การทดสอบการแจกแจงปกติ (normality test) เป็นขั้นตอนที่อาจารย์ที่ปรึกษาคาดหวังให้ทำก่อนรันสถิติพาราเมตริกทุกตัว t-test, ANOVA, สหสัมพันธ์ Pearson และ regression เชิงเส้น ทั้งหมดมีข้อสมมติว่าข้อมูล (หรือค่าคงเหลือ) แจกแจงใกล้เคียงปกติ ถ้าข้ามขั้นตอนนี้ไป มักเป็นจุดที่โดนติตอนสอบวิทยานิพนธ์
SPSS มีสี่วิธีสำหรับเช็คการแจกแจงปกติ: Shapiro-Wilk, Kolmogorov-Smirnov, Q-Q plot และฮิสโตแกรมพร้อมโค้งปกติ คู่มือนี้ครอบคลุมทั้งสี่วิธี อธิบายวิธีอ่านผลลัพธ์ และบอกว่าต้องทำอย่างไรเมื่อข้อมูลไม่ผ่านการทดสอบ
สรุป:
- ใช้ Explore (Analyze > Descriptive Statistics > Explore) เพื่อรันการทดสอบทั้งหมดในขั้นตอนเดียว: Shapiro-Wilk, K-S, ฮิสโตแกรม และ Q-Q plot
- Shapiro-Wilk มีพลังทางสถิติสูงกว่า Kolmogorov-Smirnov และเป็นที่แนะนำสำหรับวิทยานิพนธ์ส่วนใหญ่ (กลุ่มตัวอย่างไม่เกิน 2,000)
- ผลทดสอบมีนัยสำคัญ (p < .05) แปลว่าข้อมูลเบี่ยงเบนจากปกติ แต่ ความรุนแรงในทางปฏิบัติสำคัญกว่าค่า p โดยเฉพาะกับกลุ่มตัวอย่างใหญ่
- ค่าความเบ้ระหว่าง -1 ถึง +1 โดยทั่วไปถือว่ายอมรับได้สำหรับสถิติพาราเมตริก ค่าเกิน +/-2 บ่งชี้ปัญหาจริง
- เมื่อการแจกแจงปกติไม่ผ่าน มีสามทางเลือก: สถิตินอนพาราเมตริก, การแปลงข้อมูล หรือ รันต่อพร้อมเหตุผลรองรับ (สถิติพาราเมตริกที่ทนทาน)
ก่อนเริ่ม: คู่มือนี้สมมติว่าคุณโหลดข้อมูลใน SPSS แล้ว พร้อมตั้งค่าตัวแปรใน Variable View เรียบร้อย ถ้ายังไม่ได้รันสถิติเชิงพรรณนา ให้เริ่มที่คู่มือสถิติเชิงพรรณนาใน SPSS ก่อนนะ แล้วก็เช็คด้วยว่าตัวแปรต่อเนื่องตั้งระดับการวัดเป็น Scale ใน Variable View แล้ว
ทำไมการแจกแจงปกติถึงสำคัญสำหรับวิทยานิพนธ์
สถิติพาราเมตริก (t-test, ANOVA, สหสัมพันธ์ Pearson, regression เชิงเส้น) ตั้งอยู่บนข้อสมมติว่าข้อมูลแจกแจงแบบสมมาตร มีรูปร่างเป็นระฆังคว่ำ ถ้าข้อสมมตินี้ถูกละเมิดอย่างรุนแรง ค่า p ที่ได้อาจไม่แม่นยำ ทำให้สรุปผลผิดเกี่ยวกับสมมติฐาน
คำถามสำหรับวิทยานิพนธ์ไม่ใช่ว่าข้อมูลแจกแจงปกติสมบูรณ์หรือเปล่า ไม่มีข้อมูลจริงที่แจกแจงปกติสมบูรณ์ คำถามคือความเบี่ยงเบนรุนแรงพอที่จะส่งผลต่อการวิเคราะห์ไหม ข้อแตกต่างนี้สำคัญเพราะเหตุผลหลายประการ:
สถิติพาราเมตริก ทนทานต่อการละเมิดปานกลาง งานวิจัยแสดงให้เห็นอย่างสม่ำเสมอว่า t-test และ ANOVA ทำงานได้ดีแม้ข้อสมมติการแจกแจงปกติถูกละเมิดปานกลาง โดยเฉพาะเมื่อกลุ่มตัวอย่างเกิน 30 คน (Glass, Peckham และ Sanders, 1972; Schmider et al., 2010) การแจกแจงที่เบ้เล็กน้อยไม่ได้ทำให้ผลลัพธ์เป็นโมฆะ
กับ กลุ่มตัวอย่างใหญ่ การทดสอบจะไวเกินไป Shapiro-Wilk จะบอกว่าความเบี่ยงเบนเล็กน้อยมาก "มีนัยสำคัญ" เมื่อมี 300 คนขึ้นไป ทั้งที่ความเบี่ยงเบนนั้นไม่ส่งผลต่อสถิติพาราเมตริกเลย
กับ กลุ่มตัวอย่างเล็ก การทดสอบมีพลังไม่เพียงพอ เมื่อมีน้อยกว่า 20 คน ทั้ง Shapiro-Wilk และ K-S อาจตรวจไม่พบการแจกแจงที่ไม่ปกติจริง การดูด้วยตาจึงสำคัญมาก
นั่นคือเหตุผลที่นักวิจัยที่มีประสบการณ์ใช้หลายวิธีร่วมกัน แทนที่จะพึ่งพาการทดสอบหรือเกณฑ์ตัวเดียว
ควรใช้วิธีทดสอบการแจกแจงปกติตัวไหน
SPSS มีหลายวิธีสำหรับประเมินการแจกแจงปกติ แต่ละวิธีมีจุดแข็งและข้อจำกัด วิทยานิพนธ์ของคุณจะแข็งแรงที่สุดเมื่อใช้อย่างน้อยสองวิธีร่วมกัน
| วิธี | ประเภท | จุดแข็ง | ข้อจำกัด | แนะนำสำหรับ |
|---|---|---|---|---|
| Shapiro-Wilk | ทดสอบทางสถิติ | พลังทางสถิติสูงที่สุด แนะนำอย่างกว้างขวาง | ไวเกินไปกับกลุ่มตัวอย่างใหญ่ (n > 300) จำกัดที่ n < 2,000 | การทดสอบหลักสำหรับวิทยานิพนธ์ส่วนใหญ่ |
| Kolmogorov-Smirnov (Lilliefors) | ทดสอบทางสถิติ | ไม่มีขีดจำกัดขนาดกลุ่มตัวอย่าง | พลังต่ำกับกลุ่มตัวอย่างเล็ก ไวน้อยกว่า Shapiro-Wilk | การทดสอบเสริม บางอาจารย์ต้องการดู |
| Q-Q plot | ดูด้วยตา | เห็นชัดว่าข้อมูลเบี่ยงเบนตรงไหนและอย่างไร ไม่ได้รับผลจากขนาดกลุ่มตัวอย่าง | ต้องตีความด้วยดุลยพินิจ | เสริมการทดสอบทางสถิติ สำคัญมาก |
| ฮิสโตแกรม | ดูด้วยตา | เข้าใจง่าย เห็นรูปร่างการแจกแจง ช่องว่าง และการกระจุกตัว | ประเมินยากกับกลุ่มตัวอย่างเล็ก ความกว้างแท่งส่งผลต่อรูปร่าง | คัดกรองเบื้องต้นเร็ว |
| ค่าความเบ้/ความโด่ง | ตัวเลข | เกณฑ์ตัดสินชัดเจน รายงานง่าย | ไม่ได้ทดสอบสมมติฐาน เกณฑ์เป็นแนวปฏิบัติ ไม่ใช่กฎตายตัว | หลักฐานเสริมสำหรับรายงาน APA |
ตารางที่ 1: เปรียบเทียบวิธีประเมินการแจกแจงปกติใน SPSS
แนวทางแนะนำสำหรับวิทยานิพนธ์: รัน Shapiro-Wilk เป็นการทดสอบหลัก ดู Q-Q plot เพื่อยืนยันด้วยตา แล้วรายงานค่าความเบ้/ความโด่งเป็นหลักฐานเสริม ใส่ฮิสโตแกรมในภาคผนวกถ้าอาจารย์อยากเห็นรูปร่างการแจกแจง
ชุดข้อมูลตัวอย่าง
คู่มือนี้ใช้ชุดข้อมูลตัวอย่างเดียวกับคู่มือสถิติเชิงพรรณนา ดาวน์โหลดได้จากแถบด้านข้าง ชุดข้อมูลมีผู้ตอบ 150 คน พร้อมตัวแปรที่ออกแบบมาเพื่อแสดงทั้งการแจกแจงปกติและไม่ปกติ:
- Satisfaction (Scale, 1.00 ถึง 5.00): แจกแจงใกล้เคียงปกติตามค่าความเบ้และความโด่ง แต่ Shapiro-Wilk จะบอกว่ามีนัยสำคัญเพราะไวต่อขนาดกลุ่มตัวอย่าง
- StudyHours (Scale, 3.40 ถึง 35.00): เบ้ขวา มีค่าผิดปกติเล็กน้อย 2 ค่า ตัวแปรนี้มีการละเมิดการแจกแจงปกติจริง ที่เห็นได้ทั้งจากตัวเลขและกราฟ
- GPA (Scale, 1.80 ถึง 4.00): แจกแจงใกล้เคียงปกติ
- Age (Scale, 18 ถึง 40): แจกแจงใกล้เคียงปกติ
การที่ชุดข้อมูลมีทั้งตัวแปรปกติและไม่ปกติเป็นสิ่งที่ตั้งใจ มันสร้างสถานการณ์ที่นักศึกษาส่วนใหญ่จะเจอ: ผล Shapiro-Wilk มีนัยสำคัญ แต่ไม่ได้หมายความว่าใช้สถิติพาราเมตริกไม่ได้
ทีละขั้นตอน: รันการทดสอบการแจกแจงปกติใน SPSS
Explore เป็นวิธีที่มีประสิทธิรูปที่สุดสำหรับเช็คการแจกแจงปกติ เพราะมันสร้างทั้งสี่วิธี (Shapiro-Wilk, K-S, Q-Q plot และฮิสโตแกรม) ในการรันครั้งเดียว
ขั้นตอนที่ 1: เปิดหน้าต่าง Explore
ไปที่ Analyze > Descriptive Statistics > Explore
รูปที่ 1: ไปที่ Analyze > Descriptive Statistics > Explore ในเมนู SPSS
ขั้นตอนที่ 2: เลือกตัวแปร
ย้ายตัวแปรต่อเนื่องที่ต้องการทดสอบไปในช่อง Dependent List สำหรับคู่มือนี้ ย้าย Satisfaction, StudyHours, GPA และ Age ไปใส่
อย่าใส่ตัวแปรเชิงกลุ่ม (Gender, EducationLevel) ใน Dependent List นะ การทดสอบการแจกแจงปกติใช้กับตัวแปรต่อเนื่องเท่านั้น
ถ้าต้องการทดสอบการแจกแจงปกติแยกตามกลุ่ม (เช่น คะแนน Satisfaction ของเพศชายกับเพศหญิงแยกกัน) ให้เพิ่มตัวแปรกลุ่มในช่อง Factor List สิ่งนี้สำคัญเมื่อการวิเคราะห์ถัดไปเปรียบเทียบกลุ่ม เพราะข้อสมมติการแจกแจงปกติใช้กับข้อมูลภายในแต่ละกลุ่ม
รูปที่ 2: หน้าต่าง Explore ที่มี Satisfaction, StudyHours, GPA และ Age ในช่อง Dependent List
ขั้นตอนที่ 3: เปิดกราฟการแจกแจงปกติ
กดปุ่ม Plots ในหน้าต่าง Explore ในหน้าต่างย่อย Plots:
- ติ๊กถูก Normality plots with tests ซึ่งจะเปิดใช้ Shapiro-Wilk และ Kolmogorov-Smirnov พร้อม Q-Q plot
- ที่ Boxplots ให้ปล่อยเป็น Factor levels together (ค่าเริ่มต้น)
- ถ้าอยากได้ฮิสโตแกรมด้วย ให้ติ๊กถูก Histogram
กด Continue เพื่อกลับไปหน้าต่างหลัก
รูปที่ 3: หน้าต่าง Explore Plots: ติ๊กถูก "Normality plots with tests" และ "Histogram" ตามต้องการ
ขั้นตอนที่ 4: รันการวิเคราะห์
กด OK ในหน้าต่างหลัก Explore SPSS จะแสดงผลลัพธ์ใน Output Viewer ซึ่งรวมถึง:
- ตาราง Descriptives (พร้อมค่าความเบ้และความโด่ง)
- ตาราง Tests of Normality (Shapiro-Wilk และ Kolmogorov-Smirnov)
- Q-Q plot ปกติสำหรับแต่ละตัวแปร
- Detrended Q-Q plot
- ฮิสโตแกรม (ถ้าเลือกไว้)
- Boxplot
การอ่านผลลัพธ์
ตาราง Tests of Normality
ตารางนี้มักเป็นสิ่งแรกที่อาจารย์ที่ปรึกษาจะดู SPSS แสดงผล Kolmogorov-Smirnov (พร้อมการปรับแก้ Lilliefors) และ Shapiro-Wilk เคียงกัน
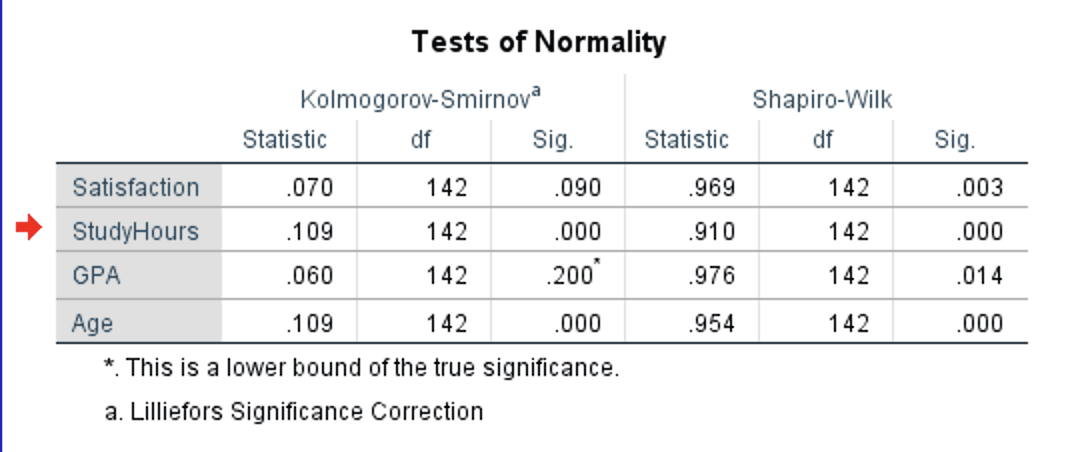
รูปที่ 4: ตาราง Tests of Normality แสดงผล Kolmogorov-Smirnov และ Shapiro-Wilk สำหรับทั้ง 4 ตัวแปร
วิธีอ่านตารางนี้:
- Statistic: ค่าสถิติทดสอบ สำหรับ Shapiro-Wilk ค่ายิ่งใกล้ 1.000 ยิ่งบ่งชี้การแจกแจงปกติมาก สำหรับ K-S ค่ายิ่งน้อยยิ่งดี
- df: องศาอิสระ (เท่ากับขนาดกลุ่มตัวอย่างของแต่ละตัวแปร ลบด้วยข้อมูลที่หายไป)
- Sig.: ค่า p ตัวเลขนี้เป็นตัวตัดสินผล
กฎตัดสิน:
- ถ้า Sig. > .05: ข้อมูลไม่เบี่ยงเบนจากการแจกแจงปกติอย่างมีนัยสำคัญ ใช้สถิติพาราเมตริกได้
- ถ้า Sig. < .05: ข้อมูลเบี่ยงเบนจากการแจกแจงปกติอย่างมีนัยสำคัญ ต้องดูเพิ่มเติม (เช็คความรุนแรงจากค่าความเบ้/ความโด่งและ Q-Q plot)
ในผลลัพธ์ตัวอย่าง สังเกตว่า ทั้ง 4 ตัวแปร มีผล Shapiro-Wilk ที่มีนัยสำคัญ (p < .05) ทั้งหมด นี่เป็นสถานการณ์ที่พบบ่อยกับกลุ่มตัวอย่าง 100 คนขึ้นไป และแสดงให้เห็นว่าทำไมไม่ควรพึ่งพาแค่ค่า p อย่างเดียว
ข้อแตกต่างสำคัญคือระหว่าง มีนัยสำคัญทางสถิติ กับ สำคัญในทางปฏิบัติ StudyHours (W = .910, p < .001) ไม่ปกติจริง มีค่าความเบ้ 1.39 และค่าความโด่ง 3.05 แต่ Satisfaction (W = .969, p = .003), GPA (W = .976, p = .014) และ Age (W = .954, p < .001) ทั้งสามตัวมีค่าความเบ้และความโด่งอยู่ในช่วง -1 ถึง +1 Shapiro-Wilk ตรวจพบความเบี่ยงเบนเล็กน้อยที่ไม่มีผลต่อสถิติพาราเมตริก Q-Q plot และค่าความเบ้/ความโด่ง (ที่จะพูดถึงด้านล่าง) ยืนยันเรื่องนี้
สังเกตด้วยว่า K-S บอกอีกเรื่องหนึ่ง: Satisfaction (p = .090) และ GPA (p = .200) ไม่มีนัยสำคัญ ขณะที่ StudyHours (p < .001) และ Age (p < .001) มีนัยสำคัญ ตรงนี้แสดงให้เห็นความแตกต่างของพลังทางสถิติระหว่างสองการทดสอบ K-S ตรวจไม่พบความเบี่ยงเบนเล็กน้อยที่ Shapiro-Wilk ตรวจพบ
ควรรายงานผลทดสอบตัวไหน? ใช้ Shapiro-Wilk เป็นการทดสอบหลัก เพราะมีพลังทางสถิติสูงกว่า (ตรวจพบการเบี่ยงเบนได้ดีกว่า) และแนะนำในตำราสถิติส่วนใหญ่ (Field, 2018; Pallant, 2020) รายงาน K-S ควบคู่ถ้าอาจารย์หรือวารสารต้องการทั้งสอง แต่ให้เสริมการทดสอบด้วยค่าความเบ้/ความโด่งและ Q-Q plot เสมอ อย่างที่ตัวอย่างนี้แสดงให้เห็น
Q-Q Plot
Q-Q plot ปกติ (quantile-quantile) แสดงค่าที่คาดหวังจากการแจกแจงปกติบนแกน X และค่าที่สังเกตได้จากข้อมูลบนแกน Y ถ้าข้อมูลแจกแจงปกติสมบูรณ์ จุดทุกจุดจะเรียงอยู่บนเส้นทแยงมุม
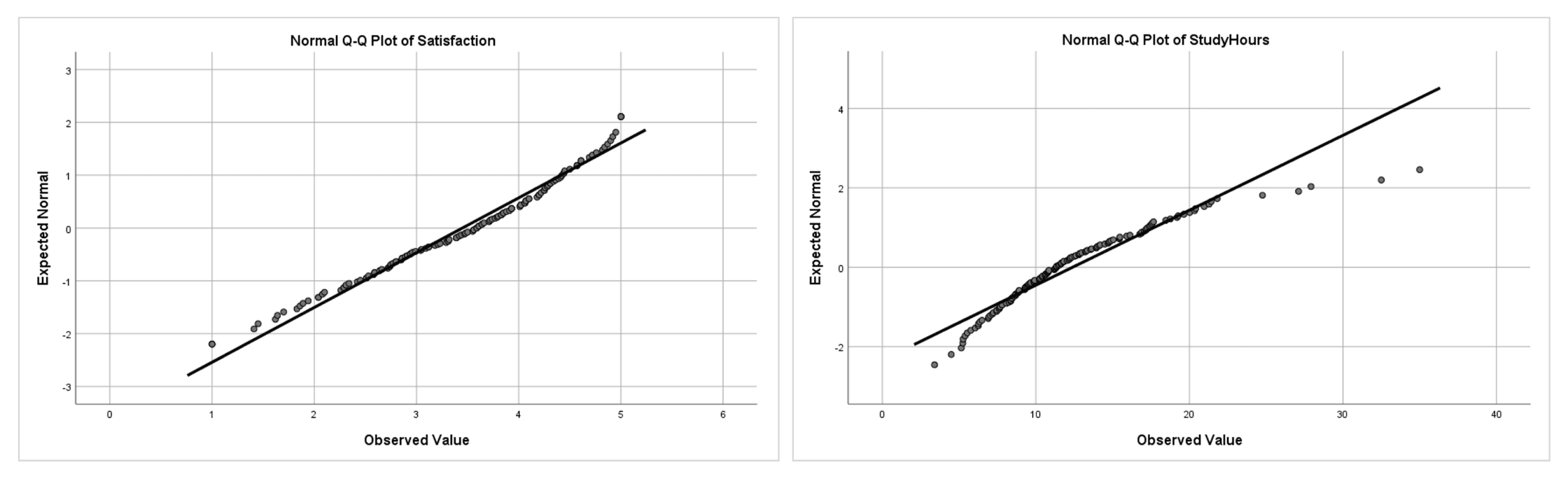
รูปที่ 5: Q-Q plot เปรียบเทียบ: Satisfaction (ซ้าย) จุดเรียงตามเส้นทแยงมุม แสดงการแจกแจงใกล้เคียงปกติ; StudyHours (ขวา) จุดโค้งออกที่ปลายบน แสดงการเบ้ขวา
วิธีอ่าน Q-Q plot:
- จุดอยู่บนหรือใกล้เส้น: ข้อมูลแจกแจงใกล้เคียงปกติ จุดกระจายเล็กน้อยรอบเส้นเป็นเรื่องปกติและยอมรับได้
- โค้งเป็นระบบ (รูป S หรือกล้วย): ข้อมูลเบ้ โค้งขึ้นที่ปลายขวาบ่งชี้เบ้ขวา (เหมือน StudyHours) โค้งลงที่ปลายซ้ายบ่งชี้เบ้ซ้าย
- จุดแยกออกที่ปลายทั้งสอง: หางหนัก (leptokurtic) จุดตกต่ำกว่าเส้นที่ซ้ายและสูงกว่าเส้นที่ขวา
- จุดเดี่ยวที่ห่างจากเส้นมาก: อาจเป็นค่าผิดปกติ ถ้ามีแค่หนึ่งหรือสองจุดที่ปลายสุดเบี่ยงเบนมาก น่าจะเป็นค่าผิดปกติ ไม่ใช่หลักฐานว่าการแจกแจงทั้งหมดไม่ปกติ
Q-Q plot มีประโยชน์มากโดยเฉพาะกับกลุ่มตัวอย่างใหญ่ที่ Shapiro-Wilk อาจไวเกินไป ถ้า Q-Q plot ดูตรงพอสมควร นั่นเป็นหลักฐานแข็งแรงว่าข้อมูลยอมรับได้สำหรับสถิติพาราเมตริก แม้การทดสอบจะได้ค่า p ที่มีนัยสำคัญก็ตาม
ฮิสโตแกรมพร้อมโค้งปกติ
ฮิสโตแกรมแสดงรูปร่างการแจกแจงได้อย่างเข้าใจง่าย SPSS จะวาดโค้งปกติทับบนฮิสโตแกรมเมื่อคุณเลือกผ่าน Explore
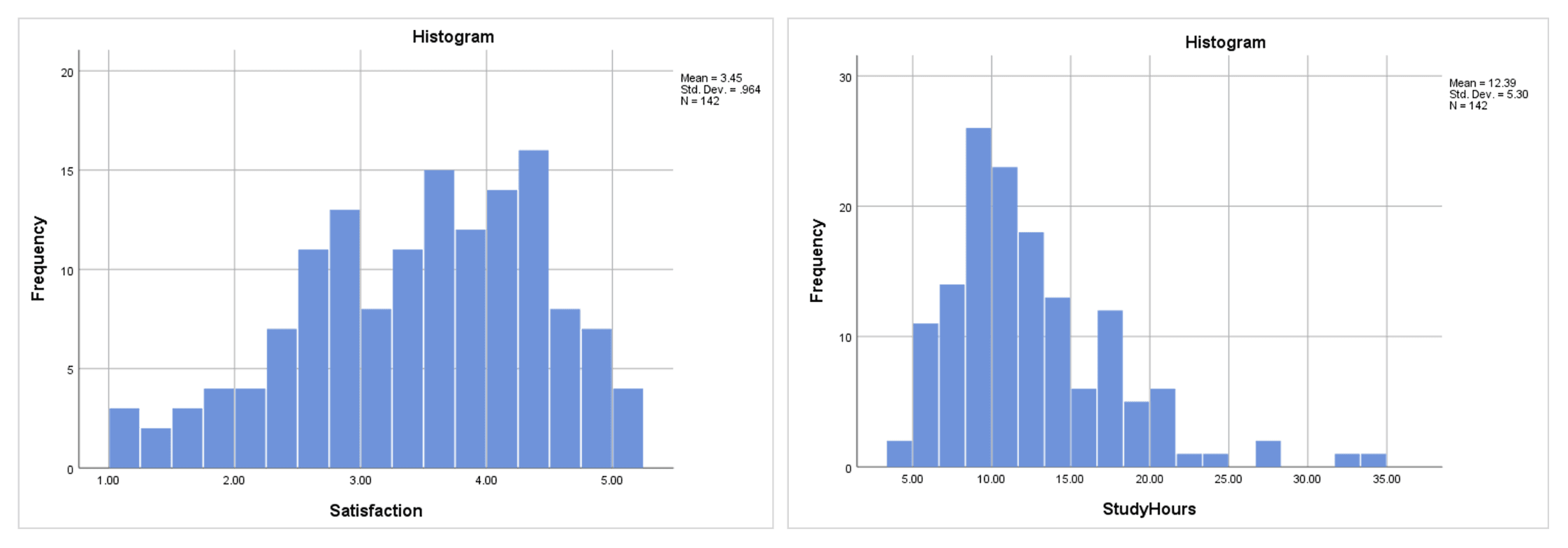
รูปที่ 6: ฮิสโตแกรมเปรียบเทียบ: Satisfaction (ซ้าย) แจกแจงค่อนข้างสมมาตร; StudyHours (ขวา) เบ้ขวาชัดเจน มีหางยาว
ฮิสโตแกรมเหมาะกับการคัดกรองเบื้องต้น ไม่ใช่สำหรับการประเมินอย่างเป็นทางการ ความกว้างของแท่ง (จำนวนแท่ง) ส่งผลต่อรูปร่างที่เห็น และกับกลุ่มตัวอย่างเล็กรูปร่างอาจดูไม่สม่ำเสมอแม้การแจกแจงจริงจะปกติ ใช้ฮิสโตแกรมควบคู่กับ Q-Q plot และการทดสอบ ไม่ใช่เป็นวิธีเดียว
ค่าความเบ้และความโด่ง
Explore แสดงค่าความเบ้ (skewness) และความโด่ง (kurtosis) ในตาราง Descriptives (ตารางเดียวกับที่มีค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐาน) ถ้าคุณรันสถิติเชิงพรรณนาไปแล้ว คุณก็มีค่าเหล่านี้จากผลลัพธ์ก่อนหน้า
| ตัวแปร | ค่าความเบ้ (SE) | ค่าความโด่ง (SE) | การตีความ |
|---|---|---|---|
| Satisfaction | -0.477 (0.203) | -0.409 (0.404) | อยู่ในช่วง +/-1: ใกล้เคียงปกติ |
| StudyHours | 1.392 (0.203) | 3.053 (0.404) | ค่าความเบ้ > 1: เบ้ขวา; ค่าความโด่ง > 2: หางหนัก |
| GPA | -0.161 (0.203) | -0.718 (0.404) | อยู่ในช่วง +/-1: ใกล้เคียงปกติ |
| Age | 0.415 (0.203) | -0.500 (0.404) | อยู่ในช่วง +/-1: ใกล้เคียงปกติ |
ตารางที่ 2: ค่าความเบ้และความโด่งจากผลลัพธ์ Explore
เกณฑ์ตีความ:
| ช่วง | ตีความค่าความเบ้ | ตีความค่าความโด่ง | สิ่งที่ควรทำ |
|---|---|---|---|
| -1 ถึง +1 | ค่อนข้างสมมาตร | หางใกล้เคียงปกติ | ใช้สถิติพาราเมตริกได้ |
| -2 ถึง -1 หรือ +1 ถึง +2 | เบ้ปานกลาง | หางเบี่ยงเบนปานกลาง | มักยอมรับได้ โดยเฉพาะกับ n > 30 |
| เกิน +/-2 | เบ้มาก | หางเบี่ยงเบนมาก | พิจารณาสถิตินอนพาราเมตริกหรือการแปลงข้อมูล |
ตารางที่ 3: เกณฑ์ตีความค่าความเบ้และความโด่งสำหรับประเมินการแจกแจงปกติ
เกณฑ์เหล่านี้เป็นแนวปฏิบัติ ไม่ใช่กฎตายตัว แหล่งอ้างอิงต่าง ๆ แนะนำค่าต่างกัน George และ Mallery (2019) ใช้ +/-1 สำหรับ "ดีเยี่ยม" และ +/-2 สำหรับ "ยอมรับได้" Hair et al. (2019) ถือว่าค่าเกิน +/-1.96 มีนัยสำคัญที่ระดับ .05 สำหรับกลุ่มตัวอย่างเกิน 50 คน สิ่งสำคัญคือระบุในวิทยานิพนธ์ว่าใช้เกณฑ์อะไร แล้วใช้ให้สม่ำเสมอกับทุกตัวแปร
เมื่อการแจกแจงปกติไม่ผ่าน ทำอย่างไร
เมื่อตัวแปรหนึ่งตัวหรือมากกว่าไม่ผ่านการทดสอบ คุณมีสามทางเลือก ทางที่ดีที่สุดขึ้นอยู่กับว่าการแจกแจงเบี่ยงเบนรุนแรงแค่ไหนและจะรันการวิเคราะห์อะไร
ทางเลือกที่ 1: ใช้สถิตินอนพาราเมตริก
สถิตินอนพาราเมตริกไม่มีข้อสมมติเรื่องการแจกแจงปกติ เป็นทางออกที่ตรงที่สุดเมื่อการละเมิดรุนแรง
| สถิติพาราเมตริก | ทางเลือกนอนพาราเมตริก | เมื่อไหร่ควรเปลี่ยน |
|---|---|---|
| t-test กลุ่มอิสระ | Mann-Whitney U | เบ้รุนแรงหรือกลุ่มตัวอย่างเล็กที่ข้อมูลไม่ปกติ |
| t-test กลุ่มคู่ | Wilcoxon signed-rank | เบ้รุนแรงในคะแนนผลต่าง |
| ANOVA แบบทางเดียว | Kruskal-Wallis H | เบ้รุนแรงในกลุ่มใดกลุ่มหนึ่งหรือมากกว่า |
| สหสัมพันธ์ Pearson | สหสัมพันธ์ Spearman แบบอันดับ | ความสัมพันธ์ไม่เป็นเส้นตรงหรือข้อมูลเรียงลำดับ |
ตารางที่ 4: สถิติพาราเมตริกและทางเลือกนอนพาราเมตริก
ทางเลือกที่ 2: แปลงข้อมูล
การแปลงข้อมูล (data transformation) ช่วยลดค่าความเบ้และทำให้ตัวแปรเข้าใกล้การแจกแจงปกติมากขึ้น วิธีที่ใช้บ่อยใน SPSS:
สำหรับข้อมูลเบ้ขวา (ค่าความเบ้เป็นบวก):
- แปลง log: Transform > Compute Variable >
LN(ตัวแปร)เหมาะกับค่าความเบ้ปานกลางถึงมาก - แปลงรากที่สอง: Transform > Compute Variable >
SQRT(ตัวแปร)แก้ได้เบากว่า log
สำหรับข้อมูลเบ้ซ้าย (ค่าความเบ้เป็นลบ):
- กลับค่าแล้วแปลง log: Transform > Compute Variable >
LN(K - ตัวแปร)โดยที่ K คือค่าสูงสุดบวก 1
หลังจากแปลงแล้ว ให้รันการทดสอบการแจกแจงปกติกับตัวแปรที่แปลงแล้วอีกรอบ ถ้าผ่าน ให้ใช้ตัวแปรที่แปลงแล้วในการวิเคราะห์ รายงานทั้งสถิติเชิงพรรณนาจากข้อมูลดิบ (เพื่อให้ตีความได้) และระบุว่าใช้ตัวแปรที่แปลงแล้วในสถิติเชิงอนุมาน
ข้อเสียของการแปลงข้อมูลคือการตีความจะยากขึ้น คะแนนความพึงพอใจที่แปลง log แล้วไม่มีความหมายเหมือนสเกลดั้งเดิม
ทางเลือกที่ 3: รันสถิติพาราเมตริกต่อ (พร้อมเหตุผลรองรับ)
ถ้าการละเมิดเล็กน้อยหรือปานกลาง คุณสามารถรันสถิติพาราเมตริกต่อแล้วให้เหตุผลรองรับ แนวทางนี้ได้รับการสนับสนุนจากงานวิจัยที่แสดงว่า t-test และ ANOVA ทนทานต่อการเบี่ยงเบนจากปกติเมื่อกลุ่มตัวอย่างเกิน 30 คน (Schmider et al., 2010)
เหตุผลรองรับในวิทยานิพนธ์ควรมี:
- ค่าความเบ้/ความโด่งที่ระบุ (แสดงว่าการละเมิดปานกลาง)
- ขนาดกลุ่มตัวอย่าง (กลุ่มตัวอย่างใหญ่ทำให้สถิติพาราเมตริกทนทานมากขึ้น)
- เอกสารอ้างอิงที่สนับสนุนเรื่องความทนทาน (เช่น Field, 2018; Glass et al., 1972)
- หลักฐานจากตา (Q-Q plot แสดงว่าเบี่ยงเบนเล็กน้อย)
นี่มักเป็นแนวทางที่ใช้ได้จริงที่สุดสำหรับวิทยานิพนธ์ ในตัวอย่างของเรา Satisfaction มีค่าความเบ้ -0.48 และ Shapiro-Wilk มีนัยสำคัญ (p = .003) แต่ค่าความเบ้อยู่ในช่วง -1 ถึง +1 และ Q-Q plot ยืนยันว่าแจกแจงใกล้เคียงปกติ แม้แต่ StudyHours ที่มีค่าความเบ้ 1.39 ก็ไม่ได้ทำให้ t-test เป็นโมฆะเสมอไปเมื่อมี 142 คน แต่ค่าความโด่ง 3.05 ต้องระวังมากขึ้น
การรายงานการแจกแจงปกติในรูปแบบ APA
รายงานในเนื้อหา
เมื่อ Shapiro-Wilk มีนัยสำคัญแต่ค่าความเบ้/ความโด่งยอมรับได้:
Normalitatea a fost evaluata folosind testul Shapiro-Wilk, inspectia vizuala a graficelor Q-Q si valorile de asimetrie/boltire. Normality was assessed using the Shapiro-Wilk test, visual inspection of Q-Q plots, and skewness/kurtosis values. Although the Shapiro-Wilk test was significant for Satisfaction, W(142) = .969, p = .003, skewness (-0.48, SE = 0.20) and kurtosis (-0.41, SE = 0.40) fell within the -1 to +1 range, and the Q-Q plot showed no systematic deviations from the diagonal. Given the sensitivity of the Shapiro-Wilk test in samples exceeding 100 and the robustness of parametric tests to minor normality violations (Schmider et al., 2010), parametric analysis was retained.
เมื่อรายงานหลายตัวแปรที่มีค่าความเบ้/ความโด่งยอมรับได้:
Shapiro-Wilk tests were significant for Satisfaction (W = .969, p = .003), GPA (W = .976, p = .014), and Age (W = .954, p < .001). However, skewness and kurtosis values for all three variables fell within the acceptable range of -1 to +1 (see Table X), and Q-Q plots indicated approximate normality. These results are consistent with the known sensitivity of the Shapiro-Wilk test in samples exceeding 100 cases (Field, 2018).
เมื่อการแจกแจงปกติถูกละเมิดจริง:
The Shapiro-Wilk test indicated that StudyHours was not normally distributed, W(142) = .910, p < .001, with a skewness of 1.39 (SE = 0.20) and kurtosis of 3.05 (SE = 0.40). Visual inspection of the Q-Q plot confirmed right skewness, with data points curving away from the diagonal at the upper end. Consequently, the Mann-Whitney U test was used instead of the independent samples t-test for group comparisons involving this variable.
เมื่อรันต่อแม้มีการละเมิดปานกลาง:
Although the Shapiro-Wilk test was significant for StudyHours, W(142) = .910, p < .001, the skewness (1.39) fell within the -2 to +2 range that Hair et al. (2019) consider acceptable. Given the sample size (N = 142) and the known robustness of the independent samples t-test to moderate normality violations (Schmider et al., 2010), parametric analysis was retained.
ตารางสรุป APA สำหรับการแจกแจงปกติ
| ตัวแปร | W | p | ค่าความเบ้ (SE) | ค่าความโด่ง (SE) | การตัดสินใจ |
|---|---|---|---|---|---|
| Satisfaction | .969 | .003 | -0.48 (0.20) | -0.41 (0.40) | ยอมรับได้ (ค่าความเบ้/ความโด่งอยู่ใน +/-1) |
| StudyHours | .910 | < .001 | 1.39 (0.20) | 3.05 (0.40) | ไม่ปกติ (ค่าความเบ้ > 1, ค่าความโด่ง > 2) |
| GPA | .976 | .014 | -0.16 (0.20) | -0.72 (0.40) | ยอมรับได้ (ค่าความเบ้/ความโด่งอยู่ใน +/-1) |
| Age | .954 | < .001 | 0.42 (0.20) | -0.50 (0.40) | ยอมรับได้ (ค่าความเบ้/ความโด่งอยู่ใน +/-1) |
ตารางที่ 5: สรุปผลการประเมินการแจกแจงปกติจาก Explore
ตารางนี้แสดงสถานการณ์จริงที่พบบ่อย: Shapiro-Wilk มีนัยสำคัญทั้งหมด แต่มีแค่ StudyHours ที่มีค่าความเบ้และความโด่งบ่งชี้ปัญหาจริง สำหรับอีกสามตัวแปร คอลัมน์ "การตัดสินใจ" สะท้อนการประเมินในทางปฏิบัติจากเกณฑ์ค่าความเบ้/ความโด่งและการดู Q-Q plot ไม่ใช่แค่จากค่า p ของ Shapiro-Wilk
ข้อผิดพลาดที่พบบ่อยในการทดสอบการแจกแจงปกติ
1. พึ่งพาแค่ค่า p ของ Shapiro-Wilk
อย่างที่ตัวอย่างในคู่มือนี้แสดงให้เห็น ทั้ง 4 ตัวแปรได้ผล Shapiro-Wilk ที่มีนัยสำคัญ แต่มีแค่ StudyHours ที่มีปัญหาจริง ให้เสริมการทดสอบด้วย Q-Q plot และค่าความเบ้/ความโด่งเสมอ
2. ทดสอบผิดอย่าง
สำหรับ regression ข้อสมมติการแจกแจงปกติใช้กับค่าคงเหลือ (residuals) ไม่ใช่ตัวแปรดิบ สำหรับ t-test และ ANOVA ใช้กับข้อมูลภายในแต่ละกลุ่ม การรันการทดสอบกับตัวแปรทั้งหมดรวมกันโดยไม่ดูบริบทการวิเคราะห์อาจให้ผลที่ทำให้เข้าใจผิด ทดสอบในระดับที่ตรงกับการวิเคราะห์ที่จะทำ
3. ใช้ Kolmogorov-Smirnov เป็นการทดสอบหลัก
ตำราเก่าและบทความออนไลน์หลายแห่งแนะนำ K-S เป็นค่าเริ่มต้น แต่ K-S มีพลังทางสถิติต่ำกว่า Shapiro-Wilk มาก ซึ่งหมายความว่ามีโอกาสมากกว่าที่จะพลาดการเบี่ยงเบนจริง (type II error) ใช้ Shapiro-Wilk เป็นหลัก ยกเว้นอาจารย์ขอ K-S โดยเฉพาะ
4. ไม่ดูหลักฐานจากตา
นักศึกษาบางคนรายงานว่า "Shapiro-Wilk ไม่มีนัยสำคัญ ดังนั้นสมมติว่าแจกแจงปกติ" โดยไม่ได้ดูการแจกแจงจริง ผลไม่มีนัยสำคัญจากกลุ่มตัวอย่างเล็กอาจหมายแค่ว่าการทดสอบมีพลังไม่พอ ให้ดู Q-Q plot และฮิสโตแกรมทุกครั้ง ถ้าวิธีดูด้วยตาพบปัญหาชัดเจน (โค้งมาก, bimodal, ค่าผิดปกติสุดขั้ว) ให้ตรวจสอบเพิ่มเติมไม่ว่าค่า p จะเป็นเท่าไหร่
5. ใช้เกณฑ์ตัวเดียวกับทุกกรณี
การใช้ +/-2 สำหรับค่าความเบ้เป็นเกณฑ์ตายตัวโดยไม่ดูขนาดกลุ่มตัวอย่างหรือการวิเคราะห์เป็นเรื่องเข้มงวดเกินไป กับกลุ่มตัวอย่าง 15 คน แม้ค่าความเบ้ 1.5 ก็อาจเป็นปัญหา กับกลุ่มตัวอย่าง 500 คน ค่าความเบ้ 1.5 อาจไม่ส่งผลต่อ t-test เลย รายงานค่าและให้เหตุผลตามบริบท
6. ลืมทดสอบแยกตามกลุ่ม
เมื่อเปรียบเทียบกลุ่ม (t-test กลุ่มอิสระ, ANOVA แบบทางเดียว) ข้อสมมติการแจกแจงปกติใช้กับข้อมูลภายในแต่ละกลุ่ม การทดสอบตัวแปรรวมทั้งหมด (ไม่แยกกลุ่ม) อาจได้ผลที่ทำให้เข้าใจผิด สองกลุ่มที่ไม่ปกติอาจรวมกันแล้วดูปกติ และในทางกลับกัน ใช้ Factor List ใน Explore เพื่อทดสอบแยกกลุ่ม
7. แปลงข้อมูลแล้วไม่เช็คอีกรอบ
หลังจากแปลง log หรือรากที่สอง นักศึกษาบางคนรันการวิเคราะห์ต่อเลยโดยไม่เช็คว่าการแปลงได้ผลจริงไหม ให้รันการทดสอบการแจกแจงปกติกับตัวแปรที่แปลงแล้วอีกครั้ง ถ้าการแปลงไม่ทำให้เข้าใกล้ปกติ สถิตินอนพาราเมตริกอาจเหมาะกว่าการแปลงซ้ำหลายรอบ
คำถามที่อาจารย์ที่ปรึกษาจะถาม
"ประเมินการแจกแจงปกติอย่างไร?" คำตอบที่แข็งแรงที่สุดแสดงว่าใช้หลายวิธี: "ประเมินการแจกแจงปกติด้วย Shapiro-Wilk, การดู Q-Q plot และค่าความเบ้/ความโด่ง Shapiro-Wilk ไม่มีนัยสำคัญสำหรับทุกตัวแปร Q-Q plot ไม่แสดงความเบี่ยงเบนอย่างเป็นระบบจากเส้นทแยงมุม และค่าความเบ้กับความโด่งอยู่ในช่วง -1 ถึง +1" สิ่งนี้แสดงให้เห็นความรอบคอบ ไม่ใช่แค่พึ่งตัวชี้วัดเดียว
"ทำไมใช้ Shapiro-Wilk ไม่ใช่ Kolmogorov-Smirnov?" อธิบายว่า Shapiro-Wilk มีพลังทางสถิติสูงกว่า ซึ่งหมายความว่าตรวจพบการเบี่ยงเบนจากปกติได้ดีกว่า Field (2018) และ Razali และ Wah (2011) แนะนำเป็นการทดสอบหลักสำหรับกลุ่มตัวอย่างไม่เกิน 2,000 SPSS รันทั้งสองพร้อมกัน จึงรายงาน K-S ควบคู่ได้ถ้าอาจารย์ต้องการ
"Shapiro-Wilk มีนัยสำคัญ ทำไมยังใช้สถิติพาราเมตริก?" คำถามนี้เจอบ่อย ให้อ้างค่าความเบ้และความโด่งเฉพาะ อ้างอิงเอกสารเรื่องความทนทาน (Schmider et al., 2010) ชี้ให้ดู Q-Q plot และระบุขนาดกลุ่มตัวอย่าง คำตอบที่เตรียมมาดีจะครอบคลุมทั้งหลักฐานทางสถิติและเหตุผลทางวิธีวิจัย
"ถ้าการแจกแจงปกติถูกละเมิดรุนแรง จะทำอย่างไร?" แสดงว่าได้พิจารณาทางเลือกไว้แล้ว: "ถ้าค่าความเบ้เกิน +/-2 หรือ Q-Q plot โค้งอย่างเป็นระบบ จะแปลงข้อมูล (log หรือรากที่สอง) แล้วทดสอบการแจกแจงปกติอีกรอบ ถ้าการแปลงไม่สำเร็จ จะใช้สถิตินอนพาราเมตริก เช่น Mann-Whitney U แทน t-test กลุ่มอิสระ"
"ต้องทดสอบแยกตามกลุ่มไหม?" สำหรับการวิเคราะห์ที่เปรียบเทียบกลุ่ม (t-test, ANOVA) คำตอบคือต้อง อธิบายว่าใช้ Factor List ใน Explore เพื่อสร้างผลทดสอบแยกกลุ่ม สิ่งนี้แสดงว่าเข้าใจว่าข้อสมมติการแจกแจงปกติใช้กับข้อมูลภายในกลุ่ม ไม่ใช่ภาพรวม
คำถามที่พบบ่อย
ขั้นตอนถัดไปหลังทดสอบการแจกแจงปกติ
หลังจากประเมินการแจกแจงปกติแล้ว ขั้นตอนถัดไปขึ้นอยู่กับผลที่ได้:
ถ้าทุกตัวแปรผ่านการทดสอบ ให้รันสถิติพาราเมตริกที่เหมาะกับแบบแผนการวิจัย สำหรับเปรียบเทียบค่าเฉลี่ยสองกลุ่ม ให้รัน t-test กลุ่มอิสระหรือกลุ่มคู่ สำหรับสามกลุ่มขึ้นไป ให้รัน ANOVA แบบทางเดียวหรือ ANOVA แบบวัดซ้ำ สำหรับความสัมพันธ์ระหว่างตัวแปรต่อเนื่อง ให้รัน Pearson หรือregression เชิงเส้น
ถ้าตัวแปรหนึ่งตัวหรือมากกว่าไม่ผ่านและมีค่าความเบ้เกิน +/-2 ให้พิจารณาสามทางเลือกที่กล่าวข้างต้น: สถิตินอนพาราเมตริก, การแปลงข้อมูล หรือรันต่อพร้อมเหตุผลรองรับ ทางเลือกที่ดีที่สุดขึ้นอยู่กับความรุนแรงของการละเมิด ขนาดกลุ่มตัวอย่าง และสิ่งที่อาจารย์คาดหวัง
ถ้ายังไม่ได้เช็คความเชื่อมั่นของแบบสอบถาม ให้ทำก่อนรันสถิติเชิงอนุมาน ดูคู่มือค่าสัมประสิทธิ์แอลฟาของครอนบาคใน SPSS ของเรานะ
ไม่ว่าผลการทดสอบจะเป็นอย่างไร ให้เขียนรายละเอียดการประเมินการแจกแจงปกติให้ครบถ้วน ส่วนนี้ที่เขียนดีจะแสดงให้อาจารย์เห็นว่าคุณเข้าใจข้อสมมติเบื้องหลังสถิติที่เลือก ไม่ใช่แค่รู้วิธีกดปุ่มรัน
เอกสารอ้างอิง
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). American Psychological Association.
Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). SAGE Publications.
George, D., & Mallery, P. (2019). IBM SPSS statistics 26 step by step: A simple guide and reference (16th ed.). Routledge.
Glass, G. V., Peckham, P. D., & Sanders, J. R. (1972). Consequences of failure to meet assumptions underlying the fixed effects analyses of variance and covariance. Review of Educational Research, 42(3), 237-288.
Hair, J. F., Babin, B. J., Anderson, R. E., & Black, W. C. (2019). Multivariate data analysis (8th ed.). Cengage Learning.
Pallant, J. (2020). SPSS survival manual (7th ed.). Open University Press.
Razali, N. M., & Wah, Y. B. (2011). Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests. Journal of Statistical Modeling and Analytics, 2(1), 21-33.
Schmider, E., Ziegler, M., Danay, E., Beyer, L., & Buhner, M. (2010). Is it really robust? Reinvestigating the robustness of ANOVA against violations of the normal distribution assumption. Methodology, 6(4), 147-151.
Tabachnick, B. G., & Fidell, L. S. (2019). Using multivariate statistics (7th ed.). Pearson.