En este tutorial aprenderás cómo calcular el error estándar en Excel, SPSS y R con ejemplos paso a paso y datasets descargables. Ya sea que necesites obtener el error estándar en Excel usando fórmulas, calcularlo en SPSS con estadísticas descriptivas, o computarlo en R, esta guía cubre todo lo necesario.
Revisaremos la fórmula del error estándar, su interpretación y cálculos prácticos en las tres plataformas con ejemplos reales.
Nota: Los términos "error estándar" y "error estándar estimado de la media" se usan indistintamente en estadística y se refieren al mismo concepto.
Qué es el Error Estándar de la Media
En un escenario ideal, los investigadores tendrían acceso a poblaciones completas para sus estudios. Sin embargo, esto rara vez es factible en la práctica.
En la mayoría de los casos, recolectamos datos mediante el muestreo de la población que investigamos. Si tomamos múltiples muestras de la misma población, observaremos que son ligeramente diferentes.
Por ejemplo, la media de cada muestra será diferente de otra, ya que cada muestra probablemente contiene miembros distintos de la misma población.
Entonces, ¿cómo sabemos si los datos muestrales representan a toda la población?
Aquí es donde el error estándar de la media (o simplemente, error estándar) se vuelve esencial. Estas son las notaciones comunes utilizadas por diversos autores en la literatura:
El error estándar se utiliza para determinar qué tan cerca está la media de una muestra tomada de una población comparada con el valor promedio de la población verdadera.
Un valor bajo de error estándar muestra que las medias muestrales tienen una distribución cercana alrededor de la media poblacional, por lo tanto son más representativas de la población verdadera.
Por el contrario, un valor alto de error estándar probablemente indica que la muestra es una representación imprecisa de la población verdadera.
La mejor forma de reducir un error estándar alto es aumentando el tamaño de muestra. Realizaremos una comparación más adelante en esta lección.
También es importante utilizar el muestreo aleatorio al recolectar los datos para evitar el sesgo de muestreo.
Finalmente, debes entender la diferencia entre el error estándar de la media y la desviación estándar. Ambos conceptos son frecuentemente una fuente de gran confusión entre estudiantes.
Cómo Calcular el Error Estándar de la Media
La siguiente fórmula es la ecuación para el error estándar de la media usando la desviación estándar poblacional:
Donde:
- = Error estándar de la media
- = Desviación estándar poblacional
- = Tamaño de muestra
- = Raíz cuadrada del tamaño de muestra
La salvedad aquí es que necesitamos conocer la desviación estándar poblacional real para poder calcular el error estándar usando la fórmula anterior.
Generalmente, las poblaciones son grandes y es poco probable que tengamos acceso a la población completa para calcular el valor de la desviación estándar poblacional.
Como en la mayoría de los casos en investigación, muestrear una población es un enfoque más fácil y menos costoso. Afortunadamente, existe una forma de estimar el error estándar de la media usando la desviación estándar muestral. Esta es la fórmula:
Donde:
- = Error estándar de la media
- = Desviación estándar muestral
- = Tamaño de muestra
- = Raíz cuadrada del tamaño de muestra
Habrás notado que ambas fórmulas para el error estándar son bastante similares. Efectivamente lo son, la única diferencia es si conocemos el valor de la desviación estándar poblacional o no.
Cómo Calcular el Error Estándar
Para calcular el error estándar, sigue estos pasos:
- Calcula u obtén tu desviación estándar (s para muestra, σ para población)
- Cuenta tu tamaño de muestra (n)
- Calcula la raíz cuadrada de tu tamaño de muestra (√n)
- Divide la desviación estándar entre √n para obtener tu error estándar
La fórmula del error estándar es: EE = s / √n (para datos muestrales) o EE = σ / √n (para datos poblacionales).
En la práctica, puedes calcular el error estándar usando:
- Excel:
=DESVEST(rango)/RAIZ(CONTARA(rango)) - SPSS: Analizar → Estadísticos descriptivos → Explorar (pasos detallados abajo)
- R:
stderr <- function(x) sd(x)/sqrt(length(x))(pasos detallados abajo)
Ahora que conocemos las ecuaciones para el error estándar, hagamos cálculos básicos y aprendamos cómo calcularlo manualmente.
Ejemplo 1: Supongamos que conocemos que la desviación estándar real de una población de estudiantes que toman su examen final es 7. También tomamos una muestra aleatoria de 100 participantes de esta población. Por lo tanto tenemos:
Ya que en este ejemplo conocemos el valor real de la desviación estándar, usaremos la primera ecuación para el error estándar:
Después de insertar los números en la ecuación tenemos:
¿Cómo interpretamos el resultado del error estándar en este ejemplo? Simplemente significa que cuando tomamos una muestra aleatoria de N = 100 de esta población, la diferencia promedio entre las medias muestrales y la media poblacional es 0.70.
Ejemplo 2: Ahora supongamos que no conocemos la desviación estándar poblacional de los estudiantes que toman su examen final. En su lugar, conocemos la desviación estándar muestral (s) que supongamos es 5. La muestra (N) permanece sin cambios, respectivamente 100. Por lo tanto tenemos:
Esta vez usaremos la ecuación para la desviación estándar muestral:
Después de insertar los números tenemos:
Podemos interpretar este resultado como la diferencia promedio entre las medias muestrales y la media poblacional cuando la muestra es seleccionada aleatoriamente y N = 100 es 0.50.
El error estándar de la media es una medida de cuánta diferencia puedes esperar entre un estadístico muestral y el parámetro poblacional cuando las muestras son seleccionadas aleatoriamente y de un tamaño determinado.
Calcular Error Estándar en SPSS
Existen varias formas de obtener el error estándar en SPSS. En esta sección, nos enfocaremos en dos métodos eficientes.
¿Quieres seguir el tutorial? Descarga el dataset de práctica de SPSS desde la barra lateral, luego abre SPSS en tu computadora y navega a File → Open → Data para importar el archivo .sav.
(1) Calcular el Error Estándar de la Media en SPSS usando Explorar
En el menú superior de SPSS, navega a Analyze → Descriptive Statistics → Explore
Figura 1: Navega a Analyze → Descriptive Statistics → Explore en SPSS
En la ventana Explore, selecciona una variable en el cuadro izquierdo y haz clic en el botón de flecha para agregarla a la Dependent List.
Figura 2: Selecciona tu variable y haz clic en el botón de flecha para agregarla a Dependent List
Haz clic en el botón OK para proceder con el análisis.
Figura 3: Haz clic en OK para ejecutar el análisis Explore
En la ventana Output, desplázate hasta la tabla Descriptives. En la fila Mean, revisa la columna Std. Error para encontrar el valor del error estándar para la variable respectiva.
En nuestro ejemplo, la media para la variable System es 4.10 y el error estándar es 0.081.
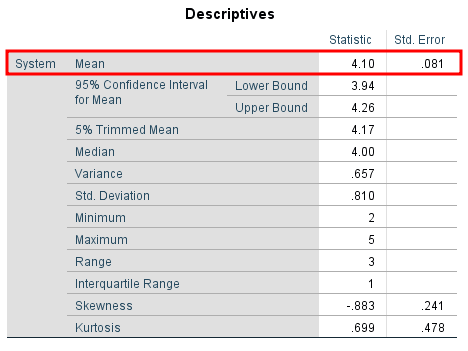
Figura 4: Tabla Descriptives de SPSS mostrando el valor del error estándar de 0.081 en la columna Std. Error
Este valor de error estándar es bastante bajo, lo que significa que las medias muestrales analizadas están distribuidas cercanamente alrededor de la media poblacional. En otras palabras, nuestra muestra es representativa de la población de donde fue tomada.
Si el error estándar de la media en tu análisis es alto, aumentar el tamaño de muestra mediante selección aleatoria probablemente disminuirá el valor del error estándar.
Por ejemplo, si tu tamaño de muestra es N = 50, podrías aumentarlo a N = 100 o más para reducir el error estándar, como se muestra en la comparación lado a lado a continuación.
Presta atención a la media y al error estándar de la media en ambas figuras.
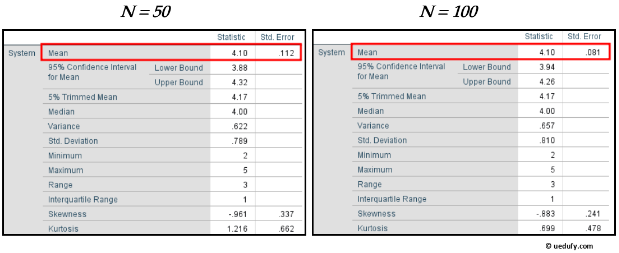
Figura 5: Comparación que muestra cómo el error estándar disminuye al aumentar el tamaño de muestra de N=50 a N=100
(2) Obtener el Error Estándar en SPSS usando Análisis de Frecuencias
Otra forma de calcular el error estándar en SPSS es usando el análisis de Frecuencias. En SPSS, navega a Analyze → Descriptive Statistics → Frequencies
Figura 6: Navega a Analyze → Descriptive Statistics → Frequencies en SPSS
En la ventana Frequencies, agrega la variable de interés del cuadro izquierdo a Variable(s). Desmarca la casilla Display frequency table y haz clic en el botón Statistics.
Figura 7: Agrega tu variable a Variable(s), desmarca Display frequency table y haz clic en Statistics
En la ventana Statistics, asegúrate de que la casilla S.E. mean esté seleccionada y presiona el botón Continue.
Figura 8: Selecciona la casilla S.E. mean y haz clic en Continue
Haz clic en OK en la ventana Frequencies para proceder con el análisis de error estándar.
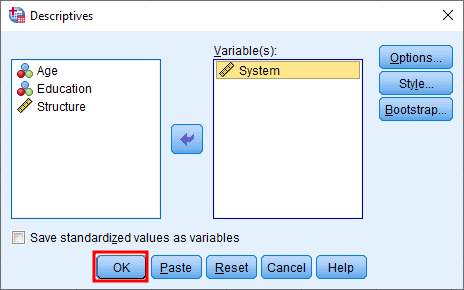
Figura 9: Haz clic en OK para ejecutar el análisis de Frequencies
El valor del error estándar aparecerá en la fila Std. Error of Mean de la tabla Statistics.
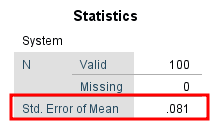
Figura 10: El resultado del error estándar aparece en la fila Std. Error of Mean de la tabla Statistics
Cálculo del Error Estándar en Excel
Para encontrar el error estándar de la media en Excel, simplemente necesitamos traducir la fórmula del error estándar a la sintaxis de Excel: error estándar = desviación estándar / raíz cuadrada del número total de muestras N.
Dataset de práctica disponible: Descarga el archivo de Excel desde la barra lateral para seguir este ejemplo.
Así es como se calcula:
- En tu dataset de Excel, haz clic en una celda vacía en cualquier parte de tu hoja de datos
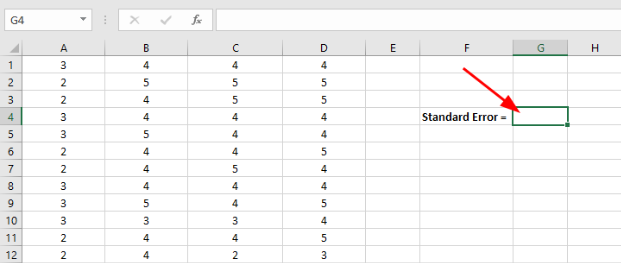
Figura 11: Haz clic en una celda vacía en Excel donde quieras que aparezca el resultado del error estándar
- Copia la fórmula del error estándar para Excel a continuación en el campo Insertar Función en Excel.
=STDEV(rango de muestreo)/SQRT(COUNT(rango de muestreo))
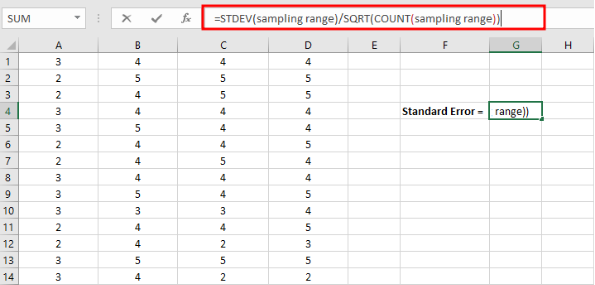
Figura 12: Ingresa la fórmula del error estándar: =STDEV(rango)/SQRT(COUNT(rango))
- Reemplaza el rango de muestreo en la fórmula del error estándar con el rango real de celdas que deseas incluir en tu análisis.
Una vez que hayas hecho tu selección, presiona la tecla ENTER para completar el análisis.
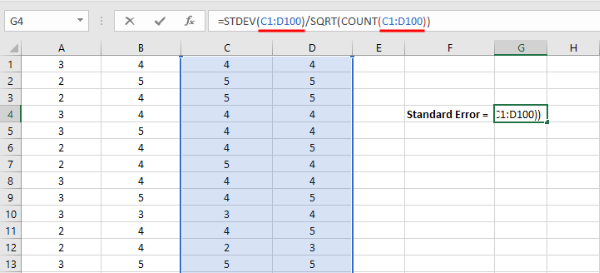
Figura 13: Reemplaza "rango de muestreo" con tu rango real de celdas (por ejemplo, A2:A101) y presiona ENTER
Excel mostrará el resultado del error estándar en la celda correspondiente como se muestra en la captura a continuación.
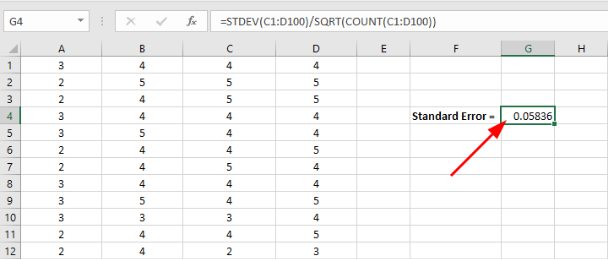
Figura 14: Excel muestra el valor calculado del error estándar en la celda seleccionada
Cálculo del Error Estándar en R
Finalmente, veamos qué función podemos usar para obtener el error estándar de la media en R.
Como discutimos anteriormente, el error estándar de la media es simplemente la desviación estándar dividida entre la raíz cuadrada del tamaño de muestra.
Para este ejemplo vamos a utilizar el mismo dataset de Excel que usamos en la sección anterior.
Abre RStudio en tu computadora. En el menú superior de R, navega a File → Import Dataset → From Excel.
En la ventana Import Excel Data in R, haz clic en Browse y selecciona el archivo dataset.xlsx que descargaste anteriormente. Haz clic en Open y luego en el botón Import para finalizar la importación del dataset de Excel en R.
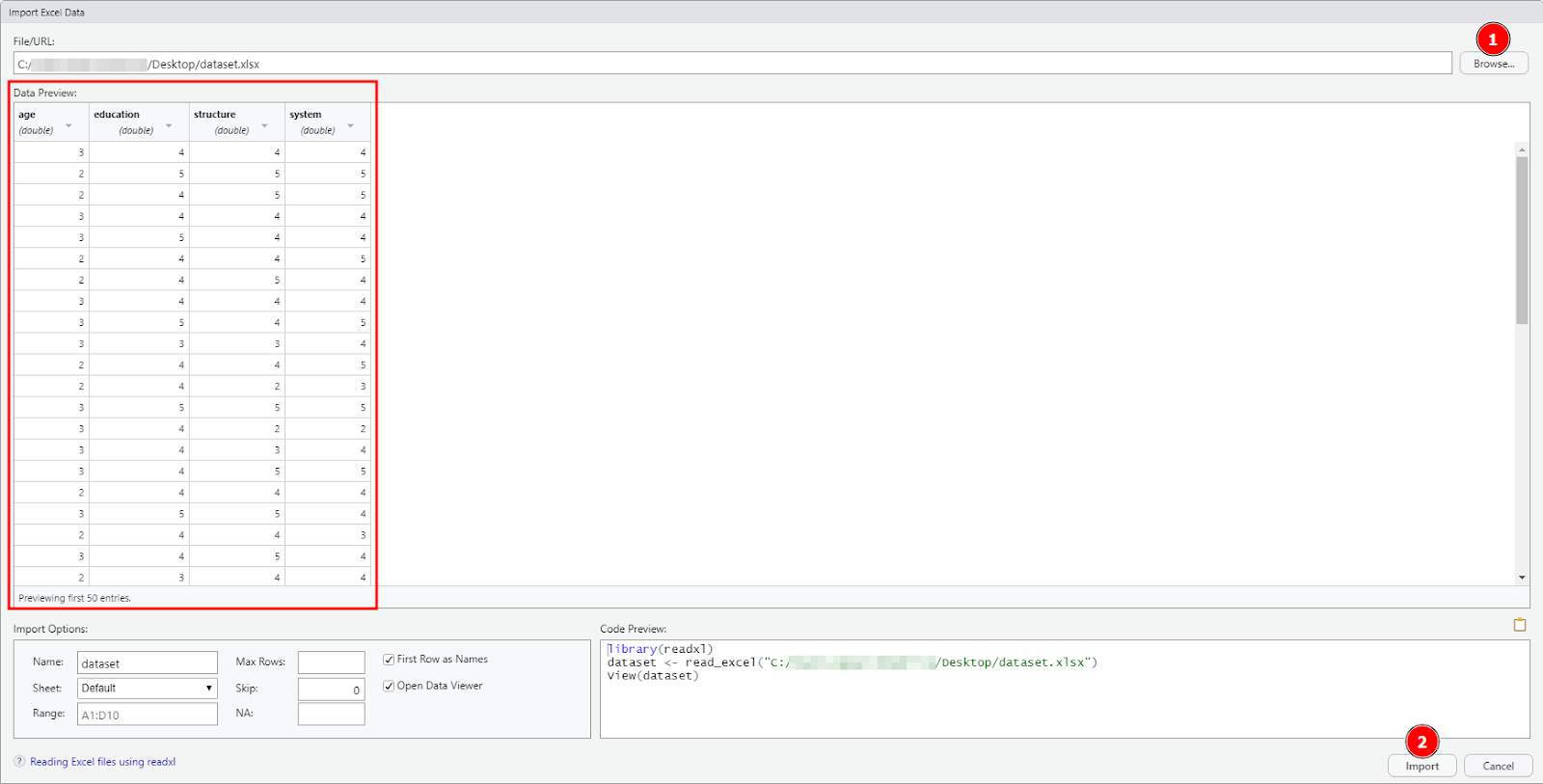
Figura 15: Haz clic en Browse para seleccionar tu archivo de Excel, luego haz clic en Import para cargar el dataset en R
NOTA: R podría requerir ciertas librerías para poder importar datos desde archivos de Excel (.xlsx, .csv, etc.). Si se te solicita, permite que RStudio instale automáticamente las dependencias requeridas.
(1) Obtener el Error Estándar en R usando la Fórmula
El primer paso es traducir la ecuación del error estándar de la media a una nueva function(x) en R. Llamemos a esta función, por ejemplo, stderr o cualquier otro nombre que desees.
Escribe esta función en la ventana Console en R y luego presiona ENTER.
stderr <- function(x) sd(x)/sqrt(length(x))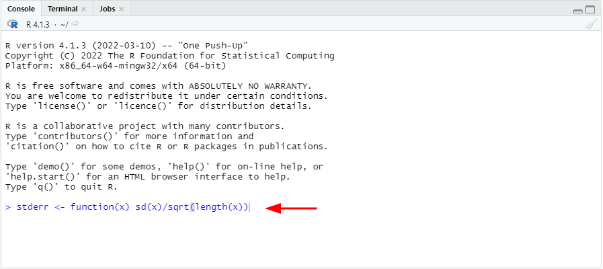
Figura 16: Crea una función personalizada stderr en la Consola de R
A continuación, calculemos el error estándar de la media para la columna age en nuestro dataset.
Para hacerlo, invocaremos la función que creamos y especificaremos el archivo de datos y la columna para la cual queremos computar el error estándar en R usando la siguiente sintaxis:
stderr(dataset$age)Donde:
- stderr = función para la fórmula del error estándar en R
- dataset = el archivo de datos que importamos en R
- age = la columna (variable) para la cual queremos obtener el valor del error estándar de la media
El error estándar para la variable age en nuestro dataset es 0.06 como se muestra en la captura a continuación:

Figura 17: La función stderr(dataset$age) devuelve un valor de error estándar de 0.06
(2) Obtener el Error Estándar en R usando la Librería Plotrix
Este método utiliza la función std.error() del paquete Plotrix en R. Primero necesitamos instalar la librería Plotrix escribiendo el siguiente comando en la ventana Console de R:
install.packages('plotrix')Luego, necesitamos llamar a la librería Plotrix en R usando el siguiente comando:
library('plotrix')Finalmente, podemos usar la función std.error para calcular el error estándar de la media para la variable system en nuestro dataset.
std.error(dataset$system)
Figura 18: Usando la función std.error() de Plotrix para calcular el error estándar de la variable system
Preguntas Frecuentes
Próximos Pasos
El error estándar de la media mide la diferencia entre las medias muestrales comparadas con la media de la población verdadera. En otras palabras, nos indica si nuestra muestra es representativa de la población de donde fue tomada.
Si el análisis de la muestra muestra un error estándar alto, la mejor forma de reducirlo es aumentando el tamaño de muestra mediante recolección aleatoria de datos.
Si trabajas con datos de encuestas o cuestionarios, también podrías necesitar evaluar la confiabilidad de tus escalas antes de calcular estadísticas descriptivas como el error estándar:
- Aprende a calcular estadísticas descriptivas en Excel para obtener media, desviación estándar y más
- Explora cómo obtener la media, mediana y moda para complementar tu análisis descriptivo
Referencias
Field, A., Miles, J., & Field, Z. (2012). Discovering statistics using R. SAGE Publications.
Field, A. (2013). Discovering statistics using IBM SPSS statistics (4th ed.). SAGE Publications.
McNeil, E. (2020). Data management and visualization using R. Songkhla: Epidemiology Unit, Faculty of Medicine, Prince of Songkla University.