Independent samples t-test เป็นสถิติทดสอบที่ใช้บ่อยมากในวิทยานิพนธ์ มันตอบคำถามตรงไปตรงมา: สองกลุ่มต่างกันในตัวแปรต่อเนื่องหรือเปล่า? ไม่ว่าจะเปรียบเทียบคะแนนความพึงพอใจระหว่างชายกับหญิง คะแนนสอบระหว่างกลุ่มทดลองกับกลุ่มควบคุม หรือตัวชี้วัดผลงานระหว่างสองแผนก independent samples t-test คือวิธีมาตรฐาน
คู่มือนี้ครอบคลุมทุกขั้นตอนใน SPSS: เช็คข้อสมมติ, รันการทดสอบ, อ่านตารางผลลัพธ์, คำนวณ Cohen's d (ที่ SPSS ไม่ได้คำนวณให้), จัดการเมื่อข้อสมมติไม่ผ่าน และรายงานผลในรูปแบบ APA ฉบับที่ 7 คู่มือนี้ใช้ชุดข้อมูลเดียวกันกับคู่มือก่อนหน้าในซีรีส์นี้ ถ้าคุณทำสถิติเชิงพรรณนาหรือทดสอบการแจกแจงปกติมาแล้ว ตัวแปรและโครงสร้างข้อมูลจะคุ้นเคย
สรุป:
- Independent samples t-test เปรียบเทียบค่าเฉลี่ยของ สองกลุ่มที่แยกจากกัน บนตัวแปรตามแบบต่อเนื่อง
- ต้องเช็ค สี่ข้อสมมติ ก่อนตีความผล: ความเป็นอิสระ, ตัวแปรตามต่อเนื่อง, การแจกแจงปกติ (แยกตามกลุ่ม) และความเป็นเอกพันธ์ของความแปรปรวน (ทดสอบ Levene)
- ถ้า ทดสอบ Levene มีนัยสำคัญ (p < .05) ให้อ่านผลจากแถว "Equal variances not assumed" ที่ใช้การปรับแก้แบบ Welch
- SPSS ไม่ได้คำนวณ Cohen's d ให้อัตโนมัติ ต้องคำนวณเองจากตาราง Group Statistics โดยใช้สูตร: d = (M1 - M2) / SD รวม
- รายงาน ค่า t, องศาอิสระ, ค่า p, ค่าเฉลี่ย, ส่วนเบี่ยงเบนมาตรฐาน และขนาดอิทธิพล ในบทผลการวิจัย
ก่อนเริ่ม: คู่มือนี้สมมติว่าคุณโหลดข้อมูลใน SPSS แล้ว พร้อมตั้งค่าตัวแปรใน Variable View เรียบร้อย และเช็คการแจกแจงปกติของตัวแปรตามแยกตามกลุ่มแล้ว ถ้ายังไม่ได้ทำ ดูคู่มือทดสอบการแจกแจงปกติใน SPSS ก่อนนะ
เมื่อไหร่ควรใช้ Independent Samples T-Test
Independent samples t-test เหมาะเมื่อการวิจัยของคุณมีเงื่อนไขเหล่านี้:
- มี ตัวแปรตามแบบต่อเนื่องหนึ่งตัว (เช่น ความพึงพอใจ, คะแนนสอบ, รายได้)
- มี ตัวแปรต้นแบบจัดกลุ่มที่มีสองกลุ่มพอดี (เช่น เพศ, กลุ่มทดลอง/กลุ่มควบคุม, ผ่าน/ไม่ผ่าน)
- ข้อมูลในแต่ละกลุ่มมาจาก คนละคนกัน (ไม่มีใครอยู่ทั้งสองกลุ่ม)
ถ้ามีตั้งแต่สามกลุ่มขึ้นไป ให้ใช้ ANOVA แทน ถ้าวัดคนเดียวกันสองครั้ง (ก่อนเรียน vs. หลังเรียน) ให้ใช้ paired samples t-test
ตัวอย่างที่พบบ่อยในวิทยานิพนธ์:
| คำถามวิจัย | ตัวแปรตาม | ตัวแปรจัดกลุ่ม |
|---|---|---|
| นักศึกษาชายและหญิงมีความพึงพอใจต่างกันไหม? | ความพึงพอใจ (ต่อเนื่อง) | เพศ (ชาย/หญิง) |
| โปรแกรมฝึกอบรมช่วยให้คะแนนสอบดีขึ้นไหม? | คะแนนสอบ (ต่อเนื่อง) | กลุ่ม (ทดลอง/ควบคุม) |
| ผู้ตอบแบบสอบถามในเมืองกับชนบทมีรายได้ต่างกันไหม? | รายได้ต่อเดือน (ต่อเนื่อง) | พื้นที่ (เมือง/ชนบท) |
ตารางที่ 1: ตัวอย่างงานวิจัยที่เหมาะกับ independent samples t-test
ข้อสมมติ
Independent samples t-test มีสี่ข้อสมมติ ถ้าข้อสมมติไม่ผ่านไม่ได้แปลว่าผลไม่ถูกต้องทันที แต่คุณต้องเช็คทุกข้อและบันทึกว่าเจออะไรบ้าง
1. ความเป็นอิสระของข้อมูล
ผู้ตอบแต่ละคนต้องอยู่ในกลุ่มเดียวเท่านั้น นักศึกษาคนหนึ่งจะอยู่ทั้งกลุ่ม "ชาย" และ "หญิง" พร้อมกันไม่ได้ ข้อสมมตินี้เป็นเรื่องของการออกแบบวิจัย ไม่ได้ทดสอบทางสถิติ ถ้าข้อมูลมีการวัดซ้ำจากคนเดิม ต้องใช้ paired samples t-test หรือ repeated measures แทน
2. ตัวแปรตามเป็นข้อมูลต่อเนื่อง
ตัวแปรตามต้องวัดในระดับ interval หรือ ratio คะแนนความพึงพอใจบนสเกล Likert 1 ถึง 5 มักถูกปฏิบัติเหมือนข้อมูลต่อเนื่องในงานวิจัยสังคมศาสตร์ แม้ว่าจะเป็นประเด็นถกเถียงอยู่ ข้อมูลอันดับที่มีหมวดน้อย (เช่น สเกลเห็นด้วย 1-3) เหมาะกับ Mann-Whitney U มากกว่า
3. การแจกแจงปกติภายในแต่ละกลุ่ม
ตัวแปรตามควรแจกแจงใกล้เคียงปกติภายในแต่ละกลุ่ม ไม่ใช่รวมทั้งหมด จุดนี้สำคัญมาก สองกลุ่มอาจแจกแจงไม่ปกติทั้งคู่ แต่พอรวมกันแล้วดูเหมือนปกติ หรือกลับกันก็ได้
วิธีทดสอบคือใช้ Explore แล้วใส่ตัวแปรจัดกลุ่มใน Factor List คู่มือทดสอบการแจกแจงปกติที่ลิงก์ไว้ข้างบนอธิบายรายละเอียดเรื่องนี้ รวมถึงวิธีใช้ Factor List เพื่อแยกตามกลุ่ม
t-test ทนทานต่อการละเมิดการแจกแจงปกติปานกลางเมื่อแต่ละกลุ่มมี 30 คนขึ้นไป (Schmider et al., 2010) ถ้ากลุ่มเล็กกว่านั้น ให้ดู Q-Q plot อย่างละเอียด และพิจารณา Mann-Whitney U ถ้าความเบี่ยงเบนรุนแรง
4. ความเป็นเอกพันธ์ของความแปรปรวน (ทดสอบ Levene)
สองกลุ่มควรมีความแปรปรวน (การกระจายของคะแนน) ใกล้เคียงกัน SPSS ทดสอบให้อัตโนมัติด้วยทดสอบ Levene ซึ่งอยู่ในผลลัพธ์ t-test เลย ไม่ต้องรันแยก
ถ้าทดสอบ Levene ไม่มีนัยสำคัญ (p > .05): ความแปรปรวนใกล้เคียงกัน อ่านผลจากแถว "Equal variances assumed"
ถ้าทดสอบ Levene มีนัยสำคัญ (p < .05): ความแปรปรวนไม่เท่ากัน อ่านผลจากแถว "Equal variances not assumed" ที่ใช้การปรับแก้แบบ Welch เพื่อปรับองศาอิสระและค่า p ไม่ใช่เรื่องร้ายแรงนะ Welch's t-test จัดการความแปรปรวนไม่เท่ากันได้ดี และนักระเบียบวิธีวิจัยบางท่านแนะนำให้รายงาน Welch เป็นค่าเริ่มต้นเลย (Delacre et al., 2017)
ชุดข้อมูลตัวอย่าง
คู่มือนี้ใช้ชุดข้อมูลเดียวกันกับคู่มือสถิติเชิงพรรณนาและการแจกแจงปกติ ดาวน์โหลดได้จากแถบด้านข้าง คำถามวิจัยสำหรับการวิเคราะห์นี้:
นักศึกษาชายและหญิงมีคะแนนความพึงพอใจต่างกันไหม?
- ตัวแปรตาม: Satisfaction (ต่อเนื่อง, Scale, 1.00 ถึง 5.00)
- ตัวแปรจัดกลุ่ม: Gender (นามบัญญัติ, 1 = ชาย, 2 = หญิง)
- กลุ่มตัวอย่าง: 147 คน (ชาย 61 คน, หญิง 86 คน)
จากคู่มือการแจกแจงปกติ เรารู้ว่า Satisfaction มีค่าความเบ้ -0.48 และความโด่ง -0.41 (ทั้งคู่อยู่ในช่วง -1 ถึง +1) ทดสอบ Shapiro-Wilk มีนัยสำคัญ (p = .003) เพราะขนาดกลุ่มตัวอย่าง แต่ความเบี่ยงเบนจริงเล็กน้อยมาก ข้อมูลเหมาะสมสำหรับสถิติพาราเมตริก
ทีละขั้นตอน: รัน Independent Samples T-Test
ขั้นตอนที่ 1: เปิดหน้าต่าง T-Test
ไปที่ Analyze > Compare Means > Independent-Samples T Test
รูปที่ 1: ไปที่ Analyze > Compare Means > Independent-Samples T Test
ขั้นตอนที่ 2: ตั้งค่าตัวแปร
ในหน้าต่าง Independent-Samples T Test:
- ย้าย Satisfaction ไปในช่อง Test Variable(s) นี่คือตัวแปรตาม คุณสามารถใส่ตัวแปรหลายตัวเพื่อรัน t-test หลายตัวพร้อมกัน แต่ทุกตัวจะทดสอบกับตัวแปรจัดกลุ่มเดียวกัน
- ย้าย Gender ไปในช่อง Grouping Variable จะเห็น "Gender(? ?)" ซึ่งหมายความว่า SPSS ต้องให้คุณกำหนดว่าค่าไหนเป็นกลุ่มไหน
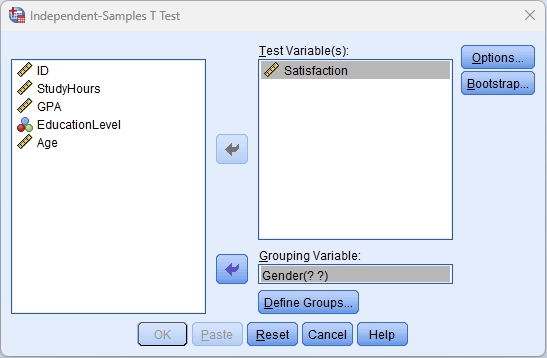
รูปที่ 2: หน้าต่าง Independent-Samples T Test พร้อม Satisfaction เป็นตัวแปรทดสอบ และ Gender เป็นตัวแปรจัดกลุ่ม
ขั้นตอนที่ 3: กำหนดกลุ่ม
กดปุ่ม Define Groups แล้วใส่ค่าที่เป็นตัวแทนของสองกลุ่ม:
- Group 1: 1 (ชาย)
- Group 2: 2 (หญิง)
ค่าเหล่านี้ต้องตรงกับรหัสในข้อมูล ถ้าไม่แน่ใจให้เช็คใน Variable View ว่าตัวเลขไหนหมายถึงหมวดไหน
กด Continue เพื่อกลับไปหน้าต่างหลัก
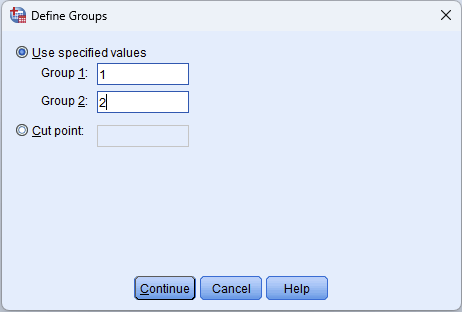
รูปที่ 3: หน้าต่าง Define Groups: Group 1 = 1 (ชาย), Group 2 = 2 (หญิง)
ขั้นตอนที่ 4: รันการทดสอบ
กด OK SPSS จะสร้างตารางผลลัพธ์สองตาราง: Group Statistics และ Independent Samples Test
อ่านผลลัพธ์
ตาราง Group Statistics
ตารางนี้แสดงสถิติเชิงพรรณนาของแต่ละกลุ่มแยกกัน
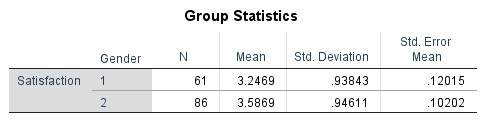
รูปที่ 4: ตาราง Group Statistics พร้อมสถิติเชิงพรรณนาของชายและหญิงบนตัวแปร Satisfaction
ดูอะไรบ้าง:
- N: จำนวนคนในแต่ละกลุ่ม (ชาย 61 คน, หญิง 86 คน) กลุ่มขนาดไม่เท่ากันไม่เป็นปัญหา
- Mean: ค่าเฉลี่ย Satisfaction ของแต่ละกลุ่ม เปรียบเทียบค่านี้เพื่อดูทิศทางของความแตกต่าง
- Std. Deviation: การกระจายของคะแนนภายในแต่ละกลุ่ม ถ้าส่วนเบี่ยงเบนมาตรฐานใกล้เคียงกัน แปลว่าความแปรปรวนน่าจะเท่ากัน ถ้าต่างกันมากอาจมีปัญหาที่ทดสอบ Levene
- Std. Error Mean: ค่าคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยแต่ละกลุ่ม ค่ายิ่งน้อยยิ่งแม่นยำ
ก่อนไปดูผลทดสอบ ให้จดค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานไว้ คุณจะต้องใช้สำหรับรายงาน APA และคำนวณ Cohen's d
ตาราง Independent Samples Test
นี่คือตารางผลลัพธ์หลัก มีทั้งทดสอบ Levene และผล t-test อยู่ในตารางเดียว
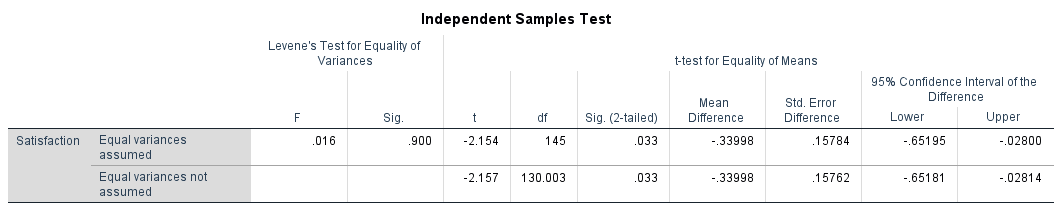
รูปที่ 5: ตาราง Independent Samples Test พร้อมทดสอบ Levene สำหรับความเท่าเทียมของความแปรปรวน และผล t-test
การอ่านตารางมีสองขั้นตอน:
ขั้นตอน A: เช็คทดสอบ Levene (ด้านซ้ายของตาราง)
ดูคอลัมน์ "Levene's Test for Equality of Variances" (F และ Sig.)
- ถ้า Sig. > .05: ความแปรปรวนเท่ากัน อ่าน แถวบน ("Equal variances assumed")
- ถ้า Sig. < .05: ความแปรปรวนไม่เท่ากัน อ่าน แถวล่าง ("Equal variances not assumed")
ขั้นตอน B: อ่านผล t-test (ด้านขวาของตาราง จากแถวที่ถูกต้อง)
- t: ค่าสถิติ t ค่าสัมบูรณ์บอกว่าค่าเฉลี่ยของสองกลุ่มห่างกันกี่เท่าของค่าคลาดเคลื่อนมาตรฐาน
- df: องศาอิสระ สำหรับ equal variances assumed, df = N1 + N2 - 2 สำหรับ Welch's t-test องศาอิสระจะถูกปรับและมักไม่เป็นจำนวนเต็ม
- Sig. (2-tailed): ค่า p ถ้าต่ำกว่าระดับ alpha (ปกติ .05) แปลว่าความแตกต่างระหว่างกลุ่มมีนัยสำคัญทางสถิติ
- Mean Difference: ผลต่างค่าเฉลี่ยดิบระหว่างสองกลุ่ม (M1 - M2)
- Std. Error Difference: ค่าคลาดเคลื่อนมาตรฐานของผลต่างนั้น
- 95% Confidence Interval: ช่วงที่ผลต่างค่าเฉลี่ยจริงของประชากรน่าจะอยู่ ถ้าช่วงนี้มีศูนย์อยู่ด้วย แปลว่าผลต่างไม่มีนัยสำคัญ
รวมผลลัพธ์เข้าด้วยกัน
ในตัวอย่างนี้ ทดสอบ Levene มี F = 0.016, Sig. = .900 (ไม่มีนัยสำคัญ) ความแปรปรวนใกล้เคียงกัน จึงอ่านแถวบน ("Equal variances assumed")
ผล t-test: t(145) = -2.154, p = .033, ผลต่างค่าเฉลี่ย = -0.34
ผลมีนัยสำคัญทางสถิติ หญิง (M = 3.59, SD = 0.95) มีคะแนนความพึงพอใจสูงกว่าชาย (M = 3.25, SD = 0.94) อย่างมีนัยสำคัญ ช่วงความเชื่อมั่น 95% ของผลต่างค่าเฉลี่ย [-0.65, -0.03] ไม่มีศูนย์อยู่ด้วย ยืนยันว่าผลมีนัยสำคัญ
ช่วงความเชื่อมั่นค่อนข้างกว้างเมื่อเทียบกับผลต่างค่าเฉลี่ย บอกว่าการประมาณค่ามีความไม่แน่นอนอยู่บ้าง แต่เราค่อนข้างมั่นใจว่าผลต่างจริงเป็นลบ (หญิงมีคะแนนสูงกว่า) ส่วนว่าผลต่าง 0.34 จุดบนสเกล 5 จุดมีความสำคัญในทางปฏิบัติหรือเปล่า ต้องดู Cohen's d
คำนวณ Cohen's d (ขนาดอิทธิพล)
SPSS ไม่ได้คำนวณ Cohen's d สำหรับ independent samples t-test คุณต้องคำนวณเอง อาจารย์ที่ปรึกษาสมัยนี้คาดหวังให้รายงานขนาดอิทธิพลควบคู่กับค่า p เพราะผลไม่มีนัยสำคัญกับกลุ่มตัวอย่างเล็กไม่ได้หมายความว่าไม่มีผลจริง และผลมีนัยสำคัญกับกลุ่มตัวอย่างใหญ่ไม่ได้หมายความว่าผลนั้นมีความหมายในทางปฏิบัติ
สูตร
โดยส่วนเบี่ยงเบนมาตรฐานรวม (pooled) คือ:
ตัวอย่างการคำนวณ
ใช้ค่าจากตาราง Group Statistics:
- (ชาย) = 3.2469, = 0.93843, = 61
- (หญิง) = 3.5869, = 0.94611, = 86
การตีความ
| Cohen's d | ขนาดอิทธิพล | ความหมายในทางปฏิบัติ |
|---|---|---|
| 0.2 | เล็ก | ความแตกต่างมีอยู่แต่สังเกตได้ยาก |
| 0.5 | กลาง | ความแตกต่างเห็นได้ชัดและอาจมีความหมายในทางปฏิบัติ |
| 0.8 | ใหญ่ | ความแตกต่างชัดเจนและมีความหมายในทางปฏิบัติ |
ตารางที่ 2: เกณฑ์ Cohen's d สำหรับตีความขนาดอิทธิพล (Cohen, 1988)
ในตัวอย่างนี้ d = 0.36 เป็นอิทธิพลขนาดเล็กถึงกลาง หญิงมีคะแนนสูงกว่าชายประมาณหนึ่งในสามของส่วนเบี่ยงเบนมาตรฐานบน Satisfaction เมื่อรวมกับค่า p ที่มีนัยสำคัญ (.033) ผลนี้ให้หลักฐานทั้งทางสถิติและทางปฏิบัติว่ามีความแตกต่างทางเพศ แม้ว่าขนาดอิทธิพลจะไม่ได้ใหญ่โตนัก
เครื่องหมายของ Cohen's d บอกทิศทาง (ลบแปลว่ากลุ่ม 2 คะแนนสูงกว่า) แต่สิ่งที่สำคัญสำหรับการตีความคือขนาด ถ้าทิศทางชัดจากค่าเฉลี่ยแล้ว ให้รายงานเป็นค่าสัมบูรณ์
ถ้าข้อสมมติไม่ผ่านต้องทำอย่างไร
การแจกแจงปกติไม่ผ่าน
ถ้าการแจกแจงปกติถูกละเมิดรุนแรง (ค่าความเบ้เกิน +/-2 ในกลุ่มใดกลุ่มหนึ่งหรือทั้งคู่) และขนาดกลุ่มน้อยกว่า 30 ให้ใช้ Mann-Whitney U test ซึ่งเป็นทางเลือกนอนพาราเมตริกมาตรฐาน มันเปรียบเทียบอันดับ (ranks) ของคะแนนแทนค่าเฉลี่ย และไม่ต้องการการแจกแจงปกติ
วิธีรัน Mann-Whitney U ใน SPSS: Analyze > Nonparametric Tests > Legacy Dialogs > 2 Independent Samples ย้ายตัวแปรทดสอบไป Test Variable List ตัวแปรจัดกลุ่มไป Grouping Variable กำหนดกลุ่ม แล้วเลือก "Mann-Whitney U" ที่ Test Type
กับกลุ่มตั้งแต่ 30 คนขึ้นไป สถิติพาราเมตริกทนทานพอที่การละเมิดปานกลาง (ค่าความเบ้ระหว่าง -2 ถึง +2) มักไม่ส่งผลต่อความถูกต้องของผล (Glass et al., 1972) ให้บันทึกการละเมิดและอ้างอิงงานวิจัยเรื่องความทนทาน
ความแปรปรวนไม่เท่ากัน (ทดสอบ Levene มีนัยสำคัญ)
นี่คือการละเมิดที่จัดการง่ายที่สุด แค่อ่านแถว "Equal variances not assumed" ใน output Welch's t-test ปรับองศาอิสระเพื่อชดเชยความแปรปรวนไม่เท่ากัน ไม่ต้องรันอะไรเพิ่ม
รายงานตรงไปตรงมา: "Levene's test indicated unequal variances, F(1, 145) = 5.23, p = .024. Therefore, the Welch-adjusted t-test was used."
ทั้งสองข้อสมมติไม่ผ่าน
เมื่อทั้งการแจกแจงปกติและความแปรปรวนเท่ากันไม่ผ่าน Mann-Whitney U เป็นทางเลือกที่ปลอดภัยที่สุด รายงานการละเมิด อธิบายว่าทำไมถึงเลือกทางเลือกนอนพาราเมตริก แล้วนำเสนอผล Mann-Whitney U ในรูปแบบ APA
รายงานในรูปแบบ APA
รายงานผลจริงจากคู่มือนี้
An independent samples t-test was conducted to compare Satisfaction scores between male and female students. Levene's test for equality of variances was not significant (F = 0.02, p = .900), so equal variances were assumed. Female students (M = 3.59, SD = 0.95) reported significantly higher satisfaction than male students (M = 3.25, SD = 0.94), t(145) = -2.15, p = .033, d = 0.36, 95% CI [-0.65, -0.03]. The effect size was small to medium.
แม่แบบสำหรับผลไม่มีนัยสำคัญ
ถ้าผลไม่มีนัยสำคัญ จะรายงานแบบนี้:
An independent samples t-test was conducted to compare Satisfaction scores between male and female students. There was no significant difference between males (M = 3.25, SD = 0.94) and females (M = 3.38, SD = 0.96), t(145) = -0.84, p = .401, d = 0.14. The effect size was negligible.
กรณีใช้ Welch (ความแปรปรวนไม่เท่ากัน)
Levene's test indicated unequal variances (F = 5.23, p = .024), so the Welch-adjusted t-test was used. There was no significant difference between males (M = 3.12, SD = 0.89) and females (M = 3.24, SD = 1.12), t(141.35) = -0.72, p = .474, d = 0.12.
ตาราง APA
สำหรับบทผลการวิจัยที่ต้องสร้างตารางสรุป:
| ตัวแปร | กลุ่ม | N | M | SD | t | df | p | d |
|---|---|---|---|---|---|---|---|---|
| Satisfaction | ชาย | 61 | 3.25 | 0.94 | -2.15 | 145 | .033 | 0.36 |
| หญิง | 86 | 3.59 | 0.95 |
ตารางที่ 3: ผล independent samples t-test เปรียบเทียบ Satisfaction ตามเพศ
รายการตรวจสอบการรายงาน
ทุกครั้งที่รายงาน independent samples t-test ควรมี:
- วัตถุประสงค์ของการทดสอบ (เปรียบเทียบอะไร ทำไม)
- ผลทดสอบ Levene (ความแปรปรวนเท่ากันหรือไม่ และอ่านแถวไหน)
- ค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานของแต่ละกลุ่ม
- ค่า t, องศาอิสระ และค่า p แบบเจาะจง
- ขนาดอิทธิพล (Cohen's d) พร้อมการตีความ
- ช่วงความเชื่อมั่น 95% ของผลต่างค่าเฉลี่ย (ไม่บังคับแต่แนะนำ)
ข้อผิดพลาดที่พบบ่อย
1. ใช้ t-test กับสามกลุ่มขึ้นไป
การรัน t-test หลายครั้งเพื่อเปรียบเทียบสามกลุ่ม (เช่น ม.ปลาย vs. ปริญญาตรี, ม.ปลาย vs. ปริญญาโท, ปริญญาตรี vs. ปริญญาโท) ทำให้โอกาสเกิดความผิดพลาดประเภทที่ 1 เพิ่มขึ้น เปรียบเทียบสามคู่ที่ alpha = .05 โอกาสได้ผลบวกลวงอย่างน้อยหนึ่งครั้งเพิ่มเป็นประมาณ .14 ให้ใช้ ANOVA พร้อม post-hoc test แทน
2. ไม่ดูทดสอบ Levene
นักศึกษาบางคนรายงานแค่แถว "Equal variances assumed" โดยไม่เช็คว่าข้อสมมตินั้นจริงหรือเปล่า ถ้าทดสอบ Levene มีนัยสำคัญ องศาอิสระ ค่า p และช่วงความเชื่อมั่นในแถวบนจะไม่ถูกต้องทั้งหมด ต้องเช็คและรายงานว่าอ่านแถวไหนเสมอ
3. ไม่เช็คการแจกแจงปกติแยกตามกลุ่ม
การรันทดสอบการแจกแจงปกติรวมทั้งตัวแปร (สองกลุ่มรวมกัน) ไม่เพียงพอ ข้อสมมติต้องการให้ข้อมูลแจกแจงปกติภายในแต่ละกลุ่ม ใช้ Factor List ใน Explore เพื่อทดสอบแยกกลุ่ม
4. ไม่รายงานขนาดอิทธิพล
ค่า p บอกแค่ว่าผลมีนัยสำคัญทางสถิติหรือไม่ ไม่ได้บอกว่าความแตกต่างใหญ่พอที่จะมีความหมายหรือเปล่า ผลที่มีนัยสำคัญกับ d = 0.10 และกลุ่มตัวอย่าง 500 คน มีนัยสำคัญทางสถิติแต่ไม่มีความหมายในทางปฏิบัติ อาจารย์ที่ปรึกษาคาดหวัง Cohen's d หรือตัวชี้วัดขนาดอิทธิพลอื่นมากขึ้นเรื่อย
5. สับสนระหว่าง independent กับ paired
ถ้าวัดคนเดียวกันก่อนและหลังการแทรกแซง ข้อมูลไม่เป็นอิสระ การใช้ independent samples t-test ในกรณีนี้จะไม่สนใจความสัมพันธ์ระหว่างค่าที่วัดคู่กัน ทำให้ได้ผลไม่ถูกต้อง ใช้ paired samples t-test สำหรับการเปรียบเทียบภายในกลุ่ม
6. รันการทดสอบแบบหางเดียวโดยไม่มีเหตุผล
SPSS รายงานค่า p แบบสองหางเป็นค่าตั้งต้น การหารค่า p ด้วย 2 เพื่อให้ได้ผลแบบหางเดียวเหมาะสมเฉพาะเมื่อคุณมีสมมติฐานทิศทางที่ชัดเจนก่อนเก็บข้อมูล การเปลี่ยนเป็นหางเดียวหลังเก็บข้อมูลเพื่อให้ได้นัยสำคัญเป็นรูปแบบของ p-hacking ที่อาจารย์ที่ปรึกษาจะตั้งคำถาม
คำถามที่อาจารย์ที่ปรึกษาจะถาม
"ทำไมใช้ independent samples t-test ไม่ใช่ ANOVA?" Independent samples t-test เป็นสถิติที่เหมาะสมเมื่อเปรียบเทียบสองกลุ่มบนตัวแปรต่อเนื่อง ANOVA ออกแบบมาสำหรับสามกลุ่มขึ้นไป แม้ว่า one-way ANOVA กับสองกลุ่มจะให้ผลเหมือนกันทางคณิตศาสตร์ (F = t²) แต่ t-test ตอบคำถามการเปรียบเทียบสองกลุ่มโดยตรงและเป็นทางเลือกตามธรรมเนียม
"จัดการข้อสมมติความแปรปรวนเท่ากันอย่างไร?" อธิบายว่าเช็คทดสอบ Levene ใน output SPSS ถ้าไม่มีนัยสำคัญ สมมติว่าความแปรปรวนเท่ากัน ถ้ามีนัยสำคัญ ใช้ผลจากแถว "Equal variances not assumed" ที่ปรับแก้ด้วย Welch อ้างอิง Delacre et al. (2017) ถ้าอาจารย์สงสัย
"ผลมีนัยสำคัญ แต่ความแตกต่างสำคัญในทางปฏิบัติไหม?" ตรงนี้คือจุดที่ Cohen's d เข้ามา d = 0.36 เป็นอิทธิพลขนาดเล็กถึงกลาง หญิงมีคะแนนสูงกว่าชายประมาณหนึ่งในสามของส่วนเบี่ยงเบนมาตรฐาน ผลต่าง 0.34 จุดบนสเกล 5 จุดจะมีความหมายหรือไม่ขึ้นอยู่กับบริบทของงานวิจัย รายงานขนาดอิทธิพล อธิบายขนาดตามเกณฑ์ Cohen แล้วให้ผู้อ่านประเมินความเกี่ยวข้องกับบริบทของตัวเอง
"ทำไมถึงเชื่อถือ t-test ได้ถ้า Shapiro-Wilk มีนัยสำคัญ?" อ้างอิงความแตกต่างระหว่างนัยสำคัญทางสถิติกับความสำคัญในทางปฏิบัติของทดสอบการแจกแจงปกติ อ้างค่าความเบ้และความโด่ง (อยู่ในช่วง +/-1) หลักฐานจาก Q-Q plot และงานวิจัยเรื่องความทนทาน (Schmider et al., 2010) คำถามนี้ถูกอธิบายอย่างละเอียดในคู่มือทดสอบการแจกแจงปกติ
คำถามที่พบบ่อย
ขั้นตอนถัดไป
หลังจากรัน independent samples t-test แล้ว การวิเคราะห์ถัดไปขึ้นอยู่กับแบบแผนการวิจัย
ถ้าต้องเปรียบเทียบคนกลุ่มเดียวกันในสองช่วงเวลา (ก่อนเรียน vs. หลังเรียน) ให้ใช้ paired samples t-test ถ้างานวิจัยมีตั้งแต่สามกลุ่มขึ้นไป ให้ใช้ ANOVA ซึ่งขยายหลักการของ t-test ไปสู่การเปรียบเทียบหลายกลุ่มด้วยการทดสอบ omnibus ครั้งเดียว
สำหรับการศึกษาความสัมพันธ์ระหว่างตัวแปรต่อเนื่องสองตัวแทนการเปรียบเทียบค่าเฉลี่ย regression เชิงเส้น ให้กรอบสำหรับการทำนายและอธิบาย ถ้ามาตรวัดมีหลายข้อ ให้เช็คความเชื่อมั่นด้วย Cronbach's Alpha ก่อนนำคะแนนรวมไปใช้ใน t-test
ตรวจสอบว่าการวิเคราะห์พื้นฐานถูกบันทึกไว้แล้ว: สถิติเชิงพรรณนา สำหรับลักษณะของกลุ่มตัวอย่าง และทดสอบการแจกแจงปกติ สำหรับการเช็คข้อสมมติ ควรอยู่ในบทผลการวิจัยก่อนผล t-test
เอกสารอ้างอิง
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). American Psychological Association.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
Delacre, M., Lakens, D., & Leys, C. (2017). Why psychologists should by default use Welch's t-test instead of Student's t-test. International Review of Social Psychology, 30(1), 92-101.
Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). SAGE Publications.
Glass, G. V., Peckham, P. D., & Sanders, J. R. (1972). Consequences of failure to meet assumptions underlying the fixed effects analyses of variance and covariance. Review of Educational Research, 42(3), 237-288.
Pallant, J. (2020). SPSS survival manual (7th ed.). Open University Press.
Schmider, E., Ziegler, M., Danay, E., Beyer, L., & Bühner, M. (2010). Is it really robust? Reinvestigating the robustness of ANOVA against violations of the normal distribution assumption. Methodology, 6(4), 147-151.