (negativ - necesită inversare)
Când respondenții sunt total de acord cu itemul 3 (scor=5), de fapt au auto-eficacitate SCĂZUTĂ. Aceasta trebuie inversată la 1 înainte de a calcula alpha.
Cum să Corectezi:
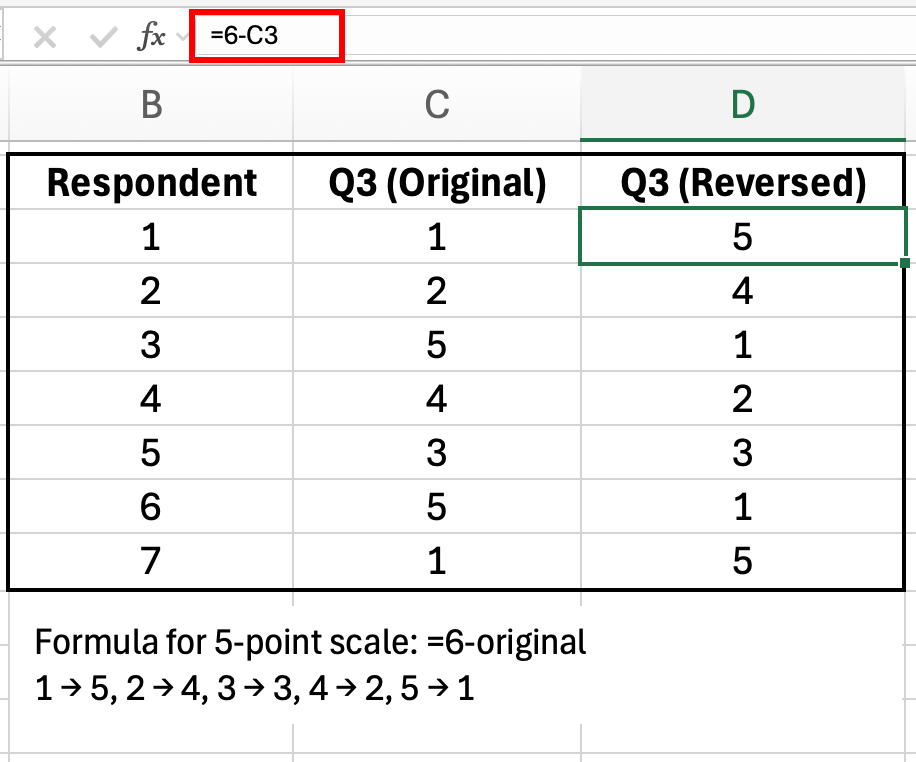 Figura 7: Formula de codificare inversă pentru o scală în 5 puncte: =6-valoare_originală
Figura 7: Formula de codificare inversă pentru o scală în 5 puncte: =6-valoare_originală
Pentru o scală în 5 puncte (1-5), folosește această formulă:
=6-B2Pentru o scală în 7 puncte (1-7):
=8-B2Formula generală:
=(valoare_MAX + valoare_MIN) - valoare_originalăDupă inversarea itemilor formulați negativ, recalculează Cronbach's alpha. Fiabilitatea ta va crește probabil de la 0.45 la 0.80+.
Prevenire:
Când proiectezi chestionarul, marchează care itemi necesită codificare inversă. Înainte de a calcula orice statistici de fiabilitate, creează o secțiune "Itemi Inversați" în fișierul tău Excel și aplică formula.
Consultă ghidul nostru despre interpretarea rezultatelor Cronbach's alpha pentru depanarea altor probleme de fiabilitate.
Greșeala #8: Formula Greșită pentru Procente
Problema:
Raportezi: "50 de respondenți au fost de acord cu afirmația."
Evaluatorul lucrării tale întreabă: "50 din câți? Ce procent?"
Calculezi procentele manual și te încurci. Procentele tale dau 94% sau 107% în loc de 100%. Erorile comune includ:
- Folosirea numitorului greșit: Împărțirea la total rânduri (inclusiv headerele sau rândurile goale) în loc de răspunsurile valide
- Amestecarea formulelor: Folosirea COUNTA pentru unele rânduri și COUNT pentru altele
- Uitarea de a exclude datele lipsă: Includerea celulelor goale în numărarea totală
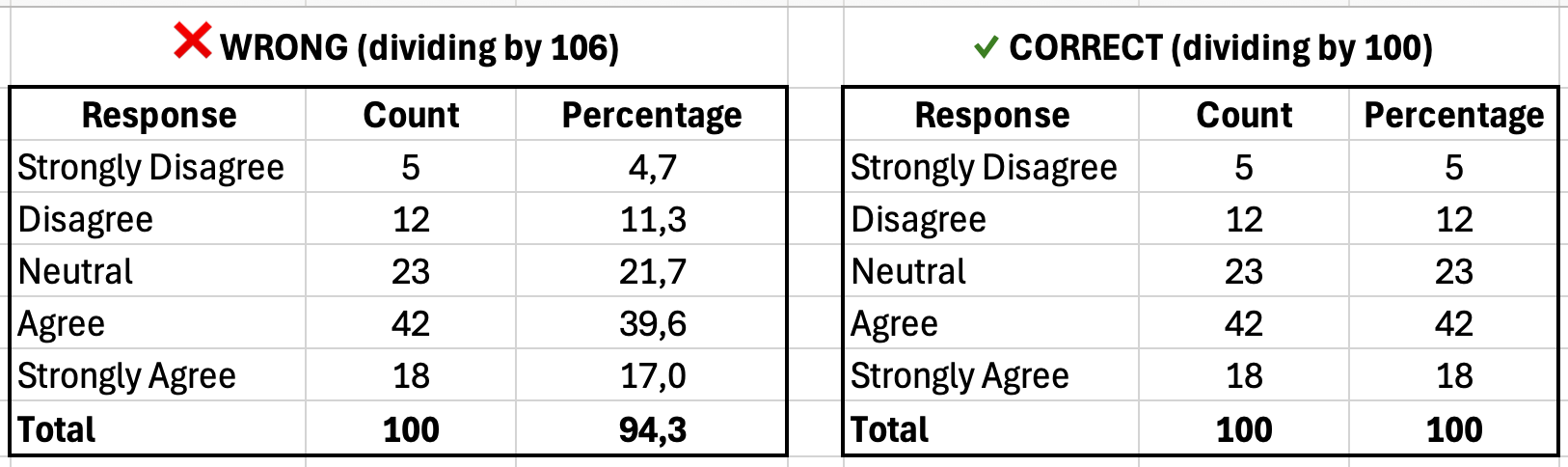 Figura 8: Stânga arată procente incorecte (94% total din cauza numitorului greșit); dreapta arată calculul corect (100% total)
Figura 8: Stânga arată procente incorecte (94% total din cauza numitorului greșit); dreapta arată calculul corect (100% total)
Cum să Corectezi:
Raportează întotdeauna atât numărul, cât și procentul, folosind formule consistente:
// Numără câți au spus "De acord" (codat ca 4)
=COUNTIF(B2:B101, 4)
// Total respondenți
=COUNTA(B2:B101)
// Procent
=COUNTIF(B2:B101, 4) / COUNTA(B2:B101) * 100Exemplu de tabel de frecvență cu procente:
Modelul de formulă pentru fiecare rând este:
=COUNTIF(B:B, [valoare_răspuns]) / COUNTA(B:B) * 100Unde [valoare_răspuns] este 1 pentru "Total dezacord", 2 pentru "Dezacord", etc.
| Răspuns | Număr | Procent |
|---|---|---|
| Total dezacord | 5 | 5.0% |
| Dezacord | 12 | 12.0% |
| Neutru | 23 | 23.0% |
| De acord | 42 | 42.0% |
| Total de acord | 18 | 18.0% |
| Total | 100 | 100.0% |
Tabelul 3: Tabel de frecvență arătând distribuția răspunsurilor (procentele trebuie să dea 100%)
Verificare de control:
Adună toate procentele. Trebuie să dea 100% (permițând o eroare de rotunjire de 0.1%). Dacă totalul tău este 98% sau 103%, ai o eroare de formulă.
Prevenire:
Creează un șablon cu formule de procent pre-construite. Refolosește acest șablon pentru toate întrebările din chestionar.
Greșeli în Prezentarea Rezultatelor
Analiza ta poate fi corectă, dar prezentarea slabă îți subminează credibilitatea.
Greșeala #9: Raportarea Prea Multor Zecimale
Problema:
Raportezi media satisfacției ca 3,8462857143 (outputul brut al Excel).
Acest nivel de precizie este fals. O scală Likert în 5 puncte nu poate măsura satisfacția la 10 zecimale. Raportezi precizie de măsurare pe care instrumentul tău nu o are.
Cum să Corectezi:
Folosește funcția ROUND:
=ROUND(AVERAGE(B2:B101), 2)Aceasta returnează 3.85 în loc de 3.8462857143.
Zecimale recomandate:
| Statistică | Zecimale | Exemplu |
|---|---|---|
| Media (M) | 2 | M = 3.85 |
| Deviația standard (SD) | 2 | SD = 0.92 |
| Corelație (r) | 3 | r = 0.547 |
| Valoarea p | 3 | p = 0.003 |
| Dimensiunea efectului (Cohen's d) | 2 | d = 0.65 |
| Procent | 1 | 42.0% |
Tabelul 4: Zecimale recomandate APA pentru statistici comune
Prevenire:
Aplică ROUND la toate statisticile calculate înainte de a le copia în lucrare. Setează formatul de afișare al Excel la 2 zecimale pentru întregul tabel de rezultate.
Consultă ghidul nostru despre raportarea statisticilor descriptive în format APA pentru reguli complete de formatare.
Greșeala #10: Crearea Graficelor Înșelătoare
Problema:
Creezi un grafic cu bare comparând satisfacția medie între trei grupuri:
- Grupul A: 3.8
- Grupul B: 3.9
- Grupul C: 4.0
Pentru a face diferențele să pară mai impresionante, setezi minimul axei Y la 3.5 în loc de 0. Graficul arată acum bara Grupului C ca fiind de două ori mai înaltă decât cea a Grupului A, deși diferența reală este doar de 0.2 puncte.
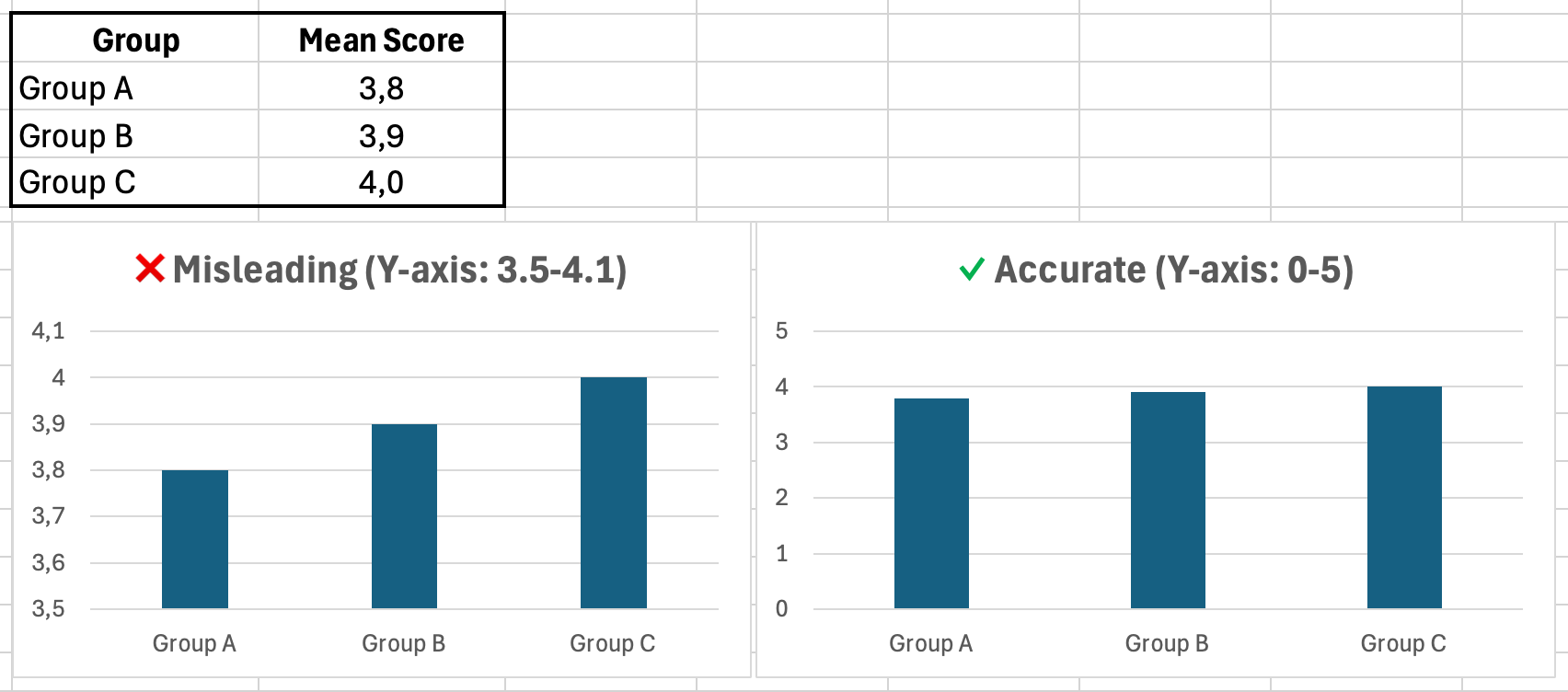 Figura 9: Aceleași date, scale diferite pe axa Y. Graficul din stânga exagerează diferențele; graficul din dreapta arată proporțiile corecte
Figura 9: Aceleași date, scale diferite pe axa Y. Graficul din stânga exagerează diferențele; graficul din dreapta arată proporțiile corecte
Cum să Corectezi:
Urmează aceste reguli pentru grafice:
- Începe întotdeauna axa Y de la zero pentru graficele cu bare (cu excepția cazului în care ai o justificare puternică)
- Folosește grafice 2D (evită graficele pie 3D, care distorsionează percepția)
- Etichetează axele clar (include unitățile)
- Folosește culori consistente (nu atribui aleatoriu culori grupurilor)
- Include bare de eroare pentru medii (eroarea standard sau IC 95%)
Pentru datele pe scală Likert (1-5), setează axa Y de la 0 la 5, chiar dacă toate răspunsurile se încadrează între 3 și 4.
Prevenire:
Folosește setările implicite ale graficelor Excel ca punct de plecare. Ajustează scalele axelor doar dacă poți justifica schimbarea în fața comisiei.
Calculează Mărimea Eșantionului
Folosește calculatorul nostru gratuit pentru a determina mărimea eșantionului necesar folosind Yamane, Cochran și Krejcie & Morgan. Compară cele trei metode și obține o citare APA.
Încearcă CalculatorulLista Ta de Verificare pentru Prevenire
Folosește această listă de verificare înainte de a începe orice analiză de chestionar:
Configurare Pre-Analiză:
- Analysis ToolPak instalat și butonul Data Analysis vizibil
- Toate răspunsurile codificate numeric (1-5), nu text ("De acord")
- Data Validation aplicat pentru a preveni introducerile inconsistente
- Setările de export ale chestionarului configurate pentru output numeric
Curățarea Datelor:
- Strategie pentru datele lipsă decisă și documentată
- Răspunsurile duplicate verificate și eliminate
- Dimensiunea eșantionului actualizată după curățare (n=numărul final)
- Toate celulele conțin date valide (fără erori, fără text în coloanele numerice)
Analiza Statistică:
- Testul statistic corect identificat înainte de analiză
- Itemii formulați negativ codificați invers înainte de testele de fiabilitate
- Asumpțiile verificate (normalitate, omogenitatea varianței)
- Comparațiile multiple corectate (dacă rulezi teste t multiple, folosește ANOVA în schimb)
Prezentarea Rezultatelor:
- Toate statisticile rotunjite la numărul potrivit de zecimale
- Procentele verificate să dea 100%
- Graficele folosesc axa Y bazată pe zero (cu excepția justificărilor)
- Dimensiunile eșantionului raportate (n=X) în toate tabelele și graficele
- Rezultatele respectă ghidul de formatare APA ediția a 7-a
Descarcă această listă de verificare și ține-o vizibilă în timp ce lucrezi la analiză.
Întrebări Frecvente
Pașii Următori
Acum că știi ce greșeli să eviți, urmează aceste ghiduri pentru a analiza corect datele din chestionar:
Începe aici: Cum să Analizezi Datele din Chestionar în Excel: Ghid Complet
Alege testul tău statistic:
Verifică fiabilitatea:
Raportează rezultatele:
Referințe
- American Psychological Association. (2020). Publication Manual of the American Psychological Association (7th ed.). American Psychological Association.
- Field, A. (2018). Discovering Statistics Using IBM SPSS Statistics (5th ed.). SAGE Publications.
- Pallant, J. (2020). SPSS Survival Manual: A Step by Step Guide to Data Analysis Using IBM SPSS (7th ed.). Open University Press.
- Nunnally, J. C., & Bernstein, I. H. (1994). Psychometric Theory (3rd ed.). McGraw-Hill.