Paired samples t-test เปรียบเทียบสองการวัดจากคนกลุ่มเดียวกัน เป็นสถิติมาตรฐานสำหรับแบบแผนก่อนเรียน/หลังเรียน การศึกษาก่อนและหลังการแทรกแซง และงานวิจัยที่วัดกลุ่มเดียวกันสองครั้งในเงื่อนไขต่างกัน ต่างจาก independent samples t-test ที่เปรียบเทียบสองกลุ่มแยกกัน paired test คำนึงถึงสหสัมพันธ์ภายในกลุ่ม ทำให้มีพลังทางสถิติมากกว่าในการตรวจจับผลต่างจริง
คู่มือนี้ครอบคลุมทุกขั้นตอนใน SPSS: เช็คข้อสมมติ, รันการทดสอบ, อ่านตารางผลลัพธ์ทั้งสามตาราง, คำนวณ Cohen's d สำหรับแบบจับคู่ และรายงานผลในรูปแบบ APA ฉบับที่ 7 ถ้าคุณทำ independent samples t-test มาก่อน ให้สังเกตว่า paired version มีข้อกำหนดการแจกแจงปกติต่างกัน และสูตร Cohen's d ก็ต่างกันด้วย คู่มือนี้ใช้ชุดข้อมูลขยายจากคู่มือก่อนหน้า โดยเพิ่มตัวแปรคะแนนก่อนเรียนและหลังเรียนเข้ามา
สรุป:
- Paired samples t-test เปรียบเทียบ สองการวัดจากคนกลุ่มเดียวกัน (เช่น ก่อนเรียน vs. หลังเรียน, ก่อน vs. หลังการแทรกแซง)
- ข้อสมมติการแจกแจงปกติใช้กับ คะแนนผลต่าง ไม่ใช่ตัวแปรแต่ละตัวแยกกัน
- SPSS คำนวณผลต่างเป็น ตัวแปรที่ 1 ลบตัวแปรที่ 2 ซึ่งมักทำให้ค่า t ติดลบเมื่อคะแนนดีขึ้น นี่ไม่ใช่ข้อผิดพลาด
- Cohen's d สำหรับแบบจับคู่ใช้ สูตรที่ต่างจาก independent version: d = ค่าเฉลี่ยของผลต่าง / ส่วนเบี่ยงเบนมาตรฐานของผลต่าง
- รายงาน ค่า t, องศาอิสระ, ค่า p, ค่าเฉลี่ยทั้งสองพร้อม SD และขนาดอิทธิพล ในบทผลการวิจัย
ก่อนเริ่ม: คู่มือนี้สมมติว่าคุณโหลดข้อมูลใน SPSS แล้ว พร้อมตั้งค่าสองตัวแปรที่สัมพันธ์กัน (เช่น คะแนนก่อนเรียนและหลังเรียน) ใน Variable View เรียบร้อย คุณควรดูสถิติเชิงพรรณนาของตัวแปรมาก่อนแล้ว ถ้าต้องเช็คการแจกแจงปกติของคะแนนผลต่าง ดูคู่มือทดสอบการแจกแจงปกติใน SPSS นะ
เมื่อไหร่ควรใช้ Paired Samples T-Test
Paired samples t-test เหมาะเมื่อการวิจัยของคุณมีเงื่อนไขเหล่านี้:
- มี ตัวแปรตามแบบต่อเนื่องหนึ่งตัว ที่วัดสองช่วงเวลาหรือสองเงื่อนไข
- คนกลุ่มเดียวกัน ให้ข้อมูลทั้งสองการวัด (หรือจับคู่เป็นคู่)
- ต้องการทดสอบว่า ค่าเฉลี่ยของผลต่าง ระหว่างสองการวัดมีนัยสำคัญทางสถิติหรือไม่
ถ้าสองการวัดมาจากคนละคน ให้ใช้ independent samples t-test แทน ถ้ามีสามการวัดที่สัมพันธ์กันขึ้นไป ให้ใช้ repeated measures ANOVA
ตัวอย่างที่พบบ่อยในวิทยานิพนธ์:
| คำถามวิจัย | ตัวแปรที่ 1 | ตัวแปรที่ 2 | แบบแผน |
|---|---|---|---|
| โปรแกรมฝึกทักษะช่วยให้คะแนนสอบดีขึ้นไหม? | PreTestScore | PostTestScore | ก่อน/หลังการแทรกแซง |
| นักศึกษาให้คะแนนรายวิชาต่างกันไหมระหว่างกลางภาคกับปลายภาค? | MidtermRating | FinalRating | สองช่วงเวลา |
| คะแนนจากการรายงานตนเองกับการสังเกตต่างกันไหม? | SelfReport | ObservedScore | สองวิธีวัด |
ตารางที่ 1: ตัวอย่างแบบแผนการวิจัยที่เหมาะกับ paired samples t-test
ข้อสมมติ
Paired samples t-test มีสามข้อสมมติ สองข้อแรกตรงไปตรงมา ข้อที่สามต้องเช็คเฉพาะ และต่างจาก independent t-test
1. ข้อมูลเป็นคู่ (Related Observations)
แต่ละเคสในชุดข้อมูลต้องมีค่าทั้งสองการวัด คนที่ 1 มีคะแนนก่อนเรียนและหลังเรียน คนที่ 2 มีคะแนนก่อนเรียนและหลังเรียน เป็นต้น ข้อสมมตินี้มาจากแบบแผนการวิจัย ถ้าบางคนออกกลางคันระหว่างสองการวัด SPSS จัดการด้วย listwise deletion (ตัดเคสนั้นออก)
2. ตัวแปรตามเป็นข้อมูลต่อเนื่อง
ทั้งสองการวัดต้องอยู่ในระดับ interval หรือ ratio คะแนนสอบ คะแนนบนสเกลต่อเนื่อง และค่าทางสรีรวิทยาผ่านข้อสมมตินี้ ข้อมูลอันดับที่มีหมวดน้อย (เช่น สเกล 3 จุด) เหมาะกับ Wilcoxon signed-rank test มากกว่า
3. การแจกแจงปกติของคะแนนผลต่าง
จุดนี้ paired t-test ต่างจาก independent version ข้อสมมติการแจกแจงปกติไม่ได้ใช้กับตัวแปรแต่ละตัวแยกกัน มันใช้กับ คะแนนผลต่าง (ตัวแปรที่ 1 ลบตัวแปรที่ 2 ของแต่ละคน)
วิธีเช็ค:
- สร้างตัวแปรใหม่: Transform > Compute Variable ตั้งชื่อตัวแปรเป็น
Differenceแล้วใส่สูตรPostTestScore - PreTestScore - ทดสอบการแจกแจงปกติของตัวแปรใหม่นี้ด้วย Explore ตามที่อธิบายไว้ในคู่มือทดสอบการแจกแจงปกติ
ถ้ากลุ่มตัวอย่าง 30 คนขึ้นไป paired t-test ทนทานต่อการละเมิดปานกลางได้ (Schmider et al., 2010) กับ 150 คนในตัวอย่างนี้ ข้อสมมตินี้ผ่านง่าย ถ้ากลุ่มเล็กและคะแนนผลต่างไม่แจกแจงปกติรุนแรง ให้ใช้ Wilcoxon signed-rank test เป็นทางเลือกนอนพาราเมตริก
สังเกตว่าทดสอบ Levene สำหรับความเท่าเทียมของความแปรปรวน ซึ่งเป็นส่วนหนึ่งของ independent t-test ไม่ใช้ที่นี่ เพราะมีแค่กลุ่มเดียวที่วัดสองครั้ง จึงไม่มีความแปรปรวนระหว่างกลุ่มให้เปรียบเทียบ
ชุดข้อมูลตัวอย่าง
คู่มือนี้ใช้ชุดข้อมูลขยายจากคู่มือสถิติเชิงพรรณนาและการแจกแจงปกติ โดยเพิ่มตัวแปรใหม่สองตัว: PreTestScore และ PostTestScore ซึ่งเป็นคะแนนก่อนและหลังการแทรกแซงด้านทักษะการเรียน ดาวน์โหลดชุดข้อมูลขยายได้จากแถบด้านข้าง
คำถามวิจัย: โปรแกรมฝึกทักษะการเรียนช่วยให้คะแนนสอบดีขึ้นไหม?
- ตัวแปรที่ 1: PreTestScore (ต่อเนื่อง, Scale, ช่วง 40-90)
- ตัวแปรที่ 2: PostTestScore (ต่อเนื่อง, Scale, ช่วง 45-95)
- กลุ่มตัวอย่าง: 150 คน วัดก่อนและหลังการแทรกแซง
- แบบแผน: กลุ่มเดียว ก่อนเรียน/หลังเรียน
รูปที่ 1: Variable View ใน SPSS แสดงตัวแปร PreTestScore และ PostTestScore
รูปที่ 2: Data View ใน SPSS พร้อมคะแนนก่อนเรียนและหลังเรียนของ 150 คน
ทีละขั้นตอน: รัน Paired Samples T-Test
ขั้นตอนที่ 1: เปิดหน้าต่าง T-Test
ไปที่ Analyze > Compare Means > Paired-Samples T Test
รูปที่ 3: ไปที่ Analyze > Compare Means > Paired-Samples T Test
ขั้นตอนที่ 2: เลือกตัวแปรคู่
ในหน้าต่าง Paired-Samples T Test:
- เลือก PreTestScore จากรายการตัวแปรด้านซ้าย
- กด Ctrl ค้างไว้ (หรือ Cmd บน Mac) แล้วเลือก PostTestScore ด้วย
- กดปุ่ม ลูกศรสีน้ำเงิน เพื่อย้ายตัวแปรทั้งสองไปในช่อง Paired Variables
- SPSS จะแสดงเป็น Pair 1: PreTestScore - PostTestScore
ลำดับมีผลต่อเครื่องหมายของผลลัพธ์นะ SPSS คำนวณเป็นตัวแปรที่ 1 ลบตัวแปรที่ 2 (PreTestScore ลบ PostTestScore) เพราะเราคาดว่าคะแนนหลังเรียนจะสูงกว่า ค่าเฉลี่ยของผลต่างจะติดลบ นี่ไม่ใช่ข้อผิดพลาด
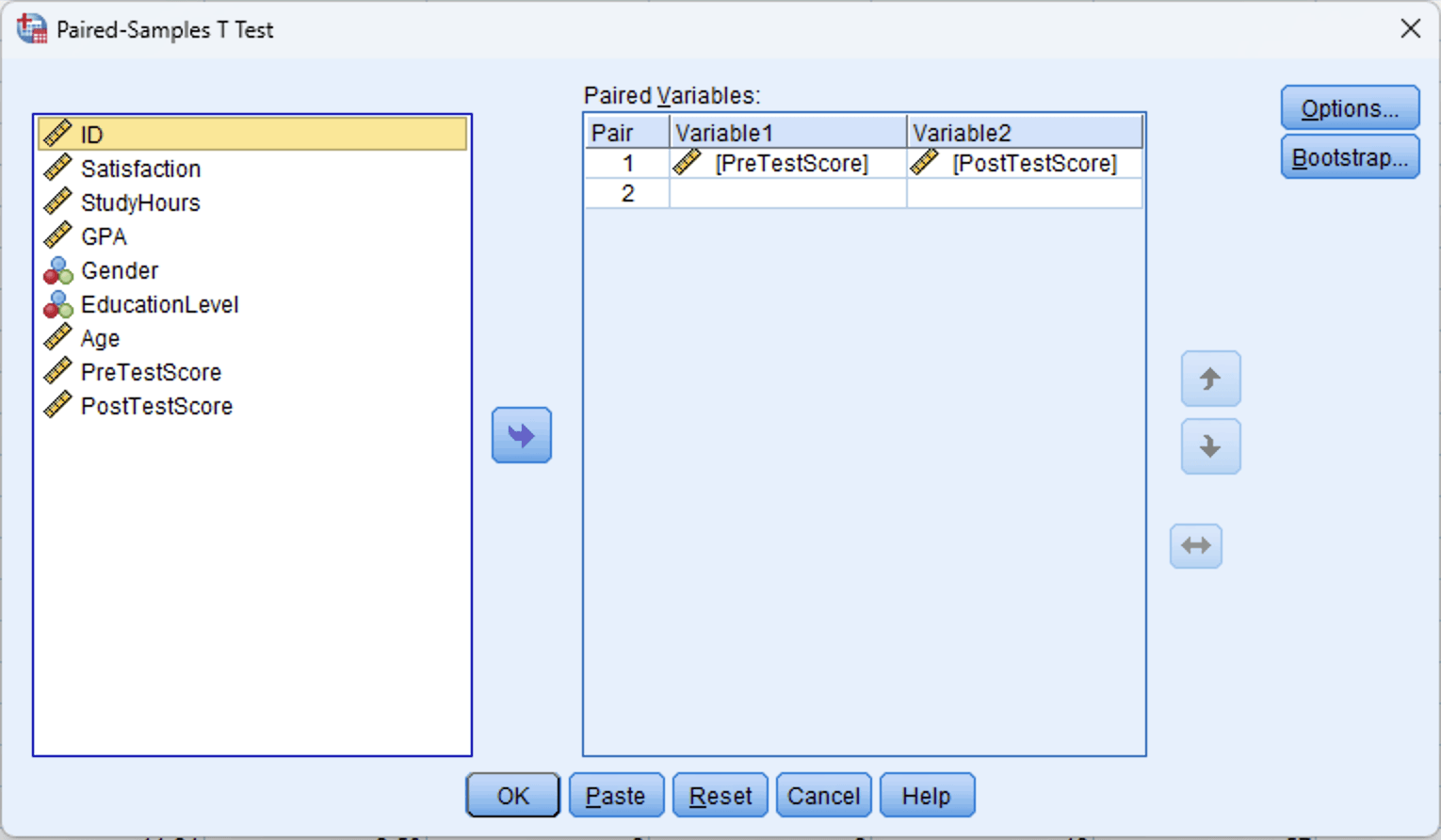
รูปที่ 4: หน้าต่าง Paired-Samples T Test พร้อม PreTestScore เป็นตัวแปรที่ 1 และ PostTestScore เป็นตัวแปรที่ 2
ขั้นตอนที่ 3: รันการทดสอบ
กด OK SPSS จะสร้างตารางผลลัพธ์สามตาราง: Paired Samples Statistics, Paired Samples Correlations และ Paired Samples Test
อ่านผลลัพธ์
SPSS สร้างสามตารางสำหรับ paired samples t-test แต่ละตารางให้ข้อมูลต่างกัน คุณต้องใช้ค่าจากทั้งสามตารางเพื่ออ่านผลและรายงาน APA ให้ครบถ้วน
ตาราง Paired Samples Statistics
ตารางนี้แสดงสถิติเชิงพรรณนาของแต่ละตัวแปรแยกกัน
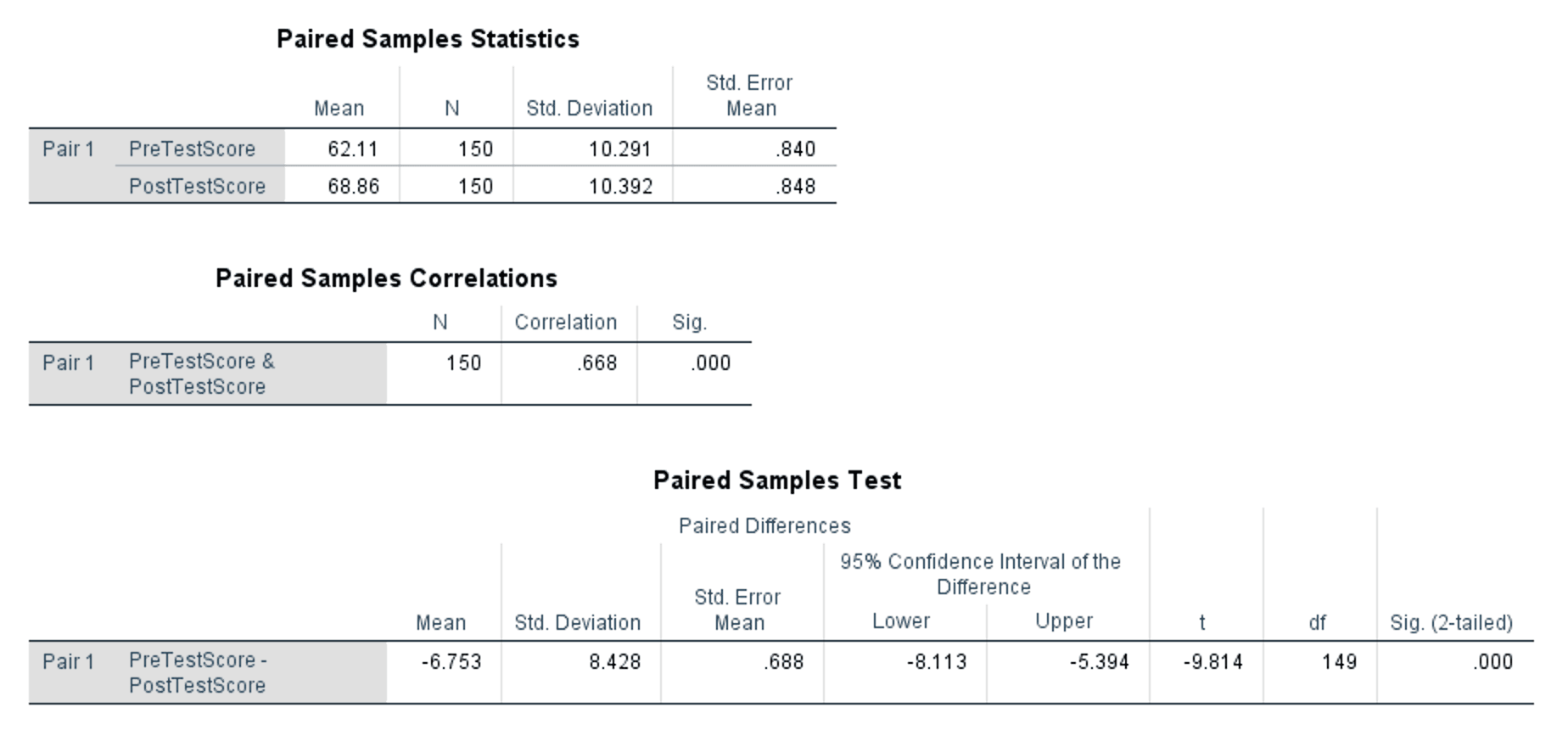
รูปที่ 5: ผลลัพธ์ paired samples t-test ทั้งสามตาราง
ดูอะไรบ้าง:
- Mean: PreTestScore = 62.11, PostTestScore = 68.86 คะแนนหลังเรียนสูงกว่าก่อนเรียนเฉลี่ย 6.75 จุด
- N: 150 ทั้งสองตัวแปร ไม่มีเคสถูกตัดออกเพราะข้อมูลหาย
- Std. Deviation: PreTestScore = 10.291, PostTestScore = 10.392 การกระจายของคะแนนใกล้เคียงกันทั้งสองการวัด
- Std. Error Mean: ความแม่นยำของค่าเฉลี่ยแต่ละตัว ค่ายิ่งน้อยยิ่งแม่นยำ
ตาราง Paired Samples Correlations
ตารางนี้แสดงสหสัมพันธ์ Pearson ระหว่างสองการวัด
- Correlation: .668, Sig.: .000 (p < .001)
สหสัมพันธ์ .668 อยู่ในระดับปานกลางถึงสูง และมีนัยสำคัญทางสถิติ ยืนยันว่าคะแนนก่อนเรียนและหลังเรียนมีความสัมพันธ์เชิงบวก คนที่คะแนนสูงก่อนเรียนก็มีแนวโน้มได้คะแนนสูงหลังเรียนด้วย สิ่งนี้เป็นเรื่องปกติในแบบแผนภายในกลุ่ม และเป็นเหตุผลที่ paired t-test มีพลังมากกว่า independent version เพราะมันนำสหสัมพันธ์นี้ไปลดความแปรปรวนระหว่างบุคคลออกจากค่าคลาดเคลื่อน
ถ้าสหสัมพันธ์ใกล้ศูนย์หรือติดลบ แปลว่ามีอะไรผิดปกติกับข้อมูล (เช่น โครงสร้างคู่อาจผิด หรือสองการวัดอาจไม่ได้วัดสิ่งเดียวกัน)
ตาราง Paired Samples Test
นี่คือตารางผลลัพธ์หลัก แสดงผลต่างแบบจับคู่และผล t-test
อ่านคอลัมน์ Paired Differences:
- Mean: -6.753 นี่คือค่าเฉลี่ยของผลต่างทั้งหมด (PreTestScore ลบ PostTestScore ของแต่ละคน) เครื่องหมายลบแปลว่าคะแนนหลังเรียนสูงกว่าก่อนเรียนโดยเฉลี่ย
- Std. Deviation: 8.428 นี่คือส่วนเบี่ยงเบนมาตรฐานของคะแนนผลต่าง ไม่ใช่ของตัวแปรแต่ละตัว คุณต้องใช้ค่านี้สำหรับคำนวณ Cohen's d
- Std. Error Mean: 0.688 ค่าคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยผลต่าง
- 95% Confidence Interval: [-8.113, -5.394] ช่วงทั้งหมดเป็นลบ แปลว่าเรามั่นใจ 95% ว่าค่าเฉลี่ยผลต่างจริงของประชากรอยู่ระหว่าง -8.11 ถึง -5.39 เพราะช่วงนี้ไม่มีศูนย์ ผลต่างจึงมีนัยสำคัญ
อ่านสถิติทดสอบ:
- t: -9.814 ค่า t ติดลบเพราะค่าเฉลี่ยผลต่างติดลบ (ก่อนเรียน ลบ หลังเรียน) ค่าสัมบูรณ์ (9.814) บอกว่าค่าเฉลี่ยผลต่างห่างจากศูนย์กี่เท่าของค่าคลาดเคลื่อนมาตรฐาน
- df: 149 (N - 1 = 150 - 1)
- Sig. (2-tailed): .000 (p < .001) ผลมีนัยสำคัญทางสถิติที่ทุกระดับ alpha ทั่วไป
รวมผลลัพธ์เข้าด้วยกัน
Paired samples t-test แสดงว่าคะแนนสอบเพิ่มขึ้นอย่างมีนัยสำคัญจากก่อนเรียน (M = 62.11, SD = 10.29) ไปหลังเรียน (M = 68.86, SD = 10.39) โดยมีค่าเฉลี่ยเพิ่มขึ้น 6.75 จุด ช่วงความเชื่อมั่น 95% ของค่าเฉลี่ยผลต่าง [-8.11, -5.39] ไม่มีศูนย์ และ t-test มีนัยสำคัญ t(149) = -9.81, p < .001
สหสัมพันธ์ระหว่างคะแนนก่อนเรียนและหลังเรียน (r = .668) ยืนยันว่าแบบแผนภายในกลุ่มเหมาะสม และ paired t-test เป็นทางเลือกที่ถูกต้องเมื่อเทียบกับ independent version
คำนวณ Cohen's d (ขนาดอิทธิพล)
สูตร Cohen's d สำหรับแบบจับคู่ต่างจาก independent samples version สำหรับ independent samples คุณหารด้วยส่วนเบี่ยงเบนมาตรฐานรวมของสองกลุ่ม สำหรับ paired samples คุณหารด้วยส่วนเบี่ยงเบนมาตรฐานของคะแนนผลต่าง
สูตร
โดย:
- คือค่าเฉลี่ยของผลต่างแบบจับคู่ (จากตาราง Paired Samples Test)
- คือส่วนเบี่ยงเบนมาตรฐานของผลต่างแบบจับคู่ (จากตารางเดียวกัน)
ค่าทั้งสองมาจากผลลัพธ์ SPSS โดยตรง ไม่ต้องคำนวณ pooling เอง
ตัวอย่างการคำนวณ
ใช้ค่าจากตาราง Paired Samples Test:
ค่าสัมบูรณ์คือ 0.80
การตีความ
| Cohen's d | ขนาดอิทธิพล | ความหมายในทางปฏิบัติ |
|---|---|---|
| 0.2 | เล็ก | ความแตกต่างมีอยู่แต่สังเกตได้ยาก |
| 0.5 | กลาง | ความแตกต่างเห็นได้ชัดและอาจมีความหมายในทางปฏิบัติ |
| 0.8 | ใหญ่ | ความแตกต่างชัดเจนและมีความหมายในทางปฏิบัติ |
ตารางที่ 2: เกณฑ์ Cohen's d สำหรับตีความขนาดอิทธิพล (Cohen, 1988)
ในตัวอย่างนี้ d = 0.80 เป็นอิทธิพลขนาดใหญ่ โปรแกรมฝึกทักษะการเรียนทำให้คะแนนสอบดีขึ้นประมาณ 0.80 ส่วนเบี่ยงเบนมาตรฐาน เมื่อรวมกับค่า p ที่มีนัยสำคัญสูง (p < .001) และช่วงความเชื่อมั่นที่แคบ ผลเหล่านี้ให้หลักฐานที่แข็งแรงว่าโปรแกรมมีผลในเชิงบวกต่อผลสัมฤทธิ์ของนักศึกษา
ทำไมสูตรสำหรับแบบจับคู่ถึงต่างกัน
ใน independent samples t-test Cohen's d ใช้ส่วนเบี่ยงเบนมาตรฐานรวม (pooled) เพราะเปรียบเทียบสองกลุ่มแยกกันที่แต่ละกลุ่มมีความแปรปรวนของตัวเอง ในแบบจับคู่มีแค่คะแนนผลต่างชุดเดียว และความแปรปรวนที่เกี่ยวข้องคือผลต่างเหล่านั้นแตกต่างกันมากน้อยแค่ไหนระหว่างผู้ตอบ การใช้ pooled SD จากสองตัวแปรจะทำให้ตัวหารใหญ่เกินไปและประมาณขนาดอิทธิพลต่ำเกินจริง เพราะไม่ได้คำนึงถึงสหสัมพันธ์ระหว่างสองการวัด
นักระเบียบวิธีวิจัยบางท่านแยกระหว่าง (ใช้ SD ของผลต่าง ซึ่งเป็นวิธีที่เราคำนวณที่นี่) กับ (ใช้ค่าเฉลี่ยของ SD สองตัว) เป็นวิธีมาตรฐานสำหรับแบบแผนภายในกลุ่ม และเป็นสิ่งที่อาจารย์ที่ปรึกษามักคาดหวัง (Lakens, 2013)
ถ้าข้อสมมติไม่ผ่านต้องทำอย่างไร
คะแนนผลต่างไม่แจกแจงปกติ
ถ้าคะแนนผลต่างไม่แจกแจงปกติรุนแรง (ค่าความเบ้เกิน +/-2) และกลุ่มตัวอย่างน้อยกว่า 30 คน ให้ใช้ Wilcoxon signed-rank test เป็นทางเลือกนอนพาราเมตริกมาตรฐาน มันเปรียบเทียบอันดับของค่าสัมบูรณ์ของผลต่างแทนค่าดิบ
วิธีรันใน SPSS: Analyze > Nonparametric Tests > Legacy Dialogs > 2 Related Samples ย้ายตัวแปรทั้งสองไป Test Pairs List แล้วเลือก "Wilcoxon" ที่ Test Type กด OK
ถ้ากลุ่มตัวอย่าง 30 คนขึ้นไป paired t-test ทนทานต่อการละเมิดปานกลางได้ (Schmider et al., 2010) ให้บันทึกการละเมิด รายงานค่าความเบ้และความโด่งของคะแนนผลต่าง อ้างอิงงานวิจัยเรื่องความทนทาน แล้วใช้สถิติพาราเมตริกต่อไป
ค่าสุดโต่งในคะแนนผลต่าง
ค่าสุดโต่ง (outliers) ในคะแนนผลต่างอาจส่งผลต่อค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานมาก ให้ระบุค่าสุดโต่งด้วย boxplot ของคะแนนผลต่างหรือดูค่ามาตรฐานที่เกิน +/-3
ถ้าเจอค่าสุดโต่ง ให้ตรวจสอบก่อนว่าเป็นข้อมูลจริง (ไม่ใช่ข้อผิดพลาดจากการบันทึก) ถ้าเป็นข้อมูลจริง ให้รันการวิเคราะห์ทั้งแบบมีและไม่มีค่าสุดโต่ง แล้วรายงานทั้งสองผล ถ้าข้อสรุปไม่เปลี่ยน แปลว่าค่าสุดโต่งไม่มีอิทธิพล ถ้าข้อสรุปเปลี่ยน ให้อภิปรายเรื่องนี้ในบทผลการวิจัย
รายงานในรูปแบบ APA
รายงานผลจริงจากคู่มือนี้
A paired samples t-test was conducted to evaluate the effect of a study skills intervention on test scores. Post-test scores (M = 68.86, SD = 10.39) were significantly higher than pre-test scores (M = 62.11, SD = 10.29), t(149) = -9.81, p < .001, d = 0.80, 95% CI [-8.11, -5.39]. The effect size was large, indicating that the intervention produced a substantial improvement in student performance.
แม่แบบสำหรับผลไม่มีนัยสำคัญ
ถ้าผลไม่มีนัยสำคัญ จะรายงานแบบนี้:
A paired samples t-test was conducted to compare test scores before and after the intervention. There was no significant difference between pre-test scores (M = 62.11, SD = 10.29) and post-test scores (M = 63.40, SD = 10.55), t(149) = -1.12, p = .264, d = 0.13. The effect size was negligible.
กรณีใช้ Wilcoxon (คะแนนผลต่างไม่แจกแจงปกติ)
The Shapiro-Wilk test indicated that the difference scores were not normally distributed (W = 0.94, p = .003). A Wilcoxon signed-rank test was therefore conducted. Post-test scores were significantly higher than pre-test scores (Z = -5.42, p < .001, r = .44).
ตาราง APA
สำหรับบทผลการวิจัยที่ต้องสร้างตารางสรุป:
| Variable | Condition | N | M | SD | t | df | p | d |
|---|---|---|---|---|---|---|---|---|
| Test Score | Pre-test | 150 | 62.11 | 10.29 | -9.81 | 149 | < .001 | 0.80 |
| Post-test | 150 | 68.86 | 10.39 |
ตารางที่ 3: ผล paired samples t-test เปรียบเทียบคะแนนก่อนเรียนและหลังเรียน
รายการตรวจสอบการรายงาน
ทุกครั้งที่รายงาน paired samples t-test ควรมี:
- วัตถุประสงค์ของการทดสอบ (เปรียบเทียบอะไร ทำไม)
- ค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานของทั้งสองเงื่อนไข
- ค่า t, องศาอิสระ และค่า p แบบเจาะจง (หรือ "< .001" ถ้าเล็กมาก)
- ขนาดอิทธิพล (Cohen's d) พร้อมการตีความ
- ช่วงความเชื่อมั่น 95% ของค่าเฉลี่ยผลต่าง
- สหสัมพันธ์ระหว่างสองการวัด (ไม่บังคับแต่แนะนำ โดยเฉพาะเมื่อต้องอธิบายว่าทำไมถึงเลือกแบบจับคู่)
ข้อผิดพลาดที่พบบ่อย
1. ทดสอบการแจกแจงปกติกับตัวแปรแต่ละตัวแทนคะแนนผลต่าง
ตามที่อธิบายไว้ในข้อสมมติข้อ 3 ด้านบน paired t-test เช็คการแจกแจงปกติของคะแนนผลต่าง ไม่ใช่ตัวแปรแต่ละตัวแยกกัน ตัวแปรสองตัวที่ไม่แจกแจงปกติอาจให้ผลต่างที่แจกแจงปกติก็ได้ ต้องสร้างและทดสอบตัวแปรผลต่างเสมอ
2. ใช้ Independent Samples T-Test กับข้อมูลคู่
ถ้าวัดคนเดียวกันสองครั้ง ข้อมูลมีสหสัมพันธ์กัน การใช้ independent t-test ไม่สนใจสหสัมพันธ์นี้ ทำให้ค่าคลาดเคลื่อนสูงเกินจริงและพลังทางสถิติลดลง คุณอาจพลาดผลที่แท้จริงที่ paired test จะตรวจจับได้ ให้เช็คแบบแผนการวิจัย: คนเดียวกันวัดสองครั้ง = paired, คนละคน = independent
3. ไม่สนใจเครื่องหมายของค่า t
ตามที่อธิบายไว้ในขั้นตอนที่ 2 SPSS คำนวณตัวแปรที่ 1 ลบตัวแปรที่ 2 ตามลำดับที่ใส่ คะแนนที่ดีขึ้นจากก่อนเรียนไปหลังเรียนจะให้ค่า t ติดลบ รายงานค่าตามที่ SPSS แสดง แล้วอธิบายทิศทางด้วยค่าเฉลี่ยจากตาราง Paired Samples Statistics
4. ไม่รายงาน Cohen's d หรือใช้สูตรผิด
แบบจับคู่ต้องหารด้วย SD ของผลต่าง ไม่ใช่ pooled SD ที่ใช้กับ independent samples (ดูทำไมสูตรสำหรับแบบจับคู่ถึงต่างกันข้างบน) การสลับสูตรจะทำให้ขนาดอิทธิพลต่ำเกินจริง ค่าทั้งสองที่ต้องใช้อยู่ในตาราง Paired Samples Test
5. รัน Paired T-Test หลายครั้งกับหลายช่วงเวลา
ถ้าวัดผู้ตอบสามช่วงเวลาขึ้นไป (ก่อน, ระหว่าง, หลัง) การรัน paired t-test ทุกคู่ทำให้โอกาสเกิดความผิดพลาดประเภทที่ 1 เพิ่มขึ้น เปรียบเทียบสามคู่ที่ alpha = .05 โอกาสได้ผลบวกลวงอย่างน้อยหนึ่งครั้งเพิ่มเป็นประมาณ .14 ให้ใช้ repeated measures ANOVA แทน ถ้า omnibus test มีนัยสำคัญ ให้ใช้ Bonferroni correction สำหรับการเปรียบเทียบรายคู่
คำถามที่อาจารย์ที่ปรึกษาจะถาม
"ทำไมใช้ paired samples t-test ไม่ใช่ independent samples t-test?" อธิบายว่าคนกลุ่มเดียวกันถูกวัดก่อนและหลังการแทรกแซง ทำให้ข้อมูลสัมพันธ์กัน Paired t-test คำนึงถึงความสัมพันธ์นี้โดยวิเคราะห์คะแนนผลต่าง ซึ่งลดความแปรปรวนระหว่างบุคคลออกและเพิ่มพลังทางสถิติ การใช้ independent test กับข้อมูลคู่จะละเมิดข้อสมมติความเป็นอิสระและเสียข้อได้เปรียบของแบบแผนภายในกลุ่ม
"เช็คข้อสมมติการแจกแจงปกติอย่างไร?" อธิบายว่าคุณสร้างคะแนนผลต่าง (PostTestScore ลบ PreTestScore) แล้วทดสอบการแจกแจงปกติ กับ 150 คน อ้างอิงความทนทานของ t-test ต่อการละเมิดปานกลาง (Schmider et al., 2010) และรายงานค่าความเบ้กับความโด่งของผลต่างถ้าเกี่ยวข้อง
"ขนาดอิทธิพลใหญ่ อาจเกิดจาก practice effects ไม่ใช่โปรแกรมก็ได้?" นี่เป็นข้อกังวลที่สมเหตุสมผลสำหรับแบบแผนก่อน/หลัง ยอมรับตรงๆ ว่าถ้าไม่มีกลุ่มควบคุม ไม่สามารถยืนยันได้ 100% ว่าคะแนนดีขึ้นเพราะโปรแกรม Practice effects, การเจริญเติบโต, regression to the mean และภัยคุกคามอื่นต่อ internal validity เป็นไปได้ทั้งนั้น ถ้าวิทยานิพนธ์ใช้แบบแผนกลุ่มเดียว ให้อภิปรายข้อจำกัดเหล่านี้ตรงๆ ในบทอภิปราย แบบแผนที่แข็งแรงกว่าจะมีกลุ่มควบคุมที่ทำข้อสอบเดียวกันแต่ไม่ได้รับโปรแกรม
"ทำไมถึงเชื่อถือ t-test ได้เมื่อมีแค่สองช่วงเวลา?" Paired samples t-test ถูกออกแบบมาสำหรับสองการวัดที่สัมพันธ์กัน เป็นสถิติที่มีพลังมากที่สุดสำหรับการเปรียบเทียบนี้ ถ้ามีช่วงเวลาเพิ่มเติม repeated measures ANOVA จึงจะเหมาะสม สองช่วงเวลากับ paired t-test เป็นวิธีมาตรฐานในงานวิจัยแบบก่อน/หลัง (Field, 2018)
คำถามที่พบบ่อย
ขั้นตอนถัดไป
หลังจากรัน paired samples t-test แล้ว การวิเคราะห์ถัดไปขึ้นอยู่กับแบบแผนการวิจัยและคำถามที่ยังเหลือ
ถ้างานวิจัยมีกลุ่มควบคุมควบคู่กับการวัดก่อน/หลัง คุณอาจต้องใช้ mixed-design ANOVA เพื่อทดสอบทั้งผลภายในกลุ่มและระหว่างกลุ่มพร้อมกัน ถ้ามีสามการวัดที่สัมพันธ์กันขึ้นไป ให้ใช้ repeated measures ANOVA ซึ่งขยายหลักการของ paired t-test ไปสู่หลายช่วงเวลา
สำหรับการศึกษาว่าตัวแปรต่อเนื่องทำนายผลลัพธ์ได้หรือไม่ แทนที่จะเปรียบเทียบเงื่อนไข linear regression ให้กรอบที่เหมาะสม ตรวจสอบว่าการวิเคราะห์พื้นฐานถูกบันทึกไว้แล้ว: สถิติเชิงพรรณนา สำหรับลักษณะของกลุ่มตัวอย่าง และทดสอบการแจกแจงปกติ สำหรับการเช็คข้อสมมติ ควรอยู่ในบทผลการวิจัยก่อนผล t-test
เอกสารอ้างอิง
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). American Psychological Association.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). SAGE Publications.
Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science: A practical primer for t-tests and ANOVAs. Frontiers in Psychology, 4, 863.
Pallant, J. (2020). SPSS survival manual (7th ed.). Open University Press.
Schmider, E., Ziegler, M., Danay, E., Beyer, L., & Bühner, M. (2010). Is it really robust? Reinvestigating the robustness of ANOVA against violations of the normal distribution assumption. Methodology, 6(4), 147-151.