การวิเคราะห์ข้อมูลในวิทยานิพนธ์ทุกเรื่องเริ่มต้นที่สถิติเชิงพรรณนา (descriptive statistics) ก่อนที่คุณจะรัน t-test, ANOVA หรือ regression ต้องรู้ก่อนว่าข้อมูลหน้าตาเป็นอย่างไร ค่าเฉลี่ยเท่าไหร่ ข้อมูลกระจายตัวแค่ไหน การแจกแจงเบ้หรือเปล่า แล้วก็มีข้อมูลหายหรือค่าผิดปกติอะไรบ้าง
SPSS มีสามวิธีสำหรับทำสิ่งนี้ แต่นักศึกษาส่วนใหญ่รู้จักแค่วิธีเดียว คู่มือนี้จะพาคุณผ่านทั้งสามวิธี (Descriptives, Frequencies และ Explore) พร้อมวิธีอ่านผลลัพธ์ และแม่แบบรายงานตาม APA ฉบับที่ 7 สำหรับบทที่ 4 ของวิทยานิพนธ์
สรุป:
- SPSS มีสามวิธีสำหรับสถิติเชิงพรรณนา: Descriptives (สรุปตัวเลขเร็ว), Frequencies (ข้อมูลเชิงกลุ่มและตารางความถี่) และ Explore (วิเคราะห์เชิงลึกพร้อมทดสอบการแจกแจงปกติและกราฟ)
- ค่าความเบ้ (skewness) ระหว่าง -1 ถึง +1 ถือว่าเข้าใกล้การแจกแจงปกติ ค่าเกิน -2 หรือ +2 แสดงว่าเบี่ยงเบนมาก
- รายงาน ค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐาน (SD) สำหรับตัวแปรต่อเนื่องที่แจกแจงปกติ รายงาน ค่ามัธยฐานและ IQR สำหรับข้อมูลเบ้หรือตัวแปรเรียงลำดับ
- Explore เป็นวิธีที่ละเอียดที่สุด ให้ช่วงความเชื่อมั่น, ทดสอบ Shapiro-Wilk, boxplot และ Q-Q plot ในการรันเดียว
- รายงานสถิติเชิงพรรณนา ก่อน การวิเคราะห์เชิงอนุมานในบทที่ 4 ของวิทยานิพนธ์เสมอ
ก่อนเริ่ม: คู่มือนี้สมมติว่าคุณติดตั้ง SPSS แล้ว และป้อนข้อมูลใน Data View พร้อมตั้งค่าตัวแปรใน Variable View เรียบร้อย ถ้าคุณต้องเช็คความเชื่อมั่นของแบบสอบถามก่อนสรุปผล ลองดูคู่มือ ค่าสัมประสิทธิ์แอลฟาของครอนบาคใน SPSS ของเรานะ
ชุดข้อมูลตัวอย่าง
คู่มือนี้ใช้ชุดข้อมูลตัวอย่างสำหรับวิทยานิพนธ์ที่มีผู้ตอบ 150 คน คุณดาวน์โหลดได้จากแถบด้านข้างแล้วทำตามไปด้วยกันได้เลย ชุดข้อมูลมีตัวแปร 6 ตัวที่พบบ่อยในงานวิจัยสังคมศาสตร์:
- Satisfaction (Scale, 1.00 ถึง 5.00) และ GPA (Scale, 1.80 ถึง 4.00): ตัวแปรต่อเนื่องที่แจกแจงใกล้เคียงปกติ ใช้สำหรับ Descriptives และ Explore
- StudyHours (Scale, 3.40 ถึง 35.00): ตัวแปรต่อเนื่องที่เบ้ขวาและมีค่าผิดปกติ (outlier) เล็กน้อย 2 ค่า เหมาะสำหรับดูว่าความเบ้แสดงอย่างไรในผลลัพธ์ SPSS และค่าผิดปกติปรากฏใน boxplot ของ Explore อย่างไร
- Gender (Nominal, 1 = Male, 2 = Female) และ EducationLevel (Ordinal, 1 = High School, 2 = Bachelor's, 3 = Master's): ตัวแปรเชิงกลุ่มที่ใช้สำหรับ Frequencies
- Age (Scale, 18 ถึง 40): ตัวแปรต่อเนื่องเพิ่มเติมเพื่อความหลากหลายในผลลัพธ์ Descriptives
ชุดข้อมูลตั้งใจใส่ค่าที่หายไป 2-3 ค่าต่อตัวแปร เพื่อให้คุณเห็นว่า SPSS จัดการข้อมูลหายอย่างไรในผลลัพธ์ (ดูคอลัมน์ Valid N)
ถ้าคุณเปิดไฟล์ .sav ตัวแปรจะถูกตั้งค่าไว้แล้วใน Variable View พร้อมระดับการวัดและ value labels ที่ถูกต้อง ถ้าคุณนำเข้าจากไฟล์ .xlsx แทน คุณต้องตั้งค่าเหล่านี้เอง ให้สลับไปที่ Variable View (แท็บที่ด้านล่างของหน้าต่าง SPSS) แล้วเช็คตามนี้:

รูปที่ 1: การตั้งค่า Variable View: Satisfaction, StudyHours, GPA และ Age ตั้งเป็น Scale; Gender ตั้งเป็น Nominal พร้อม value labels (1 = Male, 2 = Female); EducationLevel ตั้งเป็น Ordinal พร้อม value labels (1 = High School, 2 = Bachelor's, 3 = Master's)
การตั้งระดับการวัดให้ถูกต้องสำคัญมาก ถ้าตัวแปรต่อเนื่องถูกตั้งเป็น Nominal ผิด บางวิธีใน SPSS จะไม่รวมตัวแปรนั้นหรือให้ผลที่ไม่มีความหมาย ถ้าตัวแปรเชิงกลุ่มถูกทิ้งไว้เป็น Scale โปรแกรม SPSS จะคำนวณค่าเฉลี่ยโดยไม่เตือนอะไรเลย (ดูข้อผิดพลาดที่พบบ่อย #1 ด้านล่าง)
สถิติเชิงพรรณนาคืออะไร?
สถิติเชิงพรรณนา (descriptive statistics) ก็คือการสรุปข้อมูลของคุณโดยไม่ได้อ้างอิงไปถึงประชากรที่ใหญ่กว่า มันตอบคำถามพื้นฐานเกี่ยวกับตัวแปร: ค่าเฉลี่ยเท่าไหร่? ข้อมูลกระจายตัวแค่ไหน? การแจกแจงสมมาตรหรือเบ้ไปข้างใดข้างหนึ่ง?
ค่าสถิติเหล่านี้แบ่งออกเป็น 4 กลุ่ม:
แนวโน้มเข้าสู่ส่วนกลาง (central tendency) บอกว่าจุดกลางของข้อมูลอยู่ตรงไหน ค่าเฉลี่ย (mean) เป็นตัวที่ใช้บ่อยที่สุด ตามด้วยค่ามัธยฐาน (median) ซึ่งก็คือค่ากลางเมื่อเรียงข้อมูล และฐานนิยม (mode) ซึ่งก็คือค่าที่พบบ่อยที่สุด จะรายงานตัวไหนขึ้นอยู่กับรูปร่างการแจกแจง
การกระจาย (dispersion) บอกว่าข้อมูลกระจายตัวมากแค่ไหน ส่วนเบี่ยงเบนมาตรฐาน (standard deviation) เป็นตัวหลักที่ใช้ แต่คุณจะเจอพิสัย (range), ความแปรปรวน (variance) และพิสัยระหว่างควอร์ไทล์ (IQR) ในผลลัพธ์ SPSS ด้วย
รูปร่างการแจกแจง (distribution shape) อธิบายว่าข้อมูลสมมาตรหรือเบ้ ค่าความเบ้ (skewness) วัดความไม่สมมาตร ส่วนค่าความโด่ง (kurtosis) วัดว่าหางของการแจกแจงหนักหรือเบาเทียบกับโค้งปกติ ทั้งสองค่านี้สำคัญสำหรับตัดสินใจว่าจะใช้สถิติเชิงอนุมานแบบไหน
ตำแหน่ง (position) ระบุตำแหน่งของค่าเฉพาะเทียบกับข้อมูลที่เหลือ เช่น เปอร์เซ็นไทล์ ควอร์ไทล์ และ z-score
ทำไมสถิติเชิงพรรณนาถึงสำคัญสำหรับวิทยานิพนธ์
สำหรับวิทยานิพนธ์ สถิติเชิงพรรณนาทำหน้าที่ 3 อย่างที่อาจารย์ที่ปรึกษาและกรรมการสอบจะคาดหวัง:
ข้อแรก อธิบายลักษณะกลุ่มตัวอย่าง ผู้อ่านต้องรู้ว่าใครเข้าร่วมวิจัย การแจกแจงคะแนนเป็นอย่างไร และมีอะไรโดดเด่นบ้าง ส่วนนี้มักอยู่ตอนต้นบทที่ 4 หรือตอนท้ายบทที่ 3
ข้อที่สอง เช็คข้อตกลงเบื้องต้น (assumptions) t-test, ANOVA และ regression ล้วนมีข้อตกลงเรื่องการแจกแจงปกติ ค่าความเบ้ ค่าความโด่ง และกราฟจาก SPSS ช่วยให้คุณประเมินได้ว่าข้อตกลงเหล่านี้เป็นจริงหรือไม่ ก่อนจะรันการทดสอบจริง
ข้อที่สาม เผยปัญหาคุณภาพข้อมูล ข้อมูลหาย ค่าผิดปกติ คะแนนที่เป็นไปไม่ได้ (เช่น ได้ 6 จาก Likert Scale 1-5) และรูปแบบที่ไม่คาดคิด ทั้งหมดนี้จะปรากฏในผลลัพธ์สถิติเชิงพรรณนา การจับปัญหาเหล่านี้ได้ตั้งแต่เนิ่นจะช่วยให้คุณไม่ต้องวิเคราะห์ข้อมูลที่มีปัญหา
ควรใช้วิธีไหนใน SPSS?
SPSS มีสามวิธีภายใต้ Analyze > Descriptive Statistics แต่ละวิธีใช้แทนกันไม่ได้ วิทยานิพนธ์ส่วนใหญ่ต้องใช้อย่างน้อยสองวิธี
| วิธี | เหมาะสำหรับ | ผลลัพธ์ที่ได้ | ใช้เมื่อ |
|---|---|---|---|
| Descriptives | สรุปตัวเลขเร็วของตัวแปรต่อเนื่อง | ค่าเฉลี่ย, SD, ค่าต่ำสุด, ค่าสูงสุด, ความแปรปรวน, ความเบ้, ความโด่ง | ต้องการตารางสรุปกระชับสำหรับตัวแปรตัวเลขหลายตัวพร้อมกัน |
| Frequencies | ข้อมูลเชิงกลุ่มและการแจกแจงความถี่ | ตารางความถี่, เปอร์เซ็นต์, เปอร์เซ็นต์สะสม, ค่าเฉลี่ย, ค่ามัธยฐาน, ฐานนิยม | มีตัวแปรนามบัญญัติ/เรียงลำดับ หรือต้องการค่ามัธยฐานและฐานนิยมของตัวแปรต่อเนื่อง |
| Explore | วิเคราะห์ตัวแปรเชิงลึก | ช่วงความเชื่อมั่น, ทดสอบการแจกแจงปกติ (Shapiro-Wilk, K-S), boxplot, stem-and-leaf, Q-Q plot, ค่าผิดปกติ | ต้องเช็คข้อตกลงเรื่องการแจกแจงปกติ หาค่าผิดปกติ หรือสร้างกราฟสำหรับรายงาน |
ตารางที่ 1: เปรียบเทียบสามวิธีสถิติเชิงพรรณนาใน SPSS
สำหรับวิทยานิพนธ์ทั่วไป ให้รัน Descriptives ก่อนเพื่อดูภาพรวมของตัวแปรต่อเนื่อง จากนั้นรัน Frequencies สำหรับตัวแปรเชิงกลุ่มหรือเรียงลำดับ สุดท้ายใช้ Explore กับตัวแปรต่อเนื่องหลักเพื่อเช็คการแจกแจงปกติและหาค่าผิดปกติก่อนจะทำสถิติเชิงอนุมาน
วิธีที่ 1: Descriptives (สรุปตัวเลขเร็ว)
Descriptives เป็นวิธีที่ง่ายที่สุดในสามวิธี คำนวณสถิติสรุปพื้นฐานสำหรับตัวแปรต่อเนื่อง (scale) แล้วแสดงทุกตัวแปรในตารางเดียว ถ้าคุณต้องการภาพรวมกระชับของหลายตัวแปรเทียบกัน เริ่มที่นี่เลย
ขั้นตอนที่ 1: เปิดหน้าต่าง Descriptives
ไปที่ Analyze > Descriptive Statistics > Descriptives จากเมนูด้านบน
รูปที่ 2: การเข้าถึง Descriptives ใน SPSS
ขั้นตอนที่ 2: เลือกตัวแปร
ในหน้าต่าง Descriptives ให้ย้ายตัวแปรต่อเนื่องที่ต้องการจากแผงซ้ายไปยังช่อง Variable(s) ทางขวา คุณสามารถเลือกหลายตัวแปรพร้อมกันได้โดยกด Ctrl (Cmd บน Mac) ค้างแล้วคลิกแต่ละตัวแปร จากนั้นกดปุ่มลูกศร
รูปที่ 3: หน้าต่าง Descriptives พร้อมตัวแปรที่ย้ายไปในช่อง Variable(s)
ขั้นตอนที่ 3: ตั้งค่าตัวเลือก
กดปุ่ม Options เพื่อเลือกว่าจะให้ SPSS คำนวณสถิติอะไรบ้าง ค่าเริ่มต้น SPSS คำนวณค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน ค่าต่ำสุด และค่าสูงสุด ในหน้าต่าง Options คุณสามารถเปิดเพิ่มได้:
- Variance (ความแปรปรวน ซึ่งก็คือส่วนเบี่ยงเบนมาตรฐานยกกำลังสอง)
- Range (พิสัย ค่าสูงสุดลบค่าต่ำสุด)
- S.E. mean (ค่าคลาดเคลื่อนมาตรฐานของค่าเฉลี่ย)
- Skewness (ค่าความเบ้ วัดความสมมาตรของการแจกแจง)
- Kurtosis (ค่าความโด่ง วัดน้ำหนักของหางเทียบกับโค้งปกติ)
สำหรับวิทยานิพนธ์ ต้องเปิด Skewness และ Kurtosis อย่างน้อย เพราะค่าเหล่านี้จำเป็นสำหรับประเมินว่าข้อมูลเข้าใกล้การแจกแจงปกติหรือไม่ ซึ่งเป็นข้อตกลงเบื้องต้นของสถิติเชิงอนุมานส่วนใหญ่
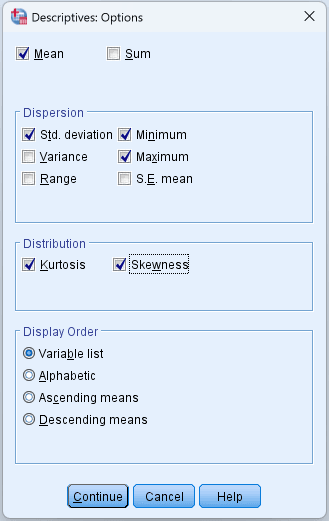
รูปที่ 4: หน้าต่าง Options ของ Descriptives พร้อมเปิดค่าความเบ้และความโด่ง
กด Continue เพื่อกลับหน้าต่างหลัก แล้วกด OK เพื่อรันการวิเคราะห์
ขั้นตอนที่ 4: อ่านผลลัพธ์
SPSS จะแสดงตาราง Descriptive Statistics หนึ่งตาราง โดยมีแถวหนึ่งแถวต่อตัวแปร
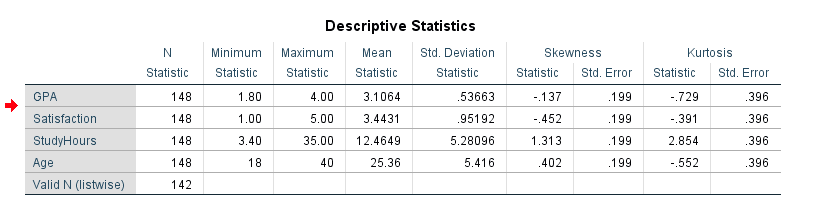
รูปที่ 5: ตารางผลลัพธ์ Descriptive Statistics ใน SPSS
วิธีอ่านแต่ละคอลัมน์:
- N คือจำนวนข้อมูลที่ใช้ได้ (ไม่นับข้อมูลหาย) ลองเทียบกับขนาดกลุ่มตัวอย่างที่คาดไว้ ถ้าตัวเลขไม่ตรงกัน แสดงว่ามีข้อมูลหายที่ต้องจัดการ
- Minimum / Maximum แสดงค่าที่เล็กที่สุดและใหญ่ที่สุดที่สังเกตได้ ให้เช็คค่าเหล่านี้กับช่วงข้อมูลที่ควรจะเป็น เช่น ถ้า Likert Scale 1-5 แต่เห็นค่า 6 แสดงว่ามีการกรอกข้อมูลผิด
- Mean คือค่าเฉลี่ยเลขคณิต สำหรับข้อมูลที่แจกแจงปกติ นี่คือตัววัดแนวโน้มเข้าสู่ส่วนกลางที่ดีที่สุด
- Std. Deviation บอกว่าข้อมูลกระจายจากค่าเฉลี่ยมากแค่ไหน ถ้า SD ใหญ่มากเมื่อเทียบกับค่าเฉลี่ย มักบ่งบอกว่ามีความแปรปรวนสูงหรือค่าผิดปกติดึงการแจกแจง
- Skewness วัดความไม่สมมาตรของการแจกแจง ดูวิธีอ่านค่าในหัวข้อด้านล่าง
- Kurtosis วัดน้ำหนักของหาง ดูวิธีอ่านค่าในหัวข้อด้านล่าง
วิธีที่ 2: Frequencies (ข้อมูลเชิงกลุ่มและจำนวนนับ)
Frequencies เป็นวิธีที่คุณต้องใช้กับตัวแปรเชิงกลุ่ม (เพศ ระดับการศึกษา กลุ่มทดลอง) และทุกกรณีที่ต้องการจำนวนนับและเปอร์เซ็นต์ นอกจากนี้ยังคำนวณค่ามัธยฐานและฐานนิยมสำหรับตัวแปรต่อเนื่อง ซึ่ง Descriptives ไม่มี ถ้ามีข้อคำถาม Likert Scale และอยากดูว่าคำตอบแจกแจงอย่างไรตามสเกล ใช้วิธีนี้เลย
ขั้นตอนที่ 1: เปิดหน้าต่าง Frequencies
ไปที่ Analyze > Descriptive Statistics > Frequencies
ขั้นตอนที่ 2: เลือกตัวแปรและตั้งค่าสถิติ
ย้ายตัวแปรไปในช่อง Variable(s) กดปุ่ม Statistics เพื่อเลือกว่าจะคำนวณค่าสถิติอะไรบ้าง
สำหรับ ตัวแปรเชิงกลุ่ม (นามบัญญัติ/เรียงลำดับ) ตารางความถี่ค่าเริ่มต้นก็เพียงพอ อาจเปิด Mode เพิ่มเพื่อดูกลุ่มที่พบบ่อยที่สุด
สำหรับ ตัวแปรต่อเนื่อง ที่ต้องการค่ามัธยฐาน ให้เลือกค่าต่อไปนี้ภายใต้ Statistics:
- Mean, Median, Mode (ภายใต้ Central Tendency)
- Std. Deviation, Variance, Range (ภายใต้ Dispersion)
- Skewness, Kurtosis (ภายใต้ Distribution)
- Quartiles หรือ Percentile(s) ถ้าต้องการ
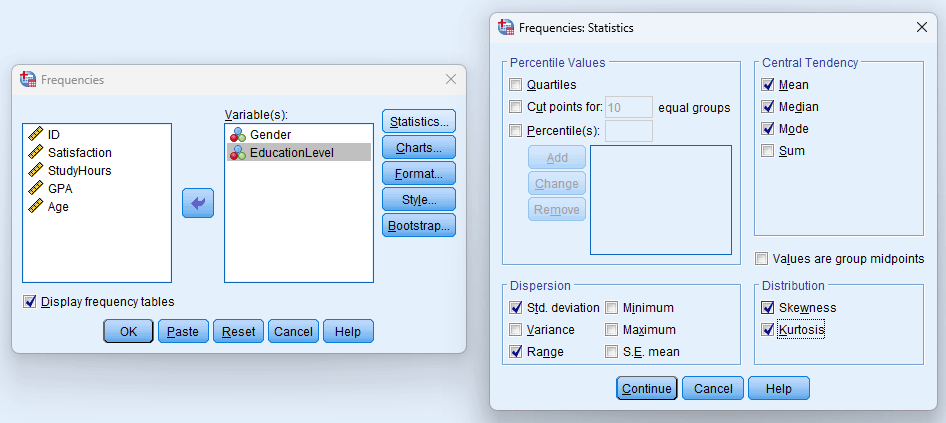
รูปที่ 6: หน้าต่าง Frequencies Statistics พร้อมตัวเลือกที่แนะนำสำหรับวิทยานิพนธ์
ขั้นตอนที่ 3: อ่านผลลัพธ์
Frequencies สร้างผลลัพธ์ 2 แบบ:
ตารางสถิติ: ตารางสรุปแสดงค่าสถิติที่คุณเลือก (ค่าเฉลี่ย ค่ามัธยฐาน ฐานนิยม SD ความเบ้ ความโด่ง Valid N, Missing N)
ตารางแจกแจงความถี่: หนึ่งตารางต่อตัวแปร แสดงค่าเฉพาะ จำนวน (Frequency) เปอร์เซ็นต์ (Percent) เปอร์เซ็นต์ที่ใช้ได้ (Valid Percent ไม่นับข้อมูลหาย) และเปอร์เซ็นต์สะสม (Cumulative Percent)
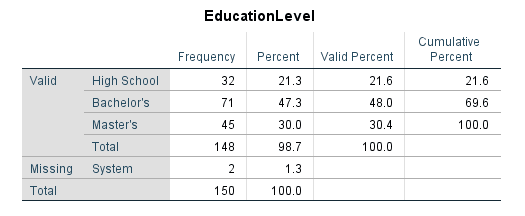
รูปที่ 7: ตารางแจกแจงความถี่ของตัวแปรเชิงกลุ่ม
จุดสำคัญในการอ่านผล:
- Percent รวมข้อมูลหายในตัวหาร ส่วน Valid Percent ไม่รวม ในวิทยานิพนธ์ให้รายงาน Valid Percent เพราะมันแสดงการแจกแจงจริงของผู้ที่ตอบคำถาม
- Cumulative Percent แสดงเปอร์เซ็นต์สะสม เหมาะสำหรับข้อมูลเรียงลำดับ เช่น "73% ของผู้ตอบให้คะแนนความพึงพอใจ 4 หรือต่ำกว่าจากสเกล 5 ระดับ"
- สำหรับข้อคำถาม Likert Scale ตารางความถี่มักให้ข้อมูลมากกว่าค่าเฉลี่ยอย่างเดียว ค่าเฉลี่ย 3.5 หน้าตาต่างกันมากเมื่อ 80% เลือก 3 หรือ 4 เทียบกับเมื่อคำตอบแบ่งครึ่งระหว่าง 1 กับ 5
วิธีที่ 3: Explore (วิเคราะห์เชิงลึก)
Explore เป็นวิธีที่ทรงพลังที่สุดในสามวิธี และเป็นวิธีที่กรรมการสอบมักถามถึงมากที่สุด มันสร้างการทดสอบการแจกแจงปกติ (Shapiro-Wilk และ Kolmogorov-Smirnov), ช่วงความเชื่อมั่น, ตารางค่าผิดปกติ และกราฟ (ฮิสโตแกรม, boxplot, Q-Q plot) ในการรันเดียว
ขั้นตอนที่ 1: เปิดหน้าต่าง Explore
ไปที่ Analyze > Descriptive Statistics > Explore
ขั้นตอนที่ 2: ตั้งค่าการวิเคราะห์
- ย้ายตัวแปรต่อเนื่องไปในช่อง Dependent List
- ถ้าต้องการสถิติเชิงพรรณนาแยกตามกลุ่ม (เช่น เปรียบเทียบชายกับหญิง) ให้ย้ายตัวแปรกลุ่มไปในช่อง Factor List
- ในส่วน Display ด้านล่าง เลือก Both เพื่อให้แสดงทั้งสถิติและกราฟ
ขั้นตอนที่ 3: ตั้งค่ากราฟและสถิติ
กด Plots เพื่อตั้งค่ากราฟ สำหรับวิทยานิพนธ์ ให้เปิด:
- Histogram (พร้อมเส้นโค้งปกติซ้อนทับ)
- Normality plots with tests (สร้างทดสอบ Shapiro-Wilk และ Kolmogorov-Smirnov พร้อม Q-Q plot)
กด Statistics เพื่อเช็คว่า:
- Descriptives ถูกเลือก (ให้ค่าเฉลี่ย ค่ามัธยฐาน ความแปรปรวน SD ค่าต่ำสุด ค่าสูงสุด พิสัย IQR ความเบ้ ความโด่ง และช่วงความเชื่อมั่น 95% ของค่าเฉลี่ย)
- Outliers ถูกเลือก (ระบุ 5 ค่าที่ใหญ่ที่สุดและเล็กที่สุด)
- Percentiles ถูกเลือก ถ้าต้องการค่าควอร์ไทล์หรือเปอร์เซ็นไทล์
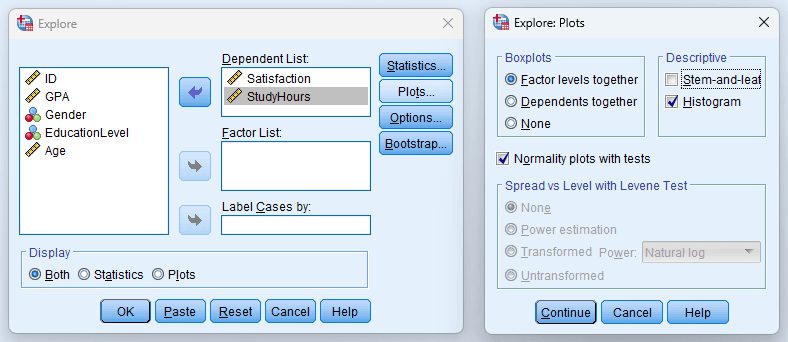
รูปที่ 8: หน้าต่าง Explore Plots พร้อมการตั้งค่าที่แนะนำสำหรับวิทยานิพนธ์
ขั้นตอนที่ 4: อ่านผลลัพธ์
Explore สร้างผลลัพธ์หลายส่วน:
ตาราง Descriptives: รวมค่าเฉลี่ย (พร้อมช่วงความเชื่อมั่น 95%) ค่าเฉลี่ยตัดขอบ 5% (5% trimmed mean) ค่ามัธยฐาน ความแปรปรวน ส่วนเบี่ยงเบนมาตรฐาน ค่าต่ำสุด ค่าสูงสุด พิสัย IQR ความเบ้ และความโด่ง
ให้สังเกต 5% trimmed mean ด้วย SPSS จะตัดข้อมูล 5% บนและล่างออกแล้วคำนวณค่าเฉลี่ยใหม่ ถ้าค่าเฉลี่ยตัดขอบต่างจากค่าเฉลี่ยปกติมาก แสดงว่ามีค่าผิดปกติดึงค่าเฉลี่ยไปทางใดทางหนึ่ง
ตาราง Tests of Normality: แสดงผลทดสอบ Kolmogorov-Smirnov (K-S) และ Shapiro-Wilk สำหรับกลุ่มตัวอย่างน้อยกว่า 50 ควรดูค่า Shapiro-Wilk ถ้าผลมีนัยสำคัญ (p < .05) แสดงว่าการแจกแจงเบี่ยงเบนจากปกติอย่างมีนัยสำคัญ
Boxplot: ระบุค่าผิดปกติ (วงกลม) และค่าสุดขั้ว (ดอกจัน) ข้อมูลที่ปรากฏเป็นค่าผิดปกติใน boxplot ควรตรวจสอบเพิ่มเติม
Q-Q Plot: จุดที่อยู่ตามแนวเส้นทแยงมุมแสดงว่าข้อมูลเข้าใกล้การแจกแจงปกติ ถ้าจุดเบี่ยงออกจากเส้นอย่างเป็นระบบ แสดงว่าไม่ใช่การแจกแจงปกติ
วิธีอ่านค่าความเบ้และความโด่ง
ค่าสองตัวนี้ปรากฏในผลลัพธ์ทั้ง Descriptives และ Explore และเป็นตัวตัดสินว่าคุณจะใช้สถิติแบบพาราเมตริกได้หรือต้องเปลี่ยนไปใช้ทางเลือกอื่น
วิธีอ่านค่าความเบ้ (Skewness)
| ค่าความเบ้ | ความหมาย | ผลที่ตามมา |
|---|---|---|
| ใกล้ 0 | การแจกแจงสมมาตร | ข้อมูลเข้าใกล้การแจกแจงปกติ (ดี) |
| เป็นบวก (> 0) | เบ้ขวา (positive skew) | หางยื่นไปทางขวา ข้อมูลส่วนใหญ่อยู่ทางซ้าย |
| เป็นลบ (< 0) | เบ้ซ้าย (negative skew) | หางยื่นไปทางซ้าย ข้อมูลส่วนใหญ่อยู่ทางขวา |
| ระหว่าง -1 ถึง +1 | เข้าใกล้ปกติ | ยอมรับได้สำหรับสถิติพาราเมตริกส่วนใหญ่ |
| ระหว่าง -2 ถึง +2 | เบ้ปานกลาง | ยอมรับได้โดยมีข้อระวัง สถิติบางตัวทนต่อระดับนี้ได้ |
| เกิน -2 หรือ +2 | เบ้มาก | พิจารณาแปลงข้อมูลหรือใช้สถิตินอนพาราเมตริก |
ตารางที่ 2: วิธีอ่านค่าความเบ้
วิธีอ่านค่าความโด่ง (Kurtosis)
SPSS รายงาน ค่าความโด่งส่วนเกิน (excess kurtosis) ซึ่งหมายความว่าการแจกแจงปกติจะมีค่าความโด่ง = 0 (ไม่ใช่ 3 ตามสูตรทางคณิตศาสตร์)
| ค่าความโด่ง | ความหมาย | ผลที่ตามมา |
|---|---|---|
| ใกล้ 0 | Mesokurtic (ความแหลมปกติ) | หางคล้ายกับการแจกแจงปกติ |
| เป็นบวก (> 0) | Leptokurtic (หางหนัก) | มีค่าสุดขั้วมากกว่าปกติ อาจมีค่าผิดปกติ |
| เป็นลบ (< 0) | Platykurtic (หางเบา) | มีค่าสุดขั้วน้อยกว่าปกติ |
| ระหว่าง -1 ถึง +1 | เข้าใกล้ปกติ | ยอมรับได้สำหรับสถิติพาราเมตริก |
| เกิน -2 หรือ +2 | ไม่เป็นปกติมาก | ตรวจสอบค่าผิดปกติ พิจารณาแปลงข้อมูล |
ตารางที่ 3: วิธีอ่านค่าความโด่ง
หลักปฏิบัติคือ: ถ้าทั้งค่าความเบ้และความโด่งอยู่ระหว่าง -1 ถึง +1 ใช้สถิติพาราเมตริกได้เลย ถ้าค่าใดเกิน -2 หรือ +2 พิจารณาแปลงข้อมูล (log, square root) หรือเปลี่ยนไปใช้สถิตินอนพาราเมตริก ค่าระหว่าง -1 ถึง -2 (หรือ +1 ถึง +2) ต้องพิจารณาเป็นกรณี ขึ้นอยู่กับขนาดกลุ่มตัวอย่างและความทนทานของสถิติที่เลือกใช้
วิธีรายงานสถิติเชิงพรรณนาในรูปแบบ APA
APA ฉบับที่ 7 มีข้อกำหนดเฉพาะสำหรับการรายงานสถิติเชิงพรรณนา แม่แบบด้านล่างออกแบบมาเพื่อให้คุณนำไปปรับใช้กับบทที่ 4 ของวิทยานิพนธ์ได้โดยตรง
แม่แบบ APA สำหรับตัวแปรต่อเนื่อง
อย่างน้อยต้องรายงานขนาดกลุ่มตัวอย่าง ค่าเฉลี่ย และส่วนเบี่ยงเบนมาตรฐานของแต่ละตัวแปรต่อเนื่อง ถ้าอาจารย์ที่ปรึกษาต้องการเอกสารการเช็คการแจกแจงปกติ (ส่วนใหญ่ต้องการ) ให้ใส่ค่าความเบ้และความโด่งด้วย
การรายงานในเนื้อความ:
คะแนนความพึงพอใจของผู้ตอบอยู่ระหว่าง 1.00 ถึง 5.00 (M = 3.44, SD = 0.95, N = 148) การแจกแจงเข้าใกล้ปกติ (skewness = -0.45, kurtosis = -0.39)
รูปแบบตาราง (แนะนำสำหรับหลายตัวแปร):
| ตัวแปร | N | M | SD | Min | Max | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
| Satisfaction | 148 | 3.44 | 0.95 | 1.00 | 5.00 | -0.45 | -0.39 |
| Study Hours | 148 | 12.46 | 5.28 | 3.40 | 35.00 | 1.31 | 2.85 |
| GPA | 148 | 3.11 | 0.54 | 1.80 | 4.00 | -0.14 | -0.73 |
ตารางที่ 4: ตัวอย่างตารางสถิติเชิงพรรณนาในรูปแบบ APA
ข้อควรจำสำหรับรูปแบบ APA:
- ใช้ตัวเอียงสำหรับสัญลักษณ์สถิติ: M, SD, N, n
- ทศนิยม 2 ตำแหน่งสำหรับสถิติส่วนใหญ่
- ค่าในตารางไม่ต้องตัวหนา เฉพาะแถวหัวตารางเท่านั้น
- ใส่หมายเลขตารางตามลำดับ ("ตารางที่ 1", "ตารางที่ 2") พร้อมชื่อตารางเชิงบรรยายไว้ด้านบน
- ตารางสถิติเชิงพรรณนาอยู่ตอนต้นบทที่ 4 ก่อนการวิเคราะห์เชิงอนุมาน
แม่แบบ APA สำหรับตัวแปรเชิงกลุ่ม
สำหรับตัวแปรเชิงกลุ่ม ให้รายงานความถี่และเปอร์เซ็นต์
การรายงานในเนื้อความ:
กลุ่มตัวอย่างประกอบด้วยเพศหญิง 87 คน (58.4%) และเพศชาย 62 คน (41.6%) ผู้ตอบส่วนใหญ่สำเร็จการศึกษาระดับปริญญาตรี (n = 71, 48.0%) ตามด้วยปริญญาโท (n = 45, 30.4%) และมัธยมปลาย (n = 32, 21.6%)
รูปแบบตาราง:
| ตัวแปร | กลุ่ม | n | % |
|---|---|---|---|
| เพศ | หญิง | 87 | 58.4 |
| ชาย | 62 | 41.6 | |
| ระดับการศึกษา | มัธยมปลาย | 32 | 21.6 |
| ปริญญาตรี | 71 | 48.0 | |
| ปริญญาโท | 45 | 30.4 |
ตารางที่ 5: ตัวอย่างตารางความถี่ในรูปแบบ APA สำหรับตัวแปรเชิงกลุ่ม
สถิติเชิงพรรณนาควรอยู่ตรงไหนในวิทยานิพนธ์
สถิติเชิงพรรณนามักอยู่ในที่ใดที่หนึ่งจาก 2 ที่:
-
ตอนท้ายบทที่ 3 (ระเบียบวิธีวิจัย) สำหรับข้อมูลประชากรศาสตร์ของกลุ่มตัวอย่าง รายงานลักษณะกลุ่มตัวอย่าง: สัดส่วนเพศ ช่วงอายุ ระดับการศึกษา และตัวแปรประชากรศาสตร์อื่น
-
ตอนต้นบทที่ 4 (ผลการวิจัย) สำหรับสรุปตัวแปร รายงานสถิติเชิงพรรณนาของตัวแปรวิจัย (ค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน คุณสมบัติการแจกแจง) ก่อนแสดงผลสถิติเชิงอนุมาน
อาจารย์ที่ปรึกษาบางท่านอาจต้องการให้ใส่สถิติเชิงพรรณนาทั้งหมดไว้ในบทที่ 4 ลองสอบถามอาจารย์ที่ปรึกษาของคุณนะ
ข้อผิดพลาดที่พบบ่อยเมื่อรันสถิติเชิงพรรณนาใน SPSS
1. ใช้ Descriptives กับตัวแปรเชิงกลุ่ม
ถ้าเพศถูกใส่รหัสเป็น 1 = ชาย และ 2 = หญิง SPSS จะคำนวณค่าเฉลี่ยออกมาเป็น 1.58 โดยไม่เตือนอะไรเลย ค่านั้นไม่มีความหมาย Descriptives คำนวณค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐาน ซึ่งเหมาะกับตัวแปรต่อเนื่องเท่านั้น ใช้ Frequencies สำหรับข้อมูลเชิงกลุ่ม
2. ไม่ดูค่า Valid N
SPSS รายงานจำนวนข้อมูลที่ใช้ได้ (ไม่นับข้อมูลหาย) เป็น N ในผลลัพธ์ ถ้าชุดข้อมูลมี 200 ราย แต่ตัวแปรหนึ่งแสดง N = 185 แสดงว่ามีข้อมูลหาย 15 ค่า ต้องเช็ค Valid N เสมอและรายงานข้อมูลหายในวิทยานิพนธ์
3. รายงานแค่ค่าเฉลี่ยไม่มีค่าการกระจาย
ค่าเฉลี่ยความพึงพอใจ 3.5 อาจมาจากกลุ่มตัวอย่างที่ทุกคนให้คะแนนระหว่าง 3 กับ 4 หรืออาจมาจากกลุ่มที่ครึ่งหนึ่งให้ 1 อีกครึ่งให้ 5 ค่าเฉลี่ยอย่างเดียวบอกไม่ได้ว่าเป็นแบบไหน ต้องรายงานคู่กับส่วนเบี่ยงเบนมาตรฐานเสมอ
4. ไม่เช็คค่าความเบ้ก่อนใช้สถิติพาราเมตริก
นักศึกษาหลายคนข้ามจากสถิติเชิงพรรณนาไป t-test หรือ ANOVA เลยโดยไม่เช็คการแจกแจงปกติก่อน ถ้าข้อมูลเบ้มาก (เกิน +/-2) ผล parametric test อาจไม่น่าเชื่อถือ Explore ทำให้การเช็คนี้ง่ายเพราะให้ทั้งตัวเลขทดสอบและกราฟ
5. สับสนระหว่าง Percent กับ Valid Percent ในตารางแจกแจงความถี่
SPSS รายงานทั้ง Percent (รวมข้อมูลหายในตัวหาร) และ Valid Percent (ไม่รวมข้อมูลหาย) ในวิทยานิพนธ์ ให้รายงาน Valid Percent เพราะมันแสดงการแจกแจงของผู้ที่ตอบคำถามจริง
6. รายงานทศนิยมมากเกินไป
ผลลัพธ์ SPSS มักแสดงทศนิยม 8 ตำแหน่งหรือมากกว่า การคัดลอก M = 3.4527189 ลงในวิทยานิพนธ์ดูไม่เป็นมืออาชีพ และบอกเป็นนัยว่าเครื่องมือวัดมีความแม่นยำสูงขนาดนั้น ซึ่งแทบจะไม่มีทาง APA แนะนำทศนิยม 2 ตำแหน่ง: M = 3.45
7. รัน Descriptives โดยไม่เช็คระดับการวัดของตัวแปร
SPSS ใช้ระดับการวัดที่ตั้งใน Variable View (Nominal, Ordinal, Scale) เพื่อตัดสินว่าสถิติอะไรเหมาะสม ถ้าตัวแปรต่อเนื่องถูกตั้งเป็น Nominal ผิด บางวิธีอาจไม่รวมตัวแปรนั้น ให้เช็คระดับการวัดใน Variable View ก่อนรันการวิเคราะห์ใดก็ตาม
คำถามที่อาจารย์ที่ปรึกษาและกรรมการสอบจะถาม
คำถามเหล่านี้เจอบ่อยในการสอบวิทยานิพนธ์ที่เกี่ยวข้องกับข้อมูลเชิงปริมาณ:
"รู้ได้อย่างไรว่าข้อมูลแจกแจงปกติ?" ตรงนี้แหละที่ผลลัพธ์จาก Explore จะมีค่ามาก ชี้ไปที่ค่าความเบ้และความโด่ง ผล Shapiro-Wilk และ Q-Q plot แล้วบอกเกณฑ์ที่ใช้: "ค่าความเบ้และความโด่งอยู่ในช่วง -1 ถึง +1 สำหรับทุกตัวแปร และ Q-Q plot ไม่แสดงการเบี่ยงเบนอย่างเป็นระบบจากการแจกแจงปกติ"
"ทำไมถึงเลือกค่าเฉลี่ยและ SD แทนที่จะเป็นค่ามัธยฐานและ IQR?" คำตอบควรแสดงว่าคุณตัดสินใจอย่างมีเหตุผล ไม่ใช่เลือกตามค่าเริ่มต้น อธิบายว่าคุณเช็ครูปร่างการแจกแจงก่อนและพบว่าข้อมูลเข้าใกล้การแจกแจงปกติ จึงเลือกใช้ค่าสรุปแบบพาราเมตริก
"มีข้อมูลหายเท่าไหร่ และจัดการอย่างไร?" ผลลัพธ์สถิติเชิงพรรณนาบอกข้อมูลนี้อยู่แล้วในคอลัมน์ Valid N ให้บอกเปอร์เซ็นต์ข้อมูลหายต่อตัวแปร แล้วอธิบายวิธีจัดการ (listwise deletion, pairwise deletion หรือ imputation) พร้อมเหตุผล
"มีค่าผิดปกติในข้อมูลไหม?" อ้างอิง boxplot และตาราง Extreme Values จาก Explore ถ้าพบค่าผิดปกติ ให้อธิบายว่าเก็บไว้หรือตัดออก และเพราะอะไร กรรมการสอบต้องการเห็นว่าคุณตรวจสอบแล้ว ไม่ได้เพิกเฉย
คำถามที่พบบ่อย
ขั้นตอนถัดไปหลังจากสถิติเชิงพรรณนา
หลังจากดูผลลัพธ์สถิติเชิงพรรณนาแล้ว ขั้นตอนถัดไปขึ้นอยู่กับสิ่งที่คุณพบ:
ถ้าค่าความเบ้หรือความโด่งชี้ว่าอาจไม่ใช่การแจกแจงปกติ ให้รันทดสอบการแจกแจงปกติอย่างเป็นทางการ คู่มือการทดสอบการแจกแจงปกติใน SPSS ของเราอธิบาย Shapiro-Wilk, Q-Q plot และวิธีแก้เมื่อข้อมูลไม่ผ่าน Explore สร้างทดสอบเหล่านี้อยู่แล้ว แต่ถ้าคุณข้าม Explore ไป จะต้องทำเพิ่มก่อนรันสถิติพาราเมตริก
ถ้าตัวแปรเป็นแบบหลายข้อคำถาม (เช่น มาตราส่วนความพึงพอใจที่มี 5 ข้อ Likert) ให้เช็คความเชื่อมั่นด้วย ค่าสัมประสิทธิ์แอลฟาของครอนบาคใน SPSS ก่อนคำนวณคะแนนรวม
พอข้อมูลสะอาดและข้อตกลงเบื้องต้นผ่านแล้ว ก็เดินหน้าทดสอบสมมติฐานได้ สถิติที่ใช้ขึ้นอยู่กับแบบแผนการวิจัย:
- เปรียบเทียบค่าเฉลี่ย 2 กลุ่ม: Independent samples t-test หรือ paired samples t-test
- เปรียบเทียบ 3 กลุ่มขึ้นไป: Repeated Measures ANOVA หรือ One-way ANOVA
- ตรวจสอบความสัมพันธ์ระหว่างตัวแปรต่อเนื่อง: สหสัมพันธ์ หรือ การวิเคราะห์ Linear Regression ใน SPSS
- ทดสอบสมมติฐานตัวแปรคั่นกลาง: การวิเคราะห์ตัวแปรคั่นกลางใน SPSS
- ทดสอบสมมติฐานตัวแปรกำกับ: การวิเคราะห์ตัวแปรกำกับใน SPSS
เอกสารอ้างอิง
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). American Psychological Association.
Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). SAGE Publications.
George, D., & Mallery, P. (2019). IBM SPSS statistics 26 step by step: A simple guide and reference (16th ed.). Routledge.
Hair, J. F., Babin, B. J., Anderson, R. E., & Black, W. C. (2019). Multivariate data analysis (8th ed.). Cengage Learning.
Pallant, J. (2020). SPSS survival manual (7th ed.). Open University Press.
Tabachnick, B. G., & Fidell, L. S. (2019). Using multivariate statistics (7th ed.). Pearson.